改进MobileNetV2网络在遥感影像场景分类中的应用
2020-04-01杨国亮李放朱晨许楠
杨国亮,李放,朱晨,许楠
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引言
遥感场景分类是根据遥感图像的内容进行特征提取,使用分类器对抽象出来的特征进行分类,从而对遥感场景进行分类和识别的过程。精准而快速的场景分类可以降低如地理目标检测、土地利用分析、土地覆盖分析、城市规划等遥感解译任务的难度,并提高解译精度。
传统场景分类算法多数是基于人工特征提取的,这些算法依赖大量的专业知识以及专家经验来设计针对不同任务的特征描述子,此种基于人工特征提取的场景分类方法难以取得较好的泛化效果。近年来,随着卷积神经网络的快速发展,遥感图像场景分类的准确率和泛化能力得到了极大提升[1-2]。Krizhevsky等[3]于2012年凭借AlexNet取得了ImageNet大规模视觉识别挑战赛图像分类和目标定位任务的冠军,展现了卷积神经网络在图像领域上的巨大潜力。在此之后,vgg-16[4]、GoogLeNet[5]、ResNet[6]等网络的提出及发展[7-8]大大提高了分类任务的分类准确度的同时应用领域也逐渐多元[9-10]。但是这些网络性能得到提高的同时也使得模型的深度与参数的数量快速增加,这会导致模型训练困难,存储空间占用大,训练、预测时间长等问题,对于集成卷积网络的方法更是如此。近年来,越来越多的研究都聚焦在了网络模型的效率问题。2017年发表在ICLR上的利用fire module的SqueezeNet,同年发表在CVPR上的利用深度可分离卷积的MobileNet,以及之后发表的ShuffleNet[11]、Xception[12]和MobileNetv2[13],这些网络在保持相似精度的同时大量缩减网络参数数量,通过减少网络的参数与计算量来解决网络的效率问题。
本文在MobileNetv2的基础上,结合了Densenet的密集连接思想,通过引入密集连接,调整瓶颈扩张系数等方式构建了一个新的改进网络。新的网络有效降低了网络的参数量和计算量,网络更加轻量和有效,同时具有与原始网络相似的分类准确率。
1 MobileNetv2及DenseNet网络概述
1.1 MobileNetv2
现代先进网络需要的高计算资源远远超出了移动和嵌入式设备的能力。Mobilenetv2网络[13]是针对此种限制设计出来的一种新型的网络结构。该网络可以在保持相似准确度的情况下有效减少网络中的参数量与计算量。
MobileNetv2的主要贡献来自Linear Bottlenecks和Inverted Residual block[13]。Linear Bottlenecks即去除网络中输出维度较小的层后的激活函数Relu,将其改为线性激活。这种改进降低了使用Relu函数造成的信息损失。Inverted Residual block的设计采用了先升维、后降维的结构,与传统的Residual block先降维、后升维的结构相反,减少了信息的损失。同时网络设计了扩张系数t以控制网络的大小。MobileNetv2的瓶颈结构如图1所示,其中每层的输入与输出如表1所示。表1中,k表示输入通道数;h表示输入的高;w表示输入的宽;t表示扩张系数;s表示步长;k’表示输出通道数。
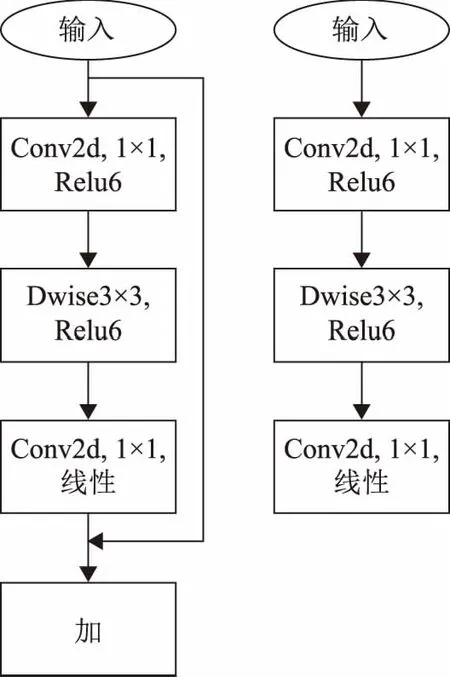
图1 MobileNetv2瓶颈图(左图步长为1,右图步长为2)

表1 瓶颈各层的输入输出
1.2 DenseNet
DenseNet[14]的设计不同于ResNet,在一个Dense块中,层的输入为之前所有层输出的拼接。对于残差网络来说,第l层的输出等于第l-1层的输出加上对l-1层的非线性变换,即:xl=Hl(xl-1)+xl-1;而对于Densenet来说,[x0,x1,…,xl-1]表示将第0层到第l-1层的输出特征图拼接,故此时第l层的输出为xl=Hl([x0,x1,…,xl-1])。Dense块结构[14]如图2所示。
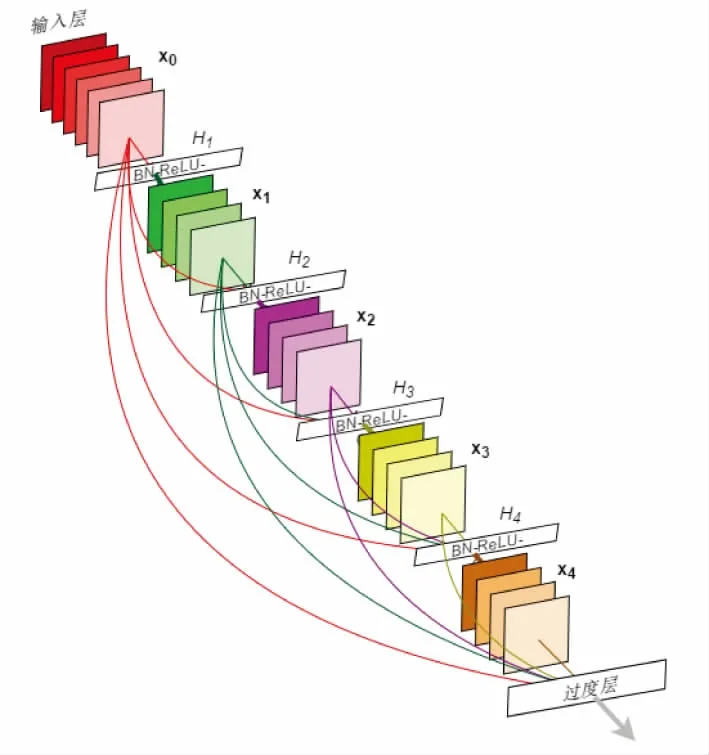
图2 Dense block图
这种设计提升了信息和梯度在网络中的传输效率,Dense块中的每层都能直接从损失函数获得梯度信息,并且直接得到输入信号。除此之外,这种网络结构同时还具有正则化的效果,对于过拟合现象有一定的抑制作用。
2 网络结构及设计思路
2.1 深度可分离卷积
对于目前很多高效的神经网络结构来说,深度可分离卷积[12](depthwise separable convolution)都是非常重要的一个设计。在改进网络中将继续沿用这一设计。深度可分离卷积的设计思想是将一个标准卷积分成两个部分,第一部分为深度卷积(depthwise convolutions),depthwise convolution将3×3的卷积核应用在每一个输入通道上,产生与输入通道数个数相同的结果;第二部分逐点卷积(pointwise convolutions)为普通的1×1卷积,它被用来将depthwise convolution的输出进行线性组合。过程如图3所示[12]。
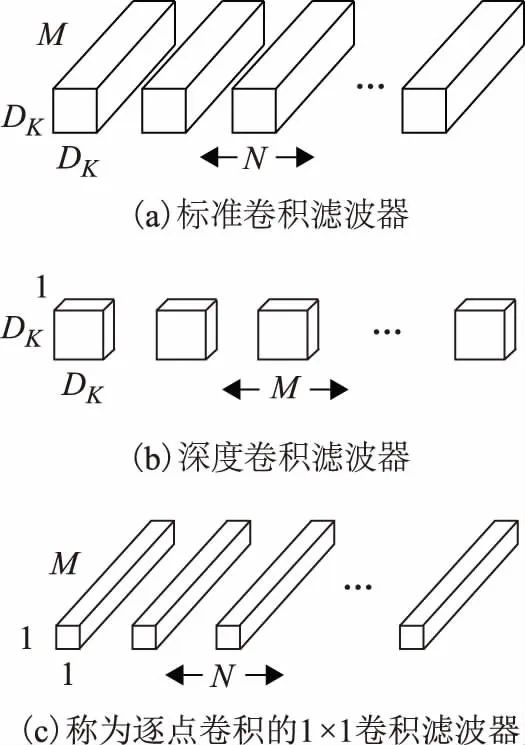
图3 深度可分离卷积
深度可分离卷积的计算量与标准卷积计算量的比值如公式(1)所示。
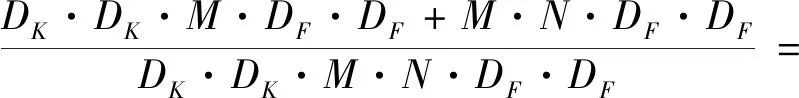
(1)
式中:DK为卷积核的尺寸;M为输入通道数;N为输出通道数;DF为特征图的大小。从公式中可以看出使用3×3大小的卷积核可以将计算量减小为标准卷积的九分之一。
2.2 瓶颈设计
在设计瓶颈的时候采用先升维后降维的策略并在降维后使用线性激活来避免激活函数Relu对信息的损失,与原网络不同的是,本文去除了残差连接,在输出特征图大小一致的瓶颈之间使用密集连接代替残差,借助特征复用来提升信息和梯度在网络中的传输效率,同时密集连接使用的是拼接而不是求和,这会造成瓶颈的输出通道数的快速增加,从而导致网络参数和计算量的增加。所以这里没有和原始网络一样将扩张系数t设定为默认值6,而是对扩张系数进行了适当的调整,控制网络的规模。扩张系数的调整范围限制在1到6。在设计网络时使用了扩张系数为1的瓶颈,但是在设计瓶颈的时候并没有删除最初的1×1卷积层,因为1×1卷积不仅可以提高网络的表现能力,更重要的是1×1的卷积层可以将多个特征图线性组合,从而实现了跨通道的信息整合。因为网络引入了密集连接,所以认为初始的1×1卷积即使扩张系数为1也同样对网络性能的提高有着积极的作用。文中设计的瓶颈结构如图4所示。
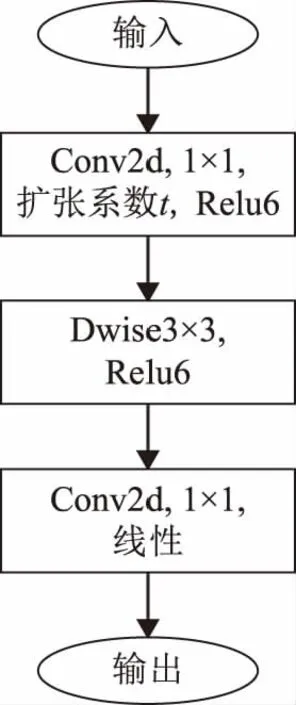
图4 本文瓶颈
2.3 网络整体结构
改进网络的结构如图5所示,图中的c表示瓶颈的输出通道数。
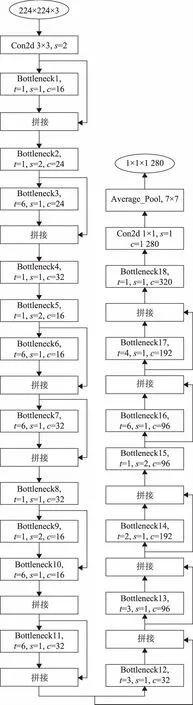
图5 改进网络的结构图
本文采用了密集连接来代替原网络中的残差连接,使得梯度与信息可以在网络中得到更好的传递。同时为了解决在多个输出拼接作为下一个瓶颈的输入时所产生的通道数过大的问题,在设计网络的时候放弃了原网络在多个输出通道数相同的瓶颈堆叠,之后对下一个瓶颈的输出通道数进行放大,最终使得网络的通道数逐步增加。首先对输出通道数进行缩小,之后堆叠数个步长为1的瓶颈,借助密集连接来对输出通道数进行拼接,最终使得网络的通道数得到放大的设计,此种设计可以有效减少网络的参数量与计算量。同时,为了保证网络的复杂度与表现力,使用了一个T=1,S=1的瓶颈和一个T=1,S=2的瓶颈的组合来完成输出通道数缩小的过程,如图5 bottleneck4和bottleneck5、bottleneck8和bottleneck9的使用。本文的网络在网络较深的位置仅使用一个步长为2的瓶颈进行通道数的缩减,主要原因是基于网络参数与计算量的考虑,如bottleneck15的使用。同时,网络在bottleneck13、bottleneck14、bottleneck17和bottleneck18的位置减小了扩张系数t,主要想法是这些瓶颈的输入经过数次拼接,通道数已经增加到了一定程度。而拼接导致的通道数增加在一定程度上可以代替或者部分代替扩张系数对于通道数的扩张作用。每个瓶颈的输入与输出大小与表1中给出的值相同。扩张系数t的调整范围为大于等于1、小于6的整数。
2.4 参数量与计算量分析
瓶颈的参数量计算方法见公式(2)。
P=t×Cin×Cin+9×t×Cin+t×Cin×Cout
(2)
式中:P表示参数量;t表示扩张系数;Cin表示输入通道数;Cout表示输出通道数。
瓶颈的计算量如公式(3)、公式(4)所示。公式(3)、公式(4)中采用的步长分别为1、2,其中h表示输入的高;w表示输入的宽;t表示扩张系数;Cin表示输入通道数;Cout表示输出通道数;s表示步长的大小。
M=h×w×Cin×(Cin+9+Cout)
(3)
(4)
文中设计的网络结构所对应的参数和计算量见表2。改进网络的参数个数共计2 852 496,较原网络减少约16%,计算量减少了约13%。经过改进之后的网络的计算量与参数量都取得了不错的压缩程度。参数与计算量的减少主要原因是因为步长为2的瓶颈的输出通道是减小的而后通过多个瓶颈的输出拼接使得之后瓶颈的输入得以放大,此种操作会使得最初的几个瓶颈的输入通道数较少,即这些瓶颈内的参数与计算量也较少。而拼接本身并不会产生多余的参数与计算量。与此设计不同的是,在原始网络中,步长为2的瓶颈会对通道数进行放大,再将这些输出作为输入传入到下一个瓶颈时必然会产生更多的参数与计算量。

表2 网络参数及计算量
3 实验及分析
3.1 实验环境及数据集
本文的实验环境为Ubuntu14.04系统,Intel core i7-4790CPU,内存为8 GB,显卡为GTX 1080 8 G GDDR5,搭配tensorflow-1.4.0,cuda8.0,cudnn6.5,使用的数据集为遥感图像场景分类数据集NWPU-RESISC45[15]。该数据集是由西北工业大学(NWPU)创建的REmote传感图像场景分类(RESISC)的公开可用基准。该数据集包含31 500个图像,涵盖飞机场、棒球场等45个场景类,每个类有700个图像,示例如图6所示。

图6 NWPU-RESISC45示例图
首先将数据集图片大小统一为224×224。本文实验均未使用预训练参数,为避免训练集图像过少造成的不利影响,尤其是参数较多的大型网络,故从每一类场景中随机抽取500张作为训练集,即训练集的数目为500×45;剩余的作为测试集,数目为200×45。在训练之前,对数据集进行数据增强。对每张训练集图片进行2次随机旋转、1次左右翻转、3次随机亮度处理、3次随机对比度处理,使得数据集更加多样。最终的数据集规模为5 000×45张图片,预处理效果见图7。为了验证原始和旋转等操作后的测试图片分类效果,对于测试集的每张图片进行了1次随机旋转、1次左右翻转、2次随机亮度处理和2次随机对比度处理,最终测试集规模为1 400×45张图片。

图7 训练集预处理(左上角的图像为原始图像)
3.2 网络的训练与分析
为了说明改进网络的有效性来自网络设计而不是超参数调整或者训练策略的不同,在训练2种网络时采用一致的设定。在训练MobileNetv2和改进网络时设定每个批(batch)包含32张图片。在训练的过程中,使用了RMSprop优化方法来加速训练,训练开始时设置的初始学习率为0.045,训练的过程中使用tensorboard对loss值进行可视化监控,当损失下降困难时,暂停训练并且调低学习率的大小。在本次实验中学习率下降了3次,分别下降为0.022 5、0.012 5、0.005。随着学习率的下降,loss值会继续减小,说明调低学习率的做法的确对于网络的训练可以起到积极作用。在实验结束后,使用tensorboard对遥感场景的分类准确率、召回率和训练过程中的loss值变化曲线进行可视化显示,方便对2种网络进行对比。在训练的过程中,原始网络完成一步训练的时间大约为0.350 s,而改进网络完成一步训练只需要大约0.250 s,完成每步训练的时间缩短了大约28%,改进的网络在缩短训练时长方面有着较好的效果。
图8为训练过程中的loss值曲线。从图8可以看出2条loss曲线差别不大,在训练之初原始网络loss值下降速度略快于改进网络,而后二者的loss值基本相近,原始网络稍低于改进网络,这说明在对原始网络的规模进行缩减时并没有使网络的训练变得困难。
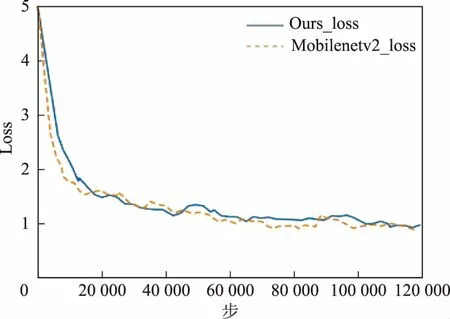
图8 Loss值(smooth=0.6)
为了更好地说明问题,本文使用相同的训练策略和数据集训练了几种应用广泛的网络结构。使用这些网络对测试集的图片进行评估,测试时批的大小设置为50,测试集共计63 000张图片,即1 260个批。
图9为网络在测试集准确率变化曲线。从图9可以看出在训练的过程中改进网络和原始MobileNetv2网络在遥感图像场景分类任务上有着较高的准确率,训练结束时本文网络的准确率为92.54%,MobileNetv2为93.49%,二者相差不足1%。Inceptionv3为91.44%,Res50为89.60%,而在ImageNet大规模数据集上表现出色的Inceptionv4网络在遥感图像场景分类数据集上的表现不够理想,准确率为84.9%。实验结果显示Inceptionv4网络不适合遥感图像的场景分类任务。
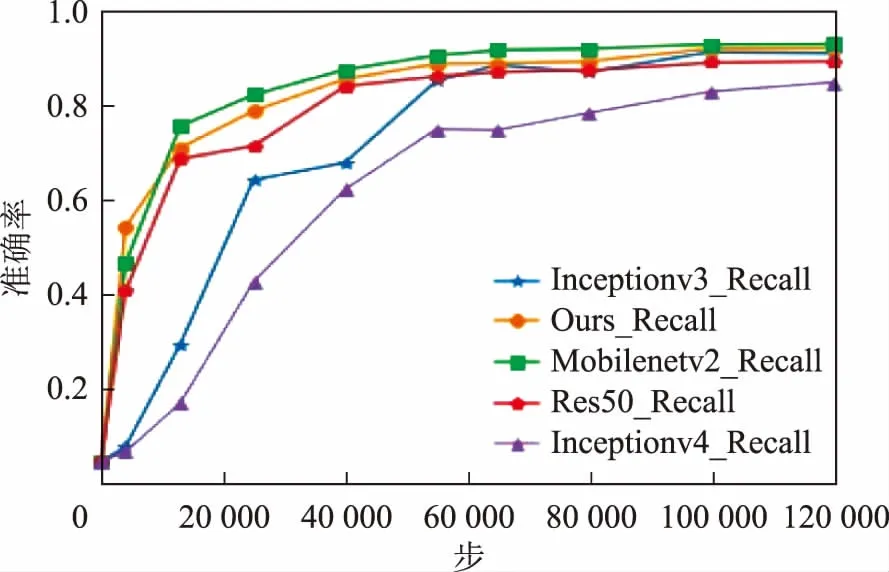
图9 测试集准确率
图10为召回率变化曲线。可以看出,5种网络在召回率方面都有不错的效果,除了Inceptionv4的96.65%和res50的97.96%以外,其余网络的召回率都可以达到99%以上。几种网络的详细对比见表3。
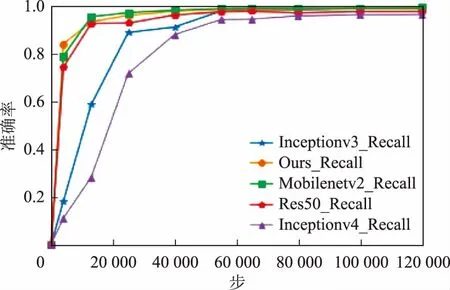
图10 测试集召回率

表3 几种网络性能的对比
结合图9、图10和表3的实验结果综合分析这5种网络在遥感图像分类任务上的表现。Inceptionv4网络的场景分类效果是这5种网络中最差的一个,不足85%的场景分类准确率说明此网络并不适合遥感图像场景分类任务。Inceptionv3虽然可以达到91%的分类精度,但是在训练次数较少时准确率大幅低于剩下的3个网络,而且Inceptionv3的参数量也更多。Res50的各项结果均不如改进网络和MobileNetv2。在改进网络与原MobileNetv2的对比中,改进网络参数量减少了55万,计算量减少了3 800万,完成一步训练的耗时减少了28%左右,完成一次测试集评估用时减少了20%左右,分类准确率只下降了0.9%,召回率下降了0.3%,改进网络在基本保持了遥感图像场景分类任务的分类准确率的同时,减少了网络的参数量和计算量,提高了网络的训练速度与预测评估速度。网络较原始MobileNetv2更加轻量高效,在遥感图像场景分类任务上取得了较好的效果,网络瓶颈的输出特征图的部分显示如图11所示。测试集中每个分类的准确度如图12所示。根据图12可以看出在绝大多数的情况下网络有着不错的性能。

注:最左侧为第一个卷积层的特征图,从左至右分别对应文中图5所示结构的瓶颈1至瓶颈18。特征图尺寸对应文中表2输出所示。图11 网络部分特征图
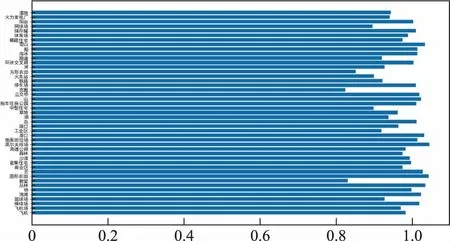
图12 每个分类的准确率
4 结束语
为了可以使用卷积神经网络对遥感场景图像进行分类时既保证分类准确率又减小网络的参数量与计算量,使得网络轻量高效,将DenseNet中的密集连接引入到MobileNetv2中,借助特征图的复用提高网络性能。利用一个扩张系数为1,步长为1的瓶颈与一个扩张系数为1,步长为2的瓶颈的组合压缩特征图的通道数。并将部分瓶颈的扩张系数减小以控制网络的整体规模。最后,在遥感图像场景分类数据集NWPU-RESISC45上进行实验。实验结果表明,改进的网络在基本保持场景分类精度的同时,完成每步训练的时间、前馈计算消耗时长、网络参数数量、网络计算量都得到了一定程度的减小,说明了模型对于遥感图像场景分类任务的可行性与实用性。
