基于Stacking集成学习的恒星/星系分类研究∗
2020-04-02张文辉王俊义林基明
李 超 张文辉 李 然 王俊义 林基明
(1 桂林电子科技大学信息与通信工程学院桂林541004)
(2 桂林电子科技大学认知无线电与信息处理教育部重点实验室桂林541004)
(3 桂林电子科技大学广西云计算与大数据协同创新中心桂林541004)
(4 桂林电子科技大学广西高校云计算与复杂系统重点实验室桂林541004)
(5 桂林电子科技大学广西无线宽带通信与信号处理重点实验室桂林541004)
(6 广西高校卫星导航与位置感知重点实验室桂林541004)
1 引言
2 算法理论
2.1 Stacking集成学习算法
Stacking集成学习[10]是一种异质集成的策略.异质集成是通过集成若干个不同类型的基分类器, 组合成一个强分类器, 以此来提升强分类器的泛化能力.Stacking集成学习算法采用两层框架的结构, 如图1所示.其训练过程如下: 首先分别对多个基分类器进行训练; 然后将多个基分类器的预测结果作为元分类器的输入, 再次进行训练.最终的集成算法会兼顾基分类器和元分类器的学习能力, 使得分类精度和准确率得到明显提升.Stacking集成学习算法的效果好坏取决于两个方面: 一个是基分类器的预测效果, 通常基分类器的预测效果越好, 集成学习模型的预测效果越好; 另一个是基分类器之间需要有一定的差异性, 因为每个模型的主要关注点不同, 这样集成才能使每个基学习器充分发挥其优点.试想, 如果基分类器的差异性较低, 那么每个基分类器的预测结果就会很相似, 那么这样集成和单个分类器的预测基本没有区别, 只会徒增模型的复杂度.
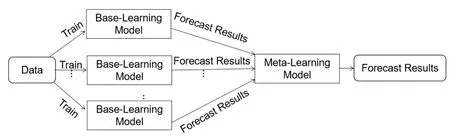
图1 基于Stacking的集成学习算法Fig.1 An ensemble learning algorithm based on Stacking
2.2 支持向量机算法
支持向量机(Support Vector Machine, SVM)是一种二类分类模型, 其基本模型是定义在特征空间上的间隔最大的线性分类器.线性可分SVM算法旨在找到一个可以完全划分所有数据的超平面, 使得数据集中所有数据距离此超平面最远, 即硬间隔(hard margin) SVM.当训练数据近似线性可分时, SVM通过软间隔(soft margin)最大化也可以学习到一个线性分类器, 也称软间隔SVM.随着数据复杂程度的提高, 当训练数据线性不可分时, 通过引入软间隔最大化和核技巧, 学习到一个分类器, 即非线性SVM.非线性SVM可以将在原始特征空间中线性不可分的训练样本映射到一个高维的特征空间中,从而使得映射后的训练样本在高维特征空间中线性可分.本文使用的SVM算法采用的是径向基函数(Radial Basis Function, RBF), 也称高斯核函数:
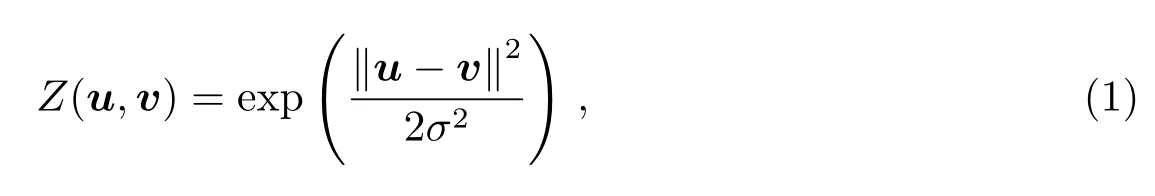
其中u和v表示为两个样本向量, Z表示为RBF核函数的值, σ是一个自由参数.
2.3 随机森林算法
随机森林(Random Forest, RF)是集成学习中Bagging思想的一种算法策略.Bagging思想是对训练集进行随机采样, 产生出多个不同的训练子集, 再对每个训练子集训练出一个基分类器, 预测结果通过多个基分类器取平均或者投票得出.这时的预测模型有望获得较好的预测结果和较强的泛化能力.随机森林是在将决策树作为基学习器构建Bagging集成算法的同时, 还引入了特征的随机采样, 进一步提升了模型的抗噪声能力, 有效地防止了过拟合的发生.
2.4 梯度提升树算法
梯度提升决策树(Gradient Boosting Decision Tree, GBDT)[11]是集成学习Boosting思想中的一种算法, 它同样将决策树作为基函数.GBDT算法的核心在于每颗树学习的是之前所有树结论和的残差.传统的提升树算法采用平方损失函数, 可以直接计算残差,但是缺点是仅能解决回归问题.GBDT算法对其做了改进, 它每次在建立单个弱分类器时, 是在之前建立模型的损失函数的梯度下降方向(或称负梯度值)来近似残差.因此, 多种损失函数的选取, 不仅可以帮助GBDT算法有效地解决回归问题, 同时也可以解决分类问题.GBDT算法的学习能力较强, 是如今机器学习领域非常重要的一个算法.
2.5 XGBoost算法
XGBoost(eXtreme Gradient Boosting)[12]是一种对GBDT做了改进的提升算法,在优化时同时使用一阶导数信息和二阶导数信息.其模型如下所示:

“师长话语”给人的感觉始终是一种严谨、拘束的状态。在中国这样的礼义之邦,适当的严肃能够树立一定的威严,但面对现今普及化的大学教育,过于严肃的话语方式很难起到实质性的教育效果。学生不会对大而空的套话、官话感兴趣,他们所需要的是新时代励志教育所注入的新的思维话语模式。
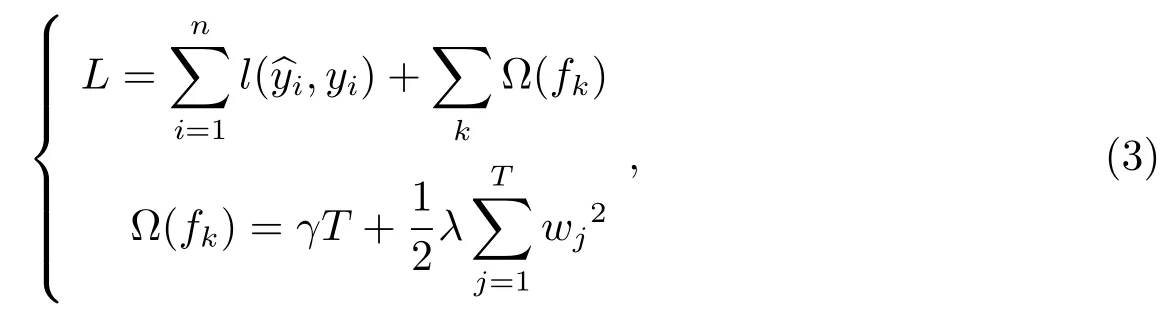
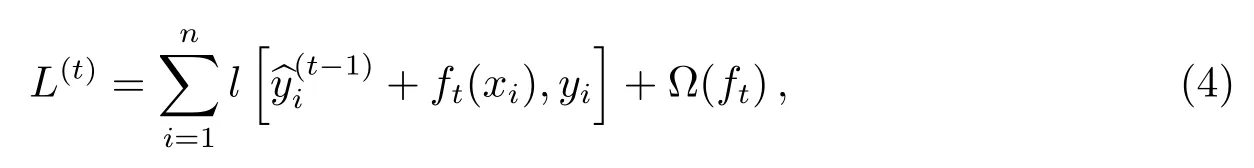
其中L(t)表示为第t轮的目标函数,表示为前t −1棵树的输出值之和, 构成前t −1棵树的预测值, ft表示为第t棵树的模型, ft(xi)表示为第t棵树的输出结果,相加构成最新的预测值.
定义gi和hi:


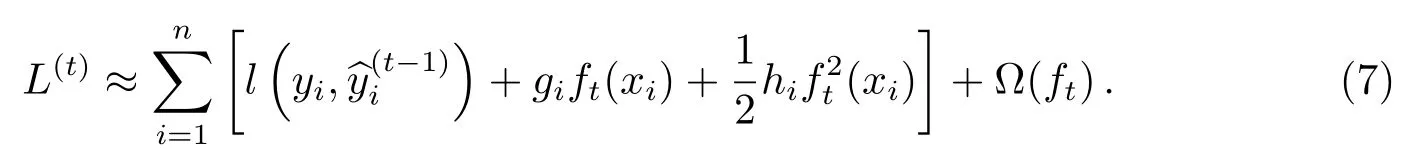
去掉常数项, 第t次迭代后的损失函数变为:
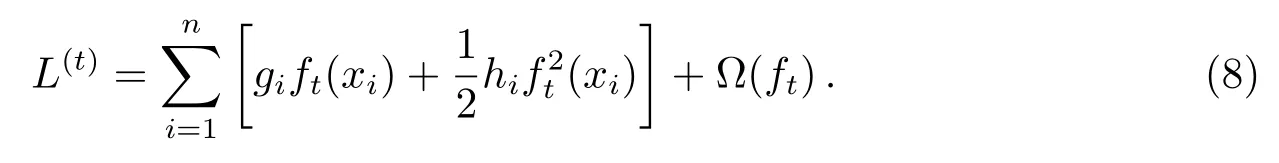
定义Ij= {i|q(xi)=j}作为叶子节点j的实例集, 其中I表示节点划分前的实例集, 根据(8)式得:
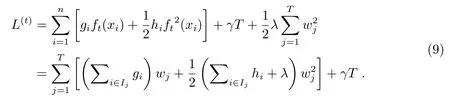
对于固定了的决策树的结构q(xi), 可以计算得出叶子节点j的最优权重w∗j:

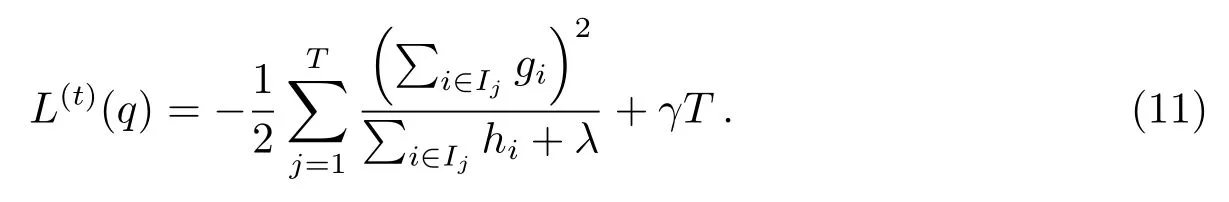
(11)式作为衡量树结构质量的指标, 可以用来计算树结构q的得分.同时, 需要使用贪心算法迭代地在每一个已有的叶子节点添加分支.假定IL和IR是划分后左右子树叶子节点的集合, 即I =IL∪IR, 则划分后的损失函数如下:
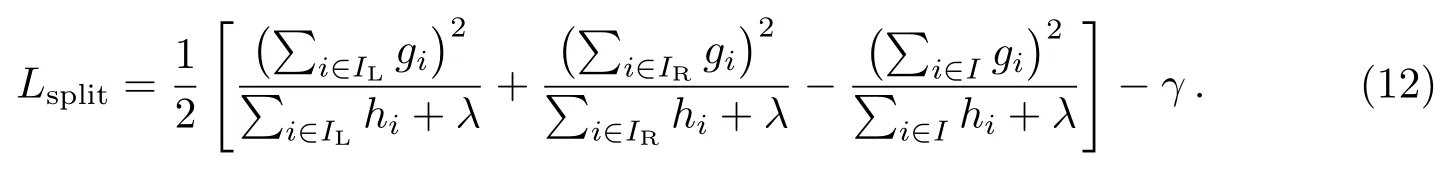
3 基于Stacking集成学习算法的训练
本文充分考虑了决定Stacking集成学习模型效果好坏的两个方面: 一是选择学习能力较强的基学习器; 二是充分考虑基学习器之间的差异性.SVM在解决非线性的中小规模数据集的分类和回归中具有非常好的效果.RF和XGBoost分别是集成学习Bagging和Boosting中泛化能力和学习能力较强的算法.3种算法不仅有充分的理论支撑, 而且在科学研究中正扮演着重要的角色.第2层元学习器同样选择学习能力较强的GBDT算法, 用于对第1层基学习器的集成, 并且使用10×10折嵌套交叉验证划分数据的方式防止过拟合的发生.综上所述, 本文基于Stacking集成学习的分类模型第1层基学习器选择SVM、RF、XGBoost, 第2层元学习器选择GBDT, 模型结构如图2所示.
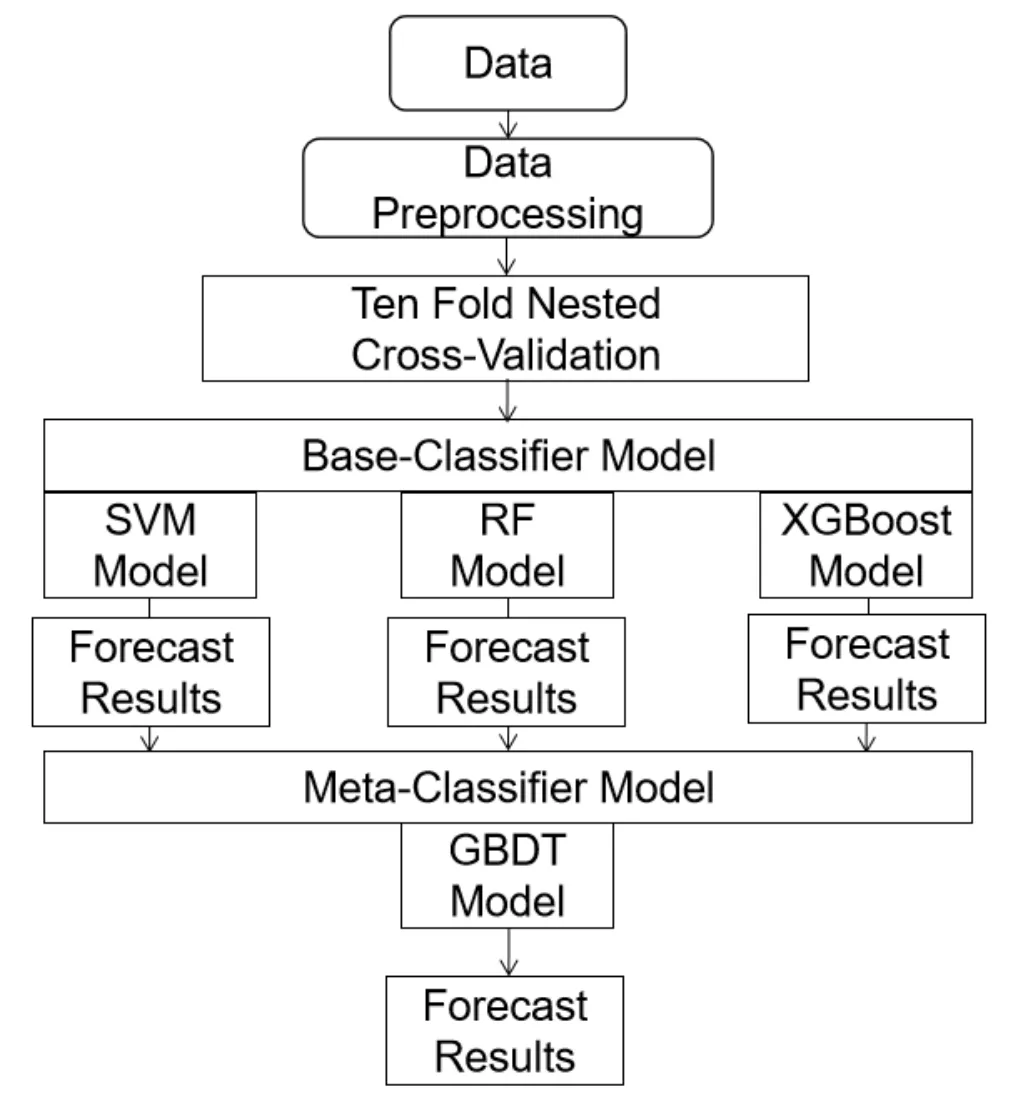
图2 基于Stacking集成学习的恒星/星系分类模型Fig.2 A star/galaxy classification model based on the Stacking ensemble learning
传统的10折交叉验证就是将原始数据划分为10等分, 轮流将其中的9份作为训练集,剩下1份作为测试集.本文采用10×10折嵌套交叉验证的划分方法, 即在每一个训练集的内部再做一次10折交叉验证.
基于Stacking集成学习框架的训练流程如下:
(1)对原始数据进行预处理并且按照10×10折嵌套交叉验证的方式进行划分;
(2)使用划分后的数据集分别对第1层基学习器中的SVM、RF、XGBoost 3种算法进行训练, 并得到预测结果;
(3)将第1层基学习器的预测结果拼接起来作为第2层元学习器GBDT的输入, 再次进行训练, 并得到最终的预测结果.
4 实验结果与分析
4.1 数据集介绍
完整的SDSS-DR7测光数据集见http://skyserver.sdss.org/dr7/en/, 根据星等值(modelMag)大小可以划分为: 亮源星等集(14–19)、暗源星等集(19–21)、最暗源星等集(20.5–21).与SDSS-DR7恒星/星系亮源和暗源星等集数据相比, 最暗源星等集数据量规模较小, 数据测量困难, 分类准确率较低.因此本文采用的是SDSS-DR7恒星/星系最暗源星等数据集, 可直接使用简单的SQL (Structured Query Language)语句从Skysever平台获取, 并且与文献[4]特征参数保持一致.数据特征参数如表1所示.
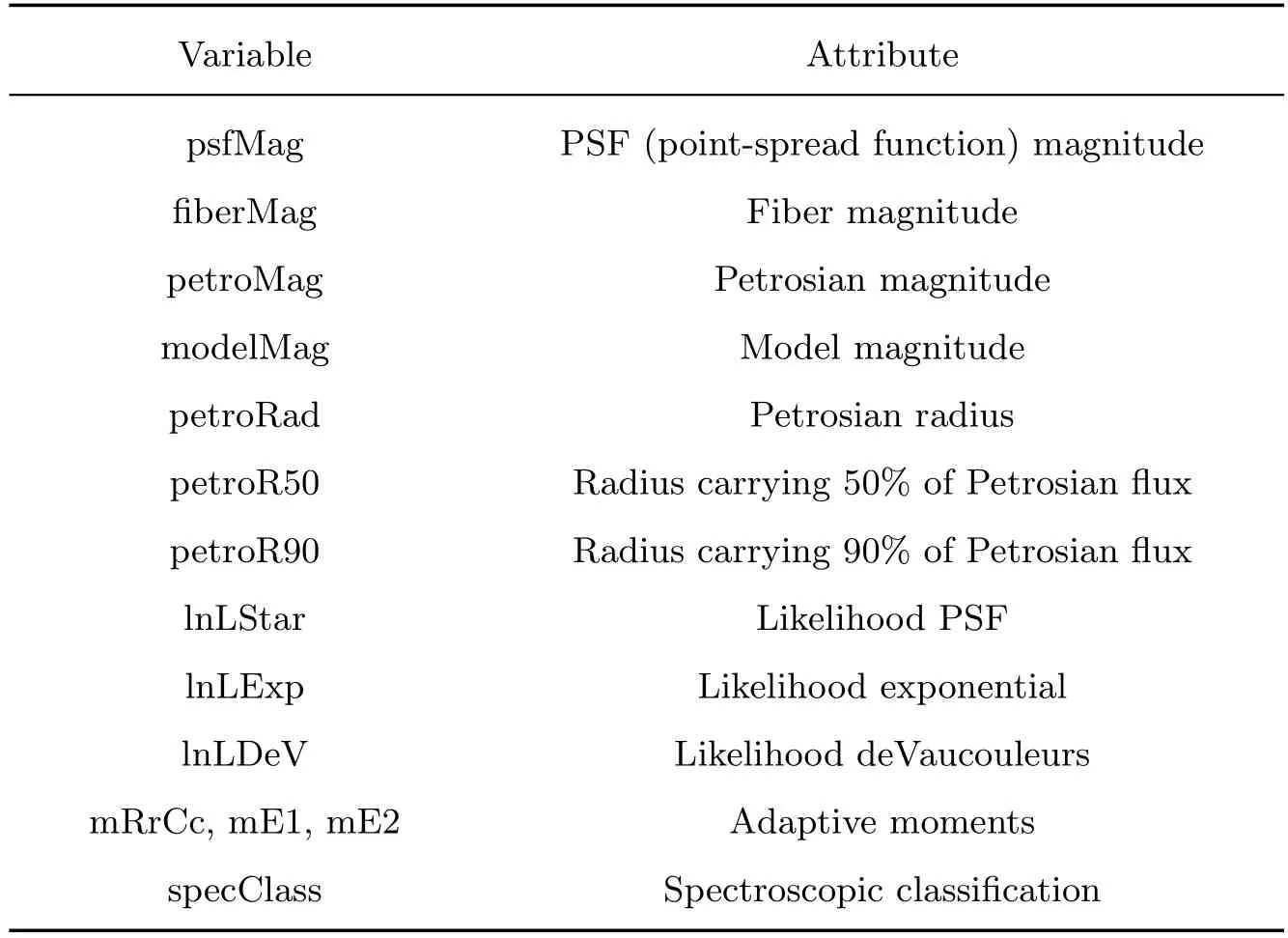
表1 用于SDSS-DR7恒星/星系分类的特征参数Table 1 The feature parameters for SDSS-DR7 star/galaxy classification
4.2 参数设置
基于Stacking集成学习模型通过将SVM、RF、XGBoost算法作为基学习器训练,得到预测结果, 作为元学习器GBDT的输入, 再次进行训练, 得到最终预测结果.各个算法的主要参数设置如下: SVM算法模型采用RBF, gamma参数设置为1; RF算法模型采用计算属性的基尼指数来选择分裂节点, 决策树的个数和深度分别为65和7; XGBoost算法模型的弱学习器数目设置为710, 学习速率设置为0.01, 树的深度设置为6; GBDT算法模型的弱学习器数目设置为200, 学习速率设置为0.04, 树的深度设置为3.
4.3 实验方法及模型对比
为了能更好地评估基于Stacking集成学习模型在恒星/星系最暗源星等集分类上的性能, 本文对比了FT、SVM、RF、GBDT、XGBoost[13−14]、DBN、SDAE、DPDT等算法, 详细的对比实验结果如表2.同样, 为了保证对比分类结果的有效性, 采用了与文献[4]一致的分类性能衡量指标(CP), 即星系的分类正确率.其定义如(13)式所示:
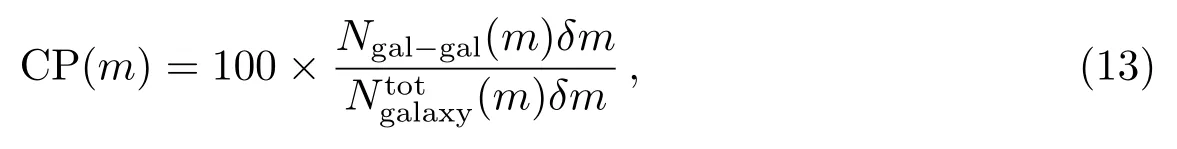
其中, Ngal−gal(m)δm代表星等值在区间内的数据样本中被正确分类为星系的数量,代表星等值在区间内数据样本中星系的总数量.本文仅使用modelMag在20.5–21之间的最暗源星等集.
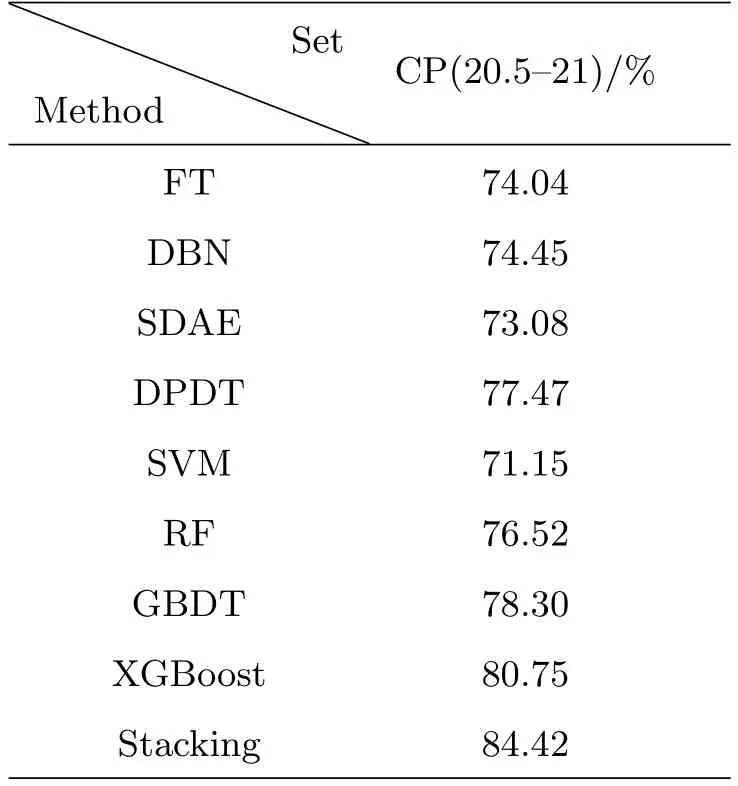
表2 SDSS-DR7星系分类正确率Table 2 The accuracy of SDSS-DR7 galaxy classification
通过仿真实验得出的表2可以看出, 对最暗源星等集, 基于Stacking集成学习模型的星系分类准确率要远优于FT, 提高了约10%的准确率.而与之前已经研究过的SDAE、DPDT模型相比, 准确率提高了约7%–10%.与其他较为先进的DBN、SVM、RF、GBDT、XGBoost等算法相比, 也提高了约4%–13%的星系分类准确率.由此可见, 基于Stacking集成学习模型综合了各个基分类器的优点后, 并充分发挥了集成模型的性能,因此具有更强的泛化能力和更好的预测效果.
5 结论
本文通过使用SDSS-DR7测光数据集, 并且采用10×10折嵌套交叉验证的方法, 研究了基于Stacking集成学习算法的恒星/星系的分类问题.最后通过对基分类器和元分类器参数调优, 基于星系分类准确率的评价指标, 与FT、SVM、RF、GBDT、XGBoost、DBN、SDAE、DPDT等模型进行对比.实验结果表明, 基于Stacking集成学习模型在恒星/星系最暗源星等集上的分类效果要远好于其他模型.因此, 该Stacking集成学习模型在天文学有非常高的应用价值.
在下一步工作中, 将探讨解决Stacking集成学习模型的算法复杂度问题.在中小规模数据集上, 该集成模型应用较好.但是, 遇到大规模或者超大规模数据集, 势必会大大增加集成模型的训练时间.因此, 在未来的研究中, 会尝试使用分布式的方法, 对基学习器并行训练, 这样不仅会使集成模型达到较高的精确度, 而且也会使得集成模型训练起来有较高的效率.
