基于情感评分的分层文本表示情感分类方法
2020-03-19胡均毅李金龙
胡均毅,李金龙
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
0 概述
文本分类作为自然语言处理(Natural Language Processing,NLP)中的一项基础性工作,被广泛应用于文本检索[1]、文本排序[2]和情感分类[3]等任务中。文本的情感分类要求按照文本整体情感倾向对文档进行分类。其中,识别文档中的积极、消极、中立情感及其表达强度,是取得良好分类效果的关键。
文本由单词等符号信息构成,因此,在进行情感分类前首先需要对这些符号信息进行向量化表示。为了生成更富有情感信息的文本表示并获得较高的分类准确率,本文提出一种基于情感评分的分层注意力网络框架,该框架对文本中的单词、句子进行分层编码,并利用注意力机制加权求和获得文档的最终表示。评估每个单词表现的情感信息,促使注意力机制更加关注文本中的情感内容。在此基础上,提出一种辅助的情感评分网络(SAN)来评估每个单词的情感得分,设计分阶段的联合损失函数来训练框架中的分类器和辅助网络SAN。SAN利用文档标签信息结合当前的单词表示和注意力权重来评估每个单词的情感信息,并将其作为监督信号以进一步调整注意力权重分布。
1 相关工作
自然语言处理任务中一种常见的文本表示方式是由文本中的单词或短语来组成句子/文档[4-5]。由于单词是语义的基本单位,经过学习后的词表示(如预先训练的词向量)可以作为捕捉单词语义信息的特征。较多学者关注上下文共现信息,提出了捕捉句法和语义信息的单词嵌入方法,如word2vec[6]、GloVe[7]。这些词嵌入方法通常将上下文相似但情感相反的单词,如good和bad,映射到向量空间中的相邻位置上,这对于词性标注等任务而言已经包含足够的语义信息,但对于情感分类来说,可能影响对其情感倾向的判断。为了更好地嵌入情感信息,文献[5,8]提出学习情感专用词嵌入(SSWE)方法。SSWE对C&W[9]模型进行了扩展,利用文档的类别标签设计了一个新的损失函数来同时对文本的语义和情感信息进行编码。然而,由于SSWE是将文档全局情感直接分配给每个词,因此当文档内词的情感倾向与文档整体情感倾向相反时,学习和表示其情感信息会比较困难。SSPE[10]在短语表示方面也做了类似的工作,通过将SkipGram[6]进行扩展,把句子情感信息纳入其中。然而,上述工作都致力于改进词或短语本身的泛化表示,忽略了其所在的特定上下文。因此,在特定的上下文语境中学习更富有语义的单词表示,并结合上下文来评估每个单词所含的情感信息仍然是一个挑战。
情感分类任务中的另一个挑战是将单词表示更好地编码为文档表示。根据compositionality[11]的原则,一个较长的表达(一个句子或文本)的语义来源于它所含单词的语义信息。因此,分类任务中通常使用基于神经网络的模型将单词表示结合成文档表示,然后再进行分类。FastText[12]使用单隐层集成所有的单词表示,并取得了较好的效果。但是,FastText只关注单词向量的平均值,而忽略了单词顺序的信息。循环神经网络(Recurrent Neural Network,RNN)[13-14]在文本序列建模方面更有优势,可以更好地捕捉上下文信息,适合对依赖长距离的信息进行建模。卷积神经网络(Convolutional Neural Network,CNN)[15-16]通过类似n-gram的方式逐层提取局部信息构成文本表示,但卷积窗口的大小较难确定[17]。文献[18]提出了一种应用于全局最大池化层的GMP-CNN,以快速提取不同窗口的语义特征。
与RNN和CNN相比,注意力机制[19-20]能够根据不同词的重要程度决定其在构建文本表示时的贡献度。在此基础上,文献[21]提出了分层注意力网络(HAN)模拟文本的构成方式,对单词和句子进行分层编码,并根据注意力权重将其融合成文本表示。文献[22]将用户和产品信息与单词/句子的注意力机制相结合,进一步改进了层次注意力机制。文献[23]提出了一种基于层次结构的文档表示通用框架。为了引入针对不同层次中注意力机制的监督信息以减少模型过拟合现象,文献[24]提出了一种基于情感词典监督的注意力模型(LBSA),其将情感词典和注意力机制通过软约束方法[25]相结合。实验结果表明,当情感词典引导神经网络模型中的注意力机制关注富有情感信息的词汇时,情感分类性能会得到改善。然而,基于情感词典的方法难以找到具有领域和上下文特定关系的意见词[26]。为此,本文提出了基于情感评分的分层注意力网络框架HSAN,其在上下文语境中评价词的情感信息,以生成更富有情感信息的文本表示。
2 基于情感评分的分层注意力网络框架
基于情感评分的分层注意力网络框架HSAN如图1所示,其主要由分层注意力机制分类器H-BiGRU和情感评分网络SAN组成。H-BiGRU分类器是指基于分层注意力机制的双向GRU编码分类器,它包含词表示层、句表示层和注意力机制模块。SAN包含词表示层、注意力机制模块以及情感分析模块,其中,分类器与SAN共享词表示层和注意力机制模块。分类器首先计算单词表示和注意力权重分布,然后在句表示层最后生成文档表示并进行分类。SAN中的情感评分机制评估每个单词的情感信息得分以及强度,并将其作为注意力权重的监督信息。本文假设一个文档有L个句子si,i∈[1,L],每个句子都包含Ti个单词xit,t∈[1,Ti]。

图1 HSAN框架结构
2.1 基于分层的文本表示及分类方法
2.1.1 基于双向GRU的单词表示层
在本文模型中,使用双向GRU来编码单词及其上下文以生成单词的表示。GRU[19]使用门控机制跟踪序列状态update gatezt和reset gatert。其中,zt决定保留多少过去的信息以及添加多少新的信息,rt控制过去状态对候选状态的贡献大小。如果rt等于0,其就会忘记之前的状态。zt和rt更新如式(1)所示:
zt=σ(Wzxt+Uzht-1+bz)
rt=σ(Wrxt+Urht-1+br)
(1)
zt和rt一起控制t时刻的状态信息如何更新,xt是序列在t时刻的输入向量,ht-1是GRU在前一时刻的状态。GRU按照式(2)计算新状态ht:
(2)
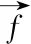
(3)
为了权衡每个单词的贡献,词表示hit将通过tanh激活的单层全连接网络得到其隐状态表示uit,并与单词上下文向量uw相乘,以计算它们与uw的相似度。单词上下文向量uw可以看作是单词级别的固定查询(Question)——“什么是富含信息量的词”的高级表示[27]。uw随机初始化,并在训练过程中随其他参数共同训练。通过softmax函数对相似度进行归一化后,计算出单词的注意力权重αit以衡量单词对句子的重要性。以上过程可以总结为式(4):
uit=tanh(Wwhit+bw)
(4)
根据注意力权重αit,通过单词表示的加权和形式计算句子向量si,如式(5)所示:
(5)
2.1.2 基于双向GRU的句子表示层
给定句子向量si,可以用2.1.1节类似的方法得到文档向量表示。如式(6)所示,首先仍使用双向GRU对句子进行上下文编码,得到句子表示hi:
(6)
为了提高关键句对文档编码的贡献度,再次使用注意力机制,引入一个语句上下文向量us来衡量句子的重要性。同样,根据句子注意力权重αi对句子表示hi进行加权求和,得到文档的向量表示。以上过程可以总结为式(7):
ui=tanh(Wshi+bs)
(7)
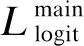
(8)
设数据集共有J个类别,使用正确分类标签的负对数似然作为训练损失,如式(9)所示,其中,j∈[1,J]是文档d的类标。
(9)
2.2 情感评分及注意力权重调整
2.2.1 单词/句子的情感评价
情感分析模块是SAN的一个核心组件,用于评价每个词、句所含的情感信息,并生成相关监督信息以引导注意力机制更多地关注情感词汇。如前文所述,每个单词级别的最终表示hit都捕获了上下文语义,因此,可以用式(10)来计算情感得分向量pit:
qit=tanh(Wqhit+bq)
(10)
其中,Wq、Wpolar是2个可训练参数,bq和bpolar是它们的偏差。
(11)
如式(12)所示,情感得分p也可以用来预测文档的类别,因此,本文同样使用负对数似然来训练情感评分模型,即将文档标签所含的情感信息根据当前的注意力权重分配给每个单词,用于获得当前词表示hit的情感得分。
(12)
为了评价每个单词和句子所体现的情感强度,本文定义了式(13):
(13)
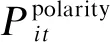
2.2.2 注意力权重调整
为了使注意力机制更多地关注情感强烈的词,本文引入了软约束方法[25],以情感强度占比引导注意力权重分布,使它们的分布尽可能相似。如式(14)所示,Δ(Ppolar,α)表示2个向量之间的交叉熵。
Δ(Ppolar,α)=-∑Ppolar·ln(α)
(14)
其中,λ1、λ2为交叉熵损失的系数,可以用来平衡模型在分类与注意力约束之间的侧重。考虑到HSAN的有效泛化性,本文加入了L1正则使得pit尽可能稀疏,减轻辅助模型SAN的过拟合现象。HSAN分阶段进行训练,E1、E2是控制训练阶段的2个超参数。最终损失函数如式(15)所示,其中,λ3用于调整分类器和评分模型占最终损失的比例。
(15)
3 实验结果与分析
3.1 实验数据集
本文在Yelp 2013、Yelp 2014、Yelp 2015和IMDB 4个大型情感分类数据集上进行实验评估。数据集的统计信息如表1所示,本文将80%的数据用于训练,10%用于验证,其余10%用于测试。Yelp点评来自2013年—2015年的Yelp数据集挑战赛,评分范围为1~5。IMDB点评来自互联网电影数据库,评分范围为1~10。所有数据集均可在http://ir.hit.edu.cn/~dytang/上获取[3]。

表1 实验数据集信息Table 1 Information of experiment datasets
3.2 实验参数设置
对于实验数据集,本文只保留在该数据集中出现5次以上的单词并添加到词汇表中,通过word2vec[6]获得它们预先训练的词向量。对于词汇表之外的单词(Out-Of-Vocabulary,OOV),本文使用(-0.1,0.1)之间的均匀分布来进行随机初始化。在实验过程中,模型的超参数在验证集上进行调优,词向量维数和GRU维度分别为200和50,batch_size设置为64,并尽可能地保证同一batch中的文本长度相似。另外,使用SGD优化器与Cyclical Learning Rate(CLR)[28]、Cyclical Learning Momentum(CLM)[29]取代逐步衰减初始学习速率的方法,CLR中的超参数base_lr和max_lr根据SMITH论文中所述的LR_Range_Test进行调整[28]。实验中的所有训练和测试都在GTX-1080Ti上完成。
3.3 结果分析
3.3.1 性能对比
本文将HSAN与以下2组基准方法进行情感分类准确率比较:
1)基于支持向量机的方法,包括SVM+AverageSG[3]、SVM+SSWE[3]。
2)基于神经网络的方法,包括CNN-word[3]、CNN-char[16]、LSTM[16]、Conv-GRNN[3]、LSTM-GRNN[3]和LBSA[24]。
所有数据集的实验结果如表2所示。其中,H-LSTM代表基于分层注意力的LSTM网络,H-BiLSTM和H-BiGRU分别代表基于分层注意力的双向LSTM和GRU网络。从表2可以看出,HSAN在所有数据集上都有较好的表现,在4个数据集上都达到了最优的准确率,其中,有3个数据集均超过了最优对比模型,另一个数据集与最优对比模型持平。对于较小的数据集,如Yelp 2013和IMDB,本文模型的分类准确率分别达到了68.7%和49.4%,在Yelp 2013上超过最优的LSTM-GRNN模型3.6个百分点,并在IMDB上达到了与最优H-BiLSTM + LBSA相同的准确率。对于较大的数据集,本文模型在Yelp 2014和Yelp 2015上的准确率分别达到了70.5%和71.1%,分别超过最优LSTM-GRNN模型3.4个和3.5个百分点。另外,从对基准分层网络的分类准确率提升效果上来看,LBSA在原本H-BiLSTM的基础上通过情感词典对注意力机制添加了监督信息,减轻了模型的过拟合现象,使得模型的准确率在Yelp 2013、Yelp 2014和IMDB上分别提高了0.3%、0.3%和0.2%[24]。文献[30]通过迁移学习技术,利用基于类噪声估计的样例迁移算法对不同数据集进行筛选和合并,例如,在Yelp 2013上迁移了部分IMDB数据集的数据,使得准确率提高了0.3%[30]。本文在H-BiGRU的基础上添加了辅助情感评分网络SAN,通过让模型自动评价所有词、句的情感信息,并得到它们的情感强度占比来监督注意力机制。在Yelp 2013、Yelp 2014、Yelp 2015和IMDB上,HSAN均优于H-BiGRU模型,而且HSAN不依赖于外部的情感词典,也无需扩增、合并数据集。
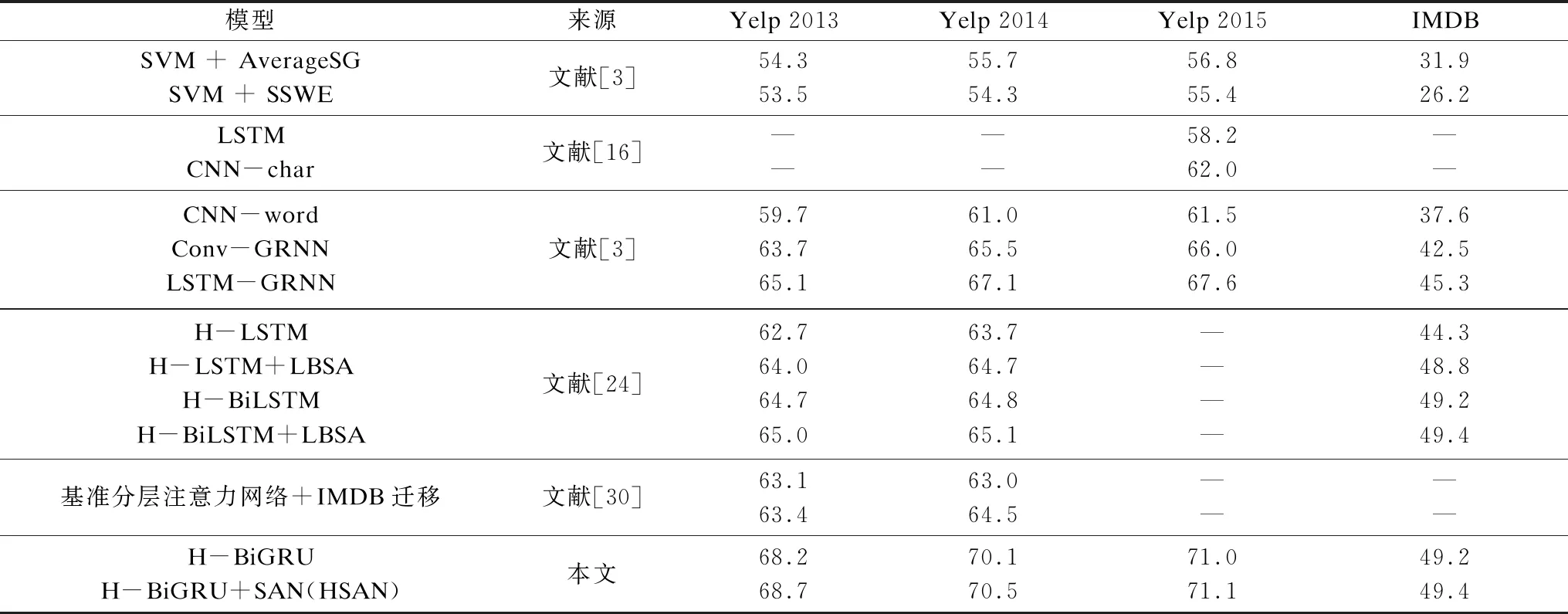
表2 各模型的分类准确率对比Table 2 Comparison of classification accuracy of each model %
3.3.2 辅助网络参数分析
控制辅助情感评分网络SAN占最终损失函数比例的参数λ3和pit中的L1正则化系数对模型性能的影响如图2所示。从图2可以看出,在Yelp 2013数据集上,随着参数λ3的增大,模型在性能表现最优时SAN的L1正则化系数也需要随之增大,这说明随着SAN的变化,要得到更好的训练,需要更大的正则化系数来防止SAN快速过拟合。同时也可以看到,模型的最优准确率随着λ3∈[0.45,0.60]先增大后减小,这说明辅助模型损失占比不能过大,否则会影响分类器的训练效果。当模型准确率达到最优(68.7%)时,λ3的取值为0.50。L1正则化系数的取值为0.000 05。

图2 情感评分网络SAN参数分析结果
Fig.2 Parameter analysis results of sentiment evaluation network SAN
3.3.3 情感评价网络评分分析
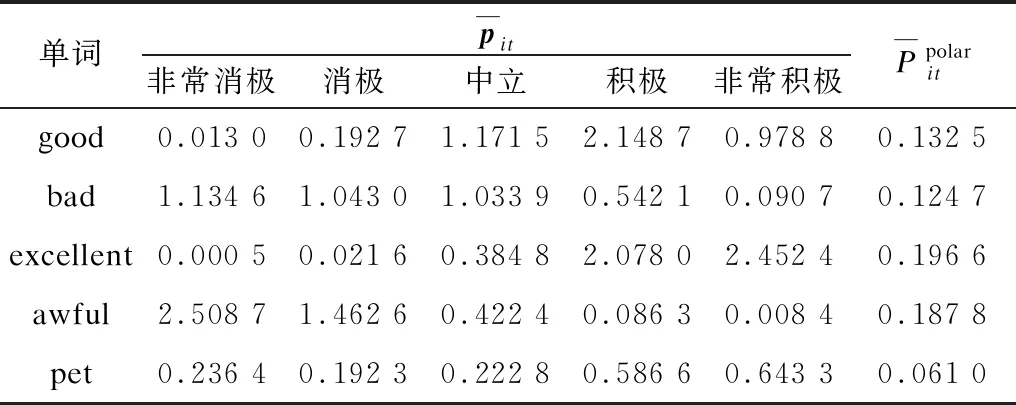
表3 情感评分统计结果Table 3 Statistics results of sentiment evaluation
由表3可以看出,excellent和awful这类情感倾向明显的词平均情感占比最高,good和bad次之,pet最低。而在具体的情感倾向方面,因为Yelp数据集中1分代表最消极,5分代表最积极,而excellent和awful分别在第5维和第1维情感得分最高,证明excellent所表达的情感最为积极,而awful最为消极。类似地,可以发现在Yelp中good的平均情感倾向整体偏向积极,而bad偏向消极,而pet在每个维度的情感得分都较低,且相对平均,证明pet这个词并没有明显的情感倾向。
3.3.4 注意力可视化分析
本文从Yelp 2013中随机抽取4个样例,并对其注意力权重进行可视化,结果如图3所示,其中,GT表示该文档的正确类标,H-BiGRU和HSAN分别表示 2个模型的分类结果。本文用句子的注意力权重来规范单词的权重,以确保只强调重要句子中的重要单词。

图3 注意力可视化结果
为了便于可视化,在图3中,为每个单词显示正比于αit的背景灰度,为每个句子显示正比于αi的背景灰度。其中,αit和αi分别是注意力机制中的单词注意力权重和句子注意力权重。从图3可以看出,利用注意力机制,H-BiGRU选取了good、great、delicious等情感色彩较强的词对文档表示做出较大的贡献。然而,在H-BiGRU出现分类错误的第2个~第4个文档,一些不太具有情感信息的单词(如第2个文档中的pets、第3个文档中的knowledge以及第4个文档中的three)也被赋予了较大权重,但是这些内容对于情感分类结果并没有很大的帮助。而与情感分类密切相关的单词(如第3个文档中最后一句fresh、第4个文档中的solid和fun)却被忽视。本文HSAN情感评分模型对每个单词和句子进行评价,识别出了knowledge、pets、three这类单词与类别相关度较低,因此,HSAN在最终注意力分布上忽略了这些单词,识别出了fresh、solid、fun这类单词,并对not、high、great、good、friendly这类单词给予了更多的关注。
4 结束语
本文提出一种基于情感评分的分层注意力网络框架HSAN,以进行文本情感分类。H-BiGRU按照文本结构先后对文本进行词编码与句编码,情感评分网络SAN利用文档标签以及每个词对文档表示的贡献度对每个单词的情感强度进行评分,并将其作为监督信息返回给分类网络以调整注意力权重分布。实验结果表明,HSAN的分类准确率较高,能够有效地检测出带有强烈情感色彩的词和句子,并生成文档的语义表示以用于情感分类。下一步将探究一种更普适的方法来评估每个词的情感强度,使得SAN尽可能少地遗漏或误判一些情感词汇,进一步提升情感分类的准确率。
