基于注意力生成对抗网络的图像超分辨率重建方法①
2020-03-23丁明航邓然然
丁明航, 邓然然, 邵 恒
(长安大学 信息工程学院, 西安 710064)
图像超分辨率是一种典型的不适定[1]问题, 其作为一种基础的视觉问题, 在学界和人工智能公司中引起了越来越多的关注, 并被广泛地引用于安全和监控成像, 医学成像和图像生成等领域.图像超分辨率目的在于通过模糊的低分辨率(Low Resolution, LR)图像生成视觉质量较好的高分辨率(High Resolution, HR)图像.为了解决这个不适定问题, 已经提出了众多的图像超分辨率算法, 包括基于插值的[2], 基于重构的[3]和基于学习的方法[4-10].
其中基于插值的方法[11]能较好地保护图像的边缘,但该方法不考虑图像的内容, 只是简单地进行像素点之间的计算, 容易丢失大量细节信息, 从而导致模糊.另一种基于重构的超分辨率方法[12]结合了图像的降质模型, 解决了基于插值方法无法引入先验信息的问题.该方法虽然对复杂度低的图像效果较好, 但对纹理结构丰富的图像则效果一般.随后研究人员提出了基于学习的方法, 如Dong C 等[13]提出的SRCNN.该方法结构简单, 结果相较于其他方法更精确, 但是会损失许多图像的细节信息, 同时数据来源并不多, 所恢复出的图像纹理在视觉上还是无法令人满意.
为了进一步提高视觉质量, 生成对抗网络[14](Generative Adversarial Network, GAN)被引入超分辨率领域, 以改善图像超分辨率后失真的视觉效果.然而,SRGAN[15]由于网络结构复杂, 不能稳定训练更深层的网络, 因此其结果仍与真实图像存在差距.随后, Wang XT 等[16]研究了SRGAN 网络体系结构的两个关键组成部分: 对抗损失和感知损失, 并对每个部分进行了改进, 得到了一个增强的SRGAN (ESRGAN).该方法可以训练出更深层的网络, 提取更多纹理细节特征, 但在图像恢复时容易产生更多与真实图像不一致的伪纹理.同时该方法无法充分利用低分辨率局部特征层信息,因此, 在无法生成更加自然图像的同时浪费了深层网络的优良设计.
为了解决网络容易生成伪纹理的问题, 本文首先将注意力生成对抗网络[17]引入超分辨率方法中, 以此作为超分辨率模型的基础架构.其次, 为了降低网络结构的复杂性以更多地利用低分辨率的局部特征层信息, 本文还对注意力生成对抗网络中生成器部分进行了改进, 引入了密集残差块结构[18].最后, 在图像超分辨率重建后, 本文还利用峰值信噪比[19](Peak Signal to Noise Ratio, PSNR)和结构相似性[20](Structural Similarity Index, SSIM)这两种普遍的超分辨率评价标准对结果进行定量分析, 对比说明所设计方法的优良性能.
1 相关工作
1.1 生成对抗网络
生成对抗网络(GAN)的理论基础源自于博弈论中的二人零和博弈.GAN 强大的图片生成能力, 使其在图像合成、图像修补、超分辨率、草图复原等领域内均有广泛应用.同样, 生成对抗网络的结构也被应用于本文的基础框架中.GAN 的基本框架包含一个生成器模型(Generator model, G)和一个判别器模型(Discriminator model, D), 如图1 所示.

图1 生成对抗网络基础结构
如图1 所示的GAN 的基础框架中, 生成器模型可用函数 G(x) 表示, 判别器模型可用函数 D(x)表示, 每个函数都有可调参数.图1(a)所示为判别器结构, 其处理流程是从训练高分辨率真实图像中采样作为输入x, 送入判别器模型 D(x) 中, D(x)通过自身的训练学习, 尽可能地输出接近1 的概率值.图1(b)所示为生成器结构,其处理流程是从训练低分辨图像中采样作为输入z, 经生成器模型生成伪造样本G (z), 然后将其作为判别器模型的输入.判别器模型的目的是尽量使 D( G(z))接近0,而生成器模型的目的尽量使它接近1, 最终在二者的互相博弈中达到平衡.
1.2 残差网络和跳跃连接
残差网络(Residual Network, ResNet)和跳跃连接(skip connection)结构经研究可以更加容易地训练深层的网络, 因而GAN 可以通过加入该结构来增加网络层数提升超分辨率图像生成能力.残差网络和跳跃连接的基本结构如图2 所示.

图2 残差网络和跳跃连接结构
图2 中, 残差网络在原始的卷积层上增加跳跃连接支路构成基本残差块, 使原始要学习的 H(x)被表示成 H( x)=F(x)+x .残差网络的残差结构使得对 H(x)的学习转为对 F(x) 的学习, 而对 F(x) 的学习较 H(x)容易.残差网络通过层层累加的残差块结构, 有效缓解了GAN 深层网络的退化问题, 使得GAN 更易稳定训练,更易生成自然真实的图像.
2 注意力生成对抗网络设计
基于生成对抗网络的基础框架, 本文将注意力递归网络引入到生成器中, 并将常规残差块替换为密集残差结构, 通过此设计来尽可能生成在视觉质量上更为理想的图像.同时, 改进判别器和感知损失函数, 以此作为用于平衡视觉质量和峰值信噪比(PSNR)的网络策略.
2.1 生成器设计
如图3 所示, 本文所设计的生成器主要由浅层特征提取网络, 注意力递归网络, 非线性映射网络和最后的上采样网络组成.图3 中, ILR和 ISR分别表示网络的输入和输出.具体地, 浅层特征提取网络使用两个卷积层(Conv)来提取低分辨率图像的浅层信息.第一个Conv 层从 ILR输 入中提取特征 F-1. 然后对 F-1做进一步的浅层特征提取, 输出为 F0, 用公式可以表示为:
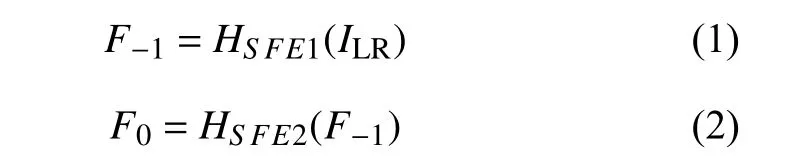
其中, HSFE1(·) 和 HSFE2(·)表示卷积运算.
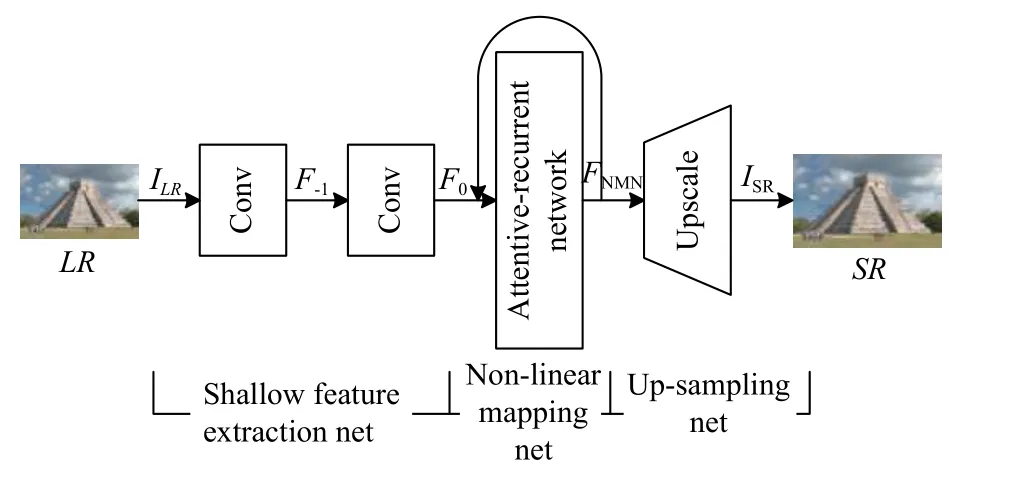
图3 生成器结构
在对原始输入 ILR进行浅层特征提取后, 其输出F0作为新的输入被送入注意力递归网络中.详细的注意力递归网络结构如图4 所示.注意力递归网络的主要目的是在输入的图像中提取出需要恢复的纹理细节,这些纹理细节将会被之后的非线性映射网络所增强并用于高分辨率图像的生成.因此能否重建出逼真自然的图像, 取决于低分辨率纹理细节提取的好坏.

图4 注意力递归网络结构
如图4 中的架构所示, 本文采用递归网络来生成视觉注意力.递归网络中的每个时间步长均包含3 层密集残差块(Residual Dense Block, RDB), 1 个循环门控单元(Gated Recurrent Unit, GRU)和1 层卷积层, 以此用来生成二维注意力图像.每个时间步长所学习到的注意力图都是一个取值介于0 到1 之间的矩阵, 其中每个矩阵元素值越大, 表示注意力就越大.在图4 中,An为注意力学习过程生成的可视化注意力图, 其中n 代表递归的次数.随着递归次数的增加, 训练出的注意力图就越能凸显细节纹理和相关结构.
递归注意力网络中用到的循环门控单元(GRU)包括一个重置门 rt和一个更新门 zt.GRU 的计算公式被定义为如下公式:
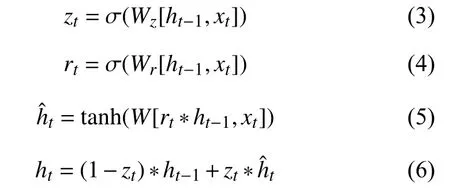
其中, ht-1和 ht分别表示上一时刻和当前时刻的隐藏层状态, 而表示当前更新状态.Wz, Wr分别表示更新门和重置门的权重, *代表卷积运算.将GRU 的输出特征送入其后的卷积层中, 即可生成二维的注意力图像.在训练过程中, 每个时间步长内输入图像均与生成的注意力图像相连, 同时它们会作为新的输入被送到递归网络的下一层中.
假设通过n 层递归注意力网络后的输出为Fn, 并用如下公式表示:

其中, HATT表示注意力网络的函数, n 代表经过几层递归操作.
在经递归注意力网络进行纹理细节特征提取后,要对这些特征进行映射.所设计的非线性映射网络具有8 层conv+ReLU 结构, 并添加了跳跃连接提升网络训练的稳定性.非线性映射网络可表示为如下公式:
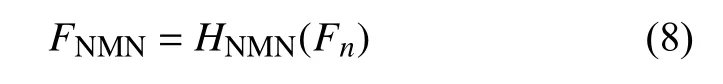
其中, FNMN是 利用非线性网络函数 HNMN输出的结果.
最后, 在生成高分辨率图像前加入了一个上采样网络, 其是由一个卷积层构成的, 以此来获得4 倍放大的超分辨率图像输出.可表示为如下公式:

其中, HUPN为上采样网络函数, ISR为超分辨率图像输出.
2.2 密集残差块设计
为了进一步提高GAN 的图像恢复质量, 本文设计了密集残差块结构, 并将其应用到注意力递归网络中,其结构如图5 所示.如图5(a), 首先在原有残差块基础上移除BN 层.当训练和测试数据集的统计数据差异很大时, BN 层往往会在生成图像中引入伪纹理并限制泛化能力.因此, 为了网络的稳定训练, 需要移除BN 层.同时, 移除BN 层有助于降低计算复杂性和减小内存开销.如图5(b), 在移除BN 层后又将密集块与跳跃连接进行结合, 前面的RDB 和后续每一层都的输出都有直接连接, 这不仅保留了前馈性质, 还充分提取了局部特征层信息, 提升了网络的容量.

图5 密集残差块结构
2.3 判别器设计
除了改进的生成器结构, 本文还改进了判别器.如图6 所示, 改进的判别器的网络结构和参数设置与原始SRGAN 的判别器不同.具体来说, 输入待判别的高分辨率图片, 先经过7 层的卷积层抽取图片特征, 再将图像数据的维度压平(flatten), 最后经全连接层(Fully Connected layer, FC)和Sigmoid 函数输出判别的结果.本文生成对抗网络经判别器对真实图像与生成图像的判别, 反馈到生成器中, 使得权重参数变化更加灵敏,以此改善了网络退化的问题.原始GAN 生成器G 在初始训练时其性能远不如判别器D, 这样便会产生模型崩溃(model collapse)问题.为此, 本文改进了原始GAN 的损失函数.该损失函数是基于L1 范数设计的,同时包含了判别器的重构误差.判别器使用该损失函数在提升图像质量的同时还提升了生成器G 的学习能力.

图6 判别器结构
首先图像像素级误差可以认为是服从高斯分布的,基于L1 范数的损失函数被定义为:
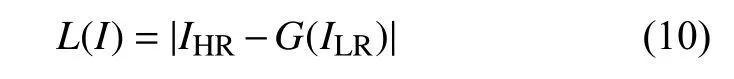
式中, 高分辨率图像用 IHR表 示, 低分辨图像用 ILR表示.需要迭代的生成器和判别器损失函数其优化规则由式(11)表示:

其中,

其中, 高分辨率图像用 x 表示, 低分辨图像用 z表示, 超分辨率图像用 y表示, 判别器关于高分辨率图像的损失用 LDr表示, 低分辨率图像的损失用 LDf表示.λk表示k 的增量, kt表示k 的第t 次迭代结果, k的值改变可以用来提升生成器的学习能力.γ是超分辨率图像误差的期望与高分辨率图像的期望值之比, 该参数的值可以提升生成图像的质量.
3 实验分析
3.1 评价指标
本文使用峰值信噪比(PSNR)和结构相似性(SSIM)这两种基础方法作为评价指标, 以此来说明图像超分辨率方法性能的优劣.在图像超分辨率评价中,PSNR 的值越高就说明图像分辨率越高, 或图像越接近真实高分辨率图像, 其是利用均方误差(Mean Square Error, MSE)进行计算的:

式中, m ×n尺寸的图像均用I 与K 表示.
PSNR 被定义为:

一般情况下, PSNR 的单位被设置为dB, 数值越大图像视觉质量越高.
图像结构相似性是一种符合人类主观感受的评价指标.通常情况下, SSIM 的值越靠近1, 代表超分辨率图像与原始图像结构越相似, 也就是失真越小, 质量越好.SSIM 被定义为:
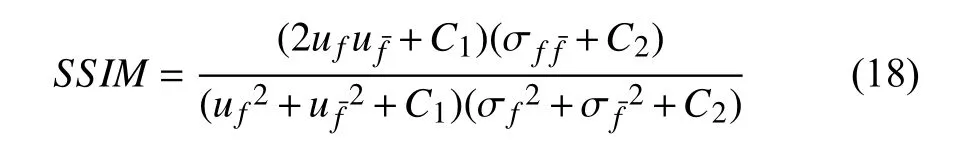
式中, uf表示真实高分辨率图像的平均灰度值, σf表示真实高分辨率图像的方差, 而表示超分辨率图像的灰度值,表示超分辨率图像的方差, 最后真实高分辨率图像与超分辨率图像之间的协方差用来表示,C1和C2是常数, 这两个常数被设置为, C1=(k1*L)2,C2=(k2*L)2, k1=0.01, k2=0.03 , L =255.
3.2 数据集与训练样本
本文利用超分辨率中被广泛使用的Set5, Set14和BSD100 3 个基准数据集进行实验.所有实验均是将低分辨率图像进行4 倍放大得到超分辨率图像的.训练样本使用来自ImageNet 数据库的10 万张图像的随机样本.并在配置有NVIDIA GTX 1080Ti 的硬件设备上进行网络的训练.低分辨率图像的获取方法是利用4 倍双三次下采样方法获取.同时, 因为网络设计为全卷积网络, 所以可以向生成器中送入任意大小的图像.为了优化网络的训练效果, 本文使用Adam 作为网络优化器.并设置初始学习速率为 1 0-4, 进行200次迭代.
3.3 不同超分辨率方法结果比较
本文将测试结果同已有方法(包括双三次方法Bicubic, SRCNN 和SRGAN)作对比.测试结果均为4倍放大的公平对比.为了对比结果清楚公平地展示, 要对超分辨率图像进行相同区域的裁切放大.如图7 所示,本文超分辨率方法相较于其他方法, 无论是视觉效果还是纹理细节均有较优的表现.因此, 本文方法在兼顾降低伪纹理的产生的同时改善了图像超分辨率后的视觉质量.

图7 不同方法超分辨率图像视觉效果对比
表1 展示了不同超分辨率方法的定量比较.可以看出, 在相同放大倍数和相同数据集下, 本文方法在PSNR 和SSIM 数值上均表现最佳.表1 中, 本文方法PSNR 值为31.62, SSIM 值为0.903, 相较于其他方法评价指标的数据均有所提升.这表明本文方法所采用的注意力递归网络和密集残差结构是有效的.

表1 不同方法超分辨率结果的PSNR 和SSIM 数值对比
同时, 为了说明本文方法在训练稳定性上的优秀表现, 还同其他方法在训练过程中的PSNR 值进行了比较.如图8 所示, 在前期训练迭代中本文方法就较快地提升了PSNR 值, 并较快地趋于稳定.这说明, 相较于其他方法本文所采用的方法有较快的收敛速度和较好的网络性能表现.
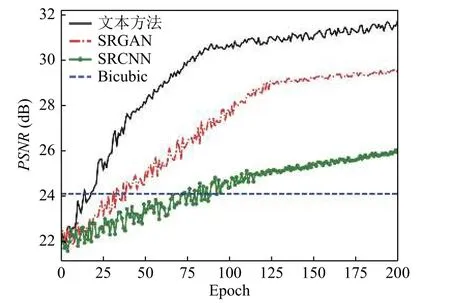
图8 不同方法PSNR 趋势
4 结论与展望
在生成对抗网络的基础上, 本文改进生成对抗网络中生成器部分, 加入了注意力递归网络, 设计了新的密集残差结构, 实现了端到端的图像超分辨率网络.在每个密集残差块中, 低分辨率的局部特征层被充分提取, 这样不仅可以稳定训练网络, 还可以快速地使网络收敛, 减小网络参数计算和内存消耗.此外, 通过注意力递归网络更加突出了图像的细节纹理, 使纹理恢复得更加自然真实, 同时减少了伪纹理的生成.最后, 本文利用普遍采用的PSNR 和SSIM 评价指标, 对本文方法产生的超分辨率图像同其他方法进行了对比, 证明了本文方法的网络性能和重建图像在视觉质量上与数值评价上的优异表现.
