信息熵加权的HOG特征提取算法研究
2020-03-19林克正张元铭李昊天
林克正,张元铭,李昊天
哈尔滨理工大学 计算机科学与技术学院,哈尔滨150080
1 引言
人脸识别技术始于20 世纪,是新兴的综合性的工程,涉及机器学习,数字图像处理与模式识别等多门计算机专业课程。随着人脸识别技术的不断成熟,人脸识别技术越来越多地被应用到各个领域,包括交通、医药、警务等。人脸识别极大地提高各工作部门的工作效率[1]。
人脸识别中一般包含四个环节:第(1)步,人脸图像的初步检测与提取;第(2)步,对检测到的人脸图像进行预处理,包括灰度化、图像滤波等;第(3)步,对人脸图像进行特征提取;第(4)步,对待识别的图像进行匹配与识别[2]。
梯度直方图HOG(Histogram of Oriented Gradients)是法国研究人员Dalal在2005年CVPR会议上提出的特征提取算法,并将其与SVM 分类器配合,用于行人检测[3]。在他的博士毕业论文中有对HOG 特征更加详细的描述。近年来,HOG 算子被越来越多地应用于特征提取方面并取得了很好的成就[4-6]。此外,有很多研究学者也探索了HOG 特征的潜能,对其进行了进一步的改进,或者使HOG 提取过程与硬件结合发挥其更大潜力[7-8]。但在对HOG 特征的相关研究中,有的只是简单地将HOG 特征应用到人脸全局特征中,有的只对HOG的全局特征和局部特征进行简单的级联,都没有考虑到人脸的不同部位对于识别效果的影响。
考虑到人脸不同部位对于识别效果的贡献程度不同,本文提出了一种信息熵加权的HOG 特征提取方法。该方法将人脸图像划分成几部分,根据不同部分识别贡献率的大小添加不同的权重,加强了人脸重要部位对于识别效果的影响,使得该算法相较于其他方法识别率大大提高,并且该算法对于人脸所具有的光照、姿态表情等变换均有良好的有效性和鲁棒性。
2 HOG特征提取与PCA降维
2.1 HOG特征提取
梯度直方图HOG由法国研究人员Dalal提出。HOG算法的主要目的是将灰度化,归一化的图像进行梯度计算,统计图像的梯度信息[9]。
HOG特征提取的具体步骤为:
(1)对图像进行灰度化处理。
(2)利用Gamma方法对图像全局归一化。
压缩公式为:

对于gamma 的值来说,当gamma <1时,在高灰度值区域内,动态范围变小,图像对比度降低,图像整体灰度值变大,显得亮一些gamma >1在低灰度值区域内,动态范围变小,图像对比度降低,图像整体灰度值变小,变得暗淡。
(3)对处理后的图像进行梯度大小和梯度方向的计算。
通过对像素梯度的计算能够获得图像的边缘信息,降低光照因素对于图像识别的影响。
像素点(x,y)的梯度为:

其中H(x,y)表示像素点(x,y)的像素值,Gy(x,y)表示像素点(x,y)的垂直方向梯度,Gx(x,y)表示像素点(x,y)的水平方向梯度。
在图像中每一个像素点(x,y)的梯度大小和方向分别为:
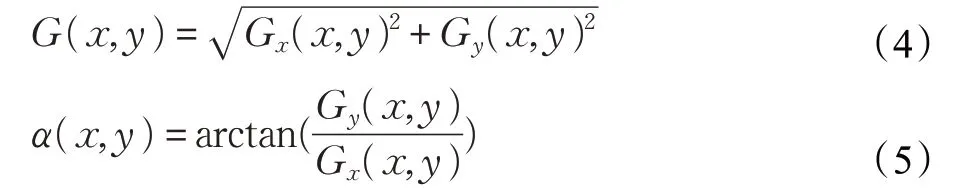
(4)将图像划分成小的细胞单元(cell)。
(5)统计每个cell 的梯度直方图,即可形成每个cell的HOG特征。
本文算法中将细胞单元的梯度方向分成9个方向块,如图1所示。
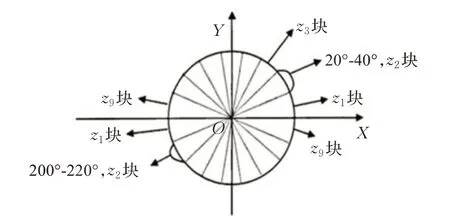
图1 梯度方向划分为9个区间
(6)将几个细胞单元(cell)组成一个块(block)。把一个block内所有cell的HOG特征串联起来归一化便得到该块的HOG特征。
归一化能够克服局部光照变化和对比度变化造成的梯度变化范围较大的影响,进一步地对光照、阴影和边缘进行压缩。
归一化之后的块特征描述符就称为HOG 描述符,图2为3×3个细胞单元组成块的示意图。

图2 细胞单元组成块
(7)将该图像内的所有块的HOG 特征串联起来就可以得到该图像的HOG 特征了。这便是最终用于分类的整幅图像HOG特征向量。
2.2 PCA算法
主成分分析PCA(Principal Component Analysis),也称为卡尔胡宁-勒夫变换(Karhunen-Loeve Transform)[10-11]。PCA 通常用于高维数据集的探索与可视化。还可以用于数据压缩,数据预处理等。
PCA 算法降维的过程主要是将相关性低的高维数据组投射到一个相关性高的低维数据组。PCA 算法的主要过程如下:
(1)计算图像的协方差矩阵
假设有P 幅M×N 人脸图像作为训练学习样本,P幅训练图像记为[x1,x2…,xp]T,那么P 幅人脸图像的平均向量μ可以表示为:

则样本协方差矩阵G 为:

其中Φ=xj-μ,j=1,2,…,P。
(2)计算协方差矩阵的特征向量ωj,将计算所得特征向量按照从小到大的顺序排列,取前d 个较大的特征向量,形成一个新的向量序列,组成投影子空间:

将P 幅训练样本分别投影到特征向量子空间,获得训练样本投影矩阵:

3 信息熵
信息熵的概念是由香农在1948 年在其著作《通信的数学理论》中提出的,他把信息熵定义为“用来消除不确定性的东西”[12]。信息熵是对信息不确定性的度量。熵越高,传输的信息越多,反之熵越低,所包含的信息越少。
信息熵的推导过程如下:
(1)计算信源的不确定度:衡量不确定性的方法就是考察信源X 的概率空间。X 包含的状态越多,状态Xi的概率pi越小,则不确定性越大,所含有的信息量越大。
不确定程度用H(X)表示,简称不确定度。一般写成:

(2)计算自信息量:一个信息本身所包含的信息量,由信息的不确定度决定。即随机事件Xi发生概率为p(xi),则随机事件的自信息量定义为:

(3)计算信息熵
信息熵是随机变量自信息量I(xi)的数学期望,用E(X)表示,则熵的定义为:
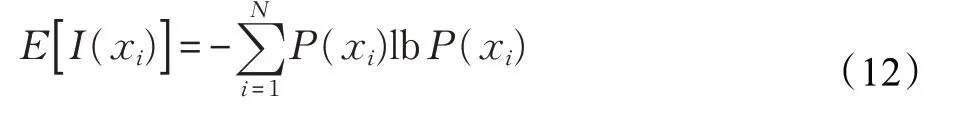
4 信息熵加权的HOG特征提取
信息熵加权的HOG 特征提取首先将待识别的人脸图像进行分块,对分块后的图像进行HOG 特征提取,然后计算每块图像所含的信息熵作为权重系数加到各个分块中形成新的HOG 特征,最后通过PCA 算法对特征进行降维,得到信息熵加权的HOG 特征。算法采用BP神经网络作为分类器,BP 神经网络强大的学习能力可以提高识别效果,将PCA 降维后的特征作为BP 神经网络的输入进行分类。算法如下步骤:
步骤1人脸图像预处理
(1)对检测到的图像进行灰度变换,在人脸图像的识别中对图像的处理大部分都在灰度图像下进行。
(2)对图像进行滤波降噪处理,为防止噪声对于图像识别的干扰,要对图像进行滤波降噪,通过各个滤波的实验选择最佳滤波器。
步骤2图像分块并提取HOG特征


图3 对图像进行3×3分块
在图像进行分块后,对每块图像进行HOG 特征提取。计算每一个块的HOG特征。
步骤3信息熵加权系数的计算
由于人脸各部位的特征对人脸的识别作用不一样,当人脸有不同表情时,只有几个关键部位会发生变化。因此,对于人脸图像的每一子块,应赋予不同的权值系数。设图像分为m个子块,第i个子块的信息熵表示为:

式中n表示像素级数,在实验中所选用的图像像素统一为256,即n=255,表示第k 级像素点出现的概率。子块的信息熵越大,则赋予它越大的权重,则第i子块的权重系数定义为:

步骤4对信息熵加权后得到的HOG特征进行PCA降维。
5 实验结果及分析
实验通过Matlab工具平台进行实验,实验运行环境为InterCore I5 处理器,8 GB 内存,Windows10 操作系统。由于ORL 人脸数据库应用较为普遍,实验首先选择ORL 人脸数据库,由于YALE 人脸库在表情、光照以及姿态等方面具有较大的变化,针对YALE 人脸库进行的实验更具说服力,实验又选择了YALE 数据库。为了验证算法的适用性,实验还选用了FERET 人脸数据库。实验识别分类采用BP 神经网络分类器,实验结果分别与原始HOG+BP 神经网络[13-14]、PCA+BP[15-16]神经网络以及全局HOG+PCA[17-18]方法进行了比较。
5.1 基于ORL人脸数据库的实验
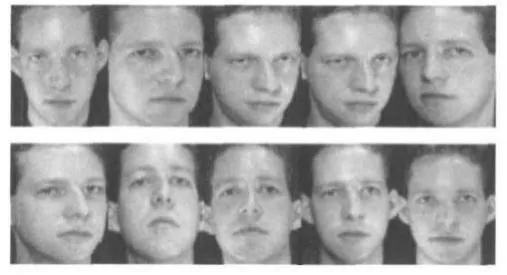
图4 ORL人脸库中某一人的10幅图像
ORL(Olivetti Research Laboratory)人脸库中包含40 人的10 幅人脸图像,共400 幅。每个人有10 幅不同姿态与表情的正面人脸图像。某人的10 个样本图像如图4所示。
取人脸库中每一个人的前N 幅图像用于训练样本,后10-N 幅图像用来测试。本实验中N 取4,5,6,7,8。首先对人脸分块的数目进行选择,通过对几种分块方式识别效果的对比选择出最佳的分块方式。
在ORL 人脸库中对于不同分块方法的测试共进行4 次实验,每一次对人脸进行不同方式的分块,通过对4种分块方式所得的实验结果进行比较,选取最佳的分块方式,得到最佳的实验结果即为本文方法的最终实验结果。不同分块方式识别效果实验步骤如下(以一次3×3分块实验为例):
首先对人脸库中的图像进行3×3 分块,通过上文提到的HOG 特征提取方法对每块进行特征提取,之后通过对每块图像所含信息熵的计算得到每块HOG 特征的加权系数。最后将加权后得到的HOG特征进行PCA降维得到最终的分块HOG特征。
实验所用的识别分类器采用BP神经网络进行识别分类。

表1 不同分块数所得识别结果 %

图5 不同分块识别率的比较
表1 给出几种分块方式的识别结果。识别结果用百分比表示。识别率比较如图5所示。
从表1 和图5 可以看出在ORL 人脸数据库的实验中,3×3分块后的图像识别效果最好。
选择最优分块后,将PCA+BP 神经网络识别算法,原始HOG 特征+BP 神经网络识别算法、全局HOG+PCA+BP 神经网络识别算法和本文算法进行实验比较,基于不同的训练样本数,实验结果如表2及图6所示。

表2 各算法识别率的比较 %

图6 不同样本识别率的比较
从表2 和图6 可以看出信息熵加权后的HOG 人脸特征通过PCA 降维处理,再通过BP 神经网络进行分类的人脸识别方法可以有效地提高人脸的识别效率。这主要因为信息熵加权后的HOG 算子加强了人脸重要部位如鼻子,眼睛等对于识别效果的影响,降低了不重要部位对于识别效果的干扰。
5.2 基于YALE人脸数据库的实验

图7 YALE人脸数据库的部分图像
YALE 人脸库中共包含15 个人的11 幅人脸图像。共165 幅图像。由于YALE 人脸库在表情、光照以及姿态等方面具有较大的变化,针对YALE 人脸库进行的实验更具说服力与可行性。YALE 人脸数据库的部分图像如图7所示。
在实验中,随机地选取YALE 人脸库中每一个人的前N 幅图像用于训练样本,后11-N 幅图像作为测试样本。本实验中N 取4、5、6、7、8。首先对人脸分块的数目进行选择,通过对几种分块方式识别效果的对比选择出最佳的分块方式。
在YALE 人脸库中对于不同分块方法的测试共进行4 次实验,每一次对人脸进行不同方式的分块,通过对4 种分块方式所得的实验结果进行比较,选取最佳的分块方式,得到最佳的实验结果即为本文方法的最终实验结果。不同分块方式识别效果实验步骤如下(以一次3×3分块实验为例):
首先对人脸库中的图像进行3×3 分块,通过上文提到的HOG 特征提取方法对每块进行特征提取。通过对每块图像所含信息熵的计算得到每块HOG 特征的加权系数。将加权后得到的HOG特征进行PCA降维得到最终的分块HOG特征。
实验所用的识别分类器采用BP神经网络进行识别分类。
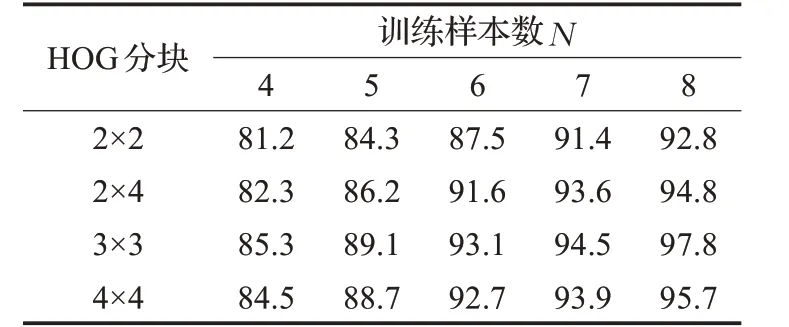
表3 不同分块数所得识别结果 %
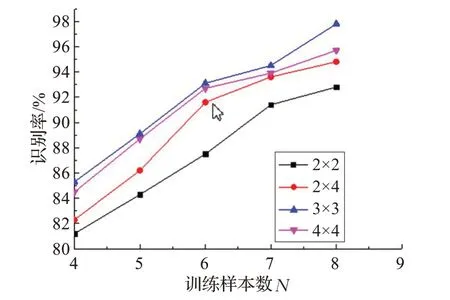
图8 不同分块识别率的比较
表3 给出几种分块方式的识别结果。识别结果用百分比表示。识别率比较如图8所示。
从表3 和图8 可以看出在YALE 人脸数据库的实验中,同样是3×3分块后的图像识别效果最好。
对图像进行分块选择后,将PCA+BP神经网络识别算法,原始HOG 特征+BP 神经网络识别算法、全局HOG+PCA+BP神经网络识别算法和本文算法进行实验比较,基于不同的训练样本数,实验结果如表4和图9所示。

表4 各算法识别率的比较 %
通过表4 和其对应的的折线图9 可以看出,采用的方法明显地优越于PCA+BP神经网络、原始HOG 特征+BP 神经网络以及全局HOG+PCA 的方法,这主要因为信息熵加权方法充分考虑了人脸各部位信息对于识别效果的影响,降低了不重要部位对于识别效果的干扰,相比于传统的全局HOG特征对人脸特征的描述更为全面。

图9 不同样本识别率的比较
5.3 基于FERET人脸数据库的实验
FERET人脸图片库的规模庞大,包含了1 199个人将近14 000 多幅图像,均是在不同拍摄角度、姿态和不同面部表情下采集的。实验中选用FERET 图片库的一个子集共包含了200×7幅图像(由200人组成,每人有7幅图片)。图10 展示了FERET 人脸图片库上某个人的部分人脸图像。

图10 FERET人脸库上某个人的人脸图像
由于子集中每个人有7 幅图像,因此实验中的训练样本数N 取2、3、4、5。测试用例数M 取10-N。
首先进行人脸分块实验。在FERET 人脸库中对于不同分块方法的测试共进行4 次实验,每一次对人脸进行不同方式的分块,通过对4 种分块方式所得的实验结果进行比较,选取最佳的分块方式,得到最佳的实验结果即为本文方法的最终实验结果。不同分块方式识别效果实验步骤如下(以一次3×3分块实验为例):
首先对人脸库中的图像进行3×3 分块,通过上文提到的HOG 特征提取方法对每块进行特征提取,之后通过对每块图像所含信息熵的计算得到每块HOG 特征的加权系数。最后将加权后得到的HOG特征进行PCA降维得到最终的分块HOG特征。

表5 不同分块数所得识别结果 %
表5 给出几种分块方式的识别结果。识别结果用百分比表示。识别率比较如图11所示。

图11 不同分块识别率的比较
从表5 和图11 可以看出在FERET 人脸数据库的实验中,3×3分块后的图像识别效果最好。
选择最优分块后,将PCA+BP神经网络识别算法,原始HOG 特征+BP 神经网络识别算法、全局HOG+PCA+BP 神经网络识别算法和本文算法进行实验比较,基于不同的训练样本数,实验结果如表6及图12所示。
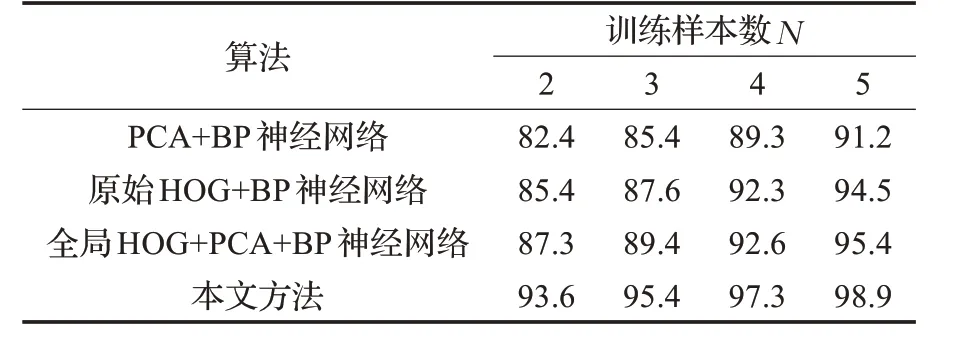
表6 各算法识别率的比较 %

图12 不同样本识别率的比较
通过表6 和其对应的的折线图12 可以看出,信息熵加权的HOG 特征提取算法同样适用于FERET 数据库。在三种数据库上的实验证明了算法的适用性和有效性。
6 结语
本文提出了一种新颖的信息熵加权的HOG 特征提取人脸识别算法。该方法一方面继承了HOG 小波能够克服光照、尺度、角度等全局干扰对识别效果的影响的能力,另一方面充分考虑了人脸各部位信息对于识别效果的影响,降低了不重要部位对于识别效果的干扰,使得识别效果显著增强。对于人脸的光照、姿态、表情等干扰因素,该算法显示出良好的有效性和鲁棒性。但是该算法还存在着一些不足之处,在实验中对人脸进行分块时没有探究不同区域大小对图像进行分块对图像识别效果的影响。接下来的工作重心将研究不同区域大小对图像进行分块,争取更完整地突出人脸的关键区域,使得人脸关键部位的影响程度更完全地体现。
