基于全卷积神经网络的遥感图像海面目标检测*
2020-03-30康秦瑀陈中伟胡志毅姚红革
喻 钧,康秦瑀,陈中伟,初 苗,胡志毅,姚红革
(1 西安工业大学, 西安 710021; 2 海军研究院, 北京 100161; 3 陆军研究院工程设计研究所, 北京 100043)
0 引言
随着卫星成像技术、传感器技术的迅速发展,舰船作为海上的运输载体和重要军事目标,高分辨率的舰船遥感图像[1]检测具有重要的应用价值。例如,在民用领域,监控特定海域和港口的海运交通,搜救遇难船只等;在军事领域可以监视敌方重点港口和海域的舰船部署,协助分析敌方的海上作战实力[2],形成海上作战情报等。因此,对于复杂海洋环境下的海面目标检测,提高检测精确率并减少虚警率具有重要的意义。
针对不同的目标,国内外学者提出了不同的目标检测算法[3]。文献[4]提出了基于卷积神经网络特征的区域方法(R-CNN),利用“选择性搜索算法+CNN+SVM”的方式进行检测,整个训练过程运算量大且耗时。文献[5]采用了多任务联合损失函数,将位置回归任务加入到了网络中,简化了训练步骤,加快了训练速度。文献[6]提出的Faster R-CNN,将区域推荐过程融入到网络模型中,实现了端对端的目标检测技术结构,但速度(7 帧/s)仍然达不到实时。为了解决检测精度与速度的平衡问题,文献[7]提出的YOLO(you only look once)算法,将整幅图划分为S×S个小网格,对每个网格预测2个边界框,计算这些网格的置信度和所属类别的概率,实现了实时检测,但由于划分的网格数目较少且网格区域较大,使得小目标的检测效果不好,相比文献[6]而言,检测精度有所下降。YOLO的核心是将整张图作为网络的输入,将目标的边界框位置及其类别作为网络的输出。随着YOLOv2[8]和YOLOv3[9]相继问世,也进一步提高了YOLO的泛化能力和检测速度。
文中针对海面目标难以识别、易漏检等问题,对YOLOv3网络结构进行了改进。利用Kmeans++生成新的anchor box值,通过优化网络结构和坐标预测函数,获得一种新的网络结构。实验结果表明,相比于其他算法,平均检测率提高了5.34%,可以有效防止海面目标的漏检等问题。
1 海面目标检测方法的提出
1.1 YOLOv3检测网络的原理
相对于传统的目标检测方法,基于深度神经网络(DNN)的目标检测可以进行端到端的训练,并将特征进行融合,有效地解决了特征不易提取的问题。图1是YOLOv3的网络结构示意图。它借鉴了残差结构的思想,使得YOLOv3可以包含53个卷积层,其网络结构主要是由5个残差块(Res1,Res2,Res8,Res8,Res4)构成,每个残差块由多个残差单元组成。残差块的结构如图2所示。

图1 YOLOv3的网络结构
在图2中,每个残差结构均有一个卷积层(Conv)、批归一化层(Batch Normalization)和激活函数(Leaky Relu)。卷积层主要负责提取图像特征;批归一化层是将提取到的特征进行归一化处理;激活函数的作用是增强网络层之间的非线性关系,使网络能够完成复杂的任务。

图2 残差块的结构
1.2 改进的YOVOv3网络
原有的YOLOv3检测网络中,主要存在三方面问题:一是anchor box值(anchor box即先验框)是由Kmeans方法生成的,不同的初始聚类中心可能导致不同的聚类结果,从而对检测结果造成影响;二是遥感数据集中的检测结果的平均精确率(mean Average Precision,mAP)较低;三是原有的目标边界框是可以优化的,使之更趋于目标的实际大小和位置。基于上述问题,做如下改进:
1)使用Kmeans++生成anchor box值。
2)采用“FPN”思想进行特征融合。
3)选用GIOU作为坐标预测的损失函数。
下面分别加以描述。
1.2.1 使用Kmeans++生成anchor box值
使用Kmeans++聚类算法对数据集进行分析,并生成适合数据集的anchor box值。Kmeans++算法保证了初始聚类中心之间的相互距离尽可能远,并选用anchor box与真值框的交并比(intersection over union, IoU )作为距离的衡量标准,计算公式如式(1)所示。距离d的值介于[0,1]之间,值越小,代表先验框越接近真值框,即聚类效果越好。
d(box,centroid)=1-IoU(box,centroid)
(1)
其中:box为数据标签的真值框坐标;centroid为先验框的坐标;IoU(box,centroid)表示先验框与真值框的交并比。
文中针对每种输出尺度设定了3种先验框,3种输出尺度共聚类出9种尺寸的先验框(k=9),生成的anchor box值为(22,26), (63,59), (167,121), (30,79), (103,95), (105,217), (55,137), (224,158)和(263,256)。
1.2.2 采用“FPN”思想进行特征融合
改进后的网络结构如图3所示。它采用了feature pyramid networks(FPN)架构思想,在残差网络提取特征的最后阶段加入了一个残差块,输出特征分别与其他3个尺度的特征进行融合[10]。从图3可知:尺度4的特征图经过3次上采样分别与尺度3、尺度2、尺度1的特征图进行拼接;尺度3的特征图经过1次上采样与尺度2 进行拼接,依此类推。多个尺度的特征图进行了拼接操作,充分利用了低层特征的细节信息与高层特征的语义信息,提高了网络的检测性能。不同尺度的特征图拼接完成之后,网络会输出3种不同的尺度框,即:当输入的图像尺寸为786×768时,输出的3个尺度框为:(24×24)、(48×48)、(96×96)。最后,利用非极大值抑制(non-maximum suppression,NMS)的方法删除重复的预测框(预测框是指待检测目标的边界框),得到最终的检测结果。

图3 改进后的网络结构图
1.2.3 选用GIoU作为坐标预测的损失函数
在目标检测中,IoU常用来评价预测框(predict box)和真值框(ground-truth)的距离。IoU的值介于[0,1]之间,其值越大,代表预测框越接近真值框。当IoU作为坐标预测的损失函数时,存在两个问题:一是当预测框与真值框没有公共区域时,损失函数的值为零,无法优化模型;二是损失函数的值无法精确反映两框的重合度大小。针对IoU的上述缺点,文献[11]提出了GIoU(generalized intersection over union)新指标,它不仅关注预测框与真值框的重叠区域,还关注其他非重叠区域,能更好反映预测框与真值框的重合度。GIoU的值介于[-1,1]之间,1代表预测框与真值框重合;-1代表预测框与真值框无交集且无限远。
图4是将L2范数、IoU、GIoU分别作为损失函数的对比示意图。图中虚线表示预测框,实线表示真值框,分别由它们的左上角和右下角的坐标位置表示,即(x1,y1,x2,y2)。图4(a)中,当L2范数的值相同时,IoU、GIoU值依据不同的情况得到不同的数值,该值直接反映了预测框与真值框的重合度情况,即重合度越大,IoU、GIoU的值越大,图4(a)中右边的回归效果最好。图4(b)中,两组对比图的IoU值相等,而左图的GIoU值大于右图的GIoU值,即左图的回归效果比右图好。所以,GIoU能更好地反映预测框与真值框的重合度大小。
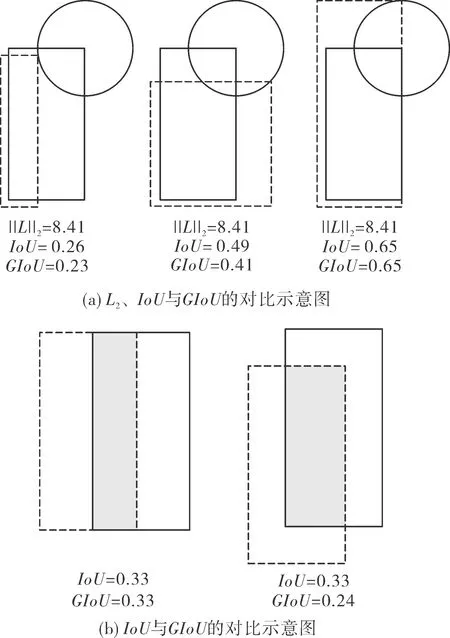
图4 各损失函数的对比示意图
将GIoU作为损失函数算法的步骤如下:
步骤1:分别计算Bg、Bp的面积Ag、Ap。
步骤2:计算Bg,Bp的重叠面积I。
步骤3:计算Bg,Bp最小闭包区域的面积Ac。
步骤4:分别计算IoU、GIoU的值,公式分别如式(2)、式(3)所示。
(2)
(3)
步骤5:计算最终的损失函数,如式(4)所示。
LGIoU=1-GIoU
(4)
2 实验结果与分析
2.1 实验的总框架
实验的总框架如图5所示。实验流程包括两大部分:数据集的准备、网络的训练。为了确保实验结果的精确性,数据集制作的重点是数据预处理。

图5 实验的总框架
2.1.1 数据集的准备
舰船类型包括5类:客船、货船、集装箱船、航母、军舰。实验数据来源于Kaggle竞赛平台和Google Earth。该数据集中,货船和客船居多,集装箱船、军舰、航母数目类别较少,且遥感数据集大多数是俯拍,舰船的朝向变化很大。为了使数据集中的舰船朝向尽可能全面,使得学习到的模型具有广泛性,对数据集进行了扩增。数据扩增主要包括如下4种方法,扩增后的结果如图6所示。

图6 数据扩增
1)水平或垂直翻转;
2)按不同角度旋转图像(如图6(b)所示);
3)添加随机噪声(如图6(c)所示);
3)导入数据后应检查其合理性,如影像和POS是否一一对应,航拍3D视图中的各点位是否与实际情况一致等。
4)按指定的量模糊图像。
2.1.2 网络的训练
实验环境的主要硬件配置为:处理器Intel(R) XEON W-2133;内存2×16 GB DDR4 RDIMM;显卡Nvidia TITAN XP 12 GB;操作系统为Ubuntu 16.04。训练完成后,对整个网络模型的检测性能进行测试。表1是检测网络的主要参数值。在训练过程中,如果学习率太小,会降低模型的训练速度,导致网络收敛变慢;学习率太大,会使得模型在最优值两侧来回摆动,阻碍网络收敛。因此,文中设置的学习率会根据不同迭代次数而改变,不仅保证了良好的训练效率,还兼顾了后期训练的稳定性。

表1 检测网络的主要参数值
2.2 实验结果
实验结果如图7所示。每张图片中的舰船目标被框选出来,在标记框上显示了目标的类别名和置信度。

图7 实验结果图
从图7可以看出,各种复杂海面背景下的舰船目标都可以被有效地检测出来,包括不同颜色、不同尺度和不同方向的舰船。尤其在图7(a)、图7(d)中,受海岸和云雾干扰较大,但舰船目标仍然可以被精确地检测。
2.3 实验结果分析
为了验证文中方法的有效性,对4种检测方法进行了对比,分别是Faster RCNN-vgg16(FR-vgg16)、Faster RCNN-res101(FR-res101)、原始YOLOv3网络以及文中方法。对4种检测方法的训练模型在1 689张数据集上进行了测试,具体实验结果如表2、表3所示。
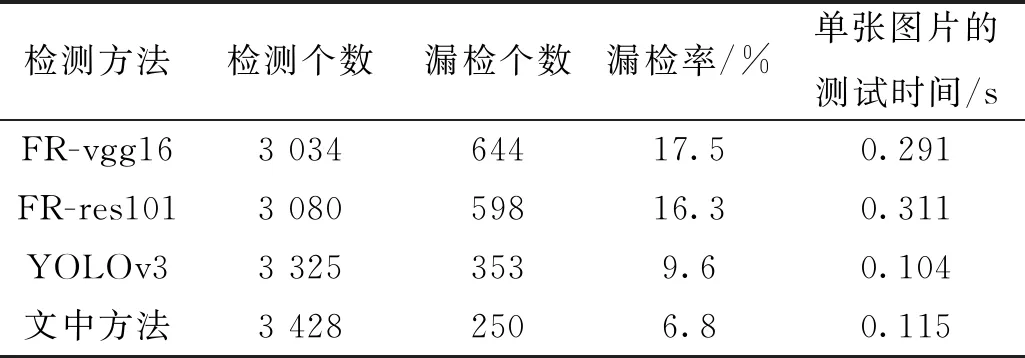
表3 4种检测方法的实验结果对比
从表2所示的结果中,可以得出:

表2 4种检测方法的平均检测精度(mAP)对比 %
相同网络结构在不同舰船类别中的检测结果比较。在FR-vgg16方法中,对于航母的检测效果最好,客船的检测效果最差。其他3种方法的检测效果也是如此。
不同网络结构在相同类别中的检测结果比较。在文中方法中,除了航母,其他类别对应的mAP值都是最高的。
对于前面的3种方法,文中方法对客船的检测精度分别提升了28.0%、24.8%、2.0%;货船的检测精度分别提升了6.6%、6.2%、0.9%;mAP值分别提升了7.86%、6.78%、1.38%。
从表3可以看出,文中方法的漏检率最低,相比于前面3种方法分别降低了10.7%、9.5%、2.8%。在单张图片测试时间方面,FR-res101的测试时间最长,为0.291 s;YOLOv3的测试时间最短,为0.104 s。测试时间比YOLOv3慢了0.011 s,但比FR-res101快了大约2.7倍。
综上所述,文中方法在检测精度和速度两方面,均比其他3种方法有所提升,尤其针对客船和货船的检测,检测精度有了大幅度的提升。
3 结论
针对遥感图像中海面目标较难识别、易漏检等问题,以原有YOLOv3网络结构为基础,通过改进残差网络结构和坐标预测的损失函数,获得一种新的网络结构,使检测性能大大提高。由实验结果得出了如下结论:1)通过数据扩增的方法,丰富了数据集中舰船的朝向,使得学习到的模型具有广泛性。2)原有YOLOv3网络结构与anchor box值仅适用于常规目标,而优化后的网络结构与新的anchor box值更适用于遥感图像海面目标的检测。3)使用“FPN”思想进行特征融合,使网络层数加深,检测精度平均提高了5.34%。4)选用GIoU作为坐标预测的损失函数,整体上进一步优化了模型的检测结果。
