课堂场景下学习者情感识别研究
2020-03-24王国中
苏 超,王国中
(上海工程技术大学 电子电气工程学院,上海201600 )
0 引言
近年来,随着互联网技术的快速发展以及大数据、云计算、AI(人工智能)等新技术的发展,智能化教育成为一种新的教育趋势。在《计算神经科学前沿》杂志中提到:“智能化教育中一直被忽略的词就是情感”[1],而情感作为一种非智力因素,能够影响和调节认知活动。心理学研究表明:积极的情感有助于激发学习者的学习动力、培养学习兴趣,促进认知过程;而消极的情感则会影响学习者的耐心度、注意力,阻碍认知过程[2-3]。
人对情感的表达是复杂且微妙的,同样对情感的识别和解读也是多通道协同完成的,包括表情、姿态、语言和声调等[4]。当前,针对情感识别,研究者们主要围绕生理信号、心理测量以及外显行为展开研究[5]。
其中,又以基于面部表情的情感识别居多。虽然面部表情能够表达人的大部分情感,但也存在一些不可避免的问题,如:面部遮挡、表情微妙以及姿态改变等,因此,基于面部表情的单模态情感识别方法并不足以准确的识别出情感状态。现实生活中,人们往往也是综合语音、面部表情、肢体动作等多种信息来判断一个人的情感状态,利用信息之间的互补性,从而准确识别出情感状态[6]。
在过去的十几年里,关于课堂中学习者的情感识别研究逐渐多了起来,如:文献[6]中提出一种基于遗传算法的多模态情感特征融合方法,利用遗传算法对单个模态的情感特征进行选择、交叉以及重组;文献[7]中提出一种基于皮肤电信号与文本信息的双模态情感识别系统;文献[8]中提出了基于双边稀疏偏最小二乘法的表情和姿态双模态情感识别方法。于此同时,国外学者们也进行了相关研究,如:Ray A,Chakrabarti A[9]指出,情绪在人的认知过程中起着重要的作用,因此提出一种新的情感计算模块,采用生物、物理(心率、皮肤电和血容量压)和面部表情方法,用来提取学习者的情感状态;Li C,Bao Z,Li L[10]等人提出了基于生理信号的情感识别方法。通过将原始生理信号转化为光谱图像,利用双向长短期记忆循环神经网络(LSTM-RNNS)学习特征,最后利用深度神经网络(DNN)进行预测。
经研究发现,上述诸多方法本质上并不完全适合于中国课堂上学习者的情感识别,主要有以下原因:
(1)〛数据集。目前关于情感识别研究的数据集都是国外的一些大学或者研究机构采集的,一是不符合课堂场景,其次受地域文化以及肤色人种的影响,国外采集的那些数据集表情与国内的人脸表情相差很大。
(2)情感分类。在情感识别领域,关于情感的分类有很多种,其中最基本的是Ekman 等[11-12]提出的6 种基本情感:高兴、愤怒、厌烦、恐惧、悲伤以及惊讶。研究发现,在学习过程中这6 种基本情感并非全部起到关键作用[12]。因此,针对课堂上学习者的情感分类,需要定义一种符合课堂场景的情感类别。
因此,本文提出一种基于表情和姿态的双模态学习者的情感识别模型,以解决课堂上学习者情感识别存在识别准确率低、特征提取困难等问题。研究中将课堂学习者的面部表情定义为专注、厌烦、困惑、疲惫和走神5 种表情;将课堂中学习者的上身姿态定义为抬头、低头、趴下和左顾右盼4 种姿态。通过最终的决策融合,定义课堂上学习者的学习状态主要包括认真听讲、不感兴趣、疑惑/没听懂、犯困/疲劳、开小差、睡觉、交头接耳和不确定等8 种状态。
1 模型设计
1.1 方法概述
基于表情和姿态的双模态学习者情感识别模型的整体流程如图1 所示。主要包含2 个模块,分别是情感识别模块和决策融合模块。首先,利用自主采集的数据集作为训练集和测试集,通过改进Tiny_YOLOv3 目标检测算法得到ER_Tiny_YOLOv3,从而进行面部表情和姿态识别。然后,针对课堂教学环境,将表情识别结果和姿态识别结果在决策层面进行融合,生成课堂评价,判断出学习者当前的学习状态。
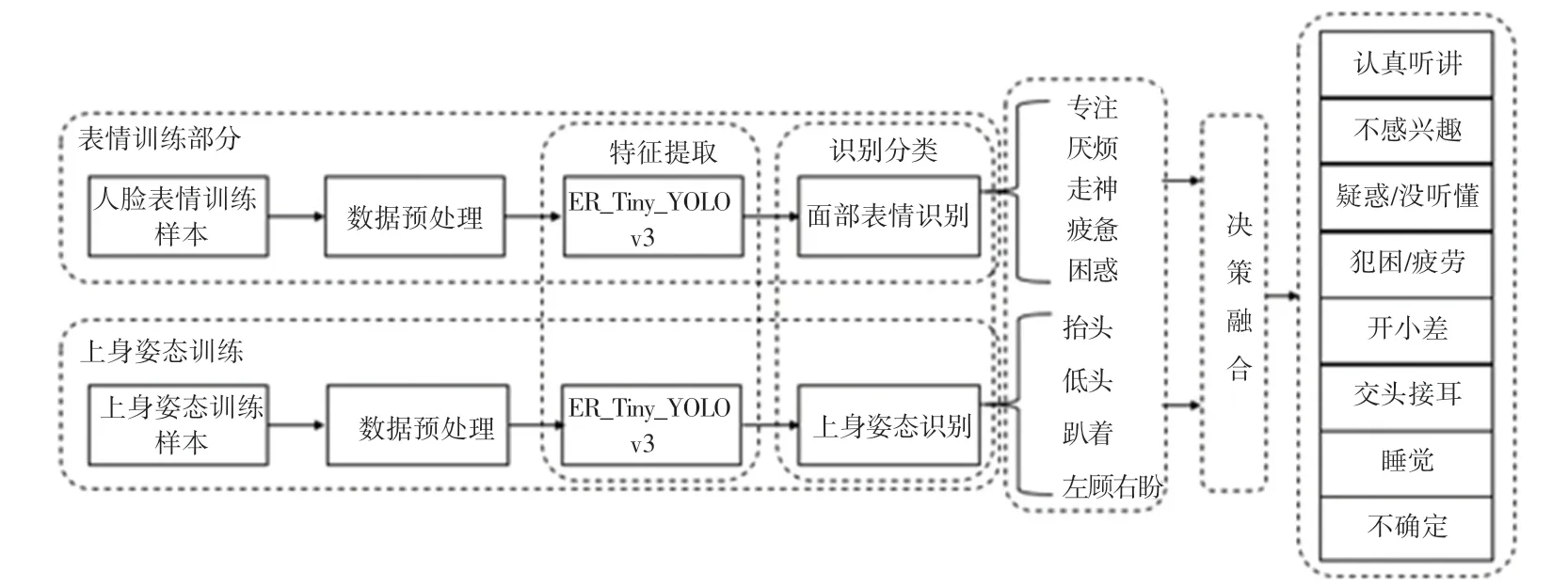
图1 基于表情和姿态的双模态情感识别模型图Fig.1 Diagram of a dual-modal emotion recognition model based on expressions and gestures
1.2 Tiny_YOLOv3
Tiny_YOLOv3 是目标检测算法YOLOv3 的一种轻量化版本,采用Tiny Darknet 网络结构,如图2 所示。
Tiny_YOLOv3 的损失函数主要包括3 个部分,分别是目标位置损失、目标置信度损失和目标分类损失。Tiny_YOLOv3 的损失函数如式(1)所示:

其中:lbox表示目标位置损失;lobj表示目标置信度损失;lcls表示目标分类损失。如式(2)所示:

其中:S2表示13×13,26×26;B表示box,表示如果在i,j处的box有目标,其值为1;否则为0;而反之。λcoord表示lbox权重;xi,yi,wi,hi为真实框的中心位置和长宽值;表示预测框的中心位置和长宽值;(2-wi×hi)表示根据真实框的大小对lbox权重进行修正;λnobj表示lobj权重;λclass表示lcls权重;ci表示真实框置信;c'i表示预测框置信。
Tiny_YOLOv3 的损失函数首先计算预测框和真实框的交并比(Intersection over Union,IoU),示意如图3 所示。将IoU 最大的预测框与真实框相匹配,通过匹配的预测框所预测的结果与真实框相比较,得出目标位置损失、目标置信度损失以及目标分类损失。IoU 表达如式(3)所示:

其中:I表示真实框与预测框的交集;U表示真实框与预测框的并集。

图2 Tiny_YOLOv3 网络结构图Fig.2 Tiny_YOLOv3 network structure diagram

图3 IoU 示意图Fig.3 Schematic diagram of IoU
2 模型改进
虽然Tiny_YOLOv3 作为轻量化模型,很适用于实际工程项目中,但是检测效果并不是很好。原因在于 Tiny _ YOLOv3 的 backbone 是浅层网络Darknet19,且Tiny_YOLOv3 只融合了13x13、26x26两个尺度上的检测结果。然而,正是由于Tiny_YOLOv3 的网络结构浅,因而时效性比较好。为了提升课堂中学习者情感识别的准确性,本文从卷积结构、锚框聚类以及损失函数3 方面对Tiny_YOLOv3 进行了改进。
2.1 卷积结构改进
注意力机制(Attention Mechanism)是一种聚焦于局部信息的机制,目前已广泛应用于计算机视觉领域。注意力机制可以分为:通道注意力机制、空间注意力机制以及混合域注意力机制。SEnet(Squeeze-and-Excitation Networks)[13]是典型的通道注意力机制,其通过建模各个特征通道的重要程度,针对不同的任务增强或者抑制不同的通道,从而提升精度。SEBlock 结构如图4 所示。
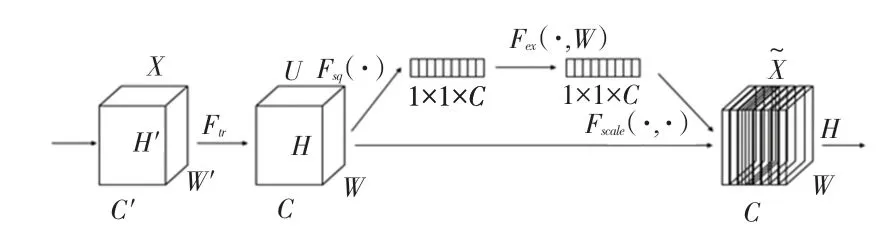
图4 SEBlock 结构图Fig.4 SEBlock structure diagram
在图4 中,X∈RH'*W'*C'表示网络的输入,Ftr表示一系列卷积操作的集合,V=[v1,v2,…,vc]表示卷积操作,U∈RH*W*C表示经过一系列卷积操作的输出,U=[u1,u2,…,uc]其表达如式(4)所示:

Fsq(·)操作是将U的输出压缩成Z∈R1*1*C。传统的卷积操作大多集中于局部信息,无法提取整体信息。因此,通过Fsq(·)操作来实现,如式(5)所示:

Fex(·,W)主要利用非线性的sigmoid 激活函数,保证非线性的前提下进行通道选择,如式(6)所示:

最后,通过Fscale(·,·)操作将学习到的通道权重应用到原有的特征上,如式(7)所示:
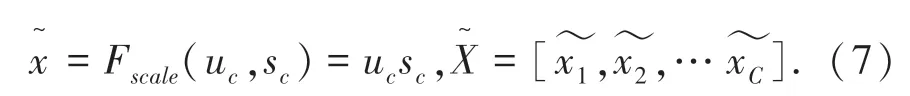
SEBlock 可以作为一种子模块插入到不同的卷积结构中,本文通过加入SEBlock 对Tiny_YOLOv3网络结构进行改进,得到一种适用于学习者情感识别的模型ER_Tiny_YOLOv3,网络结构如图5 所示。

图5 ER_Tiny_YOLOv3 网络结构图Fig.5 ER_Tiny_YOLOv3 network structure diagram
2.2 损失函数改进
在目标检测中,评价一个目标物体是否正确的被检测出,IoU 是一个重要的度量标准[14]。但IoU有其不可避免的缺点,如果预测框和真实框二者没有相交,则IoU 的结果为0,此时便无法进行学习训练。
针对上述问题,Hamid 等人提出了广义IoU 的概念(Generalized Intersection over Union,GIoU)[15],解决当前的问题,如式(8)所示:

其中:Ac表示预测框和真实框最小闭包区域面积,U表示预测框和真实框的并集。根据图3,Ac的表达如式(9)所示:

本文在添加注意力机制SEBlock 改变网络结构的基础上,将GIoU loss 作为损失函数的一部分,用来改进目标位置损失lbox。改进后的目标位置损失lbox'为:
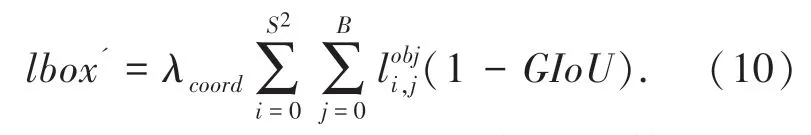
则改进后的ER_Tiny_YOLOv3 损失函数为:

2.3 k-means 锚框聚类
Tiny_YOLOv3 和YOLO v3 一样,引入了锚框(anchor)的概念,通过K-means 聚类算法[16]得到anchor 的数量和大小。但Tiny_YOLOv3 模型是通过在VOC 或COCO 数据集上聚类而得到anchor 的数量和大小的,不适合课堂中学习者的情感识别。因此,本文采用K-means 算法在自制的数据集上进行重新聚类,得到适合于学习者情感识别的anchor。
k-means 算法采用距离作为相似性指标,其中K 表示聚类的类别数,算法流程图如图6 所示。
由图6 可见,在重新聚类之前,需要先确定K值。而在先验知识缺乏的情况下,要想确定K 值是非常困难的。通常确定K 值的方法有二种:肘部法和轮廓系数法。本文采用肘部法用来确定K 值,肘部法的核心指标是通过SSE(sum of the squared errors)来描述,如式(12)所示:
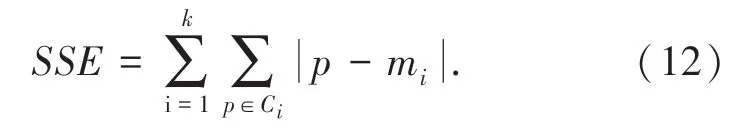
其中:Ci表示第i个簇;p表示Ci中的样本点;mi是Ci的质心,即所有样本的均值;SSE表示所有样本的聚类误差,代表了聚类效果的好坏。实验结果如图7 所示。
大气氧化性OX(OX=O3+NO2)表征大气的氧化能力(安俊琳等,2007),同时可以很好地反映O3的化学生成潜势(Shiu et al.,2007)。OX区域贡献和局地贡献存在明显的季节变化,主要受区域背景O3的影响,一般是夏季最强。

图6 K-means 算法聚类流程图Fig.6 K-means algorithm clustering flowchart
从图7 可以看出,在K值为6 时,曲率最高。因此,选取K=6。
K值确定后,利用K-means 算法对自制的数据集进行重新聚类,实验结果如图8 所示。最终聚类得到的anchor 值为:10,18、12,23、13,28、16,35、20,45、30,63,用来替换Tiny_YOLOv3 的anchor 值:10,14、23,27、37,58、81,82、135,169、344,319。
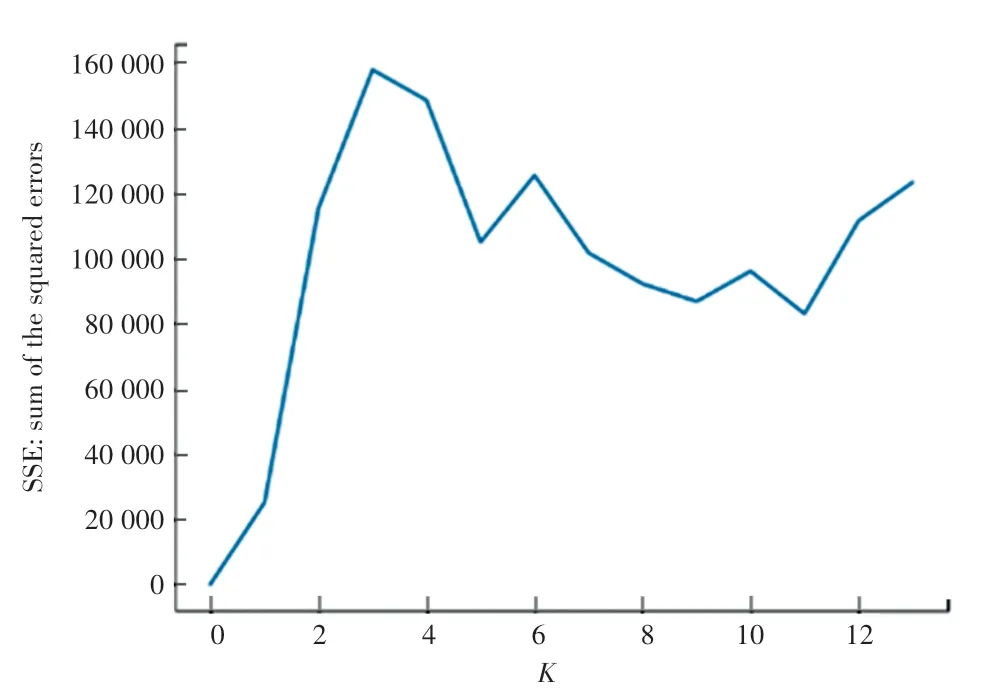
图7 利用肘部法确定K 值实验图Fig.7 The experimental diagram of using the elbow method to determine the K value

图8 K-means 算法重新聚类结果图Fig.8 K-means algorithm re-clustering result graph
3 多模态融合方法
本文针对课堂中学习者的情感识别,采用决策层融合的方法。定义课堂上学习者的表情有:“专注”、“走神”、“疲惫”、“困惑”和“厌烦”5 种表情,而上身姿态有:“抬头”、“低头”、“左顾右盼”和“趴下”4 种行为。在实际场景中,只有当学习者处于“抬头”状态下才能完整观察到学习者的面部表情。因此,本文只针对“抬头”这种情况进行最后的决策融合。而其它3 种行为对于课堂学习者来说,很容易判别出学习状态。4 种上身姿态对应的决策融合图分别对应图9 中(a)、(b)、(c)、(d)图。

图9 4 种不同上身姿态对应的决策融合图Fig.9 Decision fusion diagram corresponding to 4 different upper body postures
由图9 得知,当学习者处于抬头情况下,此时才能比较完整的检测出学习者的面部表情,从而进行面部表情识别,进而结合上身姿态和面部表情判定此时学习者的情感状态。而当学习者处于低头时,由于检测不到完整的面部表情,所以决策融合归结为不确定状态。同理,针对趴下和左顾右盼的上身姿态,在决策融合时不必考虑面部表情,直接归结为睡觉/犯困和开小差/交头接耳状态。
4 实验结果及分析
实验环境为:
软件环境:Windows 10 下的Pytorch 平台;
硬件环境:处理器是Intel(R)Xeon(R)W-2123 CPU@3.60GHz;
运行内存:16.0GB;
4.1 数据集
当前,人脸表情数据库的种类有很多,最常用的主要有日本女性人脸表情数据库(JAFFE)、卡内基梅隆大学的CK(Cohn-Kanade)人脸表情数据库及其扩展数据库CK+人脸表情数据库等[17]。而目前唯一公开的表情和姿态双模态情感数据库只有FABO 数据库[18]。但是,由于FABO 数据库ground truth label 很繁琐,且每个人的样本和情感类别数目不一致,同时外国人的脸部表情特征和中国人的人脸表情特征明显不同,且数据库的采集环境并不是针对课堂环境,因此训练出来的模型并不适合课堂学习者的情感识别。因此,本文以安徽省池州市东至三中高一某班的全体学生为采集对象,自主构建数据集。
4.2 网络训练和超参数设置
ER_Tiny_YOLOv3 在训练时采用Tiny_YOLOv3提供的权重参数作为网络训练的初始化参数,通过在自主构建的数据集上进行训练,并进行相应的网络参数微调,使得检测效果达到最优。实验参数见表1。

表1 实验参数说明Tab.1 Description of experimental parameters
4.3 评价指标
目标检测模型一般采用准确率(Precision)、召回率(Recall)以及均值平均精度(Mean Average Precision,mAP)等指标来评价模型的效果。其中,准确率表示所有检测出的目标中,正确检测出的目标所占的比例;召回率表示所有待检测目标中正确检测出的目标所占的比例。
对于课堂中学习者的情感识别,如果对于一类表情或行为能正确的被检测出,则为真正类(True Positive,TP),相反,如果对于一个既不是表情又不是行为的位置检测为某类面部表情或行为,则为假正类(False Positive,FP)。假设学习者的情感识别中表情和行为的总数为N,则:

但是,准确率和召回率是相互影响的,一般情况下准确率高、召回率就低,而准确率低,召回率就高。因此,需要在准确率和召回率之间进行权衡。一种方式是画出准确率-召回率曲线,计算AP 值,另一种方式是计算Fβ分数。如式(14)所示:
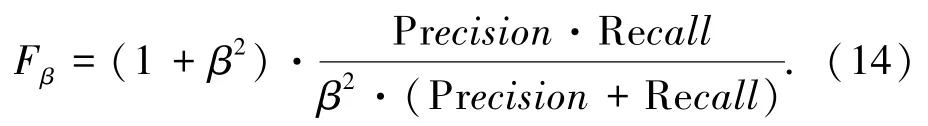
其中,当β=1 时,称为F1分数,是最常用的指标之一。
4.4 模型对比
本文通过将改进后的模型ER_Tiny_YOLOv3 与Tiny_YOLOv3 以及YOLO 系列最新算法YOLOv4 进行对比,以此来说明此模型的有效性,实验结果见表2。
从表2 的结果可以得知:改进后的模型ER_Tiny_YOLOv3 相比于原模型Tiny_YOLOv3,mAP@0.5 提升了17%,Precision 提升了35%,而F1 分数提升了22.6%。相比于YOLOv4,mAP@0.5 提升了19%,Precision 提升了27%,F1 分数提升了21.4%。但是由于ER_Tiny_YOLOv3 在Tiny_YOLOv3 的基础上加入了注意力机制SEBlock,所以参数比Tiny_YOLOv3 多了1/10,检测时间比Tiny_YOLOv3 慢了约1/100,二者几乎没有区别。但相比于深层网络YOLOv4,检测时间大幅缩短,只有YOLOv4 检测时间的1/20。同时,ER_Tiny_YOLOv3 的参数只有YOLOv4 的1/10,可见,网络参数大幅度减少。
实验结果表明,改进后的ER_Tiny_YOLOv3 模型是一种兼顾速度和精度的模型。YOLOv4、Tiny_YOLOv3 和改进后的模型ER_Tiny_YOLOv3 的检测结果对比如图10 所示。

图10 各模型检测结果对比图Fig.10 Comparison of test results of various models
从图10 可以看出,对于课堂上学习者的情感识别,检测效果最好的是ER_Tiny_YOLOv3 模型。而作为YOLO 系列最新的检测算法YOLOv4,检测效果反而一般。虽然Tiny_YOLOv3 检测速度最快,但是检测效果明显不如ER_Tiny_YOLOv3,漏检的情况比较多。ER_Tiny_YOLOv3 在检测速度上与Tiny_YOLOv3 相差无几的情况下,检测效果明显好于Tiny_YOLOv3,且识别效果比YOLOv4 效果更好。可见,本文提出的学习者情感识别模型是一种兼顾速度和精度的模型,适用于课堂场景下学习者的情感识别。
5 结束语
针对当前智能化教育环境中的“情感缺失”问题,本文提出了一个快速、准确、轻量的学习者情感识别模型。通过对Tiny_YOLOv3 的卷积结构、损失函数以及锚框值进行改进,经过训练得到一个适合于课堂中学习者情感识别的模型ER _Tiny _YOLOv3。同时,针对最终的课堂评价,采用决策层融合方法用来判断学习者的学习状态。实验结果表明,相比于Tiny_YOLOv3 和YOLOv4,识别效果更好。当然,还有很多问题需要进一步研究,比如:决策层融合的方法不具有完整的代表性。如学习者在低头的情况下,也有可能在思考问题,而本文章将其归结于不确定状态。同理,针对趴下和左顾右盼的情况,也有同样的问题。因此,下一步将重点研究更具代表性的融合方法。
