可解释个性化推荐学习平台的构建与算法研究
2020-03-24周闻,岑岗
周 闻,岑 岗
(浙江科技学院 a.机械与能源工程学院;b.信息与电子工程学院,杭州 310023)
随着教育信息技术的发展,在线学习逐渐得到人们的关注。这种新的学习方式给传统教学模式带来了前所未有的冲击,如2012年Udacity、Coursera等在线学习平台的出现,获得了广大学生的一致好评。与传统教学模式相比,在线学习平台凭借其可随时随地学习、资源重复利用、投入资金较少、每个人都可享受高质量课程资源等优势,成为教育领域的热门研究主题[1]。但是在享受这些便利的同时,也面临着信息过载等问题,越来越多的课程资源使得学生如何在学习平台上选取适合自己的课程变得十分必要。因此,个性化推荐功能应运而生,它能挖掘学生的需求或兴趣,根据相关算法进行有效推荐[2]。中国的个性化推荐技术在在线学习领域中的应用起步较晚,发展速度较慢。就目前的研究来看,大部分在线学习平台的个性化推荐功能的研究都是对推荐系统进行总体设计或对平台的资源推荐策略、学习路径进行研究,例如:张琳等[3-5]对学习资源的个性化推荐系统进行设计研究,以提高学生的学习效率;钱研[6]对学习平台的个性化学习资源推送策略进行了研究,构建了资源推送模型,为学生提供真正合适的课程;叶露[7]在学习平台的个性化推荐与学习路径规划上进行了研究,解决了学习资源的信息过载问题,对学生的学习规划有指导意义。上述研究虽然在推荐的准确性、多样性和新颖性上有了一定的提升,但没有从推荐功能的服务对象、用户体验角度来进行设计,这就造成了许多问题:推荐的相关课程缺乏解释,学生对学习平台推荐的结果感到困惑,不知道推荐的依据是什么,尤其是对陌生领域的推荐内容;推荐的课程相关性较低,不是学生想要学的课程;获取推荐结果的速度跟不上请求速度,造成用户体验下降;出现了许多推荐结果不可解释的现象[8]。针对这些问题,我们以车辆工程专业为例,提出构建可解释的个性化推荐在线学习平台,利用多种推荐算法并行计算的方式来进行混合推荐,对学生进行课程的个性化推荐。以可解释性为目标,根据相应的特征以完整的、语义连贯的句子模板生成解释语句,为学生提供“推荐+解释”的组合,从而优化推荐效果和用户体验,提高了平台的可信任度和透明度。
1 可解释个性化推荐学习平台的总体设计
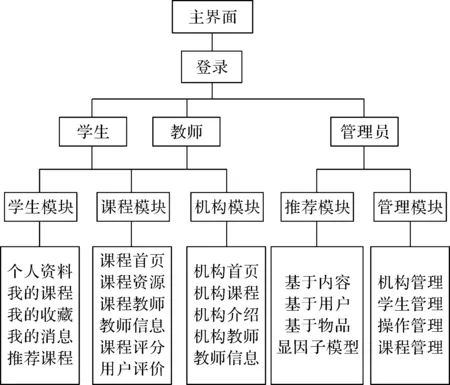
图1 可解释个性化推荐学习平台整体框架
整个平台的框架分为学生模块、课程模块、机构模块、推荐模块和管理模块5个子模块,各个子模块分别包括若干个功能模块,具体如图1所示。
2 平台可解释个性化推荐功能的算法
平台的可解释个性化推荐功能的核心是采用混合推荐方式,通过基于内容的推荐算法、基于物品和基于用户的协同过滤推荐算法、基于显因子模型(explicit factor models)推荐算法[9]等4种推荐算法并行计算进行推荐,并根据各自特征标签基于模板生成解释语句,向学生解释为何推荐相关课程。在不同的情况下,以不同的权值分别进行个性化推荐课程。当平台起步的时候,学生数据不充足的情况下,会产生“冷启动”。“冷启动”主要包括3类:一是用户“冷启动”,当平台刚起步时,对新的学生用户进行个性化推荐;二是物品“冷启动”,将新的课程推荐给可能对其感兴趣的学生;三是系统“冷启动”,在平台学生用户行为少且只有少数课程信息的情况下为其进行个性化推荐。
针对用户“冷启动”,平台设有热门课程,将最热门的课程推荐给学生,同时平台基于内容的推荐算法,通过提取学生注册时自定义的标签及其选择的感兴趣主题,为学生推荐其可能感兴趣的课程[10]。针对物品“冷启动”,平台在教师上传课程时,通过对课程的标签分类进行语义分析,得到可供教师选择的课程主题,教师也可自定义设置课程的主题。通过这一方式完成对课程的初步分类,为后续推荐做好准备。针对系统“冷启动”,基于以上两种“冷启动”问题解决方案,平台利用学生注册时选择的感兴趣主题与学习课程标签进行匹配来完成初步的推荐,以解决在学生用户行为少,只有一部分课程信息时的推荐问题。
当学生的行为记录(如评论和评分等)超过一定量的时候,可以用基于物品的协同过滤推荐算法(ItemCF)和基于用户的协同过滤推荐算法(UserCF)来进行计算。根据学生喜欢的课程,采用ItemCF推荐与其所喜欢的课程相似的课程,采用UserCF找到与目标学生有相同兴趣的学生,将有相同兴趣的学生所喜欢的课程推荐给目标学生[11]。用显因子模型对学生给予课程的评论及打分进行短语级的情感分析,构建相应的情感词典和矩阵,计算学生对每个特征的喜好程度来对课程进行推荐,并根据各自的特征形成解释语句,实现可解释功能。
2.1 基于内容的推荐算法
学生在注册时,系统会让他选择自己感兴趣的特征标签,学生的特征向量取所有标签的权重平均值,用P(Ci)表示学生的兴趣特征,课程的特征向量用TF-IDF(词频-逆向文件频率)方法来计算。假设N为课程的总数量,fT,ij=fij/max(fj),fID,i=log(N/ni)。其中,fij为特征Ki在课程Cj中出现的次数,max(fj)为课程Cj中特征Ki出现的最大次数,ni为包含第i个特征的课程数量,fj为第j门课程的所有特征标签数量。因此,第i个特征在第j门课程中的TF-IDF权重Wij为fT,ij×fID,i,第j门课程的特征向量Fj={W1j,W2j,…,Wij}。
对学生兴趣向量表和课程特征向量表进行余弦相似度的计算,取值较高的课程资源信息推送给学生,相似度计算公式为
(1)
式(1)中:Wi为学生对课程第i个特征的喜好程度;Wj为第j门课程中包含该特征的程度(出现该特征的频率)。
每个学生的操作都是独立的,不依赖于其他学生的用户行为,可以较好地解决部分“冷启动”和稀疏性的问题。
2.2 基于用户的协同过滤推荐算法
学生在使用平台时会留下大量的显性反馈行为数据和隐性反馈行为数据。显性反馈行为即学生明确表示对课程喜好的行为,包括对课程的收藏操作、评分操作等;隐性反馈行为即不能明确反映学生喜好的行为,包括观看时长、评论记录等。平台通过这些数据及学生和课程的标签,计算出学生之间的余弦相似度,在相似度的基础上构建学生与课程的关联。
1)选取与目标学生u最接近的N个学生(用下标v表示N个学生中的某个学生);
2)根据N个学生对课程i的不同行为(观看时长、评分、收藏、评论等),确定N个学生与课程i的关联度rv i;
3)确定目标学生u与N个其他学生的不同相似度mu v;
4)计算目标学生u与课程i的推荐度
(2)
5)将推荐度高的课程推荐给学生,并生成“学过该课程的学生也喜欢此课程”的解释语句,实现可解释功能。
2.3 基于物品的协同过滤推荐算法
若两门课程同时被多名学生喜欢(对课程有过收藏操作、积极评论、高评分等行为),则它们之间有一定的相似性;同时喜欢它们的学生越多,则它们之间的相似性越高。M(i)表示喜欢课程i的学生数量,M(j)表示喜欢课程j的学生数量,M(i)∩M(j)表示同时喜欢课程i和课程j的学生数量,因此课程之间相似度
(3)
平台通过课程之间的相似度及学生的历史行为为学生生成推荐列表。课程j对学生u的推荐度
(4)
式(4)中:i为某学生喜欢的某一课程;j为某集合中的某一课程;N(u)为学生喜欢的课程集合;S(i,k)为与课程i最相似的k门课程的集合;wji为课程j和课程i的相似度;rui为学生u对课程i的喜欢程度,学生u对课程i的收藏操作或观看该课程的时间越长,则表示学生u对课程i的喜欢程度越高。
之后,将推荐度高的课程推荐给学生,并生成“此课程与某课程推荐度为多少”的解释语句,以实现可解释功能。
2.4 基于显因子模型的推荐算法

图2 基于显因子模型的推荐算法的可解释推荐步骤
显因子模型方法从用户文本评论当中提取显式的物品特征,并将矩阵分解中的每个潜在维度与特定的显式特征进行对齐,使分解或预测过程能够被跟踪,为推荐提供显式的解释,有助于提高推荐系统的可信度[2]。将该方法运用到在线学习平台上同样适用。随着平台的运用,会有越来越多的学生行为数据如学生对课程的评分和评论在积累,这些信息用于更全面地评估学生的偏好非常有价值,可以用来提供更细致更可靠的推荐解释,以说服学生或帮助学生选择更适合的课程。学生的文本评论中包含了关于学生对学习课程特征的情感、态度和偏好的丰富信息,从评论中提取明确的课程特征和相应的学生意见,不仅有助于了解学生的不同偏好,做出更好的推荐,还有助于了解为什么推荐某一特定的课程,做出更直观的解释。基于显因子模型形成可解释推荐的步骤如图2所示。
2.4.1 构建情感词典
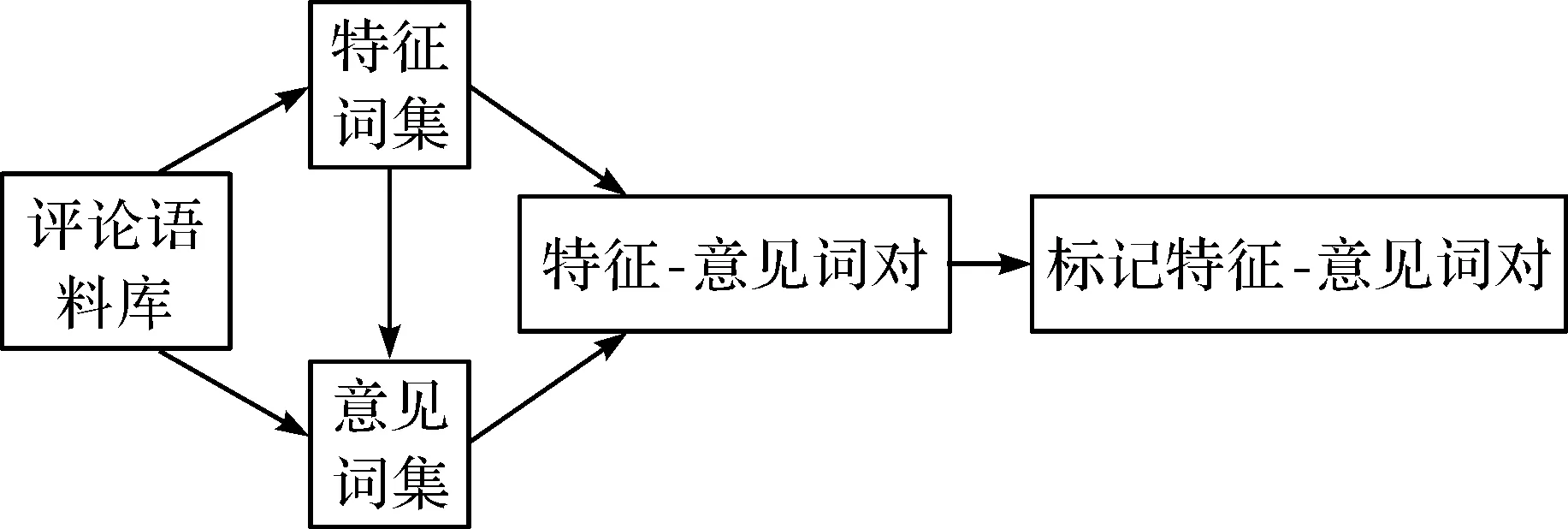
图3 情感词典的构建
从学生文本评论语料库中抽取评论的特征词,如讲课、深度、逻辑思维等,并抽取对这些特征的意见词,如很棒、很好、清晰、通俗易懂等,得到特征-意见词对。对词对进行短语级情感分析,判断学生的情感是肯定或否定并进行标记。如果这些词对是积极的情感,则用+1表示;反之则用-1表示。其中每个条目都是一个(F,O,S)三元组,类似(讲解,清晰易懂,+1)、(回答问题,细致耐心,+1)等,其中F是特征词或短语,代表课程的特征,O是意见词,代表学生对特征的表达意见,S是意见词在评论中的情绪,可以是积极的,也可以是消极的。情感词典的构建如图3所示。
2.4.2 构建矩阵
需要构建3个矩阵,第一个是学生评分矩阵A,表示学生对课程的直接评分,取值范围为1~5,没评分的记为0。第二个是学生-特征关注矩阵X,表示学生对课程特征的喜好程度,从第一步构建的情感词典中将所有学生评论的显式特征组成特征词集合F={F1,F2,…,Fr},设学生的集合为u={u1,u2,…,um},然后提取学生i的所有评论三元组,找到学生ui与课程特征Fj的关系,用tij表示学生i对特征Fj提到的次数,将学生-特征关注矩阵中的每个元素定义为
(5)
式(5)中:N为学生评分的最高分数(设置为5)。通过构造sigmoid函数将tij缩放到与学生评分矩阵A相同的范围[1,N]。第三个是课程-特征质量矩阵Y,表示某一课程的所有评论包含特征的质量。设课程的集合为C={C1,C2,…,Cn},将所有的课程评论三元组组成集合P={P1,P2,…,Pz},其中Pi为课程i的所有评论三元组。将课程i对特征Fj的包含质量矩阵元素定义为
(6)
式(6)中:Pij为Pi包含特征Fj的次数;sij为Pij次提及的特征Fj的情感均值。
2.4.3 估计矩阵缺失值
估计矩阵A、X、Y的缺失值,矩阵X、Y中的非零数值表示已有的学生或课程与显式特征之间的关系,而0则表示尚未清楚的缺失值。为了估计这些缺失值,利用二次损失函数来最小化估计值与真实值之间的差距。X、Y的最优化损失函数为
(7)
式(7)中:U1为学生的显式特征矩阵;U2为课程的显式特征矩阵;V为所有显式特征集合向量;λx和λy为正则化系数;F为损失函数的范数。
同理,学生评分矩阵A的缺失值也会用到显式特征,考虑到学生对课程评分时还会考虑其他一些潜在的特征,所以也引入了隐式特征来对缺失值进行调整。A的最优化损失函数为
(8)
式(8)中:P为学生的显式和隐式特征矩阵的建模;Q为课程的显式和隐式特征矩阵的建模。
2.4.4 计算矩阵联系程度

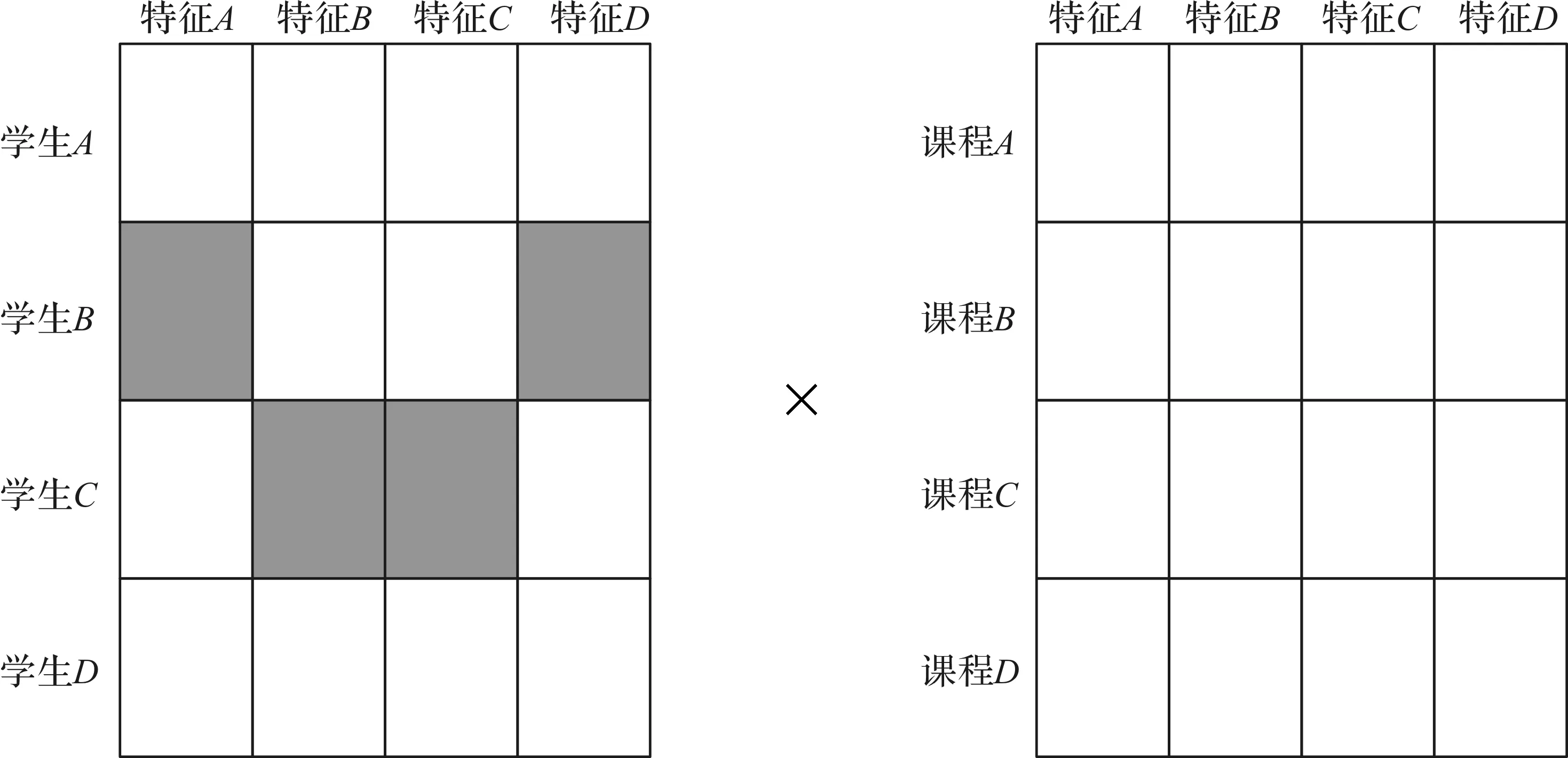
图4 学生与课程的特征向量矩阵相乘
然后计算第i个学生对第j门课程的评分
(9)
式(9)中:0≤α≤1,α是用来控制基于特征计算出来的学生-课程评分矩阵与学生对课程直接评分矩阵之间权衡的比例,具体的值由试验确定。
2.4.5 生成解释推荐理由
选择打分最高的前几门课程推荐给学生,并根据特征形成推荐语句向学生解释推荐理由。推荐语句以完整的语义连贯的句子模板来构造,如“你可能对某特征很感兴趣,而这门课程在这方面表现良好”,根据个性化算法选择特征来构建解释语句可以提高推荐系统的说服力。
3 结 语
可解释个性化推荐在线学习平台是教育信息化的必然产物,构建可解释个性化推荐在线学习平台,能够对学生的学习过程起到一定的推动作用。本平台结合推荐算法,采用混合推荐方式并行计算,对课程进行个性化推荐并根据相应特征生成解释语句向学生解释推荐理由,从而可以使学生更好地选择合适的课程,提高学生的学习效率,改善学习平台的推荐效果和用户体验,提高平台的可信度和透明度。需要说明的是,本平台还有较大的改进空间,比如引入更多的特征,或捕获课程的特征之间更复杂的联系,而不是单一的特征-意见词对;还可以采用深度学习模型,进行短语级的情感分析,甚至句子级别的分析,来提高推荐的效果。
