基于BiLSTM模型的定义抽取方法
2020-03-19谢志鹏
阳 萍,谢志鹏
(复旦大学 计算机科学技术学院,上海 201203)
0 概述
定义抽取指从自然语言文本中提取出术语,是本体生成、词汇表抽取、e-learning应用、术语词典、问答(QA)系统中的基本任务。定义抽取的主要任务是从自然文本中提取出定义性的句子,可以建模为句子分类问题。例如,WCL-1和WCL-3系统依赖于一系列词形网格的泛化,这些词形网格是从大型数据集获取的黄金定义中学习到的,从而对文本定义进行建模。DR系统[1]采用依存关系来生成句子的特征集,再利用这些生成的特征集进行句子分类。简单的分类模型依赖句子的结构特征来进行分类任务,但当遇到类似定义句结构的非定义性句子时,分类模型有可能会判断错误。
本文解决定义抽取任务的方法是实现一个序列标记系统。根据定义句概念:X=Y+区别特征,其中,X为术语,Y+区别特征就是术语的定义,可以得出在一个定义句中,一定能够找到至少一对术语及其定义,同样,如果一个句子包含至少一个术语及其相应的定义,那么这个句子就是定义性的。 通过把句子级别的分类任务转换为字级别的标注任务,可以提高对结构模糊的输入句的判断精度。
本文提出基于BiLSTM的序列标注神经网络模型用于定义抽取。BiLSTM具有学习长期依赖信息的能力,能够得到具有全局上下文信息的特征表示,通过LSTM解码器逐字生成最终的标签序列,并运用标注结果完成定义抽取任务。
1 相关工作
随着自然语言研究的发展,人们对与文本自动化处理和智能化知识生成有着越来越高的要求。而互联网技术的不断提高,新兴词汇和用语数量急剧增加,文本语料规模扩大与自动化定义抽取成为学者们研究的热点。定义抽取任务是从非结构化文本中抽取出事件或物件基本属性的描述,这对于进一步深入理解自然语言和构建词典等知识系统有着重要的作用。定义抽取的研究成果可以进一步应用于智能问答系统中,以回答“什么”类型的问题,或是自动构建词汇表,为在线学习平台提供参考依据,也可以用来完成特定领域的术语抽取任务[2]或本体获取[3-4]
定义抽取任务传统上是通过模式匹配来解决的,文献[5]应用诸如“{What is}[determiner]{concept}”之类的模式来挖掘网络上特定主题的概念和定义,可以使用像“X is Y”这样的模式来对手动标注的语料中的句子进行分类。文献[6]利用一种软硬模板相结合的方式抽取定义句,其中硬模板由手工模板和词类格模板结合形成,然后利用N元语言模型匹配完成定义句识别。模式匹配方法是基于规则的,需要大量的人力资源。由于领域的多样性和人力资源的限制,这种方法很难囊括所有的模式,因此模式匹配的方法虽然有着极高的精确度,却从本质上很难提高召回率。文献[7]提出一种通过基因编程(Genetic Programming,GP)学习有效语言规则,然后添加上通过基因算法(Genetic Algorithm,GA)学习到的权重来形成最终的规则集的方法。然而,这种基于GP的方法的召回率仍然很低。即使基于GP的方法能够自动化生成丰富的规则,但是由于定义性句子结构极其多样,这些学习到的规则仍然非常嘈杂。WCL系统[8]采用一种称为词类格(Word-Class Lattices)的有向无环图(DAG)来建模定义。
由于基于模式方法的局限性,有监督的机器学习方法被越来越多的研究者所使用。文献[9]利用词法分析加简单句法分析组成句子特征,然后通过分类完成定义抽取,这种方法虽然利用了句法信息,但是人工对句子中的专有名词以及关键动词的信息分析并没有完全利用到句子整体结构的信息。一些系统通过从依赖树中导出,或结合语言和结构特征来生成所需特征,然后将这些特征输入机器学习分类器中进行定义抽取[10-12]。文献[13]基于N-gram加入了句子结构中的上下文语义依赖关系,来解决N-gram抽取模型的数据稀疏的问题。DefMiner系统[14]通过融合前人的特征工作来生成自己的特征集,特别地,这些特征不仅包括词级别上的,而且也包括在句子级和文档级上提取的,因此可以较充分地保留上下文信息。然后,DefMiner使用条件随机场(CRF)将输入语句中的词标记为集合 A = {(T)erm,(D)efiniton,(O)ther}中的标签,标注术语和定义的F1值分别为45%和 56%。上述有监督学习方法采用的特征都来自于预处理过的语句,这意味着句子预处理操作可能导致偏差和错误传播。文献[15]提出一种利用长短时记忆神经网络获取句子特征的新方法,并在维基百科数据集上进行了实验(取得F1值为91.2%)。
近年来,随着处理大数据集技术的发展,研究者利用弱监督[16-17]或远程监督的方法来增加训练数据的大小或生成领域特定的训练数据。文献[18]提出一个基于远程监控的系统,用于在不使用任何标记数据的情况下自动获取目标语料库中的训练数据,该方法可以在样本数据不足的情况下对训练集进行有效扩充。
2 本文方法
本文模型的整体结构如图1所示,模型算法流程如下:
1)对于输入句中的词,利用词嵌入作为其空间向量表示。
2)与传统的人为建立特征方法不同,本文将词嵌入输入到一个双向长短时记忆循环神经网络中得到输入句的特征表达。
3)利用一个基于LSTM的解码器对得到的特征进行解码。
4)将解码的结果输入到一个CRF中,得到句子整体最优的标注结果。
5)利用模型预测的标签,完成定义句判断。
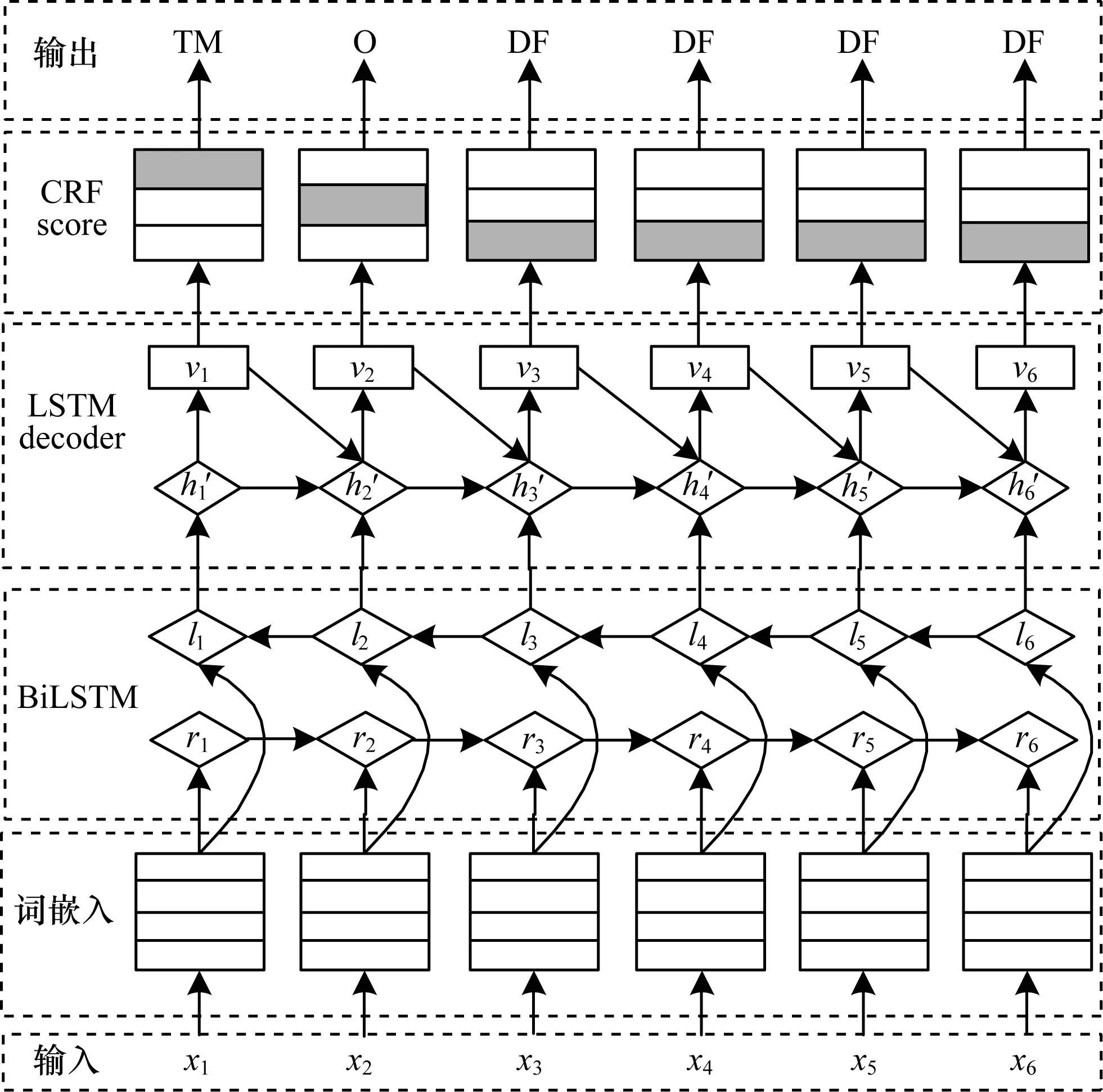
图1 模型整体结构Fig.1 Overall structure of model
本文模型是通过有监督的方法进行训练,数据集选择为WIKIPEDIA数据集,这个数据集的正样本由从维基百科中随机抽取出第1条句子(其中选取的术语属于4个不同的种类)组成,文献[19]对其进行了详细的标注,标注分为4个部分:术语(Definiendum),定义引导词(Definitor),定义(Definiens)和其他(Rest),负样本由来自于抽取到正样本文章中的其他句子组成。鉴于本文的需求,本文对标注数据进行了不同的预处理,将句子中的token标注为集合{TM,DF,NONE} 中的标签,其中,TM 代表术语,DF 代表定义,NONE表示不属于功能性的部分。
2.1 原始输入转换
转化原始输入到token,从训练集中抽取出前1 000的高频词作为高频词表L,如果句子S中的词x属于L,那么句中第i个词xi的token就为ti(ti∈L),如果该词没有出现在高频词中,那么就用该词的词性标注作为词的表征。使用的词性标注采用 TreeTagger系统自动生成。本文采用词嵌入向量作为词的向量表示,然后把词嵌入向量输入到一个BiLSTM 结构中,得到句子的特征表达。
2.2 特征建立
本文的目标是更加自动化的定义抽取。在多数情况下,人为的特征抽取并非来自于句子本身,而是来自加工处理过的包含着词依赖关系、语法等信息的结构,如依存树等,这样的方法可能会损失一部分来自于句子本身的信息,同时,以往的研究工作大多数极为依赖人为建立的特征集合,这些集合可能包含长达数十条规则特征。 虽然大量的人为特征工作可以抽取出更多更好的特征,但需要借助专家的领域知识对训练数据的深入分析和启发性思考,通过抽取或者组合各种原始特征才能得到,需要消耗大量的人力与计算资源,并且随着行业的增加、知识的深入、特征的细化以及领域的不同,人力特征抽取就更加困难,所以本文选择通过自动特征提取的方法计算出原始的特征。选择利用基于字的双向LSTM神经网络对句子进行特征建模,选择这个网络的优点是,BiLSTM在设计上避免了长期依赖,因此可以对长远依赖关系进行建模。通过BiLSTM可以对句子进行从前到后以及从后到前的完整的上下文信息保存,同时,本文的定义部分形态复杂,结构往往较长,使用双向LSTM能够更好地利用句子级的语义特征,对于标注任务也更有效。
2.3 基础LSTM
传统的RNN模型存在着梯度消失和爆炸的问题,在训练的过程中,越远的序列对于正确结果的影响越小,越近的序列对于结果的影响更大,所以不利于保存远距离的信息。LSTM模型通过对其增加控制门等操作解决了梯度消失和爆炸的问题,并且也解决了信息长期依赖的问题。文献[20]对最初的LSTM原型[21]通过增加遗忘门、加入Peephole等操作,使模型更加强大。LSTM单元模型如图2所示。
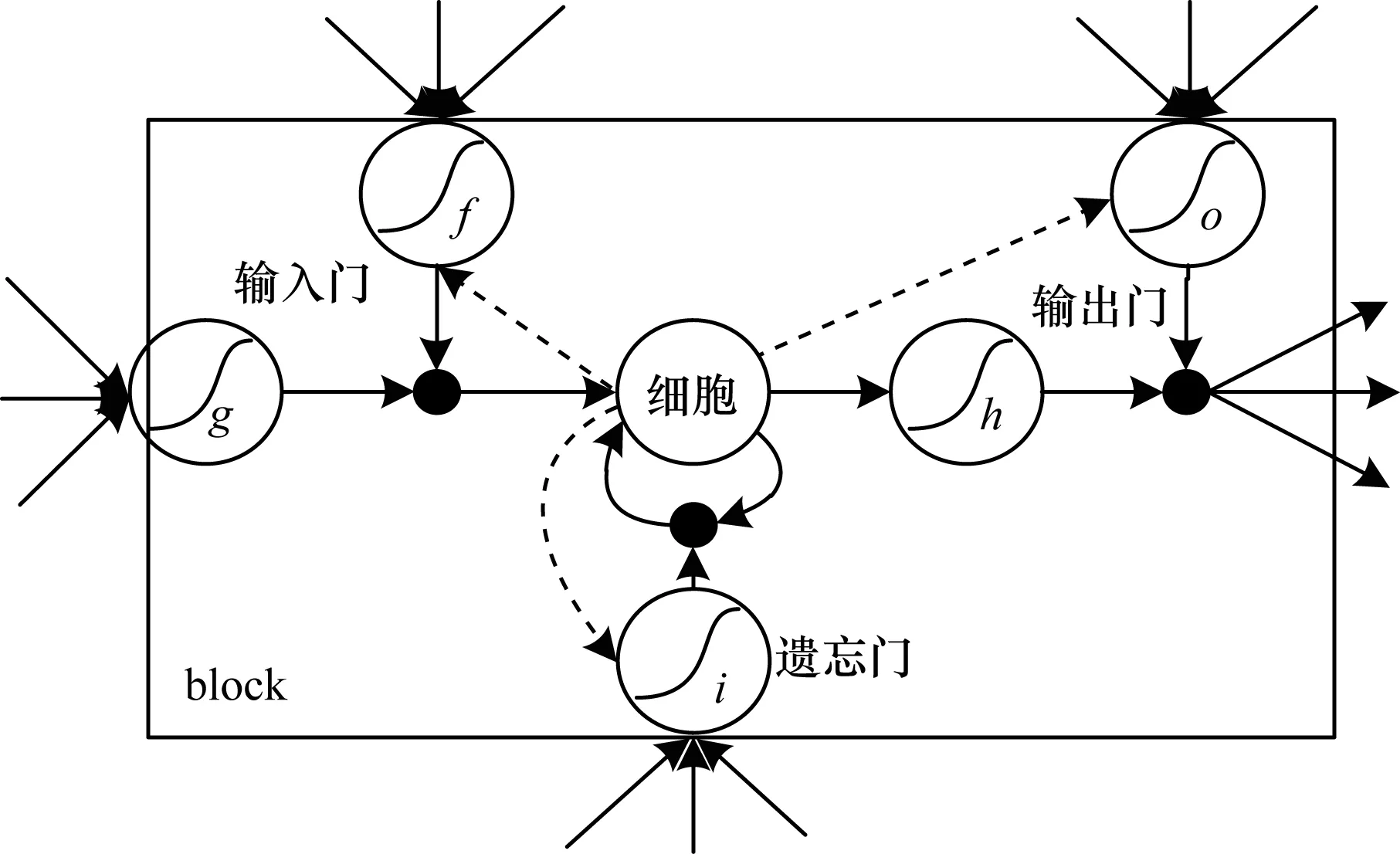
图2 基础LSTM模型Fig.2 Basic LSTM model
与简单的RNN结构不同,在LSTM模型的重复结构中有4个神经网络相互作用。在整个LSTM模型的结构中,细胞状态承载着重要的信息,LSTM通过各种门的作用对细胞状态进行修改,从而得到输出和保留的信息。在LSTM中有3个重要的门来实现信息的改变,包括遗忘门i、输入门f和输出门o。细胞状态公式为:
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(1)
其中,ct表示当前细胞状态,ft表示当前遗忘门,ct-1表示前一个细胞状态,it表示当前输入层,xt表示当前输入句子的token,ht-1表示前一个隐藏层输出,wxy表示从神经元x到y的连接权重,b(.)表示偏置量。
信息的遗弃主要由遗忘门实现,其通过输入xt和隐藏层ht-1来决定是否完全保留或丢弃前一个细胞的每个元素的信息:
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(2)
除信息的丢弃外,信息的更新由输入门实现:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(3)
通过输出门实现对信息的限制性输出:
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(4)
隐藏层输出为:
ht=ottanh(ct)
(5)
2.4 BiLSTM模型
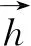
2.5 解码层
在序列标注任务中,每个词会被赋给一个来自集合{TM,DF,NONE}的标签,在这里没有采用大多数适用的BIOS(Begin,Inside,Outside,Single)[22]编码系统,因为对于术语及其定义而言,术语多数以名词的形式出现在谓语之前,在本文的数据集中,术语大部分是单一的词,而定义则是内容丰富的描述,所以,无论是术语还是其定义,其本身的位置信息(术语或定义本身的开始、中间和结尾)对于最终结果的影响很小。
在解码时,本文利用每个词经过BiLSTM的隐藏层输出作为decoder-LSTM的输入,将当前词的decoder-LSTM隐藏层输出变换输入到条件随机场(Conditional Random Field,CRF)中得到最终的句子标记结果,同时把这个隐藏层输出变换,即前一个分类标签信息作为输入传给下一个词进行解码操作。模型的LSTM基本结构与2.3节所述基本类似,输入部分改写为:
it=σ(Wxiht+Whih′t-1+WtiVt-1+bi)
(6)
其中,ht表示BiLSTM的隐藏层输出,h′t-1前一个词的decoder-LSTM隐藏层状态,Vt-1表示前一个标记信息向量。
输入到CRF的向量为:
Vt=Wth′h′t+bth′
(7)
CRF计算分数公式如下:
(8)
其中,Pt,yt表示把wt分类到标签yt的分数,Ayt-1,yt表示从标签yt-1到标签yt的转移分数。
2.6 损失函数
模型的训练目标为最大化对数似然,损失函数为:
(9)
因为数据集相对较小,所以为防止过拟合,在BiLSTM层采取dropout,保留概率为0.8。
3 实验结果与分析
3.1 实验设置
数据集:本文用到的第1个数据集是NAVIGLI等人于2010 年在网络中抽取定义和其上位词的研究而标注的数据集——Wikipedia数据集。该数据集包含了1 902条正样本和2 711条负样本,正负样本中明确地标注了句子的组块和每个token的词性,此外,正样本中还标注出了句子中的术语、定义引导项(通常为紧跟术语的谓语词)、定义及其他,同时人工标注出术语的上位词。第2个数据集是LI等人抽取的中文数据集,包括人工标注的抽取自百度百科的2 161条正样本和2 161条负样本,本文使用哈工大语言技术平台对中文数据集进行了分词、词性标注和依存句法分析等基本处理,然后对该数据集的术语和定义进行了人工标注。
数据预处理:通过转换原始句子到token,首先从数据集中抽取出前N的高词频词,高频词的选取数量N在英文数据集上为1 000,在中文数据集上为500,这在文献[15]中已被证实分别是在英文和中文数据集上取得的最好效果,然后在词级别对原始输入进行处理。本文采用一个BiLSTM神经网络自动生成句子的特征。BiLSTM的单向输出维度为100维,句子特征输出为200维,word embedding 的初始化维度为64,初始学习率为1e-3。
3.2 模型训练
本文在一台装有GeForce GTX 1080显卡的Arch Linux 系统上进行模型的训练和预测。
在Wikipedia英文数据集上,训练50个ephoch,batch大小为64,平均处理输入句的训练速率为108条/s,测试速率为277条/s。
在空间方面,模型复杂度主要跟神经网络的参数量相关。本文的神经网络模型基本结构主要利用到LSTM结构(包括一个BiLSTM和一个LSTM解码器),在该结构中,每一个句子共享相同的矩阵参数。所以,模型复杂度为:
V(LLSTM)=4n(m+n+1)
(10)
其中,n为LSTM隐藏层维度,m为数据的输入维度。
3.3 结果分析
本文采用精确率Precision,召回率Recall和F1作为评价指标。
1)句子分类比较结果
为更好地与本文系统相比较,表1列出了在Wikipedia数据集上各定义抽取系统的结果。其中Star-pattern通过将一些单词转换为stars的方式把句子概括为star pattern,如果输入句与star pattern之一匹配,则将句子识别为定义句。 Bigrams是一个基于二元语法的软匹配模型,提供了一个将模式匹配建模为生成token序列的概率过程的方法,可以用来做定义句检索。Wcl-1系统对于每组句子,从训练集中学习一个词形网格,一个句子如果匹配其中一个词形网格可以被分类为定义性的。Wcl-3系统为每个句子字段分别训练词形网格,如果句子可以匹配任意词形网格集的组合,则将句子分类为定义性的。 Defminer通过使用有监督的序列标记系统来识别术语和其相应的定义。

表1 不同系统在Wikipedia英文数据集上的句子分类结果 Tabel 1 Sentence classification results of different systemson Wikipedia English dataset %
Luis& horacio2014使用一种仅从依赖关系中提取的句法信息进行定义抽取的有监督的分类器进行分类。SVM实现仅使用从句法分析器导出的术语之间的句法依赖性的方法提取定义和上位词关系的系统。Si& bin(with lstm)采用LSTM递归神经网络识别句子是否为定义性的。
从表1可以看出,与传统基于模式的系统相比,本文系统因为避免了传统的人工模式归纳的特征工作,所以在精确率、召回率和F1上都有明显提升。虽然Wcl-1和Wcl-3在精确度上表现较好,但是模式匹配的局限性导致了较低的召回率,从而最终表现较差。与有监督的研究方法相比,本文利用自动特征抽取,避免了繁琐的人力特征工程与人为特征抽取带来的不足,减少了人为因素的干扰和错误传播以及信息不全等弊端。由于利用BiLSTM神经网络生成后续结构的特征输入,因此本文系统与之相比也有较大的优势。与Si& bin提出的神经网络模型相比,本文提出的基于BiLSTM的序列标注神经网络模型进行定义抽取,在最终的定义抽取F1分数上也有着较大的提升。
表2列出了在中文数据集上的实验结果,其中Si& bin是使用LSTM递归神经完成定义抽取的系统。结果显示,本文方法在中文数据集上有着很好的效果,具有处理不同语言的能力。

表2 不同系统在中文数据集上的实验结果 Tabel 2 Experimental results of different systems onChinese dataset %
2) 不同模型结构对实验结果的影响
为证明本文模型的有效性,通过改变模型的结构进行对比实验,如表3所示。其中,实验1为BiLSTM加上未采用decoder的模型,实验2使用CNN,实验3为BiLSTM加上CNN的分类模型,实验4使用LSTM加上decoder。
表3 不同模型对比实验结果
Tabel 3 Compare of experimental results of different models%

实验序号模型精确率召回率F11BiLSTM(no decoder)94.5585.5289.752CNN90.5588.0389.233BiLSTM+CNN92.5991.2991.874LSTM+decoder94.2265.9176.515BiLSTM+decoder(本文系统)94.2190.1092.11
4 结束语
定义抽取是信息抽取中一个重要的任务,对于本体生成、术语抽取等任务具有较大影响。本文提出基于BiLSTM的序列标注神经网络模型完成定义抽取任务,该模型首先将句子中的词标注为集合{TM,DF,NONE}中的标签,然后使用标注结果将句子分为定义性和非定义性的句子分类。对于定义描述不规范和句子结构复杂的定义句,序列标注在词级别上识别句子中的术语和定义,从而增加分类判断准确的机率,实验结果验证了本文模型的有效性。下一步将研究使用弱监督或远程监督的方法自动扩大实验数据规模,从而达到更好的实验效果。
