融合主题信息的卷积神经网络文本分类方法研究
2020-04-01杨锐陈伟何涛张敏李蕊伶岳芳
杨锐 陈伟 何涛 张敏 李蕊伶 岳芳


摘 要:[目的/意義]针对能源政策语义信息丰富的特点,研究不同环境下卷积神经网络模型对能源政策文本特征分类识别的效果并提出优化方法,辅助能源政策信息资源进行自动分类操作,方便研究人员更好地进行能源政策解读。[方法/过程]在不同环境下利用字符级和词级卷积神经网络模型对能源政策自动文本分类识别效果进行实验,从标题、内容、核心主题句等角度全面对比分析,利用Doc2Vec抽取不同比例核心主题句,将这些主题信息融入卷积神经网络模型中以对实验进行优化。[结果/结论]随着核心主题句抽取率的提高F1均值呈正态分布,当抽取率为70%时达到平衡,神经网络模型评估F1均值为83.45%,较实验中的其它方法均有所提高,通过Doc2Vec提取主题信息,并将其融入卷积神经网络的方法有效提升了卷积神经网络模型自动文本分类的效果。
关键词:能源政策;卷积神经网络;文本分类;词向量;文本向量
DOI:10.3969/j.issn.1008-0821.2020.04.005
〔中图分类号〕TP391 〔文献标识码〕A 〔文章编号〕1008-0821(2020)04-0042-08
Text Classification Method Based on Convolutional
Neural Network Using Topic Information
Yang Rui1,2 Chen Wei1,2,3 He Tao4 Zhang Min1,2 Li Ruiling1,2 Yue Fang1,2
(1.Wuhan Library,Chinese Academy of Sciences,Wuhan 430074,China;
2.Key Laboratory of Science and Technology of Hubei Province,Wuhan 430074,China;
3.School of Economics and Management,University of Chinese Academy of Sciences,Beijing 100190,China;
4.Department of Information Security,Naval University of Engineering,Wuhan 430033,China)
Abstract:[Purpose/Significance]In view of the rich semantic information of energy policy,this paper studies the effect of convolutional neural network model on energy policy text feature classification and recognition under different environments,and proposes optimization methods to assist the automatic classification operation of energy policy information resources,so as to facilitate researchers to better interpret energy policy.[Method/Process]This paper used character-level and word-level convolution neural network model to test the effect of automatic classification and recognition of energy policy texts in different environments.It made a comprehensive comparative analysis from the perspective of title,content and core topic sentences,and extracted different proportion of core topic sentences by Doc2Vec for optimization experiments.[Result/Conclusion]With the increase of the extraction rate of core topic sentences,the average value of F1 was normal distribution.When the extraction rate is 70%,the balance was reached.The average value of F1 evaluated by the neural network model was 83.45%.Compared with other methods in the experiment,the using of topic information which was extracted with Doc2Vec effectively improved the automatic classification effect of the convolutional neural network model.
Key words:energy policy;CNN;text classification;Word2Vec;Doc2Vec
能源政策是由国家或地区围绕能源的生产、供应和消费而制定的一系列行动纲领或政策规划,多涉及于产品价格、技术装备升级改造、能源战略储备等多个方面。目前国內主流数据库对能源政策的分类体系差异明显,各个体系之间存在一定的扩展和重叠。由于分类体系不统一,研究人员在进行内容解读时,难以进行有效梳理和对比分析。针对以上情况,本文以能源政策文本为出发点,在梳理能源政策文本类型的基础上,将能源政策文本特征与深度学习技术相结合,对基于字符级和词级卷积神经网络模型进行全面的能源政策文本自动分类对比实验和效果评估,并在此基础上提出一种融合主题信息的卷积神经网络文本分类方法。该方法通过对能源政策文本进行句向量构建以抽取主题信息,然后将这些主题信息添加到卷积神经网络的输入之中,从而构建出更为全面的输入特征以提高政策文本的自动分类效果。
1 相关研究
文本分类是指按照已定义好的主题类别,对数据集中的每个文档划分类别,是自然语言处理领域的一个经典课题。传统的机器学习方法进行文本分类通常主要基于向量空间模型(VSM,Vector Space Model)[1]进行,如朴素贝叶斯算法、支持向量机、随机森林[2]等。向量空间模型在文本主题特征化时,更多考虑了词语在空间分布上的特征,即词的前后关系,而忽略了词语在句子或全文中语义上的相关性。2013年谷歌公司公开发表一款用于词向量计算的工具Word2Vec[3],它将词语用向量的方式进行表达,向量的每一个维度都代表了词语的一个特征,解决了VSM模型所生成的特征维度过高、数据稀疏等问题[4]。但当进行长文本处理时,Word2Vec对上下文的语义分析能力仍需要较大提升。2014年谷歌公司的Quoc Le和Tomas Mikolov继续在Word2Vec的基础上提出了Doc2Vec方法[5]。该方法保留了句子中词语的顺序关系,使得每一个词向量都具有了语义,能够更好地处理文本自动分类的问题。随着词向量和文本向量的发展,相关学者和机构逐步开始利用卷积神经网络(CNN,Convolutional Neural Network)在自然语言处理自动文本分类领域进行探索研究[6]。其中在模型优化方面,Kalchbrenner N等基于CNN进行了句子建模的研究[7],通过动态池化方法来构建动态卷积神经网络(DCNN)的结构用于句子的语义建模,误差率减少了25%以上。在算法融合方面,殷亚博等人基于CNN和KNN进行了短文本分类研究[8],实验结果准确率比基于TF-IDF的KNN算法效果有10%以上的提升。腾讯AI Lab联合香港中文大学提出的主题记忆网络将主题模型与文本分类在神经网络框架进行有效融合,利用卷积神经网络作为文本分类器,实验证明该方法显著提升了自动文本分类的性能[9]。在应用研究方面赖文辉等基于CNN和词向量进行了垃圾短信的分类识别应用[10],识别准确率相较于传统模型提高了2.4%~5.1%。
2 研究方法
目前能源政策文本分类通常采用《能源经济学》[11]一书中提出的九大类分类体系标准,即能源开发投资政策、能源工业政策、能源技术装备政策、能源价格税收信贷政策、能源消费政策、能源进出口政策、能源外交政策、新能源政策和能源安全政策。笔者通过对知网、万方以及北大法宝等政策法规数据库的调研发现,能源政策文本数据多以国家、地方和机构的法规、规章以及司法解释为主,一方面各个数据库虽然大多都是从资源类型的角度进行区分,但不同的数据库之间分类标准也存在差异[12],例如,知网的政策分类体系中还包括团体规定、万方的政策分类体系中还包括合同范本以及北大法宝的政策分类体系中还包括行政许可批复等等各不相同;另一方面通过从内容本身的解读来看,各个类别内的政策文本仍然缺乏统一有效的类别梳理,不同类别的政策也存在着一定的重叠。由于这些政策文本范围拓展和内容重叠,导致文本分类特征不明显,如新能源政策中均包含了其他8类政策类别,算法模型难以对传统的9种类型进行有效的判定区分。为了提高文本自动分类的准确度,更好地支撑政策内容分析以及主题识别等文本计算工作,笔者在对各类数据库的政策文本内容进行深度解读后,在传统分类基础上进行了类型归纳合并,从投资开发、技术装备、安全管理和市场消费4个方面对能源政策进行划分,具体包括能源投资开发与建设类政策、能源科技与产业装备类政策、能源安全生产管理类政策和能源市场调节与监管类政策,以此作为研究出发点。
2.1 研究思路
融合主题信息的卷积神经网络文本分类方法,研究思路如图1所示。
首先将获取到的能源政策文本数据集按照4种类型特征进行人工标注并进行预处理,然后将数据集分成测试数据集和验证数据集,对数据集分别从标题、内容以及核心主题句3个方面进行字符级和词级[13]的卷积神经网络训练,利用Doc2Vec文本向量模型进行文本句向量的计算和分析并获取文本的主题句[14],通过不同抽取率进行对比试验。最后对能源政策自动文本分类评估结果进行全面地分析。
2.2 数据收集和预处理
本文利用网络采集技术从相关机构网站采集能源政策文本,然后进行过滤和查重,去掉与能源政策主题无关的冗余信息形成原始语料,对原始语料内容进行清洗,去掉各种与分析内容无关的信息,共计21 054篇原始语料作为样本数据集。按照4种能源政策分类类型,包括能源投资开发与建设类政策、能源科技与产业装备类政策、能源安全生产管理类政策和能源市场调节与监管类政策,对文本进行手工标注,每个类别从政策文本中筛选出4 000篇作为样本数据,在CNN模型定型完成后,再将样本数据输入其中进行测试,评估模型性能。本文采用十折交叉验证法进行CNN模型泛化能力评估,将数据集划分为训练集和测试集,训练集用于模型训练,测试集用于评估模型性能[15]。具体将能源政策样本数据集按照分类平均分成10等份,每次实验抽取9份组成训练集,剩余1份组成测试集,每次实验训练集数据为14 400个,测试集数据为1 600个,最后得到卷积神经网络分类器性能指标,取10次实验结果的均值进行评估。
2.3 理论模型
实验采用的模型均为基于神经网络结构为基础的数学模型。
2.3.1 词向量模型
Word2Vec是一種浅层神经网络模型。Word2Vec的网络结构分为CBOW和SkipGram两种方式[16-17]。其中SkipGram根据滑动窗口中的当前词来预测上下文中各个词的生成概率。SkipGram的网络结构主要包括输入层、隐含层以及输出层,如图2所示。
输入层中通过One-hot编码将所有的词表示成多维向量,在输出层中向量值通过隐含层以及连接隐含层和输出层之间的权重矩阵计算得到,最后输出层应用Softmax激活函数计算每一个词的出现概率[18]。Softmax函数定义为:
P(y=wn|x)=exn∑Nk=1exk
其中x表示N维输出向量,xn表示输出向量中与词wn对应的值。
在实验中进行词向量训练的基本参数包括网络结构SkipGram、词向量维度300、训练的窗口大小5以及循环迭代次数100等。
2.3.2 主题信息提取
本文采用句向量模型来对主题信息进行提取。Word2Vec基于词向量进行语义分析,但是并不具有上下文的语义分析能力。该模型可以获得句子/段落/文本的向量表达,通过计算距离找到句子/段落/文本之间的相似性,该模型的网络结构分为PV-DM和PV-DBOW两种方式[19]。其中PV-DBOW和Word2Vec的SkipGram相似,如图3所示。
PV-DBOW忽略输入的上下文,在每次迭代的时候,从文本中抽取得到一个窗口,再从这个窗口中随机采样一个词作为预测任务让模型预测。通过生成的文本向量计算句子向量的余弦相似度,最终实现主题句的抽取。使用的余弦相似度公式为:
cos(θ)=∑ni=1(xi×yi)∑n=1(xi)2×∑ni=1(yi)2
在实验中进行文本向量训练的基本参数包括网络结构PV-DBOW、句向量维度300、训练的窗口大小5以及循环迭代次数30等。
2.3.3 卷积神经网络
CNN模型包括输入层、隐含层以及输出层,利用梯度下降法最小化损失函数对权重参数逐层反向调节[20],通过迭代训练来提高模型分类效果。本文设计的CNN模型如图4所示。
1)输入层设计:在利用卷积神经网络进行训练过程中由于使用梯度下降方法来进行学习,卷积神经网络的输入特征需要在输入层进行标准化处理。处理过程中将文本中经过分词处理以后的词对应的词向量依次排列形成特征矩阵作为输入数据传入卷积神经网络进行训练。每个词向量存储在利用SkipGram网络结构提前训练好的词向量模型中,假设文本中有n个词,每个词向量维度为v,那么这个特征矩阵就是n*v的二维矩阵。
2)卷积层设计:通过内部包含的卷积核进行特征提取,特征提取的计算方法为[21]:
Si=f(Ch*v*Ti∶i+h-1+b)
其中Ch*v为卷积核,行数h为卷积核窗口大小,列数v为词向量维度,T为文本特征矩阵,每个卷积核会依次与h行v列的特征矩阵做卷积操作,b为偏置量。f为神经元激活函数,在训练过
程中为了防止神经元特征信息丢失以及克服梯度消失问题,设计中采用LeakyReLU方法[22]作为激活函数:
f(x)=max(0,x)+γmin(0,x)为固定较小常数
通过卷积核特征提取后得到特征图:
S=[S1,S2,…,Sm-h+1]
在卷积层的设计过程中,考虑到一个卷积核提取特征存在不充分性的问题,在卷积层中包含了C3*300、C4*300以C5*3003种不同大小的卷积核,每个卷积核的操作模式设置为相同,每种特征图各提取出100张。最终在卷积层的输出端得到共300张特征图。
3)池化层设计:在卷积层进行特征提取后,由于特征图的维度还是很高,因此需要将特征图传递至池化层通过池化函数进行特征选择和信息过滤。通过池化函数将特征图中单个点的结果替换为其相邻区域的特征图统计量,池化过程与卷积层扫描特征图的过程相同[23]。在实验中采用最大池化函数(MaxPooling)对卷积核获取的特征保留最大值同时放弃其它特征值。
4)全连接层设计:对提取的特征进行非线性组合得到输出,全连接层本身不具有特征提取能力,主要用来整合池化层中具有类别区分性的特征信息,在实验中采用LeakyReLU函数[24]作为全连接层神经元的激励函数。
5)输出层设计:使用多类交叉熵函数(Multiclass Cross Entropy)作为损失函数以及归一化指数函数(Softmax)[25]作为激活函数输出特征分类标签,完成文本分类任务。
2.4 评价指标
对于分类器性能优劣判断指标采用F值,F值能够较好反映神经网络在训练过程中的表现,它是精确率和召回率的加权调和平均值[26],计算公式为:
F=(α2+1)*P*Rα2*(P+R)
式中:P为精确率(Precision)、R为召回率(Recall)、α为权重因子。
P表示对于给定测试集的一个分类,分类模型正确判断为该类的样本数与分类模型判断属于该类的总样本数之比。
R召回率的定义为:对于给定测试集的一个分类,分类模型预测正确判断为该类的样本数与属于该类的总样本数之比。
当α=1时,F值是F1值,表示精确率和召回率的权重一样,是最常用的一种评价指标,F1值越高,分类效果越好。F1的计算公式为:
F1=2*P*RP+R
在对比各组实验的分类效果时,以CNN模型在政策文本分类上的F1值作为判断标准。
3 实验过程
3.1 实验环境配置
3.2 实验设计
为了验证主题信息对CNN文本分类效果的影响,设计了4组实验与融合主题信息的CNN文本分类方法进行比较,在实验过程中CNN超参数的设置如表2所示。
实验1:采用北京师范大学中文信息处理研究所构建的开放中文语言向量资源,考虑到能源政策文本内容的语义环境和人民日报有一定的相似性,选取其中的1946-2017年的人民日报词向量语料库做为Word2Vec训练好的模型实例,分别以字符级的标题和全文作为训练集和测试集,评估采用大规模词向量语料库对字符级CNN自动分类模型的性能影响。
实验2:在实验1里面的词向量语料库,使用了不同的字符以及词等上下文特征的中文词向量嵌入训练,因此采用相同的词向量语料库,以词级的标题和全文作为训练集和测试集,评估采用大规模词向量语料库对词级CNN自动分类模型的性能影响。
实验3:采用16 000篇能源领域政策文本内容作为语料生成Word2Vec词向量,采用SkipGram网络结构进行训练,分别以字符级的标题和全文作为训练集和测试集,评估采用自训练的词向量模型对字符级CNN自动分类模型的性能影响。
实验4:与实验3一样采用自训练词向量模型,以词级的标题和全文作为训练集和测试集,评估采用自训练的词向量模型对词级CNN自动分类模型的性能影响。
实验5:在前面4个实验的基础上利用Doc2Vec进行数据集文本向量模型训练,以文本标题为核心主题句利用文本向量相似度计算的方法提取与标题相似度最高的主题句放入卷积神经网络进行训练,评估介于标题和全文之间的核心主题内容对CNN自动分类模型的性能影响。
3.3 实验结果
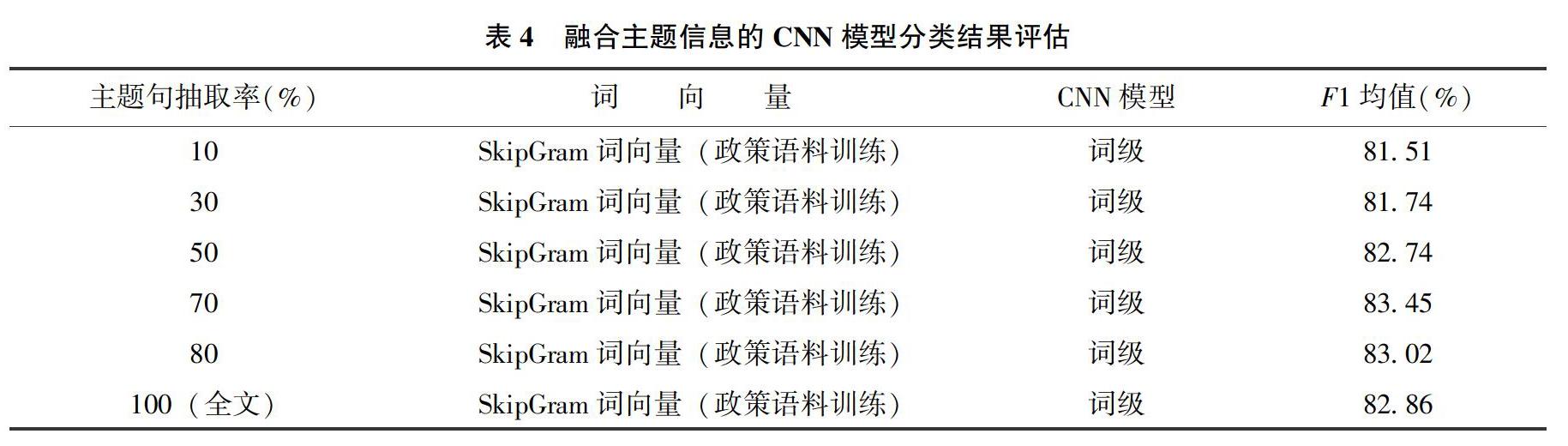
实验结果如表3、表4所示。
4 结果分析
在实验过程中,通过对能源政策文本的解读,发现对于有些文本存在内容属于多个分类的问题,在数据集人工标注过程中产生了一定的偏差,直接影响到CNN模型的分类效果,针对以上实验结果排除这些影响并在相同的迭代次数下进行分析。
4.1 字符级和词级CNN模型
从表3实验结果来看,不管是采用自训练的词向量语料还是开放的大规模词向量语料,词级CNN模型整体好于字符级CNN模型,F1均值提升范围约1%~3%。字符级和词级语言模型的区别在
于字符级或者词级的文本信息作为CNN模型的最小处理单元。对于能源政策文本通常具备较强的行文规范以及上下文之间具备较强的语义关系,从语义空间的角度,词级语言模型能够更好地表达文本中的语法和上下文语义关系,然后能够基于CNN模型去进一步放大词向量的语义表达能力,而字符级语言模型以单个字符进行处理时丢弃了词所具备的语义信息,因此对于能源政策文本采用词级CNN模型能够达到更好的分类效果[27]。另一方面实验观察到从全文的角度采用自定义词向量的词级CNN模型使用特定领域内的语料进行训练,对同领域的文本分类效果有一定的提升,但当语料扩大到100M以上时,词级CNN模型的分类效果差异较小,为0.22%。
4.2 标题和全文作为数据集
从表3实验结果来看,在字符级CNN模型分类效果上,采用标题作为数据集好于采用全文作为数据集,F1均值提升了0.58%和0.61%,在词级CNN模型分类效果上,采用全文作为数据集好于采用标题作为数据集,F1均值提升了1.82%和0.86%。对于第一种情况采用字符级CNN模型,缺乏对于能源政策文本语义特征描述,但是从标题的角度,是对能源政策文本内容的高度概括,标题作为短文本具备明显的主题性在一定程度上弥补了CNN模型训练特征不足的问题,因此分类效果好于全文。另一方面采用词级CNN模型时,全文所包含的语义特征高于标题所表达的语义特征,通过CNN模型的特征学习能力更容易产生好的分类效果。
4.3 基于Doc2Vec不同的主题句抽取率
抽取率為能源政策文本中主题句占该文本全部句子的比例。从表4的5个实验结果来看,以表3的表现最好的第四个实验作为基准线进行测试,主题句抽取率从10%逐步提升到100%,能源政策文本分类效果呈现出逐步上升随后下降的正态分布趋势,在抽取率为70%的时候,F1均值为83.45%,达到最高。利用Doc2Vec模型计算每个句子与标题的相似度,从高到低进行排序和抽取,相似度较高的句子包含更多的主题特征词,相似度较低的句子包含更多的冗余信息[28],为了使得CNN模型的性能最大化,需要采用与其分类特点相匹配的更多的特征词进行迭代训练来达到较好的收敛效果。因此主题的特征词信息和冗余信息的比例对CNN模型的分类效果产生一定的影响,该实验在70%的时候抽取比例达到平衡,使得分类效果最佳。
5 结 语
本文结合能源政策文本以卷积神经网络为基础进行了全面的自动分类模型对比分析,并提出了一种融合主题信息的卷积神经网络文本分类方法。该方法在能源政策文本自动分类任务评估上F1均值达到83.45%,较实验中的其它CNN分类模型均有所提高。在后续的工作中将更深入的研究影响模型性能的因素,并且将研究成果应用到相关工作中以提供业务服务。
参考文献
[1]白璐.基于卷积神经网络的文本分类器的设计与实现[D].北京:北京交通大学,2018.
[2]王星峰.基于CNN和LSTM的智能文本分类[J].辽东学院学报:自然科学版,2019,26(2):126-132.
[3]Kim Y.Convolutional Neural Networks for Sentence Classification[J].Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP 2014),2014:1746-1751.
[4]Johnson R,Zhang T.Effective Use of Word Order for Text Categorization with Convolutional Neural Networks[J].To Appear:NAACL-2015,2015.
[5]Nguyen T H,Grishman R.Relation Extraction:Perspective from Convolutional Neural Networks[J].Workshop on Vector Modeling for NLP,2015:39-48.
[6]Santos C N dos,Gatti M.Deep Convolutional Neural Networksfor Sentiment Analysis of Short Texts[J].In COLING-2014,2014:69-78.
[7]Kalchbrenner N,Grefenstette E,Blunsom P.A Convolutional NeuralNetwork for Modelling Sentences[J].Acl,2014:655-665.
[8]殷亚博,杨文忠,杨慧婷,等.基于卷积神经网络和KNN的短文本分类算法研究[J].计算机工程,2018,44(7):193-198.
[9]Zeng J,Li J,Song Y,et al.Topic Memory Networks for Short Text Classification[J].2018.
[10]赖文辉,乔宇鹏.基于词向量和卷积神经网络的垃圾短信识别方法[J].计算机应用,2018,38(9):2469-2476.
[11]周冬.能源经济学[M].北京:北京大学出版社,2015.
[12]杨卫东,庞昌伟.中国能源政策目标及协调战略分析[J].人民论坛·学术前沿,2018,(5):62-66.
[13]刘敬学,孟凡荣,周勇,等.字符级卷积神经网络短文本分类算法[J].计算机工程与应用,2019,55(5):135-142.
[14]齐凯凡.基于卷积神经网络的新闻文本分类问题研究[D].西安:西安理工大学,2018.
[15]张小川,余林峰,桑瑞婷,等.融合CNN和LDA的短文本分类研究[J].软件工程,2018,21(6):17-21.
[16]Zhang Y,Wallace B.A Sensitivity Analysis of(and Practitioners Guide to)Convolutional Neural Networks for Sentence Classification[J].2015.
[17]李林.基于Word2vec和卷积神经网络的文本分类研究[D].重庆:西南大学,2018.
[18]Johnson R,Zhang T.Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding[J].2015.
[19]Sun Y,Lin L,Tang D,et al.Modeling Mention,Context and Entity with Neural Networks for Entity Disambiguation,(Ijcai)[J].2015:1333-1339.
[20]Wang P,Xu J,Xu B,et al.Semantic Clustering and Convolutional Neural Network for Short Text Categorization[J].Proceedings ACL 2015,2015:352-357.
[21]孙璇.基于卷积神经网络的文本分类方法研究[D].上海:上海师范大学,2018.
[22]卢玲,杨武,杨有俊,等.结合语义扩展和卷积神经网络的中文短文本分类方法[J].计算机应用,2017,37(12):3498-3503.
[23]Shen Y,He X,Gao J,et al.A Latent Semantic Model withConvolutional-Pooling Structure for Information Retrieval[J].Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management-CIKM 14,2014:101-110.
[24]余本功,张连彬.基于CP-CNN的中文短文本分類研究[J].计算机应用研究,2018,35(4):1001-1004.
[25]夏从零,钱涛,姬东鸿.基于事件卷积特征的新闻文本分类[J].计算机应用研究,2017,34(4):991-994.
[26]苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,(9):1848-1859.
[27]Zeng D,Liu K,Lai S,et al.Relation Classification via Convolutional Deep Neural Network[J].Coling,2014:2335-2344.
[28]Weston J,Adams K.# T AG S PACE:Semantic Embeddings from Hashtags[J].2014:1822-1827.
(责任编辑:郭沫含)
