敏感渐进不可区分的位置隐私保护
2020-03-21张国印
王 斌 张 磊 张国印
1(哈尔滨工程大学计算机科学与技术学院 哈尔滨 150001) 2(佳木斯大学信息电子技术学院 黑龙江佳木斯 154007)(jmsuwang@163.com)
随着当今世界发展,定位技术和无线通信技术不断进步,使得基于位置服务更多地被应用在连续查询中,这种通过在设定的时间段或设定的路段连续获得查询结果的服务方式越来越多地被广大用户接受并使用.由于连续查询需要用户提供连续位置变更,以获得精准的位置相关服务信息,因而导致在快照查询时就不得不面对的隐私泄露形势更为严峻.由于连续位置可被攻击者关联,进而获得位置轨迹,而位置轨迹包含有相较于离散位置更多的时空属性信息,导致用户隐私受到更为严重的威胁.
对于连续位置隐私保护问题,当前的研究主要集中在轨迹泛化[1-5]、关联属性模糊[6-10]和关键位置隐藏[11-18]等3类方法上.1)轨迹泛化是将用户产生的位置轨迹与其他匿名用户或虚假用户产生的轨迹相泛化,使攻击者无法在众多的匿名轨迹中准确的识别用户的真实轨迹,以此来保护用户的位置轨迹隐私;2)关联属性模糊是将用户每次查询提供的位置以及在该查询过程中产生的属性信息与匿名用户相泛化,影响攻击者将离散位置关联获得连续位置轨迹的攻击行为,进而降低攻击者获得用户位置轨迹的概率;3)关键位置隐藏则是将潜在构成位置轨迹中的关键位置采用转移或者从cache或代理获得查询结果的方式降低这些位置发送给LBS(location based service)服务器的概率,进而在连续查询过程中从LBS服务器的视野中隐藏,降低攻击者获得位置轨迹的成功率,并提高连续查询服务的服务质量.由于这类方法可看作是从关联属性模糊中发展过来的一类方法,因此在一定程度上存在2种或多种方法的交叉使用[19-21].
然而,用户在进行连续查询时不可避免地要向着敏感目标移动,进而表现为用户所处位置敏感程度的渐进性,且这种渐进性并不随着用户的轨迹匿名或者轨迹是否准确真实而改变.也就是说产生的轨迹或者割裂开的子轨迹之间仍然存在着敏感渐进性.攻击者可利用这种渐进性识别用户潜在的查询目标,进而造成用户个人隐私的泄露.因此,针对这样一种情况,本文基于广义的差分隐私提出了一种敏感程度不可区分的隐私保护方法.该方法首先通过Voronoi图对敏感兴趣点位置划分建立敏感区域,然后在敏感区域内根据敏感程度差异设定的敏感等高线所表示的用户移动敏感变化,并通过在逐次查询过程中添加的噪声位置,实现对用户查询目标敏感程度变化的隐私保护.最后,通过对欧氏空间和路网环境中的模拟数据和真实数据的实验比较,给出了该算法的使用范围和应用条件,并且通过提出的基于敏感渐进的攻击算法对其他同类的连续位置隐私保护方法的攻击比较,证明了本文算法的优越性.
1 相关工作
连续查询的便捷特性令这类查询方式更多地被用户在日常生活中所采用,因而导致在快照查询下使用的隐私保护方法诸如k-匿名[22]、l-多样性[23]、P2P(peer to peer)用户协作[24]以及PIR(private information retrieval)[25]等方法逐渐显得力不从心.针对这种连续查询泄露用户隐私的问题,简单且基本的方法是对每一个位置进行匿名处理[26]或者将多个位置泛化为位置集合[27].但是这种方式并不能有效防止攻击者在获得的多个轨迹中分辨出用户的位置轨迹.文献[1]认为用户的位置轨迹需要与其他历史轨迹相混淆,以使攻击者无法在多条位置轨迹中准确地识别用户位置轨迹.基于这一观点,Gao等人[2]通过协作用户相似的移动方式完成轨迹匿名;Zhang等人[3]提出使用实时生成的虚假相似轨迹完成匿名;而Kato等人[4]更是丰富了这一观点,将用户轨迹中的停留位置考虑进去,提高生成轨迹的相似性;Ye等人[5]通过聚类后随机添加的假轨迹降低了这种方法的计算复杂程度.但是这类轨迹匿名方法的先决条件是用户首先生成轨迹,然后才能进行匿名,这使得攻击者仍可获得用户的位置轨迹.尽管准确识别用户位置轨迹的概率相对较低,但在获得用户轨迹的情况下可通过其他手段分析识别,存在潜在风险,因而研究者考虑如何让攻击者无法获得用户轨迹.
通常,用户连续查询产生的位置是通过用户的各种属性相互关联后链接生成轨迹的,若将这些属性加以模糊或者泛化可在一定程度上降低攻击者获得用户轨迹的概率.针对多种属性泛化,Zhang等人[6]提出了一种属性泛化模型,将各种属性通过相似性计算来寻找参与匿名的用户,并通过一种聚类方式提升计算速度[7];文献[8-9]考虑到中心服务器在寻找相同属性用户时的计算负载,通过协作用户解密的方式寻找匿名用户,利用协作计算加快了相似属性协作用户的寻找进程;考虑到攻击者可利用任意2位置之间的关联概率这种特殊属性进行关联,Zhang等人[10]更是利用广义差分隐私提出了关联概率不可区分,以此降低连续位置之间的属性关联.
关联属性模糊尽管能够提供较好的隐私保护,但是这类方法在实际部署时可能会影响到服务质量.因为连续的多次查询都受到同样的保护势必会增加中心服务器或者协作用户之间的计算量,进而产生服务瓶颈.而且研究者发现,通过对连续位置中的关键位置进行隐藏同样能起到限制攻击者关联获得用户轨迹隐私的目的.在这种思想的指导下,研究者使用不可观测的混合区域mix-zone[11]来实现关键位置的隐藏,并基于加密技术[12]提升了这种方式的隐私保护程度.同样基于该思想,文献[13-15]分别考虑到利用协作用户可cache查询结果的特点,利用从周围协作用户获得查询结果的方法,将关键位置隐藏,躲避以LBS服务器为潜在攻击者的探测行为.而文献[16-17]则采用在协作用户中建立代理的方式,通过可信代理全程隐藏位置,将更多的关键位置隐藏于代理之后.Schlegel等人[18]则通过用户选定的位置网格隐藏用户自身查询的真实意图,使攻击者在更多情况下仅能获得隐藏后的位置区域,进一步保护位置轨迹.
为了发挥关联属性模糊和关键位置隐藏2种方法的共同优势,文献[19]将这2种方法结合,利用候选区域进行关联属性模糊,利用推测区域对关键位置隐藏,同时保留了2类算法的优点;而文献[20]则通过加密路段匿名实现这样观点;Zhang等人[21]将这种加密匿名应用在最短路径计算,也取得了不错的效果.
虽然上述提及的算法在其应用领域取得了较好的隐私保护效果,但是这些方法均忽略了用户位置是否敏感这样的关键问题,即在非敏感情况下用户的位置不需要保护,而仅在用户进入敏感区域才需要对用户位置加以保护[28].Dewri等人[29]考虑到这种情况,对用户提出的查询进行了等高线划分,在进入一定敏感等高划分区域后进行隐私保护.而Sun等人[30]则将敏感区域进行了划分,提出在匿名的过程中需要考虑对相同敏感类型区域中匿名用户的要求.正如文献[31-32]中所说的那样,连续查询之间的隐私保护是一个用户与攻击者之间的博弈,也可看作是一种敏感程度变化之间的变化博弈过程中.与完美匿名[33]不同,这种连续敏感程度变化过程不能被中心服务器或协作用户所泛化,也不能通过诸如[34-36]计算集会地点的方式,仅通过有限轮次获得结果并隐藏真实位置,而且这种敏感程度变化还可

Table 1 Statistical Table of Advantages and Disadvantages of Five Different Algorithms表1 5类不同算法优缺点统计表
因为匿名用户的增加而变得更易被攻击者所识别.因此,为了在敏感程度变化的过程中有效地保护用户的查询目标,进而保护用户的个人隐私,本文基于Voronoi建立敏感程度等高线,并基于广义差分隐私提出了敏感程度不可区分的隐私保护算法,以此在用户连续查询过程中位置敏感程度渐进的情况下保护用户的位置和查询隐私.各算法在隐私保护能力以及服务质量和对敏感攻击等方面的优缺点如表1所示.
2 预备知识
为便于对本文所提出算法的理解,本节将对隐私保护所针对的攻击模型、所采用的隐私保护基本思想和使用的系统架构加以简要介绍.为便于读者对本文中使用的各种变量符号的理解,表2对本文中使用的各种符号进行了描述:
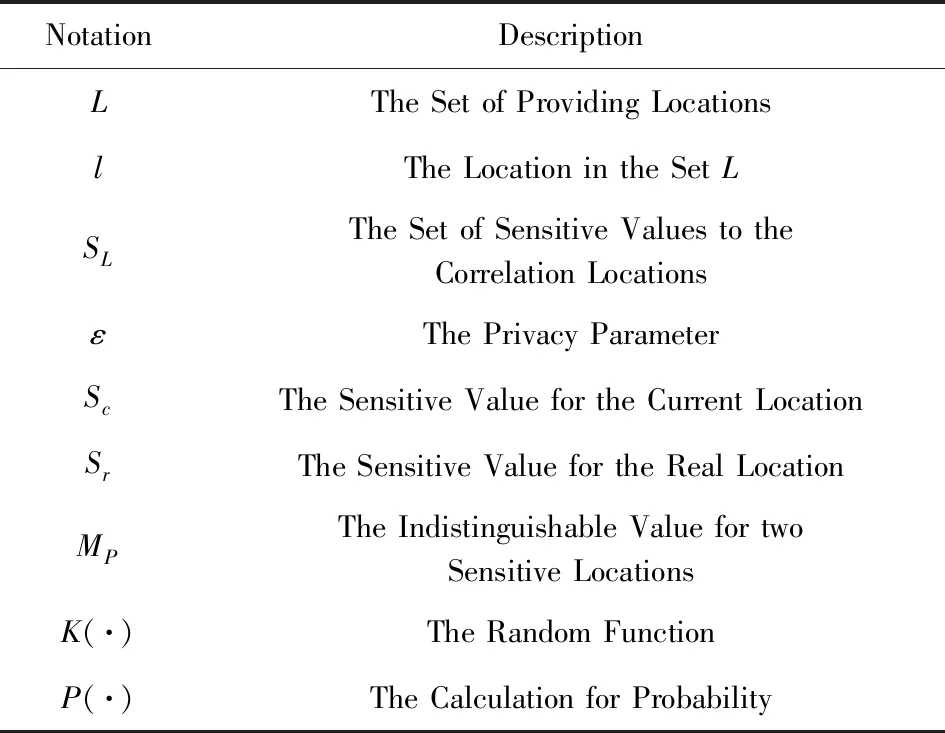
Table 2 The Various Variable Symbols Involved in This Paper表2 文中涉及的各种变量符号
2.1 攻击模型
考虑到在当前环境范围内移动用户存在的3种情况:1)向着敏感位置移动;2)背向敏感位置移动;3)在同一或较近敏感等高范围内交替移动.这3种情况对应3种用户:1)以该敏感位置为查询目标的移动用户;2)查询结束后离开该敏感位置的移动用户,且该用户进行连续查询的可能性较低;3)通过当前单元格向着其他敏感位置移动的经过用户.由此,可认为在当前单元格中,以LBS服务器为主的攻击者可利用连续查询的敏感度渐进对用户的查询目标加以攻击.为了说明敏感渐进的攻击手段,同时也为了更好地分析本文所提出的隐私保护基本方法的重要性,本文在对用户敏感程度变化的基础上给出了基于敏感渐进的攻击方法,该方法可用于对已有的隐私保护方法进行测试攻击.
在用户移动过程中,假设用户进行n次连续查询后可到达目标位置,则攻击者利用当前提交的位置集合分析,可获得n个连续提交位置组成的集合L={l1,l2,…,ln}以及每个子位置集合对应的敏感度集合SL.其中,敏感度Sl为当前位置与敏感目标位置之间相互关联的百分比,表示为
Sl=p(l→ls).
(1)
对于当前位置集合,若存在|Sl1|≤|Sl2|≤…≤|Sln|,则攻击者可认为用户向着该敏感目标位置ls移动,用户的查询目标为该敏感点.进而攻击者在连续查询的过程中可获知用户隐私.

Fig.1 The attack effect for seven privacy protecion schemes图1 针对7种隐私保护算法的攻击效果
基于这样的一种攻击方式,本文对当前存在的7种主流隐私保护算法进行了尝试性的攻击测试,取得如图1所示的攻击效果.所测试的隐私保护算法有相似轨迹计算的STGA(similar trajectories generation algorithm)算法[3]和随机插入假轨迹的RFQ(random fake queries)算法[5],有关联属性模糊的PSO Anonymization(particle swarm optimiza-tion anonymization)算法[7]和协作用户属性匿名的SACU(similar attribute collaborative users)算法[8],有关键位置隐藏的CaQBE(caching query blocks exchanging)算法[13]和使用代理的P4QS(peer to peer privacy preserving query service)算法[17],以及加密路段进行匿名的SSP(section shortest path)算法[21].其中,图1(a)表示在匿名值固定为20情况下,随查询次数增加导致的攻击效果变化;图1(b)表示在连续10次查询情况下,随匿名值增加导致的攻击效果变化.所有测试结果均通过2 000次随机测试后,利用结果平均取值建立的攻击效果图.
综合对比图1(a)和图1(b)可以看出,这种根据敏感程度渐进的攻击方法对轨迹匿名、关联属性模糊和关键位置隐藏的隐私保护算法都取得了很好的攻击效果,仅对于加密路段的隐私攻击效果稍差.产生这种情况的主要原因是这些隐私保护算法主要针对的是如何混淆或防止攻击者获得用户的位置轨迹,但未能有效地处理用户向目标位置移动过程中产生的敏感程度渐近.而且,匿名用户数量的增加所起到隐藏用户的作用有限,反而因为查询次数的增加而在一定程度上提升了攻击效果,为攻击者获得用户查询目标提供了便利.
2.2 隐私保护思想
对于敏感程度渐进这种可利用的用户特性,显然传统的基于k-匿名的隐私保护模型无法起到预期的隐私保护效果.对于这样一种情况,较为有效的方法是令攻击者可获得的敏感渐进程度表现不明显或者不可区分.基于这样一种思想,本文首先以敏感位置为图心建立当前区域的Voronoi图,然后在每个单元格中根据敏感情况变化建立该单元格内的敏感等高线,并通过敏感等高线所表示的敏感程度划分当前单元格内的敏感变化,泛化用户提交位置的敏感程度.最后,通过噪声位置覆盖,使得用户的真实位置与噪声位置所产生的敏感程度在移动之后彼此不可区分,令攻击者无法利用用户在该单元格连续查询过程中的敏感程度变化识别查询目标,进而保护用户的个人隐私.
2.3 系统架构
由于本文所提出的算法需要在指定区域建立Voronoi图,且向该图的单元格内添加噪声,这使得分布式架构中的移动客户端因其计算能力很难实现预定构想.因此,本文选择如图2所示的带有中心服务器的集中式架构.在该架构中,共包含3种实体,分别是用户、中心服务器和LBS服务器.其中,用户主要指那些有连续查询要求,并且配备了能够完成定位与信息交互设备的移动用户,该实体能够与中心服务器和LBS服务器之间进行信息交互,且具有对查询结果基本的接收处理能力,在本文中为保护用户隐私,用户只与中心服务器进行信息交互而不与LBS服务器进行信息交互;中心服务器是一种由政府部门或大型商业机构提供的可信的隐私保护服务实体,该实体能够对用户发送过来的查询信息进行隐私保护处理,在完成对用户提交信息的计算加工之后,将查询信息发送给LBS服务器,并对LBS服务器反馈的查询结果集合进行结果提取后返回给查询提交用户;最后,LBS服务器是指拥有位置服务数据,并能根据用户要求提供查询结果的服务提供商或数据拥有者,该实体一方面能够按照协议完成用户要求的查询请求,另一方面又存在着对用户隐私信息的好奇行为,同时可根据掌握的道路或区域情况等背景信息分析用户连续查询过程中的查询目标.

Fig.2 The system architecture of centralized model图2 集中式系统架构
3 基于敏感程度不可区分的隐私保护方法
本文所提出的敏感程度不可区分的隐私保护方法分为2个主要处理阶段:1)建立能够表现用户敏感程度渐近的位置变化区域;2)在这一确定区域按照广义差分隐私的思想,通过添加噪声建立敏感位置渐进程度的不可区分,以此实现对用户的位置和查询的隐私保护.
3.1 基于Voronoi的敏感等高线建立
通常情况下,用户所在的区域是一个由各种不同的敏感点组成的位置环境,其中每个敏感点所在的区域都可用一个不规则的多边形所限定.这令利用Voronoi图建立不规则多边形成为可能.按照用户提供的敏感位置,在不考虑这些敏感位置是否具有相同敏感程度的情况下,完成Voronoi图的绘制,因此不同敏感程度的Voronoi图生成元并不会造成Voronoi单元格的差异,且不会影响算法效果.根据Voronoi图的基本性质,即每个单元格中的任意位置距当前单元格的图心距离要低于距离其他单元格图心位置这一特性,可利用Voronoi图来标识当前区域中的所有敏感位置.于是,中心服务器在收到由用户发送的隐私保护请求之后,首先根据用户所在空间存在的敏感位置建立基于该空间的Voronoi图,如图3所示;在建立完成Voronoi图之后,考虑到用户进行连续查询时是需要向着某一敏感位置不断移动,该移动将会导致敏感程度的不断渐进.因此,对于建立完成的Voronoi图,针对该图中的全部单元格的敏感程度渐进变化情况,建立敏感等高线.建立完成的敏感等高线如图3中的单元格A所示,其中的虚线部分分别代表不同的敏感度等高区域,等高线越接近该单元格的图心则敏感程度越高.用户在该单元格中向着敏感位置移动则会产生敏感程度渐进,攻击者有可能分析获得用户位置和查询隐私.

Fig.3 The Voronoi diagram of sensitive positions and cells with sensitive contour lines图3 敏感位置Voronoi图及单元格内敏感等高线
敏感等高线的建立是通过当前单元格内存在具有相同敏感程度的各位置相互连接所建立的.如图4所示,在建立的Voronoi图中的某一单元格内,存在如图4中虚线所示的具有不同敏感程度的各个位置,将相同敏感程度的位置相互连接,即可获得当前敏感度所指示的敏感等高线.为了便于计算,本文仅将敏感等高线限定在以20%为单位的递进取值上.由此可获得如算法1所示的敏感等高线建立过程.

Fig.4 Degree of sensitivity in Voronoi cell图4 Voronoi单元格内的敏感度
算法1.敏感等高线建立算法.
输入:单元格内各位置的敏感度SL;
输出:敏感等高线.
① for (i=1;i≤L.num;++i)
② while (lj不可链接且j≤L.num-1)
③ if (Si=Sj)
④ if (li.next=null)
⑤ 链接li和lj;
⑥ else
⑦ 链接lj-1和lj;
⑧ end if
⑨ else
⑩ ++j;
算法1通过敏感度之间的相似程度建立敏感等高线.在建立完成之后,可根据计算方面的便利性,按照敏感等级的百分比进行等高线划分,进而获得如图4所示的多边形单元格内的敏感等高线划分.由此,利用Voronoi图,我们建立了用户在当前区域移动情况下的敏感程度变化等高线表示.在建立完成这种等高线之后,为了有效地保护用户的位置和查询隐私,需要在指定的等高线范围内添加噪声,而噪声按照什么标准添加,将在3.2节加以说明.
3.2 基于敏感程度不可区分的噪声添加
在对用户位置隐私进行攻击的情况下,攻击者将会掌握大量的背景知识,本文已在第2节给出了这种潜在的攻击方式,并且对已有的隐私保护方法进行了尝试性的攻击.从其攻击结果上不难看出这种攻击方式相当有效.为了应对这种攻击手段,本文已建立了基于敏感程度渐进的敏感等高线,因此需要在满足敏感程度不可区分的前提下对用户的隐私信息加以保护.

Fig.5 The variation of noises added in Voromoi cell图5 Voronoi单元格内添加的噪声变化
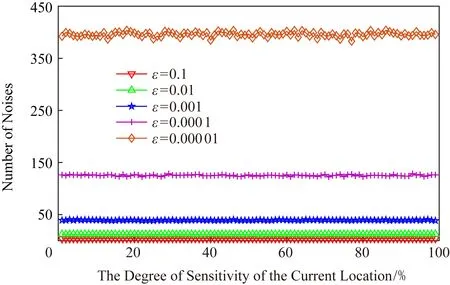
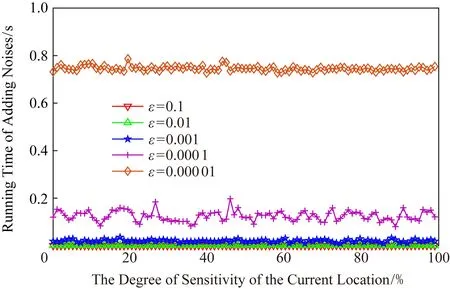
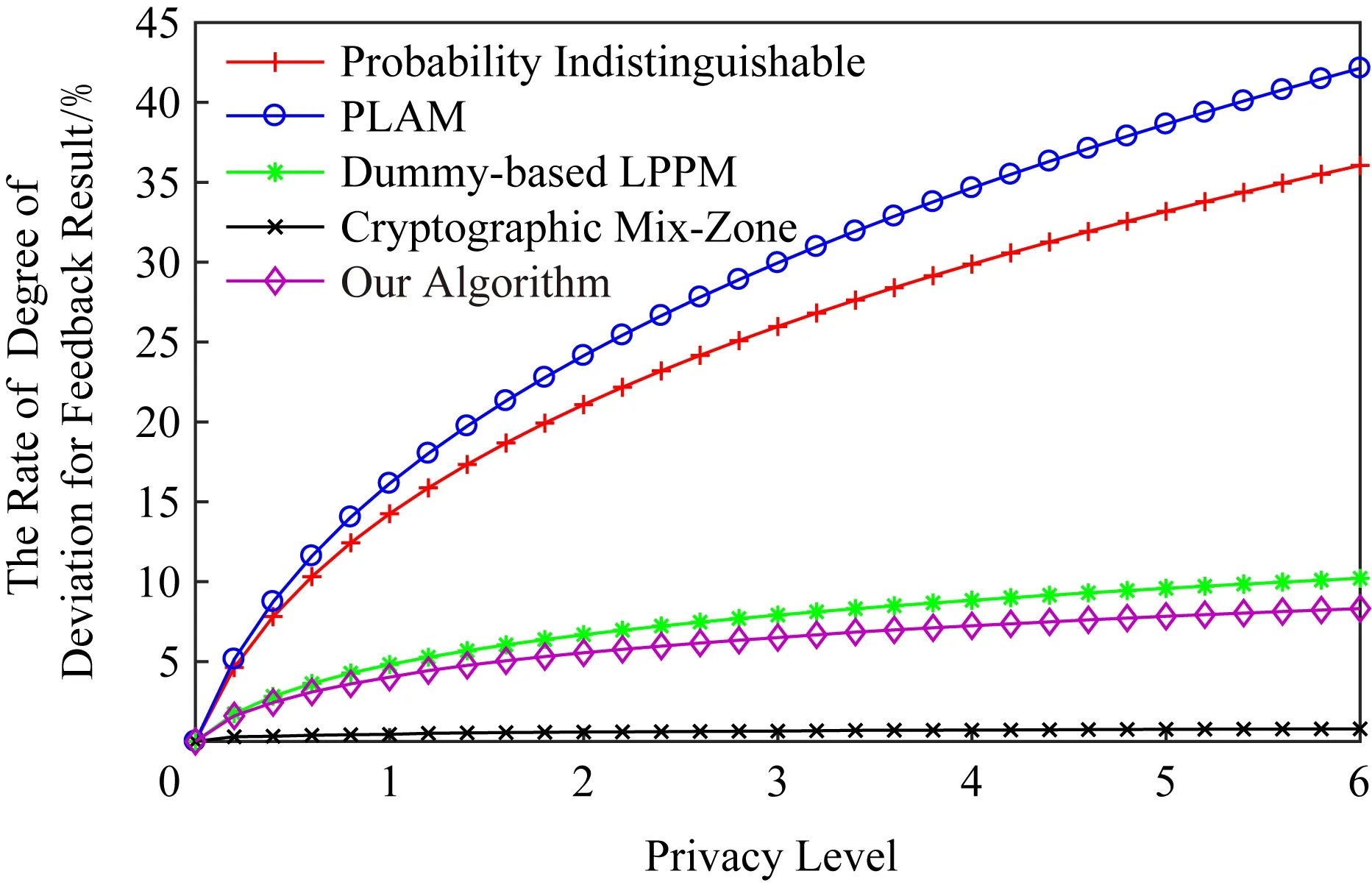
正如本文在攻击模型中描述的那样,攻击者可利用当前区域内的敏感程度渐进分析获得用户隐私.设用户当前位置的敏感程度为Sc,攻击者所能掌握的该单元格内真实用户敏感度集合为SL,则在用户向着敏感位置移动过程中的敏感程度变化为Sc MP(μ1,μ2)=Supz∈Z|μ1(z)-μ2(z)|. 当μ1(z),μ2(z)同时为0或者∞时,|μ1(z)-μ2(z)|=0,即MP(μ1,μ2)在μ1,μ2对每个值z有相似概率.MP表示p和p′之间的不可区分级别,如果该值越小,表示2次提交的位置之间的敏感程度不可区分性越强.那么机制P(K(L)→ls)→P(Z)满足ε-敏感度不可区分,当且仅当对于连续2次提交的位置集合li和lj之间的敏感度变化存在: MP(p(K(li)→ls),p(K(lj)→ls))≤ (2) 式(2)可等价表示为K(li→ls)(z)≤eεMP(p(li→ls),p(lj→ls))K(lj→ls)(z),对于所有z∈Z.参数ε可看作是对MP的缩放.代入式(2)可表示为 MP(p(K(li)→ls),p(K(lj)→ls))≤ (3) 即 MP(K(Sli),K(Slj))≤εMP(Sli,Slj). (4) 从式(4)中可知,通过函数K(·) 的处理,使得攻击者获得的连续2次查询敏感度变化彼此不可区分,即|Sli-Slj|<ε.式(4)中,隐私参数ε的取值是通过用户隐私需求设定的,对于该值的讨论不在本文的研究范围之内,本文不再探讨如何选择. 同样,为了保证每次提交的位置集合,在攻击者掌握最大背景知识的情况下,仍不能通过敏感程度差异识别用户,还需保障提交位置集合中,真实位置与全部位置之间满足|SL-Sr|<ε.其中,SL为提交的全部位置集合的敏感度,Sr为真实位置敏感度.由此可认为当前用户的敏感程度在向着敏感位置移动过程中满足ε-敏感程度不可区分.其中,敏感程度以敏感等高线建立的敏感百分比取值进行计算. 添加噪声的基本要求已经通过图5和分析加以说明,其具体的操作过程如算法2所示: 算法2.满足ε-不可区分的连续噪声添加算法. 输入:当前用户位置lc、前一次查询位置lc-1、前一次查询位置集合Lc-1、当前所有位置敏感度集合SL; 输出:噪声位置集合Ld. ① if (lc-1=null且Lc-1=null) ② while (|SL-Sc|≥ε) ③ 随机添加噪声ld; ④SL=(Sc+Sd)/L.num; ⑤Ld=Ld+ld; ⑥ end while ⑦ else ⑧ while (|SL-Sc|≥ε且|SL-SL-1|≥ε) ⑨ 随机添加噪声ld; ⑩SL=(Sc+Sd)/L.num; 在算法2中,利用代码行③和⑨来添加随机噪声,即添加随机位置与用户真实位置混合,并通过添加的随机噪声利用当前位置集合与前一位置集合产生的共同敏感度之间的极小差异来实现敏感程度渐进的不可区分.此时,2个临近的由中心服务器发送给LBS服务的位置集合满足|SLi-SLj|<ε,即攻击者所能收到的2个位置集合产生的敏感程度集合之间不可区分.同时这种ε-敏感程度不可区分也保障了在当前提交的位置集合中,各位置敏感程度之间的不可区分性. 本文所提出的隐私保护方法,其安全性主要取决于建立的敏感区域是否能够正确表示敏感程度渐进,以及通过添加噪声满足的ε-敏感程度不可区分是否能够有效地抵抗基于敏感程度渐进的攻击方法. 首先,Voronoi图的图心是由敏感位置所确定的,且距离图心位置越近,其敏感程度越高.同时,Voronoi图性质使得当前单元格中的位置据其图心的距离低于该位置与其他单元格图心的距离,这使得在当前单元格内的所有位置的敏感程度呈现一种从单元格边缘到图心的递进趋势,且这种趋势并不受单元格之间的图心所影响.因此,在这种敏感程度渐进基础上建立的敏感等高线能够真实地反映当前单元格内不同位置敏感程度的差异和渐进性. 其次,对于使用Voronoi建立的敏感程度等高线,在同一单元格内的用户从位置li向图心位置移动到lj,有其敏感程度变化Sli≤Slj.攻击者在无法获得该用户准确位置的情况下,可根据当前单元格内全局敏感度变化来判断用户是否向图心所代表的敏感位置移动,于是有连续2次查询所提交的敏感度变化SLi≤SLj,进而攻击者分析获得用户的移动目标.但是,由于本文算法基于ε-不可区分在每次查询过程中对当前单元格添加了随机噪声,使得|SLi-SLj|<ε,即当ε取值足够小时,有敏感程度变化百分比在2次查询敏感程度集合中不可区分.进而攻击者无法通过敏感程度之间的变化猜测用户的移动目标. 最后,由于在连续2次查询过程中,添加的噪声分别满足|Sli-Slj|<ε,使得在连续的2个敏感程度集合中,用户敏感程度是否存在或者是否变化对整个敏感程度集合的影响低于ε取值.这进一步令攻击者在掌握当前区域其他用户敏感程度的前提下,仍不可通过敏感程度集合的差分运算获得用户的敏感程度百分比,因此在用户未移动的情况下,攻击者也无法通过其掌握的最大背景知识获得用户的位置和查询隐私. 定理1.本文算法可保护用户的敏感渐进隐私. 证明.对于2.1节中所提出的攻击模型,以及攻击者所能掌握的泛化后的位置集合La和Lb有2个位置集合的敏感度关联百分比SL=p(La→Lb).攻击者获得的理想结果是能够准确的获得|SLa|≤|SLb|,从而分析用户是向着Lb中的位置移动.但是,由于存在随机函数K(·)对2个集合中添加噪声数据,使得在满足敏感度不可区分级别MP的基础上有MP(p(K(li)→ls),p(K(lj)→ls))≤εMP(Sli,Slj),那么当隐私参数ε在取值足够小的情况下,敏感度关联百分比足够小,甚至可忽略不计,此时SL与之前获得的敏感度SL′之间的取值不可区分,因此攻击者无法准确辨识出2个临近位置集合之间的敏感程度变化,用户的位置隐私得以获得保护. 由此,可认为本文所提出的方法能够有效地在攻击者使用敏感程度变化作为攻击手段的前提下保护用户的位置和查询隐私. 证毕. 在算法性能方面,针对用户实体,由于算法的主要执行者是中心服务器,所有用户实体仅需要将自身真实位置提交给中心服务器即可,此时用户实体的算法时间复杂度为零;针对中心服务器,本文算法的整体是由中心服务器完成的,在中心服务器中执行算法1和算法2,且上述2个算法可看作是嵌套使用的,因此该实体的算法时间复杂度为O(n2).针对LBS服务器,LBS需要按照由中心服务器提交的噪声和真实位置集合反馈查询结果,因此其算法时间复杂度可认为是O(n). 为便于分析本文所提出方法的有效性和各参数对用户的影响,本文将通过实验测试对算法进行比较和模拟.实验环境为笔记本电脑Intel core I5,4 GB内存,Windows7操作系统,并采用Matlab R2017a作为测试工具.同时,为了验证在欧氏空间和路网环境的差异,实验将基于这2种不同的环境进行分析对照.实验测试将分别在提供隐私保护在隐私参数变化过程中的噪声添加数量、算法执行时间、查询结果提取时间和不同隐私参数下的攻击成功率等几个方面展开. Fig.6 The number of noises added in Euclidean space图6 欧氏空间下添加噪声数量 图6给出了不同隐私参数ε取值在欧氏空间下满足敏感程度不可区分所需添加的噪声数量.由图6可知,当前用户所处位置的敏感并未对添加的噪声数量有所影响,且在隐私参数ε>0.001的情况下,添加的噪声数量仅略高于50,只有在隐私要求较高的ε取值下,才会需要大量的噪声来满足不可区分性,此时添加的噪声数量较为巨大.但对于一般用户而言,ε取0.001左右的值时,已经可以提供较好的隐私保护效果,因此算法可在实际欧氏空间下部署. 图7给出了不同隐私参数ε取值在路网环境下满足敏感程度不可区分所需添加的噪声数量.与图6进行对比分析可以看出,在路网环境下为满足不可区分性,算法需要添加高于欧氏空间情况下的噪声数量.造成这种现象的原因是,在路网环境下只有真实存在于道路上的噪声位置才可以起到泛化作为,而路网中道路环境的限制远高于欧氏空间.这使得为达到同样的隐私保护不可区分性,路网环境需要添加近似于欧氏空间2倍的噪声,以此实现敏感程度不可区分. Fig.7 The number of noise added in road network图7 路网添加噪声数量 Fig.8 The running time of adding noises in Euclidean space图8 欧氏空间添加噪声的计算时间 图8给出了不同隐私参数ε取值在欧氏空间下添加满足敏感程度不可区分所需的计算处理时间.从图8中可以看出,与添加噪声数量相似,算法计算处理时间同样不因当前用户所在位置的敏感程度变化而改变.在隐私参数ε>0.001的情况下,因添加噪声数量相对较少,算法的执行时间均低于0.1 s,只有在隐私要求极高的情况下,算法需要计算选择更多的噪声位置以满足敏感程度不可区分,此时才会导致较长的处理时间,但该处理时间仍低于0.9 s,基本能满足基于位置服务实时反馈查询结果的需求. 图9给出了不同隐私参数ε取值在路网环境下添加满足敏感程度不可区分所需的计算处理时间.同样与图8进行对比分析,可以看出在路网环境下,算法的处理计算时间要高于在欧氏空间下的处理计算时间.这主要是因为添加的噪声数量在路网环境要高于欧氏空间,更多的计算处理时间主要是在对路网限制和噪声选择上所耗费的处理时间,因此相比欧氏空间产生了接近于2倍的计算处理时间. Fig.9 The running time of adding noises in road network图9 路网环境添加噪声的计算时间 从添加噪声数量方面看,这种方法添加的噪声数量很大,尤其当ε取值较小的情况下,噪声数量十分巨大,在这种情况下有可能会使LBS服务器的负载过大,造成服务瓶颈.另外,随着用户隐私要求的提升其计算处理时间尤其是在现实的路网环境下的计算处理时间较高.因此,可适当对用户提交位置进行可计算范围内的偏移,利用中心服务器的计算处理能力,在获得查询结果后按照偏移距离对用户查询结果加以计算提取.由此,可获得用户位置偏移后在欧氏空间和路网环境的噪声添加数量. 偏移的方向选择为用户当前位置向着前一次查询位置方向进行偏移,以此降低敏感程度之间的变化,同时为了提升偏移的不可确定性,将偏移距离设定为当前位置与上一位置之间距离的1/2~ 3/4之间的随机距离,一方面提升偏移距离的不确定性,另一方面在保障降低敏感程度变化的同时不至于造成过多的服务偏差.用户的偏移过程如算法3所示. 算法3.偏移优化算法. 输入:当前用户位置lc、前一次查询位置lc-1; 输出:偏移后位置lc′. ① if (lc-1=null) ②lc′=lc; ③ else ④lc′=lc-1和lc之间1/2~3/4处任意偏移位置; ⑤ end if ⑥ returnlc′ 算法3给出了对用户进行噪声添加实现敏感渐进不可区分保护之前的用户位置预处理过程,该偏移处理的目的是为了降低添加噪声的数量,减少噪声对中心服务器等实体的影响.由于偏移会造成反馈结果与真实结果之间的偏差,因此偏移距离不易过大,且为实现减少噪声,设定偏移量为1/2~3/4处的任意偏移位置.如何有效地界定偏移上界将在今后的研究中具体展开.为了便于同无偏移方法进行比较,给出了在欧氏空间和路网环境下的添加噪声数量测试以及算法执行时间测试. 图10给出了不同隐私参数ε取值在欧氏空间下通过对用户位置偏移后满足敏感程度不可区分所需添加的噪声数量.与图6对比可以发现,经过用户位置偏移之后,其噪声添加数量同样不随着用户所处位置的敏感程度变化而变化,并且所需要添加的噪声数量明显减少.这是因为随着用户位置向着上一查询位置偏移,用户的敏感程度变化减少,为满足敏感程度不可区分所需要调节的敏感程度百分比同样降低,因而导致所需要添加的噪声数量同时减少.由此可见,用户位置偏移可实现减少添加噪声数量的目的,降低了中心服务器的服务负载. Fig.10 The number of noises added in Euclidean space with location shifting图10 偏移后欧氏空间的噪声数量 图11给出了不同隐私参数ε取值在路网环境下通过用户位置偏移后满足敏感程度不可区分所需添加的噪声数量.与图7相比较可见偏移后在路网环境下同样降低了对噪声数量的需求,满足了敏感程度的不可区分.同样,与图10相比较,可见即使通过用户的位置偏移,由于路网环境的限制作用,在路网环境下,仍需要添加相较于欧氏空间更多的噪声,以满足ε-敏感程度不可区分. Fig.11 The number of noise added in road network with location shifting图11 偏移后路网添加噪声数量 图12给出了不同隐私参数ε取值在欧氏空间下通过用户偏移后导致的添加满足敏感程度不可区分所需的计算处理时间.与图8相比较,经过用户的偏移后,由于添加的噪声数量发生了变化,致使其计算处理时间同样减少,并且通过降低对添加噪声的计算处理,中心服务器的服务负载被有效降低,其计算处理时间要低于相同环境下未进行偏移的用户. Fig.12 The running time of adding noises in Euclidean space with location shifting图12 偏移后欧氏空间添加噪声的计算时间 图13给出了不同隐私参数ε取值在路网环境下通过用户偏移导致的满足敏感程度不可区分所需的计算处理时间.与图9相比,在偏移后,中心服务器的处理时间明显降低,且在与图12相比后也可发现在路网环境下即使经过偏移仍需要较长的计算处理时间.这主要是因为路网的限制以及偏移对敏感程度差异的影响.通过对比可见,偏移对用户的隐私尤其是路网环境的用户隐私能够起到降低中心服务器负载,提高响应时间的较好影响.但是,由于用户偏移距离的差异,势必会造成节点反馈位置的精确性降低,进而反馈结果精确程度等服务质量受到影响. Fig.13 The running time of adding noises in road network with location shifting图13 偏移后路网环境添加噪声的计算时间 Fig.14 The trend of query result difference with the shifted图14 查询结果差异随偏移的变化 由上述实验可以看出通过偏移能够很好地降低添加的噪声数量、减少执行时间,但这样势必会在一定程度上影响用户获得查询结果精确的性.因此,对偏移后造成的查询结果差异进行了测试. 图14给出了使用初始位置偏移和未使用偏移2种方式随用户查询次数变化导致的查询结果差异.从测试结果中可以看出,尽管通过用户偏移会导致查询结果与真实结果之间存在一定误差,降低服务质量,但这种差异被很好地控制在可接受的范围内,即使用户连续进行50次查询,这种差异仍被控制在40%以下.因此用户可获得相对较为准确的查询结果,且偏移算法降低了服务器负载.同时减少了算法的计算处理时间,是用户在对查询结果精确程度要求不高的情况下的一种有效选择. 为验证本文算法与其他算法相比较的优势,本文将该算法与同类算法进行了实验比较,参与比较的算法有关联概率不可区分的Probability Indistin-guishable算法[10]、用户协作敏感位置标签的PLAM(privacy local area mobile)算法[30]以及身份授权加密的Cryptographic Mix-Zone算法[12].上述5种算法将在敏感程度的渐进性、算法执行时间、反馈结果于真实结果之间的偏差量等方面展开. Fig.15 The comparison of the degree of sensitivity of various algorithms图15 不同算法的敏感渐进性对比 图15给出了5种比较算法在保护用户连续移动过程中的敏感渐进差异.从图15中可以看出,随着用户连续向目标移动,各种算法保护下的用户所表现出的敏感渐进性都在增加.在这些算法中Pro-bability Indistinguishable算法的渐进程度最高,这是由于该算法主要关注于2位置之间的关联概率,并没有考虑到在移动过程中的敏感渐进问题.同样Dummy-based LPPM算法只是利用用户中心去分析潜在的用户轨迹,进而实习轨迹泛化,在这个过程中并未有效地处理敏感渐进,因此敏感渐进程度较高.在剩余的3种算法中,PLAM算法尽管已关注用户是否在敏感区间,但并未考虑敏感渐进的问题,其渐进程度相对较高.而Cryptographic Mix-Zone算法虽然并未针对敏感渐进而设计,但是加密后用户信息在很大程度上阻止了攻击者获取用户敏感程度信息,因此具有一定的敏感程度抵抗能力,其敏感渐进性较低.最后,本文算法主要是针对如何降低连续移动位置之间的敏感程度而提出的,并利用敏感程度不可区分性来防止攻击者对位置展开关联,因此其敏感程度的渐进性最低. 图16给出了不同算法在查询次数变化过程中的算法处理时间差异.从图16中可以看出,随查询次数增加Cryptographic Mix-Zone算法的执行时间最长,这是由于该算法使用加密手段完成隐私保护,在加密过程中加密算法的执行占用了较长时间.同样Probability Indistinguishable算法需要计算处理2位置之间的关联概率,并实现关联概率不可区分处理,因此其算法执行时间同样较长.Dummy-based LPPM算法是通过添加大量噪声完成隐私保护的,添加的噪声数量以及用户中心分析占用了一定的处理时间,其算法执行时间相对较长.PLAM算法采用的是利用用户协作建立敏感区域标签的方法,虽然在单一用户处理上执行的时间较短,但是当多个用户协作最终建立起敏感区域时,这个执行时间同样较高.最后,本文算法主要执行随机噪声和随机偏移操作,并不需要较多的计算量,因此其算法执行时间最短. Fig.16 The comparison of running time of various algorithms图16 不同算法的执行时间对比 图17给出了不同算法反馈结果的偏差程度,其中对于添加噪声类的算法,这种偏差是通过噪声结果和真实结果的均值计算得到的.从图17中可以看出,Cryptographic Mix-Zone算法的反馈结果几乎没有偏差,这是由于该算法并不需要泛化或者隐藏等方式完成隐私保护,该算法完全是通过加密手段实现查询结果的隐私获取的,因此其反馈结果偏差最低,且并不随着隐私级别的增加而变化.本文算法采用的是噪声与偏移共存的方式完成隐私保护的,因此其结果偏移量要低于单独使用上述2种策略的任何一种方法.Dummy-based LPPM算法是通过添加噪声实现的,但是该算法主要是以k-匿名为隐私保护模型的,该模型添加的噪声数量要低于差分隐私保护模型,因此其结果偏差要低于剩下的2种算法.Probability Indistinguishable算法是完全的采用偏移实现的关联概率不可区分,因此其位置偏差较大.最后,PLAM算法反馈的结果是按照敏感区域反馈的,这导致获得的查询结果与真实结果之间存在最大的差异性的,因此其反馈差异最高. Fig.17 The comparison for deviation of feedback result of various algorithms图17 不同算法的反馈结果对比 综上,通过对2种不同类型的算法的实验对比,使得用户可根据自身需求选择不同的隐私保护处理方法,进而满足对用户移动过程中敏感程度不可区分的隐私保护需求. 用户在使用连续位置查询并移动的过程中,随着移动过程,其所经过并提交的位置呈敏感程度渐进的趋势,这使得攻击者可利用这种渐进识别用户的潜在目标,进而获得用户的隐私.针对这种情况,基于Voronoi敏感区间划分和敏感区域内敏感百分比等高线的划定,本文提出了敏感程度不可区分的隐私保护方法.这种方法能够有效防止攻击者通过用户移动过程中的敏感程度渐进识别用户的目标位置,进而保护了用户的个人隐私.同时,为了体现本文所提出算法的应用范围和应用环境,在欧氏空间和路网环境分别对相应参数下的算法执行情况进行了模拟对比,进而算法在执行过程中可参照这些比对结果加以应用. 然而,本文所提出的算法同样不能解决隐私保护全部问题,且由于用户单次查询过程中,通过添加随机噪声的方式使其敏感程度变化不可区分,将导致噪声数量添加增大,进而对LBS服务器的响应时间和服务质量造成影响.所以今后工作的一个方面将在如何降低隐私保护对服务质量的影响方面展开.另一方面,由于用户属性仍可作为关联用户敏感程度变化的关联,同时添加噪声会造成反馈不精确以及保护过度的问题.因此,今后研究的另一个方面将在降低属性关联以及精确性和保护度量等方面展开.
εMP(p(li→ls),p(lj→ls)).
εMP(Sli,Slj),
3.3 安全性分析及性能分析
4 实验验证




5 偏移优化及其实验验证




6 结论及今后的工作展望
