城市画像视角下的热点城市特征识别方法研究
2020-04-01毕崇武叶光辉胡婧岚李明倩
毕崇武 叶光辉 胡婧岚 李明倩

摘 要:[目的/意义]旨在识别某段时间内公众高度关注的热点城市特征,便于分析公众对城市的整体印象及其动态变化。[方法/过程]首先分析了热点城市特征的评价指标及其数据来源和计算方法;然后利用min-max标准化方法将评价指标归一化处理,进而采用线性加权和法构造综合指标评价模型;最后基于“知乎”平台中的用户问答数据,识别出不同时期我国中部六省省会城市的热点城市特征。[结果/结论]文中方法能够从海量用户问答数据中获取不同城市在不同时间内的热点城市特征,具有实际的可操作性。
关键词:城市画像;城市特征;舆情热点;特征识别; 知乎;武汉;长沙;郑州;南昌;太原;合肥
DOI:10.3969/j.issn.1008-0821.2020.04.002
〔中图分类号〕G254.91 〔文献标识码〕A 〔文章编号〕1008-0821(2020)04-0013-10
Research on Discovery of the Focus of City Identity from the
Perspective of City Profile
Bi Chongwu Ye Guanghui* Hu Jinglan Li Mingqian
(School of Information Management,Central China Normal University,Wuhan 430079,China)
Abstract:[Purpose/Significance]The research aimed to discover the focus of city identity in a period of time,and to analyze the publics overall impression of city and its dynamic changes.[Method/Process]Firstly,this paper proposed evaluation index,data source and calculation method for discovery of the focus of city identity.Secondly,it normalized the evaluation index by min-max normalization,and established evaluation model to calculate different cities identities by linear weighted sum method.Finally,it discovered the focus of city identity of the six central China provincial capitals in different periods,based on the Q&A data from“Zhihu”platform.[Result/Conclusion]It was operable to use the method in this paper to discover the focus of city identity in a period of time from the massive Q&A data.
Key words:city profile;city identity;public opinion hotspots;feature recognition;Zhihu platform;Wuhan;Changsha;Zhengzhou;Nanchang;Taiyuan;Hefei
智慧城市建设中的网络舆情监测一直受到社会各界关注。充分发挥现代信息技术的优势,感测、分析、整合城市的各项关键信息,真实、客观、完整、及时地获取城市网络舆情是政府部门做出合理决策的基础。城市画像是公众对城市特征的认知、评价和情感的综合体现。早在20世纪60年代,Lynch K就依据市民的心理形象衡量城市的视觉质量,并由此引出了城市画像的概念[1]。这种由公众依据自我认知形成的共同记忆,就像城市的一张名片,能够在一定程度上反映城市的个性与特征,展现城市形象与内涵,对城市规划管理、城市特色塑造、城市文化传承等方面具有重要意义。随着数据科学的发展,学者们逐步意识到网络数据为实现洞见城市运行情况的目标提供了可行途径,并围绕以数据为中心的城市画像研究展开了多层次、多视角、多方位的理论与技术探索[2-4]。而社交网络中的用户问答数据作为新媒体时代孕育的载体,承载了公众心中最直观且感性的城市画像,蕴含了公眾视角下某段时期内城市发展的主要特征,体现了公众对城市特征的综合印象。由此,本文从城市画像视角出发,借鉴突发主题识别技术中的爆发词检测方法,定义标签关注度、标签新颖度和标签创新度3个指标构建综合指标评价模型,以求从社交网络中的用户问答数据中识别某段时间内被社会各界广泛关注、具有较大影响力且近期未被重点关注的热点城市特征。文中方法的实施有利于提高城市全面感知、分析和利用城市画像的能力,诊断城市当前面临的突出问题和主要矛盾,辅助政府部门智能响应公共安全、城市服务和商业活动等各方面的社会需求。
1 研究现状
城市作为一个相对独立的社会系统,包含成千上万个变量。城市的政治、经济、文化和生态等因素均会对城市特征产生影响。目前城市特征研究侧重于关注城市空间特征,重视空间结构对城市特征造成的影响,通常构建研究体系探索热点空间特征的内在形成机理及其与居民活动间的互动关系;并在理论性阐述热点空间特征起源和延续原因的同时,通过实证研究分析政治、经济和文化等非物质因素对城市特征造成的影响[5]。在数据获取方面,现有研究大多采用主观性较强的问卷调查[6]、深度访谈[7]和意向草图[8-9]等社会学调查方法;在数据分析方面,现有研究也多沿袭数理统计、认知地图[10-11]和空间分析[12]等旅游学研究方法。事实上在收集、处理和分析主观性数据的过程中,传统旅游学研究方法的不足和局限逐渐显现。难以回收大量有效数据、收集数据包含大量噪声(调查对象理解偏差或填写虚假信息)、处理非线性数据困难等诸多问题均会给实证分析结果带来偏差甚至错误,并最终影响实证研究所获结论的可靠性[13]。
社交网络中描述城市特征的用户问答数据蕴含着公众的态度和认知。它们不仅相对客观,能够在一定程度上避免上述问题;而且可以利用突发主题识别技术直接获取不同城市的热点城市特征。事实上,突发主题识别在众多基于文本挖掘的社交网络研究中具有重要应用。学术界对突发主题识别研究起源于热点话题的检测与追踪(Topic Detection and Tracking,TDT)技术。该技术与数据挖掘、信息检索等自然语言处理技术间有很多共性,最初应用于监控具有突发和延续性规律的新闻语料,后来逐渐成为信息处理领域的研究热点。目前主要研究方法包括:1)在语义相似度计算和聚类分析的基础上,通过自动分类话题文本发现热点话题的向量空间方法[14-15];2)在词频统计和权重计算的基础上,挖掘热点话题的统计语言模型[16-18];3)在构建网络链接及分析的基础上,通过转移概率和转移矩阵探究话题演变的图论方法[19-20];4)混合使用以上方法,通过归纳、总结热点话题的主要特征,实现组织处理这些特征的突发检测方法[21-23]。
在众多研究之中,正确识别并处理文本中的爆发词是所有关于突发主题识别研究的基础性工作,对突发主题探测及其趋势监测具有重大影响。目前关于爆发词识别的相关研究主要是基于词语的科技监测方法,可将其总结、归纳为基于数理统计的词频分析方法、基于词组网络关系的共词分析方法、基于词频变化率的突发监测方法和基于语义相似度的内容分析方法[24]。其中,在词语集合中区分爆发词与非爆发词的研究重点并非仅仅停留在统计层面的词语聚类和分类技术上,而是逐渐向词语间的语义关系和上下文语境延伸。此外,随着通用本体与领域本体的日渐成熟,文本语义相似度研究也日臻完善,由此产生了一系列比较有代表性的理论、技术和方法,其研究成果集中在概念、语句和文档3种不同文本粒度的语义相似度计算上。与此同时,诸多学者将语义相似度研究应用于信息提取、词义消歧、语义计算、文本聚类和文本分类等自然语言处理领域,并进一步将其引入到爆发词的特征识别、时段识别、语义合并和关联映射等方面研究,从而使关于爆发词识别的相关研究更加成熟和完善[25]。
2 热点城市特征识别方法
2.1 热点城市特征特点分析
本文经过梳理现有爆发词检测方法后,对描述热点城市特征的载体——标签的特点归纳、总结为:在标注频次上具有较高的关注度、在标注时间上具有一定的新颖性、在标注内容上具有潜在的创新性。具体而言,本文认为城市画像视角下的热点城市特征应该同时满足如下条件:
1)描述某座城市热点城市特征的标签是公众广泛认可的,具有较高的标注频次,即公众对标签描述的城市特征具有较高的社会关注度;
2)描述某座城市热点城市特征的标签出现时间较晚,在当前或某段时间内受到公众广泛关注,即标签描述的城市特征具有一定的时间新颖性;
3)描述某座城市热点城市特征的标签与描述该座城市已有标签在内容层面上有所差异,现有标签和已有标签间的文本语义相似程度较小,即现有标签描述的城市特征具有潜在的语义创新性。
基于以上分析,本文从标签的标注热度、标注时间和标注内容3个维度刻画城市画像视角下的热点城市特征。其中,标注热度和标注时间分别对应热点评价指标中的标签关注度和标签新颖度,可以看作是从数理统计层面刻画的热点城市特征;而标注内容对应评价指标中的標签创新度,可以看作是从文本语义层面刻画的热点城市特征。由此,本文依据热点城市特征这3个主要特点定义热点城市特征的评价指标,并采用线性加权和法构造综合指标评价模型,以此获取不同段时间内不同城市的热点城市特征。
2.2 热点城市特征评价指标
本文根据热点城市特征评价指标的数据来源范围,将其划分为外部属性评价指标和内部属性评价指标。外部属性评价指标是指可以直接采用数理统计方法获取实证数据的标签关注度和标签新颖度,其实证数据从标签的标注频次、标注时间等数据中获得。内部属性评价指标是指需要通过挖掘标签文本内容获取实证数据的标签创新度,其实证数据从标签间文本语义相似度的计算结果中获得。由此,本文在考虑城市画像的刻画方式其现实意义的基础上,将热点城市特征评价指标的特征属性、数据来源及其计算方法总结如表1所示。
2.2.1 标签关注度
标签的标注频次蕴含了公众对其描述城市特征的认可程度。热点城市特征具有较高公众关注度这一特点可以通过描述该城市特征的标签的标注频次反映出来。由于不同标签解释城市特征的能力有所差异,因此衡量某一城市特征是否具有较高公众关注度时,若仅对描述该城市特征的标签进行简单的词频统计,会导致大量标注频次较高但解释城市特征能力较弱的标签获得较高的标签关注度。本文在依据标签标注频次的基础上,融入TF-IDF算法衡量不同标签对城市特征的解释能力,将TF理解为标签对某座城市的标注次数,将IDF理解为标签对不同城市的区别程度,其计算步骤如下:
首先,采用中文分词技术将每个标签Ta切分为n个相互独立的词组,并对这些词组进行数据预处理,以Ta=(t1,t2,…,tn)表示;
然后,采用空间向量模型将Ta表示为:VTa=(t1·wt1,t2·wt2,…,tn·wtn),并依据TF-IDF算法计算词组ti在不同向量空间VTa中的权重wti;
最后,将权重wti作为衡量标签Ta在解释城市特征能力方面的重要指标,并定义标签关注度TATa,Citya的计算方法为:
TATa,Citya=1n∑ni=1wti=1n∑ni=1logfti·log(N/nti+1)(1)
其中,fti表示词组ti标注城市Citya的频率;N表示标签集合中所有词组的总数;n表示标签Ta中词组ti的数量;nti表示词组在标签集合中出现的次数。由此可见,城市Citya中某城市特征的关注程度既和标签Ta标注城市Citya的次数成正比,又和标签Ta解释城市Citya的能力成正比。若描述某城市特征的标签Ta具有较高的标注频次,并且能够较好地区分不同城市间的城市特征,则说明这个城市特征具有较高的关注程度,即TATa,Citya值较高。
2.2.2 标签新颖度
热点城市特征会随着时间推移发生变化。公众会逐渐遗忘城市过去的历史特征,反复记忆城市持续的核心特征,不断注入城市突发的实时特征。事实上,描述城市特征的标签既可将其看作是网络信息资源的一种索引或元数据,又可将其看作是一种特殊的网络信息资源。从网络信息资源老化的角度来说,公众会逐渐减少对以往标签的标注行为,并逐渐增加对新兴标签的标注行为。因此,标签的标注时间应作为判断其描述的城市特征是否是热点城市特征的一项重要依据。
本文通过定义标签新颖度来揭示热点城市特征在时间维度上的重要特性。由于标签由若干个相互独立的词组组成,因此标签的新颖程度可以依据它包含词组的平均标引时间来衡量。在某段时间内,平均标引时间越晚的标签其新颖程度值越大,说明这些标签描述的城市特征出现时间较晚,比较可能成为其描述城市在这段时间内的热点城市特征。反之,说明这些标签描述的城市特征不太可能成为其描述城市在这段时间内的热点城市特征。由此,本文定义标签新颖度TNTa,Citya的计算方法为:
TNTa,Citya=DTan=1n∑ni=1Dtinti(2)
其中,DTa表示标签Ta中所有词组的总标引时间;Dti表示标签Ta中词组ti在标签集合中的总标引时间;n表示标签Ta中所有词组的数量;nti表示词组ti在标签集合中的出现次数。
2.2.3 标签创新度
从城市画像视角看,热点城市特征是公众在某段时间内对城市当前拥有的某些特征标注了大量标签的结果,即这段时间内描述城市特征的社会化标注系统中出现了一些新兴的标签主题。本团队在以往的研究中发现:社会化标注系统中形成新主题的标签可能是新标签,也可能是旧标签[26]。因此,描述热点城市特征的标签既可以是被公众高频次标注的旧标签,即标签关注度较高;又可以是与旧标签相比在文本内容和语义层面上有所差异的新标签,即标签创新度较高。旧标签揭示了以往出现过,但在过去一段时间内未成为公众关注热点的城市特征;新标签揭示了仅在近期出现,且短时间内迅速被公众广泛关注的新兴城市特征。由此可见,热点城市特征识别不仅需要考虑标签标注频次,还需要依据文本语义相似度计算方法,测算当前标签与已有城市特征间的语义相似度,以此补充并完善热点城市特征测度方法。
本文利用文本语义相似度计算方法计算标签的创新程度。首先,运用分词技术提取标签中包含的概念词,并采用空间向量模型表示其描述的城市特征。若标签Ta中包含XTa个概念词,则用Ta∈{Sa1,Sa2,…,Sax}表示;若城市Citya的城市特征Cb中包含YCb个概念词,则用Cb∈{Sb1,Sb2,…,Sby}表示。然后,通过计算空间向量间的余弦相似度cos(Ta,Cb)获得每个标签Ta和M个城市特征Cb间的文本语义相似度Sim(Ta,Cb),并定义标签创新度HITa,Citya的计算方法为:
TITa,Citya=1M∑Mb=1Sim(Ta,Cb)=1M∑Mb=1cos(Ta,Cb)(3)
由此,如果某座城市当前被标记的标签与以往城市特征间的文本语义相似度较小,则说明该城市当前拥有的城市特征与先前拥有的城市特征在语义含义方面差距较大,从而揭示出当前城市特征与以往城市特征相比在文本内容和语义层面上具有创新性。
2.3 热点城市特征识别过程
本文首先采用min-max標准化(Min-max Normalization)方法,将具有不同量级和不同方向的评价指标进行数据标准化处理;然后根据上文所述的热点城市特征评价指标,采用线性加权和法(Linear Weighted Sum Method)构造综合指标评价模型;最后依次计算各个城市特征的综合评价指数,以获取不同城市在某段时间内的热点城市特征。
2.3.1 指标数据标准化
标签关注度和新颖度是正向指标,其计算值越大表示标签所描述的城市特征越有可能成为热点特征;然而标签创新度是逆向指标,其计算值越小表示标签所描述的城市特征越有可能成为热点特征。因此,本文需要采用不同的数据标准化处理方法使这两种指标在因变量方向上保持一致。
2.3.2 综合指标评价模型构建
本文通过对标签关注度、标签新颖度和标签创新度3个评价指标进行线性加权求和,构造出识别热点城市特征的综合指标评价模型,如式(4)所示,依据其计算结果可以判别各标签描述的城市特征是否是对应城市的热点城市特征。
WTa,Citya=aTATa,Citya+bTNTa,Citya+cTITa,Citya(4)
其中,TATa,Citya、TNTa,Citya和TITa,Citya分别表示描述城市Citya的标签Ta在标签关注度、标签新颖度和标签创新度的计算结果;WTa,Citya表示标签Ta描述的城市特征的综合指标评价数值;a、b和c均表示指标权重,且a+b+c=1。
2.3.3 评价指标权重计算
为确保综合指标评价模型的可推广性,本文选取不同指标权重对上述模型进行多次计算,依据计算结果确定各评价指标的最终权重,其具体步骤如下:
首先,平均赋予标签关注度、标签新颖度和标签创新度这3个评价指标初始权重,即将每个评价指标的初始权重均设定为1/3;
然后,不断改变各评价指标的计算权重,以人工遴选出的最优计算结果为目标,通过对比实际计算结果进行调整与验证,以此确定各指标最终权重,达到最优的热点城市特征识别效果。
2.3.4 热点城市特征获取
热点城市特征识别过程实际上是从描述城市特征的标签中挖掘不同城市在某段时间内的主要特征,并进一步判断这些城市特征是否是在该段时间内被公众广泛关注。本文依据综合指标评价模型可以计算某段时间内城市Citya拥有的所有标签Ta对应的综合指标评价数值WTa,Citya,进而采用降序排列和设置阈值区间等数据处理、分析步骤筛选出获得较高数WTa,Citya值的标签。这些标签描述的城市Citya特征就是城市在这段时间内拥有的热点城市特征。
3 实证研究
本文利用网络爬虫技术抓取“知乎”平台中关于我国中部六省省会城市(武汉、长沙、郑州、南昌、太原、合肥)主要特征的用户问答数据,具体包括“××是一个怎样的城市?”、“关于××,你印象最深的是什么?”、“××有什么好玩的地方?”等问题。原始数据中包括了用户回答内容、用户昵称、评论内容、创立时间、点赞数、评论数、所属问题等字段,共计21 247条记录,时间范围为2011年6月10日至2019年1月4日。本团队选取5名硕士研究生从原始数据中人工抽取用户描述城市画像的标签,为规范标签标注格式及质量,满足热点城市特征识别过程中的数据处理要求,将标签结构定义为“属性词+特征词”。在人工抽取标签前,本团队以“武汉”数据为例,对5名同学进行培训,确保其可以按照相关流程,以相对规范的操作流程从城市描述文本中抽取结构化标签。此外,本团队为排除个人因素,将所有城市的用户问答数据汇总并随机分配给每位同学,以此确保每座城市的城市画像均被5名同学标记。
3.1 数据准备
3.1.1 数據预处理
人工抽取标签依然具有模糊性(如同义词、多义词等)、多样性(缩写、简写、词形多样等)等问题。本文通过定义标签清洗规则清洗标签,获得具有更高数据质量的标签集合,具体包括:1)删除与目标城市特征无关的标签数据;2)删除重复评论产生的标签,只存取其中一条标签数据;3)改正标签中的错别字,将相同标签数据进行汇总。
此外,为满足热点城市特征识别过程中的数据处理要求,本文将数据清洗后的标签按时间先后顺序排序,并设置“序号”字段作为主键,使之成为标签的唯一标识字段;定义“时间轴”字段简化时间方面的相关计算,以2011年6月10日作为起始时间,将其取值设置为0,并按时间天数递增获得所有标签在“时间轴”字段下的数值。为获取不同城市在各时间段内热点城市特征的变化情况,本文最终将所有数据分割为8个时间段,详见表2。
3.1.2 分词词库获取
在搜狗细胞词库(https://pinyin.sogou.com/dict/)——“××市城市信息精选”词库中获取搜狗官方网站推荐的我国中部六省省会城市的细分化词库。这些词库包含了我国中部六省省会城市关于地名、公交、购物、餐饮等各种信息,有助于提升标签的自动分词效果。
3.1.3 停用词表创建
根据分词词库对标签进行分词,并统计分词结果中各词组词频,通过对比标签记录表与词频统计表更新常用停用词表,以此获得自建停用词表。
3.2 评价指标计算
3.2.1 标签关注度计算
首先,利用分词词库和自建停用词表对标签进行自动分词,并删除去停用词后为空的记录。然后,依据自动分词结果统计各词组词频,获得词频表,词频合计为N。针对某时间段下的标签Ta,可按词组ti查询词频表获得nti;nti除以该时间段下的标签总数可得该词组的fti。最后,依据公式计算TATa,Citya,详见表3。
3.2.2 标签新颖度计算
首先,依据“时间轴”字段和自动分词结果抽取每个词组的所有出现时间,并计算词组平均标记时间。然后,针对某时间段下的标签Ta,按词组ti查询平均标记时间表计算标签Ta的平均标记时间获得Dti/nti;最后,从自动分词后获得的数据表中抽取标签Ta含有词组ti的数量n,按公式计算TATa,Citya,详见表4。
3.2.3 标签创新度计算
计算标签创新度时需要比较两个相邻时间段的标签,即某时间段下标签Ta与前一时间段下标签Cb间的文本语义相似度。因此,TIME1时间段下所有标签的创新度均无法计算(设置为0)。获得标签Ta与前一时间段下所有标签的文本语义相似度后,通过求和并除以前一时间段下标签总数的方式,可求得各时间段下标签的标签创新度,详见表5。
3.3 热点城市特征识别
3.3.1 指标数据标准化
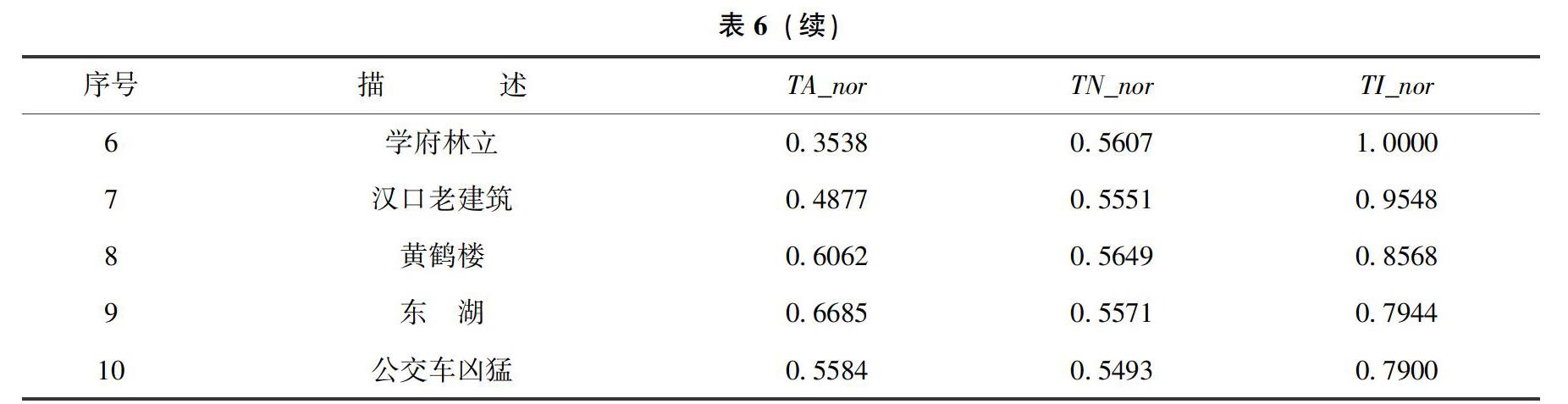
本文采用min-max标准化方法将具有不同量级和不同方向的评价指标归一化处理。正向指标的数据处理方法为Y=(X-X_min)/(X_max-X_min),逆向指标的数据处理方法为Y=(X_max-X)/(X_max-X_min)。其中,Y表示指标的标准化值,X表示指标的原始值,X_max与X_min分别表示指标原始值中的最大值和最小值,详见表6。
3.3.2 评价指标权重确定
本文以不同时间段内网络用户对不同城市的整体评价为参照对象,通过对比分析确定综合指标评价模型是否获得了符合实际情况的热点城市特征。在实证研究过程中,标签关注度指标和标签新颖度指标对识别热点城市特征的作用程度更为突出,因此在综合指标评价模型中可以设定较大权重。其中,标签新颖度指标由于受标签集合所处的时间阶段影响,其作用程度次于标签关注度指标。标签创新度指标虽然对识别热点城市特征具有一定作用,但不是最重要的考虑因素,且实际操作过程中受标签的自然语言处理结果(人工标记结果和自动分词结果)影响较大,因此在综合指标评价模型中可以适当调低权重。本文最终将评价指标权重设定为标签关注度权重0.45,标签新颖度权重0.35,标签创新度权重0.2,并由此获得完整的综合指标评价模型:
WTa,Citya=0.45TATa,Citya+0.35TNTa,Citya+0.2TITa,Citya(5)
3.3.3 结果分析与解读
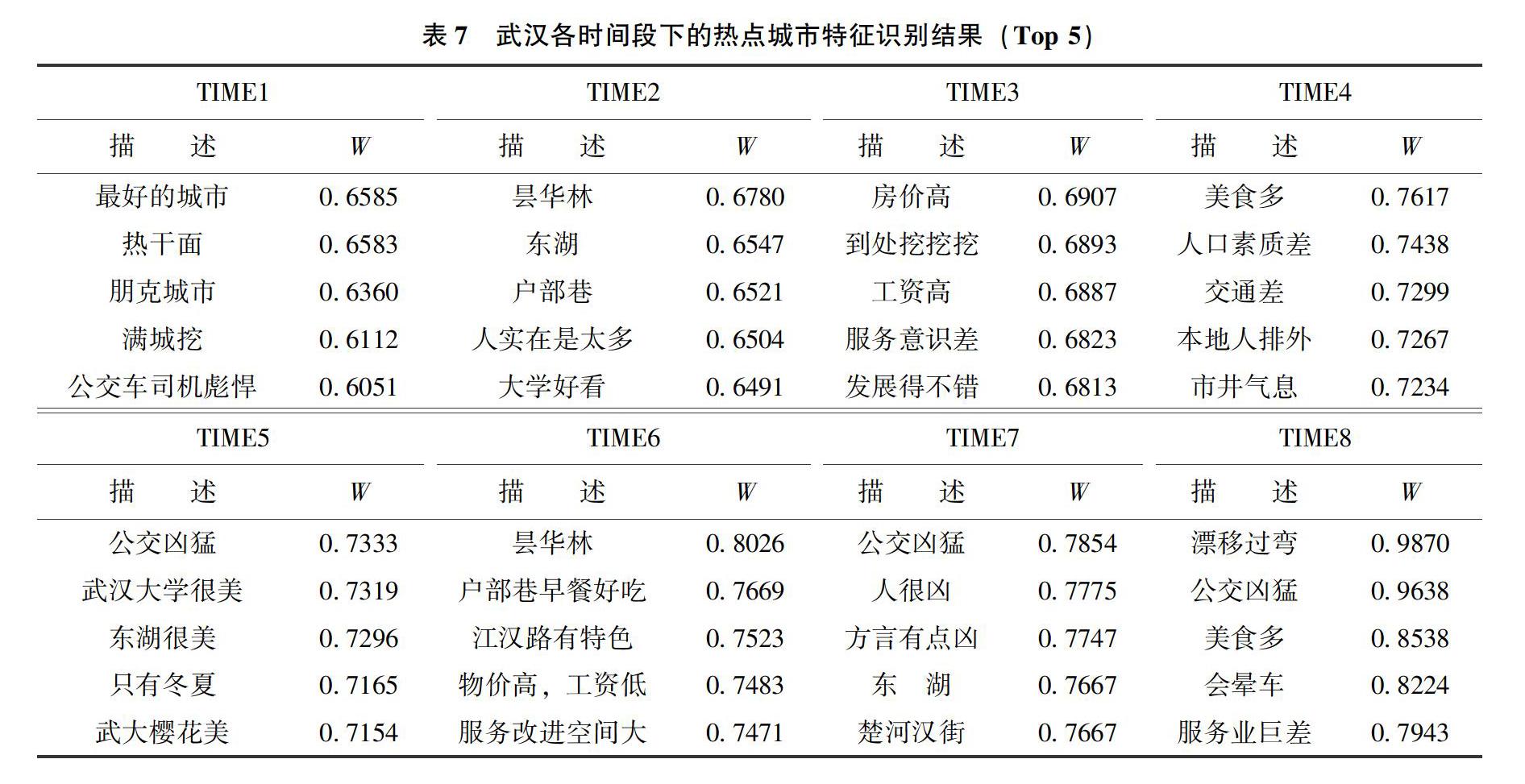
本文依据式(5)计算武汉各时间段下所有标签的WTa,Citya,并按WTa,Citya值降序排列选出其在各时间段下的热点城市特征Top5,详见表7。重复上述流程,本文得到我国中部六省省会城市在各时间段下的热点城市特征,详见表8。
以武漢热点城市特征为例,在8个时间段内主要分布着“城市文化”、“城市交通”、“城市发展”、“城市环境”4个方面的城市特征描述。其中,公众对城市交通和城市环境的描述在所有时间段内基本没有太大变化,“司机脾气急躁”、“交通拥堵”、“晕车”等描述反映了公众对城市交通的整体印象;“九省通衢”、“便利”等描述也反映武汉重要的交通枢纽地位,以及城市内多元化的交通工具给公众出行带来的便利。在TIME 6时间段内(2015.07-2015.12)首次出现了“光谷特别拥堵”的城市交通描述,这可能与光谷地区开始大力修建地铁线路引起的交通拥堵有关;在2014-2015年间,公众对城市环境的描述主要集中在“冬冷夏热”,尤其是“热”、“火炉”成为武汉气候的代表性描述。自2016年起,武汉热点城市特征中出现了“雾霾”、“暴雨”、“潮湿”等新描述,究其原因是雾霾导致空气质量变差,天空呈现灰蒙蒙现象,而潮湿环境和炎热天气组合成“湿热”气候使得整个城市环境变得更加复杂。
此外,公众对武汉城市文化和城市发展的描述也随着时间推进呈现出一定变化。例如在城市文化方面,2014-2015年间公众对武汉城市文化的描述主要体现在“黄鹤楼”、“户部巷”等历史文化,“涂鸦”、“VOX LiveHouse”等朋克文化,“热干面”、“小龙虾”等美食文化;但2017-2018年间则更倾向于旅游文化,“东湖”、“樱花”、“轮渡”、“夜景”、“长江大桥”等城市特征也均成为新晋热点城市特征。在城市发展方面,“满城挖”和“修路”一直是公众对武汉城市发展的主要描述,但武汉也在教育和经济方面出现了较为严重的人才流失问题。自2016年起,“武汉每天不一样”成为武汉新的城市宣传语,并由此带来了“经济改善”、“人口增多”、“商圈扩大”、“大学生留汉”等积极的社会影响。通过以上分析可知,尽管一座城市在不同时期内的热点城市特征具有部分相似性,但会随着时代背景变化而呈现出一定差异。这些差异会在文中方法的计算结果中展现出来,这也在一定程度上说明了本文爆发词检测方法的必要性。
4 结 语
本文在考虑城市画像刻画方式其现实意义的基础上,首先详细分析了热点城市特征的主要特点,并依据这些特点设计了热点城市特征的评价指标及其数据来源和计算方法;然后对不同量级、不同方向的评价指标进行标准化处理,并采用线性加权和法构造综合指标评价模型,计算不同时间内城市的热点城市特征;最后利用爬虫技术采集知乎平台中描述中部六省省会城市特征的用户问答数据,并以此为原始数据展开实证研究。然而本文使用城市标签数据的并不是传统意义上的标签,而是从用户问答数据中人工抽取的。虽然该方法能够从海量网络数据中获取城市在不同时间段内的热点城市特征,但标签标注质量和自动分词结果将直接影响着热点城市特征的识别效果。因此,如何结构化处理用户原始评论提高标签抽取质量,以及如何选用最优的分词技术提升分词效果将会是本项目团队今后的研究方向。
参考文献
[1]Lynch K.The Image of the City[M].Cambridge,Massachusetts:The MIT Press,1960.
[2]马亚雪,李纲,谢辉,等.数字空间视角下的城市数据画像理论思考[J].情报学报,2019,38(1):62-71.
[3]马超,李纲.基于城市大数据的城市数据画像构建[J].现代情报,2019,39(8):3-9.
[4]杜智涛,李纲.面向精细化治理的城市画像:构成要素与应用体系[J].图书情报知识,2019,(4):43-51.
[5]田逢军,汪忠列.城市空间意象研究述评与展望[J].世界地理研究,2014,(1):84-92.
[6]王德,张昀,崔昆仑.基于SD法的城市感知研究——以浙江台州地区为例[J].地理研究,2009,28(6):1528-1536.
[7]张梦琦.北京市城市意象调查及解析[D].保定:河北农业大学,2013.
[8]田逢军,沙润.城市旅游地意象空间分析——以南昌市为例[J].旅游学刊,2008,23(7):67-71.
[9]宋伟轩,吕陈,徐旳.城市社区微观空间意象研究——基于南京居民250份手绘草图的比较[J].地理研究,2011,30(4):709-722.
[10]张新红,苏建宁,魏书威.兰州城市居民意象空间及其结构研究[J].人文地理,2010,(2):54-60.
[11]宋伟轩,吕陈,徐旳.城市社区微观空间意象研究——基于南京居民250份手绘草图的比较[J].地理研究,2011,30(4):709-722.
[12]蒋志杰,吴国清,白光润.旅游地意象空间分析——以江南水乡古镇为例[J].旅游学刊,2004,19(2):32-36.
[13]陈梦远,徐建刚.城市意象热点空间特征分析——以南京为例[J].地理研究,2014,33(12):2286-2298.
[14]Kumaran G,Allan J.Text Classification and Named Entities for New Event Detection[J].2004,20(17):297-304.
[15]Nallapati R,Feng A,Peng F,et al.Event Threading Within News Topics[C]//Thirteenth ACM International Conference on Information and Knowledge Management.ACM,2004:446-453.
[16]Blei D M,Lafferty J D.Dynamic Topic Models[C]//Proc.International Conference on Machine Learning.2006:113-120.
[17]Li Z,Wang B,Li M,et al.A Probabilistic Model for Retrospective News Event Detection[J].2005:106-113.
[18]Mei Q,Liu C,Su H,et al.A Probabilistic Approach to Spatiotemporal Theme Pattern Mining on Weblogs[C]//International Conference on World Wide Web.ACM,2006:533-542.
[19]Kumar R,Mahadevan U,Sivakumar D.A Graph-theoretic Approach to Extract Storylines from Search Results[C]//Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Seattle,Washington,Usa,August.DBLP,2004:216-225.
[20]Zhao Q,Liu T Y,Bhowmick S S,et al.Event Detection from Evolution of Click-through Data[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2006:484-493.
[21]Fung G P C,Yu J X,Yu P S,et al.Parameter Free Bursty Events Detection in Text Streams[C]//International Conference on Very Large Data Bases.2005:181-192.
[22]He Q,Chang K,Lim E P.Analyzing Feature Trajectories for Event Detection[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2007:207-214.
[23]Lappas T,Arai B,Platakis M,et al.On Burstiness-aware Search for Document Sequences[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Paris,France,June 28-July.DBLP,2009:477-486.
[24]逯萬辉,马建霞,赵迎光.爆发词识别与主题探测技术研究综述[J].情报理论与实践,2012,35(6):125-128.
[25]刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012,39(2):8-13.
[26]叶光辉,胡婧岚,徐健,等.社交博客标签增长态势与连接模式分析[J].数据分析与知识发现,2018,2(6):74-82.
(责任编辑:郭沫含)
