基于内存关联分析的预拷贝迁移优化策略
2020-03-19张宏伟李晓欢李春海姚荣彬
张宏伟,李晓欢,李春海,姚荣彬,唐 欣
(桂林电子科技大学 a.信息与通信学院; b.信息科技学院,广西 桂林 541004)
0 概述
动态迁移技术是云计算虚拟化技术中的关键部分[1],其可将正在运行的虚拟机或容器从一台物理机迁移至另一台物理机,而服务程序没有中断或中断时间极短。目前,主流的动态迁移技术有内存预拷贝迁移[2]、内存后拷贝迁移[3]、内存混合复制迁移[4]和基于日志的跟踪重现迁移[5]等。其中,预拷贝迁移是动态迁移中的主流技术。但是,现有预拷贝迁移算法中的迭代过程存在重复拷贝同一个内存页的情况,导致拷贝内存页数量增加以及总迁移时间延长。
基于内存压缩的预拷贝迁移优化方法是解决上述问题的常见方案之一。文献[6]使用游程编码(RLE)压缩技术来减少迁移期间传输的页面数,由于在迁移期间转移的总迁移数据量减少,导致总迁移时间和停机时间缩短。文献[7]通过delta应用压缩迁移过程中由源主机生成的脏页,以提高迁移吞吐量并缩短停机时间,其有效减少了总迁移数据量和总迁移时间。此外,控制内存脏页产生速率的预拷贝迁移优化方法同样能取得较好的效果。文献[8]提出了一种使用CPU调度来控制内存脏页率的方法,当虚拟机内存写入速度较快时,虚拟机CPU处理速度将减慢,该方法通过降低脏内存产生速率使脏页率降低至可接受的值,其能够缩短总迁移时间和停机时间,然而,通过牺牲计算能力来减少脏内存会导致应用程序性能下降,影响用户体验。虽然上述方法通过对内存页进行压缩或降低内存的脏页产生速率来降低迁移总时间和总数据量,但仍未完全解决多次迭代重复拷贝脏内存页的问题。
为解决现有预拷贝迁移算法中存在的重复拷贝内存页问题,改变内存传输顺序的预拷贝迁移优化方法应运而生。文献[9]提出了一种动态调整内存页面传输顺序的方法,其通过对页面更新频率进行采样,优先传输更新频率较低的页面,这种动态调整内存页传输顺序的方法能有效降低内存脏页的重传次数。文献[10]提出了一种基于重用距离的预测方法,该方法采用重用距离的概念对频繁更新的页面进行跟踪,在此基础上,决策是否将该页面保存到最后进行迭代,以减少相同页面的重复传输次数。文献[11]提出了一种快速的脏页预测预拷贝方法,其对内存页状态改变的概率进行测算,并推迟状态频繁变化页面的传输,达到优化虚拟机实时迁移的目的。文献[12]通过动态指数平滑法来预测下一轮的脏页,有效地减少了迁移数据总量和总时间。文献[13]针对内存预拷贝过程中内存页反复重传的特征,考虑时间相关性,引入马尔科夫预测模型,改进现有的内存动态迁移机制,其利用脏页的历史操作访问情况预测下一轮迭代被修改的概率,且只传输预测概率较低的内存页。然而,上述方法在计算脏页概率时都只考虑时间相关性,没有考虑到内存之间的空间相关性。文献[14]利用时间相关性计算页面脏页率,优先发送脏页率低的内存页,同时考虑到空间相关性,认为相邻内存页或相邻内存页的邻居内存页也是脏页,然后提高该相邻内存页的脏页率,但是,这种判断相邻内存页是否变脏的方式并不能完全准确地反映内存的空间相关性。
本文提出一种基于内存关联分析的预拷贝迁移策略,通过统计脏页率来预测下一轮内存页变脏的概率,停止传输变脏概率高的内存页。在此基础上,基于内存的空间相关性,设计一种内存关联(Memory_cor)算法以计算内存页之间的强关联规则,取消传输脏页率高的内存页及其强关联内存页,从而避免内存脏页反复传输的现象,缩短总迁移时间。
1 基于内存关联分析的预拷贝迁移策略
1.1 高频脏页计算
内存的时间相关性是指:如果某个内存页在一定时间段内重复改变,则该内存页不久之后很有可能再次被改变[15]。基于内存关联分析的预拷贝迁移策略利用内存的时间相关性原理对内存页下一轮变脏概率进行预测。通过统计最近N轮的内存变脏情况来计算脏页率,利用脏页率的大小对内存下一轮变脏概率进行预测[16]。本文将脏页率过高的内存页定义为高频脏页,对于高频脏页,本轮迭代将不传输,以抑制内存页反复传输的现象。脏页率dp定义为:
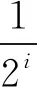
1.2 高频脏页强关联内存页计算
通过统计内存修改的历史数据来预测内存页下一轮迭代变脏概率的方法,只能在时间相关性上对内存变脏的可能性进行分析。本文基于内存关联分析的预拷贝迁移策略在预测内存页变脏概率的基础上,结合内存页的空间相关性原理,统计内存修改的历史数据,并提出Memory_cor算法用于分析内存页之间的关联性,从而减少内存页反复传输的现象。
内存的空间相关性是指:在一轮迭代的时间内,2个内存页均被修改这一事件在预设的程度上呈现关联关系,如内存页Mn的修改记录为01010111(1表示被修改,0表示未修改),内存页Mm的修改记录为01010101,2个内存页的修改记录极其相似,则两者之间可能存在空间相关性,这2个内存页有可能为强关联内存页[17]。
本文Memory_cor算法对关联分析中最基础的Apriori算法[18]进行优化和改进,使其适用于时延敏感的内存关联分析场景[19],其基本思想是计算变脏概率大的高频脏页的强关联内存页。算法主要步骤为:
1)以所有内存页修改记录为输入,计算内存页修改次数的频繁2-项集。
2)以内存页修改次数的频繁2-项集为输入,计算高频脏页的强关联内存页。
Memory_cor算法用强关联规则记录所求强关联内存页,强关联规则的格式如下:
{Mn}=>{Mm}
其中,Mn和Mm分别表示第n号内存页和第m号内存页。强关联规则表示Mn与Mm存在空间相关性,如果内存页Mn变脏概率大则Mm也有很大概率变脏。
基于内存关联分析的预拷贝迁移策略最大的时间开销来源于计算高频脏页的强关联规则,为使策略的优化达到理想效果,强关联规则的计算时间应满足:
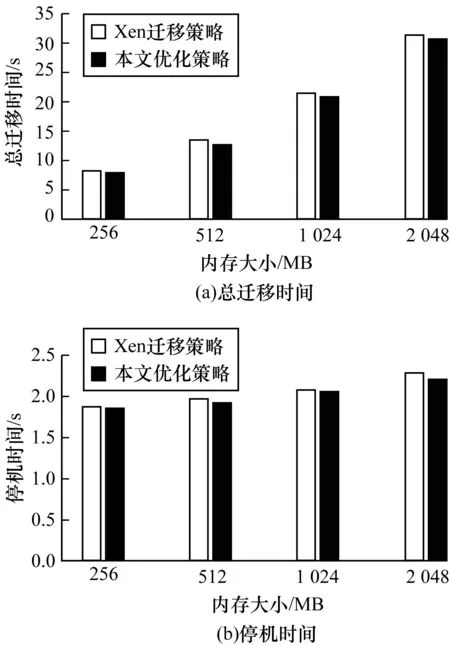
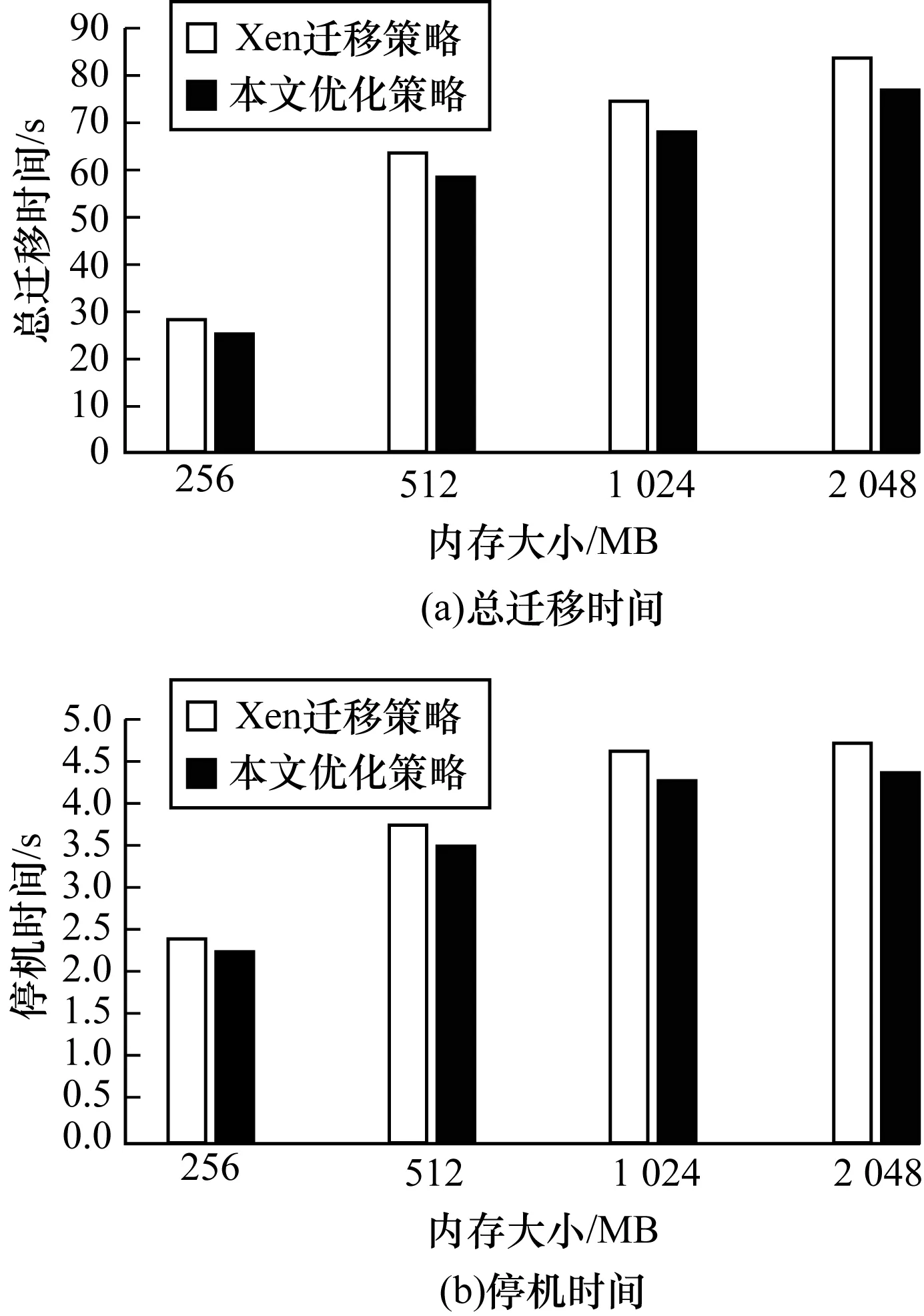
TCalcn 其中,TCalc为计算单个高频脏页强关联规则的时间开销,n为高频脏页的数量,TTra为从源主机传输单个内存页至目的主机消耗的平均时间,m为强关联内存页的数量。计算强关联规则的时间开销必须小于传输筛除的强关联内存页的时间开销,本文策略才能取得时间优化的效果。通过分析可以发现,TTra由网络传输速率决定,而n和m由负载情况决定,TCalc则由Memory_cor算法决定。由于Memory_cor算法只计算Apriori算法中的频繁2-项集,大幅降低了频繁项集的数量,减少了计算单个高频脏页强关联规则的时间开销TCalc,从而提高了优化策略的效率。Memory_cor算法伪代码描述如下: 算法1Memory_cor算法 输入二阶频繁项集L2,脏页表danger_table0 输出加入强关联规则后的脏页表danger_table 1.for all memory m∈danger_table0 do 2./*找出L2中所有包含内存页m的项集*/ 3.Ct= findfreitem(m,L2); 4.if Ct≠φ then 5./*对所有包含m的项集,计算{m}=>{t-m}置信度*/ 6.for all itemsets t∈Ctdo 7.confidence=support(t)/support(m); 8.if confidence≥minconfidence then 9./*将该强关联规则加入danger_table*/ 10.write({m}=>{t-m}) to danger_table; 11.end if 12.end for 13.end if 14.end for 依照Memory_cor算法,首先利用内存页历史修改记录计算修改次数的频繁2-项集,对于本轮脏页表中的每一个高频脏页,判断是否存在包含该脏页的频繁2-项集,若不存在,则判断下一个;若存在,则计算该频繁2-项集中此高频脏页与其他内存页之间的置信度,置信度大于等于最小置信度阈值表示该高频脏页与其他内存页之间存在强关联关系,记录此强关联规则和强关联内存页,一直遍历本轮脏页表直至为空。 基于内存关联分析的预拷贝迁移策略的基本思想是计算变脏概率大的高频脏页及其强关联内存页,在本轮迭代不传输高频脏页及其对应的强关联内存页。为实现该策略,本文定义7个内存页表类型,如表1所示。 表1 内存页表类型Table 1 Types of memory page tables 基于内存关联分析的预拷贝迁移策略实现步骤如图1所示,其中,Mx表示第x号内存页,1表示内存页变脏,0表示内存页未变脏,强关联规则使用{Mn}=>{Mm}格式。 图1 内存迁移优化策略框架 内存迁移优化策略具体步骤如下: 步骤1在预拷贝迁移阶段每一轮迭代开始前,先更新一轮迭代时间内的内存访问状况,将每一轮的内存脏页记录在history_table中。 步骤2判断本轮迭代为第几轮迭代传输,若为前3轮迭代传输,则按原有迁移策略执行,跳过以下步骤,第4轮开始执行本文的拷贝优化策略。 步骤3更新dirty_table0,将dirty_table0复制至send_table,同时使用history_table结合dirty_table0计算出本轮脏页的脏页率,生成dirty_table。 步骤4对dirty_table进行筛选,将脏页率大于判定阈值dmax的内存页放入danger_table0中,这些内存页被判定为高频脏页。 步骤5使用Memory_cor算法计算danger_table0中危险内存页的强关联规则,将强关联规则对应的内存页写入danger_table0中,生成danger_table。 步骤6融合danger_table中的强关联规则,将danger_table中的高频脏页及其强关联内存页均放入skip_table中。 步骤7更新dirty_table0并将新出现的脏页添加到内存页表skip_table中。 步骤8比较send_table和skip_table,取消传输同时出现在2个表中的脏页,传输send_table中剩余的页,清空skip_table与send_table。 步骤9本轮迭代结束,判断是否满足停机拷贝条件,若满足,则开始停机拷贝;若不满足,则转入下一轮迭代。 基于内存关联分析的预拷贝迁移策略实验环境[20]如图2所示,主机Host A和Host B均装有Xubuntu14.04和Xen4.3.0,为验证本文预拷贝迁移优化策略的性能,主机A配置现有的Xen动态迁移策略,主机B配置基于内存关联分析的预拷贝迁移优化策略,主机之间使用千兆以太网交换机连接,NFS服务器为主机提供NFS服务。基于虚拟化平台创建内存分别为256 MB、512 MB、1 024 MB、2 048 MB的Xen虚拟机,对不同内存大小的虚拟机进行来回迁移并对比总迁移时间、停机时间,对每个数据均测量20次取平均值。通过对比现有迁移策略和本文预拷贝迁移策略在不同负载下的总迁移时间、停机时间,以验证本文策略的性能优势。 图2 实验环境 本文在不同负载下的主机A与主机B之间进行Xen虚拟机迁移,进而比较现有Xen动态迁移策略和本文迁移优化策略的性能,实验选择3种应用场景: 1)空载场景:空载场景下Xen虚拟机内除系统自带服务外不运行其他应用。 2)中负载场景:在创建的Xen虚拟机内使用Apache_kafka自带的生产者与消费者性能测试脚本,在生产者吞吐量为4 000 Byte/s、消费者吞吐量为1 000 Byte/s的条件下进行测试。 3)高负载场景:在创建的Xen虚拟机内使用make工程管理器4个线程编译Linux-4.14.103内核包。 图3所示为空载场景下2种策略的总迁移时间和停机时间对比,从图3可以看出,在空载场景下,2种策略的总迁移时间和停机时间相差不大,这是由于空载场景下脏页反复变脏概率低,总变脏内存页数量少,因此,本文迁移略的时间优化效果较小。 图3 空载场景下2种策略的总迁移时间与停机时间对比 Fig.3 Comparison of total migration time and downtime of two strategies under no load circumstance 图4所示为中负载场景下2种策略的总迁移时间和停机时间对比,从图4可以看出,相比现有Xen迁移策略,本文优化策略在虚拟机内存大小为256 MB、512 MB、1 024 MB、2 048 MB的条件下,分别减少了9.0%、8.2%、8.3%、7.9%的总迁移时间和6.6%、7.5%、6.9%、6.2%的停机时间。这是由于在中负载情况下,内存页被频繁改写,优化策略能够有效抑制内存页反复传输的现象,时间优化效果较为明显。 图4 中负载场景下2种策略的总迁移时间与停机时间对比 Fig.4 Comparison of total migration time and downtime of two strategies under medium load circumstance 图5所示为高负载场景下2种策略的总迁移时间和停机时间对比,从图5可以看出,相比现有的Xen迁移策略,预拷贝迁移优化策略在虚拟机内存大小为256 MB、512 MB、1 024 MB、2 048 MB的条件下,分别减少了11.0%、10.7%、9.7%、7.7%的总迁移时间和4.2%、7.6%、10.4%、11.7%的停机时间。由于高负载下内存脏页反复传输的问题严重,而优化策略能够大幅减少脏页反复传输的现象,使预拷贝传输更快收敛,因此,其总迁移时间和停机时间更短。 图5 高负载场景下2种策略的总迁移时间与停机时间对比 Fig.5 Comparison of total migration time and downtime of two strategies under high load circumstance 本文提出一种基于内存关联分析的预拷贝迁移优化策略。依据脏页率对下一轮的内存页变脏概率进行预测,停止传输变脏概率大的高频脏页,同时融入空间相关性原理,利用Memory_cor算法计算高频脏页的强关联页面并取消传输。实验结果表明,该策略在总迁移时间、停机时间和迭代轮数上优于现有的Xen动态迁移策略,其能够提高预拷贝迁移性能。下一步将针对内存页关联性强的特定场景,对Memory_cor算法的参数进行优化,使内存页强关联规则的计算时间更短,效率更高。1.3 预拷贝迁移策略实现

2 实验结果与分析
2.1 实验环境搭建

2.2 结果分析

3 结束语
