利用节点重要度和社团接近度发现社团结构
2020-04-01冯健史丹丹罗香玉叶鸥
冯健 史丹丹 罗香玉 叶鸥


摘 要:社團发现能够揭示复杂网络的拓扑结构特性。针对现有社团发现算法社团初始节点选择随机、相似度计算过分依赖节点间共享邻居以及需要事先设定社团个数等问题,依托层次聚类思想提出基于节点重要度和社团接近度的社团划分算法。首先引入节点重要度的定义并给出重要节点的计算模型,根据该模型得到最重要节点作为社团的初始聚类中心;然后兼顾节点的共享关系和直接影响定义节点的社团接近度,依据社团接近度指标寻找与社团最接近的节点,根据该节点的加入为社团带来的局部模块度增量判断是否将其加入到已有社团。首个社团划分完毕后,重复选取初始聚类中心并构造社团的过程,直到没有可归入社团的节点。在2个典型复杂网络数据集上进行了测试,
并与Girvan-Newman算法和Newman快速算法从准确率和模块度进行对比,实验结果表明所提算法在社团数目未知的前提下能够获得更好的社团划分结果。关键词:社团发现;层次聚类;节点重要性;社团接近度中图分类号:TP 399
文献标志码:A
文章编号:1672-9315(2020)01-0181-06
DOI:10.13800/j.cnki.xakjdxxb.2020.0124开放科学(资源服务)标识码(OSID):
Discovering community structure using node importance
and community proximity
FENG Jian 1,SHI Dan-dan 2,LUO Xiang-yu 1,YE Ou 1
(1.College of Computer Science and Engineering,Xian University of Science and Technology,Xian 710054,China;
2.Chengdu Skysoft Information Technology Co.,Ltd.,Chengdu 610041,China)
Abstract:Community discovery can reveal the topological characteristics of complex networks.For the existing community discovery algorithms,selection of the initial node for a community is random,similarity calculation is over-reliant to the shared neighbors between nodes,and the numbers of communities needs to be set in advance.To overcome these problems,based on the idea of hierarchical clustering,a community discovery algorithm based on node importance and community proximity is proposed.Firstly,the definition of node importance is introduced and the calculation model of important nodes is given.According to the model,the most important node is taken as the initial cluster center of a community.Then,the concept of node-community proximity is defined by taking the sharing relationship and direct effect of nodes into account.The node closest to the community should be found according to the node-community proximity index,andwhether to add it to the existing community is decided according to the increment of partial modularity brought by the node.After the first community is divided,the process of selecting the initial cluster center and constructing the community is repeated until there are no nodes left.Experiments are carried out on two typical complex network datasets,
with a comparison of the accuracy and modularity made between the results by Girvan-Newman algorithm and Newman fast algorithm.The experimental results show that the proposed algorithm can get better result of community division under the premise that the number of communities is unknown.Key words:community discovery;hierarchical clustering;node importance;community proximity
0 引 言
大量研究表明,结构性是复杂网络的本质特性。结构性体现为社团,是指复杂网络中的节点呈现出以簇为特征的聚集状态,簇内节点联系紧密,簇间节点联系松散[1]。发现网络社团结构也称作社团划分,有助于揭示网络的组织原则和功能特性[2],具有十分重要的理论和应用价值。
社会学研究工作者Newman和Girvan等人的研究是复杂网络中社团划分的起源性研究[3],在此基础上人们提出了很多寻找社团结构的算法,包括图划分方法,如早期提出的经典Kernighan-Lin算法[4]和GN算法[5],后来逐渐倾向于层次聚类法,具体又分为分裂算法[6-7]、凝聚算法[8-9]、谱平分法[10-11]等;以及随机块模型方法[12]、结合属性和链接法[13-14]等。特别地,针对社团的重叠特性,提出了派系过滤算法[15]、极大团算法[16]、模糊算法[17]等。上述几类算法根据不同的研究对象,又可以归纳为基于节点的和基于边的社团划分方法。虽然社团划分算法已有大量研究,但仍存在一些问题,如图划分算法依据网络的结构信息进行社团发现,往往需要事先设定社团的数目,对于社团数目未知的网络效率较低[18];大多社团划分算法将属性相似或者角色相似的节点聚为一类,采用的主流相似度指标[19]如共同邻居指标、Salton指标、Jaccard指标往往主要考虑节点之间的共同关系而忽视了节点对整个网络的影响;已有算法常随机选择初始聚类中心,随后再加以调整,这样的策略易导致聚类效果不稳定[20]。
为了解决上述问题,借鉴文献[21]的思想,对层次聚类算法进行改进,提出基于节点重要度和社团接近度的社团划分算法NICP(Node Importance and Community Proximity Based Community Discovery Algorithm)以探测网络中的社团结构。该算法迭代地选择重要节点作为初始聚类中心,并将与社团最接近的节点有条件加入社团。文中其余部分组织如下,第1部分介绍NICP算法;第2部分进行实验分析;第3部分总结全文并指出未来研究方向。
1 社团发现算法
复杂网络可以建模为G=(V,E),其中V为节点集合;E为边集合。n=|V|为G的节点总数,A是G的n×n维邻接矩阵。要研究的问题是:对于网络G,如何根据网络中节点的相似性找到其社团集合CR.
1.1 评价指标
针对网络的真实社团划分未知和已知的情况,研究者们尝试采用不同的社团划分评价指标对社团结构进行量化。主要的量化指标如下
1.1.1 准确率
准确率(Precision,P)指示了被正确划分的节点数占总划分规模的比例,其定义如下
P=|CR|∩|CRT||CR|
(1)
式中 |CR|T是网络的实际社团结构。
1.1.2 模块度
模块度Q是一种用于评价划分结果的重要指标[5],考量的是社区内实际连边和随机连边概率的差异。定义为
式中 m为网络的总边数;u和v为网络中的节点。auv为邻接矩阵A中第uv个元素的值,即若u和v之间有连边,则为1,否则为0.D(u)和D(v)分别为u和v的度;Cu和Cv分别是u和v所属的社团,当Cu=Cv时,δ(Cu,Cv)=1;否则,δ(Cu,Cv)=0.
模块度的取值范围是[-1,1],值越大表示网络的社团化程度越高,相应地,认为社团发现算法性能越好。
1.1.3 局部模块度
Q通常也称为全局模块度,其计算时间复杂度高且需已知网络整体结构。为了解决这些问题,文献[22]提出了局部模块度Ql评价指标,其简化定义如下
Ql=|Ei||Ei|+|Eo|(3)
式中 |Ei|为社团内部的边数;|Eo|该社团对外连接的边数。一个社团内部边越多,外部边越少,则其Ql值越大,社团结构越清晰。
1.2 NICP算法
NICP基于层次聚类的思想提出算法基本思路:从网络G中找到最重要的节点u作为首个初始聚类中心以构建初始社团。在剩余节点中寻找与该社团最接近的节点v,计算v与该社团合并后将为社团带来的局部模块度增量ΔQl;若ΔQl>0,即v的加入将使社团的内聚力得到增强,则将v合并到u所在的社团,否则开始构建新的社团。对合并后的小社团重复上述寻找并添加最接近节点的过程,直到某个接近节点的加入将导致ΔQl≤0,这时一个社团划分完成。重新在剩余的节点中寻找最重要的节点作为下一个社团的初始聚类中心,并重复上述社团划分过程,直到网络中的所有节点都划分完毕。算法的关键点是:①最重要节点的判定,即社团初始聚类中心的确定;②接近节点的度量,即节点及社团接近度的度量;③社团内聚力的评判。
1.2.1 最重要节点的判定
在社团的聚类中,初始节点的选择在很大程度上影响了社团的内聚力和稳定性。已有层次聚类算法常随机选取初始聚类中心,后续再进行社团中心的调整,这样的方法往往导致社团划分质量不高,也容易引起社团的动荡。重要节点是网络中能够产生一定影响力并起到信息桥梁作用的节点,也即同时具有中心性和桥接能力[23]。据此引入节点重要度的概念,并选择重要节点作为社团初始聚类中心。
定义1 (节点重要度)I(u),为节点u的K-shell值和结构洞度的线性组合
I(u)=αKS(u)+βES(u),α+β=1(4)
式中KS(u)是u的K-shell值[24],ES(u)是通过Burt提出的网絡有效规模计算得到的结构洞度[25]。参数α和β为调节系数,其值根据实际网络结构与功能设定,实验中设置α=0.1和β=0.9.
社团中最重要的节点即重要度最大的节点,概念如下
定义2 (重要节点)NCi,为社团Ci的重要节点
1.2.2 节点及社团接近度的度量
社团划分实质上是寻找结构相似或性质相似的节点并将其放入同一社团中的过程,其核心问题是如何不断寻找与社团连接性最强的节点。这就要度量节点与社团中已有各节点的相似度。已有方法在评价节点间相似度时常依赖于2个节点的共同关系,如一般认为共享邻居数量越多相似性越大;文中则认为节点的相似度不仅与节点间拥有的共同关系有关,还与节点对另一节点的直接影响有关,因此提出接近度的概念。
定义3 (投入精力)ENuv,节点u对节点v投入的精力,表达节点的直接影响,定义为
ENuv= auv/D(u)(6)
定義4 (节点接近度)θuv,节点u与节点v的接近度,定义为
θuv= ENuv+sENus ENsv(7)
式中 s为u和v的共享邻居。从上式可知接近度不仅表达了节点u对节点v的直接影响,也表达了2个节点间的共同关系。
以图1的拓扑为例,节点a的邻居集合为{b,c,d,g4,g5,g6,g7,g8},根据公式(7)得到θab=0.250 0,
θac=0.125 0,
θad=0.312 5,
θag4=θag5=
θag6=θag7=
θag8=0.146 0
.根据计算结果可知,对于a来说,最接近的节点是d,这也和图1中的实际情况是吻合的。
推而广之,节点的社团接近度即为节点与社团内部所有节点的接近度之和。
定义5 (社团接近度)θuC,节点u和社团C的接近度
1.2.3 社团内聚力的评判
采用局部模块度进行社团内聚力的评判。若某个节点的加入导致当前社团的局部模块度增大,则将该节点加入社团,否则视为新社团起始的标志。
NICP算法的具体描述如下
输入:G,α,β
输出:CR
1)CR={},Ql=0;
2)对V按节点重要度降序排序形成节点序列VI;
3)选择VI中重要度最大的节点v作为社团初始聚类中心,VI=VI-{v},Ct={v};
4)建立Ct社团:
①找到与Ct相连的所有节点,建立节点集合
VCt;
②通过计算θ值,从
VCt中查找与Ct社团最接近的节点u;
③若ΔQl>0,则将u加入社团Ct,Ct=Ct+{u},
VI=VI-{u},转至①;
否则,CR=CR+Ct,若
VI={},转至⑤,否则转至③,开始新社团的划分;⑤算法结束,输出CR.
算法引入了2个关键环节来保证其稳定性和精度:根据节点的中心性和桥接性确定社团的初始聚类中心,提高社团划分质量并避免社团划分过程中的动荡;兼顾节点的共享关系和直接影响更准确地计算节点与社团的接近度,保证聚类的精度。另外,NICP算法利用局部模块度增量自动确定一个社团是否结束,无需事先给定社团数量。
2 实验分析
为了定量验证NICP算法的可行性和有效性,在人工网络—三社团网络和真实网络—足球队俱乐部Football网络数据集[3]上分别与有代表性的静态社团发现算法GN和FN[8]进行了综合评测。实验在主频为3.2 GHz,内存大小为16 GB的Intel Core i5处理器上完成,程序运行环境为Python 2.7.
表1为2个测试网络的基本信息。
2.1 三社团网络
图2为三社团网络示意图,通过NICP算法的发现过程见表2.
从表2可以清晰地看到,NICP算法的社团发现过程:首先通过节点重要度找到社团的初始聚类中心(3个社团的初始聚类中心分别为6,7,18号节点),然后逐步寻找最接近节点,再通过局部模块度的增大或减小决定将该节点加入社团或开始一个新的社团。通过对比图2和表2可以看到,NICP算法的发现结果和原网络完全一致。
表3给出各算法在三社团网络中的发现结果。
从表3可以看出,NICP算法的准确率和模块度与GN,FN算法一样,3个算法均能准确地对三社团网络进行划分。
2.2 Football
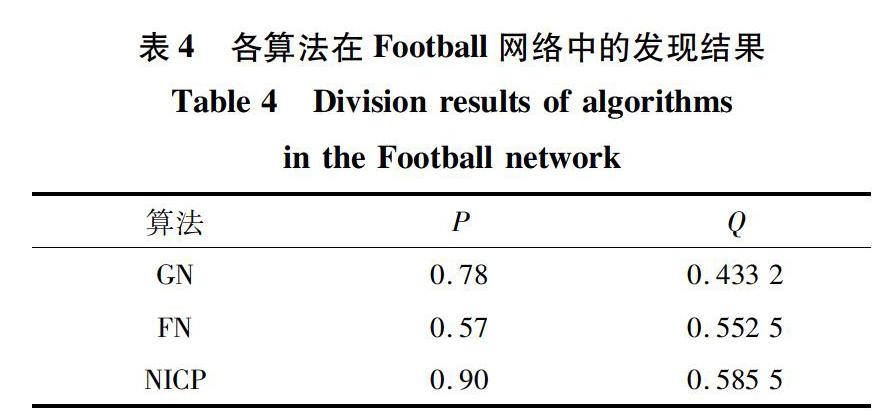
Football是2000年美国大学橄榄球联赛的网络数据。其中,节点代表参赛球队,若两支球队之间进行过一场比赛则形成连边。该网络共涉及115所大学的球队,分为12个社团,对应联赛的12个联盟。表4给出各算法的社团发现结果。
从表4可以看出,NICP算法无论是准确率还是模块度都比传统经典算法高,说明NICP算法能更有效地划分网络社团结构。
3 结 论
1)为解决复杂网络的社团发现问题提出了一种改进的基于层次聚类的社团发现算法NICP.
2)针对已有社团发现算法中初始聚类中心选择随机的问题,考虑节点的中心性和桥接性提出节点重要度的概念,选择最重要节点作为初始聚类中心,提高社团发现的效率和稳定性;针对聚类过程中相似度计算过分依赖节点间共享邻居的问题,结合节点间的共享关系和节点自身的影响提出节点接近度的概念,并扩展至节点-社团接近度,并以此作为节点与社团聚类相似度判定的依据;针对已有算法常需要事先设定社团个数的问题,将局部模块度的减小作为判定条件,自动发现新的社团。
3)将NICP算法和GN,FN算法应用在经典人工网络和实际网络中的结果表明,NICP算法社团发现结果的准确率和模块度指标都更高,证实了该算法具有可行性和有效性。
参考文献(References):
[1]汪小帆,刘亚冰.复杂网络中的社团结构算法综述[J].电子科技大学学报,2009,38(5):537-543.WANG Xiao-fan,LIU Ya-bing.Overview of algorithms for detecting community structure in complex networks[J].Journal of University of Electronic Science and Technology of China,2009,38(5):537-543.
[2]朱慶生,蒋天弘,周明强.基于自然最近邻居的社团检测算法[J].计算机应用研究,2014,31(12):3560-3563.ZHU Qing-sheng,JIANG Tian-hong,ZHOU Ming-qiang.Community detection algorithm based on natural nearest neighbor[J].Application Research of Computers,2014,31(12):3560-3563.
[3]Girvan M,Newman M E J.Community structure in social and biological networks[J].Proceedings of National Academy of Sciences of the United States of America,2002,99(12):7821-7826.
[4]Kernighan B W,Lin S.An efficient heuristic procedure for partitioning graphs[J].Bell System Technical Journal,1970(49):291-307.
[5]Newman M E J,Girvan M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69(2):026113.
[6]Radicchi F,Castellano C,Cecconi F,et al.Defining and identifying communities in networks[J].Proceedings of the National Academy of Sciences of the United States of America,2004,101(9):2658-2663.
[7]Sales-Pardo M,Guimera R,Moreira A A,et al.Extracting the hierarchical organization of complex systems[J].Proceedings of the National Academy of Sciences of the United States of America,2007,104(39):15224-15229.
[8]Newman M E J.Fast algorithm for detecting community structure in networks[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2003,69(6 Pt 2):066133.
[9]Blondel V D,Guillaume J L,Lambiotte R,et al.Fast unfolding of community hierarchies in large networks[J].Journal of Statistical Mechanics:Theory and Experiment,2008,10:10008.
[10]Luxburg U.A tutorial on spectral clustering[J].Statistics and Computing,2007,17(4):395-416.
[11]付立东.一种对分划分的复杂网络社团检测方法[J].西安科技大学学报,2012,32(5):648-651.FU Li-dong.Detecting of communities in complex networks with two partitioning approach[J].Journal of Xian University of Science and Technology,2012,32(5):648-651.
[12]Zhang H,Qiu B,Giles C L,et al.An LDA-based community structure discovery approach for large-scale social networks[C]//Muresan G,Altiok T,Melamed B,Zeng D.Proceedings of 2007 IEEE Intelligence and Security Informatics,New Brunswick,NJ USA,2007:200-207.
[13]黄发良,肖南峰.基于线图与PSO的网络重叠社区发现[J].自动化学报,2011,37(9):1140-1144.HUANG Fa-liang,XIAO Nan-feng.Discovering overlapping communities based on line graph and PSO[J].Acta Automatica Sinica,2011,37(9):1140-1144.
[14]李孝伟,陈福才,刘力雄.一种融合节点与链接属性的社交网络社区划分算法[J].计算机应用研究,2013,30(5):1477-1480.LI Xiao-wei,CHEN Fu-cai,LIU Li-xiong.Combined node and link attributes of social network community detection algorithm[J].Application Research of Computers,2013,30(5):1477-1480.
[15]Palla G,Derényi I,Farkas I,et al.Uncovering the overlapping community structure of complex networks in nature and society[J].Nature,2005,435:814-818.
[16]Shen H W,Cheng X Q,Cai K,et al.Detect overlapping and hierarchical community structure in networks[J].Physica A Statistical Mechanics & Its Applications,2009,388(8):1706-1712.
[17]Nepusz T,Petróczi A,N-gyessy L,et al.Fuzzy communities and the concept of bridgeness in complex networks[J].Physical Review E,2008,77(2):016107.
[18]Fortunato S,Barthelemy M.Resolution limit in community detection[J].Proceedings of the National Academy of Sciences of the United States of America,2007,104(1):36-41.
[19]姜雅文,贾彩燕,于 剑.基于节点相似度的網络社团检测算法研究[J].计算机科学,2011,38(7):185-189.JIANG Ya-wen,JIA Cai-yan,YU Jian.Community detection in complex networks based on vertex similarities[J].Computer Science,2011,38(7):185-189.
[20]闵 亮,邵良杉,赵永刚.基于节点相似度的社团检测[J].计算机工程与应用,2015,51(9):77-81.MIN Liang,SHAO Liang-shan,ZHAO Yong-gang.Community detection based on node similarity[J].Computer Engineering and Applications,2015,51(9):77-81.
[21]冯 健,丁媛媛.基于重叠社区和结构洞度的社会网络结构洞识别算法[J].计算机工程与科学,2016,38(5):898-904.FENG Jian,DING Yuan-yuan.A structural hole identification algorithm in social networks based on overlapping communities and structural hole degree[J].Computer Engineering & Science,2016,38(5):898-904.
[22]Clauset A.Finding local community structure in networks[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2005,72(2):026132.
[23]Feng J,Shi D D,Luo X Y.An identification method for important nodes based on K-shell[J].Journal of Complex Networks,2018,6(3):342-352.
[24]任卓明,刘建国,邵 凤,等.复杂网络中最小K-核节点的传播能力分析[J].物理学报,2013,62(10):466-471.REN Zhuo-ming,LIU Jian-guo,SHAO Feng,et al.Analysis of the spreading influence of the nodes with minimum K-shell value in complex networks[J].Acta Physica Sinica,2013,62(10):466-471.
[25]Burt R.Structural holes and good ideas[J].American Journal of Sociology,2004,110(2):349-399.
