基于集成模型的个人信用风险评估研究
2020-03-24李思瑶
李思瑶

摘要:随着金融科技的快速发展,机器学习在大数据风控领域的应用也越来越成熟,尤其在在线信贷中被广泛应用。本文从消费金融行业的实际业务出发,提出了一套基于多源数据的子模型框架系统,该系统可以根据不同的数据维度独立建立,再将模型进行自由组合。研究表明,基于多源数据的子模型系统的评分有效性比单个机器学习评分模型更好。
关键词:风险管理 信用评分 机器学习
一、引言
如今风险管理部门已经成为诸多企业中的重要职能部门之一,为实现企业的经营目标提供有力保障。随着互联网的迅猛发展,大数据、数据挖掘和机器学习等新兴技术开始出现并在企业的经营决策过程中得到应用。
大数据:作为一项新兴技术,目前在IT界较为认可的定义是:在可承受的时间范围内,无法用传统数据库软件工具进行分析利用的数据集。
(一)大数据在风险管理中的应用
最早应用大数据风险管理的正是风险管理出现最早的保险业。保险业工作人员利用客户的银行系统征信数据和在互联网上产生的涉及人际关系、历史消费行为、身份特征等方面的数据,通过大数据“画像”技术,对用户进行全面的定位,据此来预測用户的履约能力进而降低信贷风险。
大数据技术成功应用的案例很多,比如CanadianTire公司曾做过的一次将消费者行为和信用风险相挂钩的突破性调查。通过详细分析消费者在多家店铺使用本公司所发行信用卡消费的情况,CanadianTire公司发现延迟交付、信用卡违约都是可以预测的,办法就是通过研究人们购买的商品种类、品牌以及所光顾的酒吧类型。结果证明,这种预测比传统的行业预测方法更为精准。金融业工作人员可以利用大数据的优势,通过将多样化的数据集引入计算,提高对风险的防范意识并降低风险。
(二)机器学习
机器学习技术并不是刚刚起步,而是随着电子计算机的出现而出现的一种技术。互联网的普及让机器学习以大数据应用技术的全新面目呈现出勃勃生机。简言之,机器学习就是通过各种算法对海量的历史数据进行有监督或无监督的学习分析,总结规律,并利用分析结果对未来数据进行预测的一种技术。机器学习目前有很多应用方向,包括风险识别、模式识别、图像识别、智能决策等。
二、模型简介
(一)XGBoost算法
XGBoost的目标函数由两部分构成:一部分用来衡量预测分数和真实分数的差距,另一部分则是正则化项。正则化项同样包含两部分:一部分用于控制叶子结点的个数,另一部分用于避免叶子节点的分数过大,防止过拟合。XGBoost还提出了两种防止过拟合的方法:Shrinkage and Column Subsampling。Shrinkage方法就是在每次迭代中对树的每个叶子结点的分数乘上一个缩减权重η,这可以使得每一棵树的影响力不会太大,留下更大的空间给后面生成的树去优化模型。Column Subsampling类似于随机森林中的选取部分特征进行建树。其可分为两种,一种是按层随机采样,在对同一层内每个结点分裂之前,先随机选择一部分特征,然后只需要遍历这部分的特征,来确定最优的分割点。另一种是随机选择特征,则建树前随机选择一部分特征然后分裂就只遍历这些特征。一般情况下前者效果更好。当样本的第i个特征值缺失时,无法利用该特征进行划分时,XGBoost的处理思路是将该样本分别划分到左结点和右结点,分别计算增益,划分到增益大的一边。
(二)LightGBM
lightGBM主要有以下特点:基于Histogram的决策树算法、带深度限制的Leaf-wise的叶子生长策略、直方图做差加速、直接支持类别特征(CategoricalFeature)、Cache命中率优化、基于直方图的稀疏特征优化、多线程优化。Leaf-wise的方法是从当前所有叶节点中寻找信息增益最多的方向进行分裂,这样的设计比Leaf-wise方法的预测精度更高而误差更小。而且为了防止过拟合,LightGBM在分裂的时候对最大深度也进行了限制。
三、集成模型框架设计
传统银行评分卡使用的变量较少,一般10个左右的强信息变量,包含三种类型:基本信息、个人信用和贷款人社会关系。与传统银行信用卡业务相比,在线信贷由于大多为模型自动决策,而基于传统评分卡模型的建模方法数据维度较少,在互联网时代下少数的几个维度很难对借款用户进行精准画像。因此,为了弥补评分卡模型中的信息缺失,将各种维度的数据分别训练为子模型,再进行融合为最终模型是一种更好的解决方案。
为了提高网络借贷中的信用风险评估,本文提出一种集成模型框架,基本思想是:首先,根据不同场景、不同客户群的不同数据,将数据分组后分别训练子评分模型;然后根据训练好的模型输出的结果作为输入变量进行重新建模,得到最终的信用评估结果。本文中选用根据消费金融公司主要数据源进行分析建模,包括:多头借贷、高风险特征、运营商信息、银行卡信息、第三方信用评分、人行征信报告。先将数据源按照这6种维度分别进行子模型训练,再把训练得到的6个子模型输出结果整合成一个6列矩阵(将每个子模型的预测结果转换为具体分数),再重新利用机器学习融合成新的模型评分。
在该案例中,集成模型框架根据不同的数据来源,构建了6个机器学习子评分模型,子模型的数量和选用的算法都可以自由选择,而且随着数据源的丰富还可以不断的增加子模型的数量。虽然各子模型都能较好的预测用户的信用风险,但集成模型的预测准确率更高,并且预测效果也更稳定。当面对不同的借贷场景或不同的客群时,模型可用的数据也不同。这时,先将数据根据来源或客群分组,然后自由选择入模数据,自由选择模型算法,自由组合入框架的子模型,可以大大提高数据的使用效率且节约数据采购成本。
四、实证分析
实验数据为2018年1~9月11996笔小额在线贷款数据,坏样本定义为历史逾期最长天数不低于90天的客户,标记为1;好样本定义为没有逾期记录且已经有完整的借款表现期的客户,标记为0。其中坏样本共2999个,占比25%,好样本共8997个,占比75%,Odds=3,表5为本次实验数据的基本情况。
首先,本实验将6个子模型所包含的全部超过100个变量全部作为输入,预测违约概率。为了找到分类效果最佳的模型,本文尝试了GBDT、Adaboost、RandomForest、LightGBM、XGBoost多种机器学习方法,根据AUC、KS、准确率等评价指标挑选出最佳模型,对比结果见表1。
实验中,数据集按4:1的比例拆分为训练集和测试集,表2展示的是各模型在测试集上的表现。可知,在测试集上表现最佳的是LightGBM模型。与其他模型相比,其准确率、AUC、KS的数值都较大,说明该模型区分能力更高。
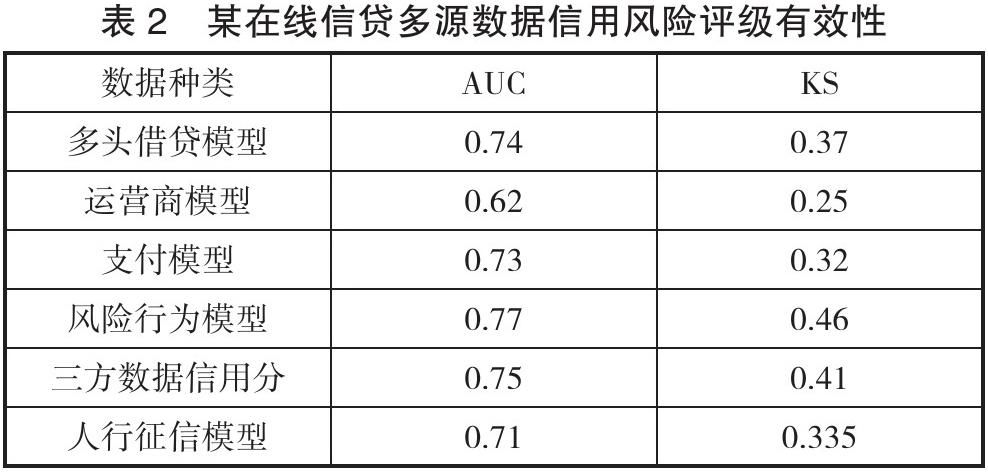
为了验证组合模型思想模型的有效性,我们对6个子模型分别训练,并对预测有效性做了分别统计,又将6个子模型的预测概率转化为具体评分,再把6个评分作为最终的模型输入变量,重新再利用进行机器学习进行建模,6个子模型的结果如表2所示。
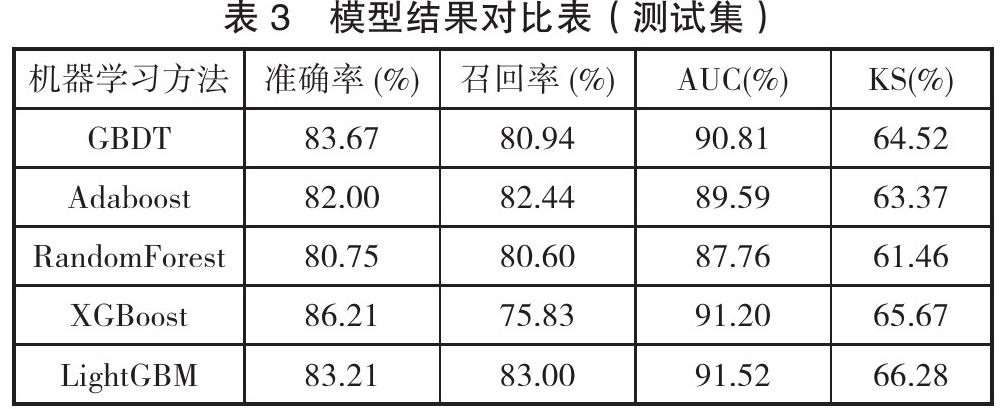
从表2可以看出,6个机器学习评分模型中,风险行为数据与某第三方信用评分模型的预测效果最好,这也说明网络借贷业务往往面临较高的信用风险。最后,将6个子模型的预测结果作为输入变量融合成一个集成机器学习模型,对比结果见表3。
从表3的试验对比可以看出,将子模型的预测结果作为输入重新构建的机器学习模型,可以获得比直接进行全变量输入更好的预测精度,其中最优算法LightGBM的预测KS值从65.45上升到了66.28,且其他算法的预测精度也有了一定的提升。
表4展示了在LightGBM模型下测试集样本的通过率和误放率的情况。模型在预设概率为0.45~0.50的条件下(即只有当某个客户被预测为坏人的概率大于0.45时才通过筛选),KS0.663,通过率最高可达67.40%,而其对应的误放率很低,为6.70%。这说明通过LightGBM模型筛选的客群能够保证较高的质量。
五、结论
本文通过尝试GBDT、Adboost、RandomForest、LightGBM、XGBoost多种机器学习方法,根据多种评价指标筛选对比,得出如下结论:
第一,对大数据而言,机器学习方法能够更好地探索数据的内在结构,形成的分类模型也更加精准。在本文尝试的几种機器学习方法中,XGBoost、LightGBM模型的分类效果最好。
第二,基于多源数据的子模型框架可以根据不同的数据维度独立建模,每个子模型可以用不同的方法进行训练,且训练的好的子模型也可以进行自由的组合。本研究只是简单的将子模型再重新进行了一次利用LightGBM算法的重新组合就获得了比直接进行全变量建模方式。实际上,子模型还能通过传统评分卡建模的方式构建评分卡模型,使得机器学习算法也能获得很好的解释效果,或者利用决策树方法,将子模型构建为一个基于决策树方法的策略集也是一个非常有价值的研究方向。
参考文献:
[1]Chen T,He T,Benesty M . xgboost: Extreme Gradient Boosting[J]. 2016.
[2]Jerome H. Friedman. Greedy Function Approximation: A Gradient Boosting Machine[J]. The Annals of Statistics,2001,29(5):1189-1232.
[3]王春峰,万海晖,张维.《商业银行信用风险评估及其实证研究》[J].《管理科学学报》,1998第1期.
[4]李旭升,郭春香,郭耀煌.《扩展的树增强朴素贝叶斯网络信用评估模型》[J].《系统工程理论与实践》,2008年第6期.
[5]涂艳,王翔宇.基于机器学习的P2P网络借贷违约风险预警研究——来自“拍拍贷”的借贷交易证据[J].统计与信息论坛,2018,33(6):75-82.
作者系兰州财经大学金融学院2019级硕士研究生
