基于“数据驱动+智能学习”的合成孔径雷达学习成像
2020-03-18倪嘉成
罗 迎 倪嘉成 张 群③
①(空军工程大学信息与导航学院 西安 710077)
②(信息感知技术协同创新中心 西安 710077)
③(复旦大学电磁波信息科学教育部重点实验室 上海 200433)
1 引言
合成孔径雷达(Synthetic Aperture Radar,SAR)作为一种利用微波进行感知的主动传感器,能够不受天气、光照等条件限制,对感兴趣目标进行全天候、全天时、远距离的持续观测,并具有识别伪装、对光学隐蔽目标成像的能力,因而成为军事侦察、情报获取的主要探测手段。目前,SAR技术已经广泛应用于机载、星载、弹载等多种平台,成为各国争相发展的重要侦察技术[1]。
对感兴趣目标的数量、位置、型号等参数信息的精确获取一直是SAR最为重要的研究内容之一。现阶段的SAR信息处理主要分为成像和解译两大部分,两者的研究之间相对独立。成像方面,SAR成像系统发展迅速,机载SAR分辨率普遍达到亚米级,个别已经达到厘米级;成像幅宽与平台高度和成像体制有关,最大可达上百公里;SAR数据获取能力也得到了大幅提升,单次航过回波数据量大幅增加。然而,图像分辨率提升和图像整体细节的增加也使得图像数据量大幅增加,图像背景也更加复杂,给部分目标检测、识别算法增加了难度。因此,SAR成像在分辨率方面的提升并未从本质上解决现阶段SAR图像解译困难、特别是对重点目标识别率低的问题。SAR解译方面,目前对SAR图像中感兴趣目标的解译工作仍大量依靠人工完成,无法满足目标信息处理的实时性需求。受SAR图像尺寸大、相干斑噪声严重、背景复杂、目标轮廓模糊等因素影响,现有的SAR图像解译方法在有效性、准确性和时效性方面同样无法满足对重点目标的信息处理需求。另外,现有SAR解译方法主要从SAR图像中提取目标信息,在图像预处理、特征提取等解译过程中丢掉了大量图像细节信息,导致了SAR成像资源的浪费。SAR成像和解译各自开发了大量算法,复杂度越来越高,但目标分类识别率低、目标属性判别困难的问题依然存在。
本文针对机载SAR中存在的问题展开研究,在分析机载SAR研究现状及存在问题的基础上,尝试从SAR成像解译一体化角度出发,基于“数据驱动+智能学习”的方法,探索提升机载SAR的信息处理能力的新思路。本文分析了基于“数据驱动+智能学习”的SAR成像解译一体化的可行性及现阶段存在的主要问题,在此基础上,以成像解译一体化为目标,提出一种基于“数据驱动+智能学习”的SAR学习成像方法,给出了初步的仿真结果,并展望了未来需要解决的关键性技术问题。
2 机载SAR研究现状及存在的主要问题
机载SAR具有机动性好、工作方式灵活、机上实时成像下传等优势,被广泛应用于军事、民用领域。近年来,中科院电子所、国防科技大学、西安电子科技大学、清华大学等国内多家单位在机载SAR研究领域取得了丰硕的研究成果,极大推动了我国机载SAR成像技术的发展[2-7]。
SAR成像方面,目前机载SAR已经向高分辨、多通道、多极化、多模式的方向发展,并在维度上由2维向3维突破。成像模式上,SAR成像已由原来的条带、聚束、扫描模式向滑动聚束模式[8]、
TOPS(Terrain Observation by Progressive Scans)模式[9](多用于星载SAR)等高分辨率宽测绘带成像模式扩展;成像维度方面,由早期的干涉SAR到现在的层析SAR[10](主要用于星载SAR成像)、阵列SAR[11,12]、圆迹SAR[2],以及最新提出的SAR微波视觉3维成像技术[13,14],都推动了SAR成像由2维向3维发展。成像对象方面,现有成像方法除了能获得高分辨的静止场景成像结果外,还逐步具备动目标检测与动目标聚焦成像能力[15-17]。成像方法方面,现有的SAR成像方法主要有两种,一种是基于匹配滤波的SAR成像方法,该方法不依赖任何目标的先验信息,直接通过傅里叶变换和匹配函数进行成像,具有实现简单、成像稳定的优点,但存在采样要求严格、分辨率受限、成像结果旁瓣较高等不足;另一种是基于稀疏优化理论的SAR成像方法,该方法将SAR成像问题转化为“反问题”(Inverse problem),通过增加目标的稀疏先验信息对求逆模型进行约束,利用迭代优化算法求解场景的散射系数,具有采样率低、分辨率高、成像结果旁瓣小等优势[18-20],但目前也存在计算复杂度高、对机载平台误差适应能力弱、优化算法超参数选择困难等问题。
解译方面,现有方法主要围绕自动目标识别(Automatic Target Recognition,ATR)的3级处理流程展开[21]。在3级流程中,对目标特征的准确提取是SAR ATR的核心,目标特征可以分为基于人工设计的特征以及高维数据特征两种。人工设计的特征包括灰度特征、几何特征、变换域特征、纹理特征等等[22],而高维数据特征主要包括各种深度神经网络提取的隐藏层数据特征[23]。目前,基于智能学习方法的SAR ATR技术发展迅速,识别率相比人工特征得到了很大提升。但智能学习方法需要大量图像数据进行网络训练,现阶段各类型SAR传感器虽然积累了大量SAR图像数据,但针对特定型号目标,且带有标记数据的SAR图像目标数据库还较少,样本数据不足的问题一定程度上限制了基于智能学习的SAR ATR技术的发展。另外,现有基于智能学习的SAR目标检测、识别方法对图像尺寸和背景杂波有一定要求,面对大场景SAR图像、复杂背景SAR图像的检测率和识别率还有待进一步提高。
虽然机载SAR技术近年来取得了飞速发展,在民用方面取得了广泛应用,但在感兴趣目标的参数获取与属性判别方面,现有方法距离实际应用还有较大差距。目前,受数据处理能力不足的限制,对SAR图像中感兴趣目标的解译工作仍主要依靠人工完成。而现有SAR图像ATR方法在有效性、准确性和时效性方面同样无法满足实际应用需求。具体而言,现阶段机载SAR系统在感兴趣目标参数获取方面还存在以下问题:
(1)SAR成像系统与SAR图像解译系统互相独立,无法共同作用提升SAR信息处理能力。SAR系统通过传感器获取0级数据后,需要首先利用机载实时成像系统或地面站对回波进行处理,通过各种成像算法得到SAR图像,然后再利用解译系统对SAR图像进行处理,从中提取感兴趣目标的特征信息,进而获取目标的参数信息。现有SAR成像方法主要考虑如何提升分辨率、增加图像细节,很少考虑到后续SAR图像处理中面临的困难。分辨率的提升一方面增加了目标的细节信息,但另一方面回波数据量也大幅增加。图像整体细节增加的同时图像背景也更加复杂,这也给一部分目标检测、识别算法增加了难度。此外,图像数据量的增大也给解译方法增加巨大负担,态势获取的时效性差。因此,现有SAR成像方法主要提升分辨率和图像细节,无法直接提高对目标属性的判别能力,大量成像资源在解译过程中被浪费。同样地,现阶段SAR解译方法只能从图像中提取目标特征信息,为了去除背景,突出目标,需要大量预处理操作,在图像去噪、感兴趣区域提取的过程中又丢掉了大量信息,损失了图像细节。另外,现有SAR目标解译方法主要基于像素进行处理,面对动辄上亿像素的大场景SAR图像,图像解译速度无法满足态势获取的实时性要求。
(2)现有方法对海量SAR数据的利用率低。SAR传感器方面,现有SAR传感器已经具备多波段、多通道、多极化、干涉等多类型的SAR数据获取能力,然而现阶段不同类型的SAR传感器及获取的SAR数据只能单独进行处理,对如何获取不同传感器之间关于同类型目标的共有特征研究较少。SAR成像方面,多年来大量SAR传感器积累了海量的SAR回波数据和SAR图像数据,然而由于数据处理能力的不足,大量SAR数据被闲置,未得到有效利用。另外,现阶段相同目标在不同雷达参数、多视角、多入射角条件下的共有特征还未得到提取与挖掘。SAR解译方面,大量的SAR解译方法提取了目标的几何尺寸、结构、形状、统计分布等多种类的特征信息,然而提取到的目标特征互相之间没有建立联系,无法共同作用提升目标识别性能。
(3)复杂背景下目标属性判别困难,不同种类目标之间的识别难度差异较大。现有的SAR自动目标识别方法主要利用人工设计好的特征实现对目标的属性判别,例如图像灰度统计特征、结构特征、纹理特征等。上述人工特征对目标-背景差别明显的图像效果较好,例如空地上的坦克、航行中的舰船等简单背景目标。当面对机库附近的飞机、港口里的舰船等复杂场景目标时,由于背景中也包含大量人工特征,导致现有SAR目标检测方法的准确率大幅下降。同时,人工设计的特征通用性较低,往往只适用于某些特定场景,敌方还能够有针对性地设计满足人工特征的假目标,使得真假目标间对应的特征差异性降低,从而提高SAR系统的战场态势获取难度。
3 基于“数据驱动+智能学习”方法的SAR成像解译一体化分析
通过第2节的分析不难看出,现阶段SAR成像技术与SAR解译技术之间相互割裂,严重影响了SAR感兴趣目标参数获取的准确性和时效性。如果能够突破SAR成像与SAR解译之间的限制,实现成像解译的一体化,必将极大提升SAR系统的整体数据处理能力和处理时效性。下面本文从信号性质变换关系出发,对基于“数据驱动+智能学习”方法的SAR成像解译一体化展开分析讨论。
3.1 从“回波数据域”到“目标参数域”
从信号的性质变换关系来看,现阶段的SAR信息处理主要涉及3个“域”的映射关系,即SAR成像通过傅里叶变换和匹配滤波方法,将单次航过的SAR回波数据从“数据域”映射到观测场景的2维“图像域”;而SAR图像解译则通过各种图像处理方法,将SAR图像从“图像域”映射到“目标参数域”,其中目标参数域包含目标位置、尺寸、数量、型号、动目标速度、运动方向等多种目标特征参数。图1给出了现阶段SAR信息处理的基本流程及3个“域”的映射关系图。
可以看出,突破SAR成像与SAR解译之间的限制,关键就是要找到从“回波数据域”到“目标参数域”的映射关系。图1中,SAR成像过程虽然可以用线性模型来表示,但机载SAR往往面临载机运动误差、目标非合作机动以及复杂电磁干扰等影响,因此从“回波数据域”到“图像域”是一种非线性映射关系。在SAR解译中,从“图像域”到“目标参数域”包含去噪、分割、特征提取等多种图像域操作,两者之间的映射是一种复杂的非线性关系。因此,直接从“回波数据域”到“目标参数域”的映射关系必然是高度抽象和非线性的。
针对这一问题,基于数据驱动的智能学习方法为寻找“回波数据域”和“目标参数域”之间的复杂非线性映射关系提供了新的思路。如果从机器学习的角度来分析,那么匹配滤波SAR成像、稀疏SAR成像以及基于人工特征的SAR特征提取方法都可以归类于模型驱动的方法。模型驱动的优点是参数少,在成像时只需要单次航过的SAR回波数据,在目标检测、识别时对目标训练样本的需求也较小。而缺点则是要求模型足够精确和简单,因此对复杂非线性映射的拟合能力较弱。与传统基于模型驱动的SAR成像和SAR解译方法相比,数据驱动方法的优势是适应力强,能够最大限度拟合数据中的复杂非线性映射关系,而缺点则是神经网络的拓扑结构设计难度大、网络参数多、对数据量的需求巨大。
近年来,深度学习、强化学习、元学习等智能学习方法发展迅速,并已在多个领域展现出强大的优势。智能学习方法以海量目标数据作为输入,利用构建的深层非线性网络,通过学习训练的方法获取海量数据中蕴含的复杂非线性映射关系。目前,智能学习类方法已经成功应用于SAR图像解译,能够从海量SAR图像数据中获取目标的高维抽象特征,实现对目标类别的区分。然而现有方法只能够表征SAR从图像域到目标单一参数域的映射关系。下面以典型深层神经网络为例,分析智能学习方法如何表征回波数据域到目标参数域的非线性映射关系。
典型深层神经网络的某一层网络输出通常可以表示为
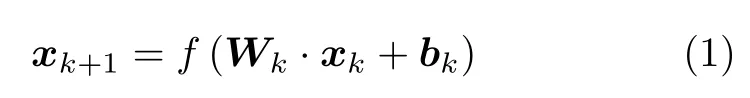
其中,xk表示网络第k(k=1,2,···,K)层的输入向量,Wk表示第k层的权重,bk为第k层的偏置,f()表示非线性激活函数,该函数将括号内的线性组合形式变换为非线性形式,从而能够通过多层的网络输出拟合复杂的非线性映射关系。对于SAR成像而言,可以将其看作一个线性反问题,表示为矩阵和向量相乘的形式

其中,s ∈CP Q×1表示SAR回波信号的离散化向量形式,P为距离向采样点数,Q为方位向采样点数。σ ∈CMN×1表示观测场景散射系数的向量形式,M,N分别为距离向和方位向离散网格数。n ∈CP Q×1为噪声向量。Φ ∈CP Q×MN表示成像观测矩阵,反映了观测场景到回波信号的全部映射关系。基于“数据驱动+智能学习”方法的SAR“回波数据域”到“图像域”映射,可以将式(2)表示为式(1)中的形式:

图1 现阶段SAR信息处理基本流程图Fig.1 Basic flow chart of SAR information processing at present
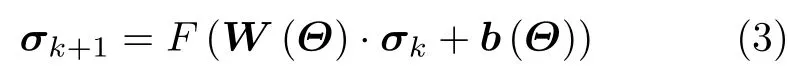
其中,W(Θ),b(Θ)分别为权重项和偏置项,Θ={Φ,σ,···}表示与观测矩阵、成像场景有关的待学习参数,F()为非线性激活函数。对于SAR解译,以目前广泛应用且效果较好的卷积神经网络为例,在得到场景散射系数σ后,目标的类别信息y可以表示为
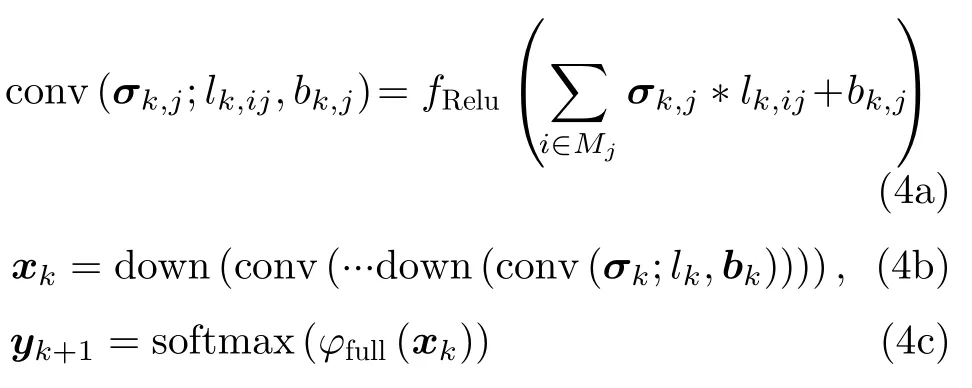
其中,conv()表示卷积层操作,Mj表示输入图像块的集合,l为卷积核,b为偏置,k是层序号,i是卷积核序号,j是特征图通道序号,fRelu()为非线性ReLU激活函数,“*”表示卷积运算。x表示网络得到的特征图,down()表示池化层操作,目的是对特征图进行下采样,φfull()表示对提取的特征图进行全连接,即将上一层得到的特征图进行顺序排列。softmax()表示最终的分类操作,一般选用softmax分类器进行。
将式(3),式(4)对应的网络结构合并,即能在一定程度上实现从回波数据到目标类别信息的映射。然而该网络仅仅能够表征含单一目标的SAR回波数据到目标类别参数的映射关系,针对包含多个目标的宽幅SAR场景,还需要在此基础上添加多层网络结构,例如目标检测网络、特征提取网络等。图2给出了一种基于神经网络结构的“回波数据域”到“目标参数域”成像解译一体化流程图。网络以SAR回波数据作为输入,可以添加现有SAR目标图像和目标先验特征作为样本标签,当网络训练完毕后,从SAR回波到目标参数和目标类别只需要进行一次网络正向传递,无需任何迭代和反向传播,有望大幅提升SAR目标参数获取的准确性和时效性。
3.2 现阶段存在的问题分析
虽然近年来基于智能学习的数据驱动方法在信号处理,特别是图像处理领域展现出强大的优势,只要网络模型足够复杂,理论上可以拟合任意非线性函数,但现阶段基于“数据驱动+智能学习”方法,直接利用海量数据学习得到“回波数据域”到“目标参数域”的映射关系还存在以下困难:
(1)观测数据集的完备性无法保证。SAR回波中包含雷达参数、载机航迹、雷达波入照角、目标运动等多种可变参数,任何参数的变化都会影响“回波数据域”到“目标参数域”的映射关系。现阶段同一目标在多航迹、多角度条件下实测数据较少,动目标成像中的目标运动轨迹、运动参数未知,成像幅宽大幅增加使得网络异常复杂,依托现有SAR数据无法直接满足数据集的完备性要求。
(2)对未知非合作目标的数据获取困难,依靠数据驱动来获得有效特征存在小样本甚至零样本的难题。现阶段对新型未知目标的数据获取极为困难,而仿真数据与真实数据的差异性较大,现有智能学习方法还无法直接利用。
(3)SAR回波数据标注困难。由于SAR回波数据只是观测场景散射点后向散射回波的叠加,本身并不含任何标签信息,因此将回波数据与目标参数对应时,必须人为添加回波数据的标签信息,这大幅提升了智能学习方法的学习成本。
通过以上分析可以看出,从SAR“回波数据域”到“目标参数域”之间的参变量数量非常巨大,未知非合作目标数据量少,样本标签制作复杂耗时,因此依靠现有的数据获取条件直接表征两者之间的复杂非线性映射关系还存在很大难度。考虑到当前智能学习类方法在SAR图像解译方面(包括目标检测、特征提取、分类识别等)已经取得了很好的应用效果,从图2所示的成像解译一体化流程图可以看出,若能构造出成像网络来实现“回波数据域”到“目标图像域”的非线性映射,将有望通过多个网络的级联来实现“回波数据域”到“目标参数域”的非线性映射。因此,下面着重讨论如何构造成像网络,并给出基于“数据驱动+智能学习”的SAR学习成像方法,初步的仿真实验表明,利用构造网络来实现SAR成像的思路是可行的,且相比现有经典成像方法,具有更快的成像速度和成像性能。
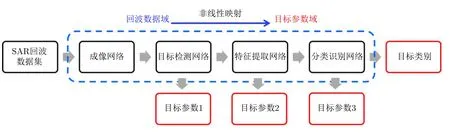
图2 一种SAR“回波数据域”到“目标参数域”成像解译一体化流程图Fig.2 An flow chart of SAR imaging &interpretation integration from“echo data domain”to“target parameter domain”
4 基于“数据驱动+智能学习”的SAR学习成像
为了简化SAR“回波数据域”到“目标参数域”的映射关系,降低参变量数量,减少对样本数据集的完备性需求,本节以图2中的成像网络为目标,提出一种基于“数据驱动+智能学习”的SAR学习成像方法。
第3节中已经提到,SAR成像问题可以转化为一个反问题进行求解。目前,基于深度学习的数据驱动方法已经在信号恢复[24]、图像去噪[25]、图像复原[26]等反问题求解领域展现出优势。文献[27]率先将深度学习应用于SAR成像中,提出了一种基于深层展开迭代软阈值算法(Iterative Soft Thresholding Algorithm,ISTA)的SAR成像方法,实现了含相位误差条件下的点目标成像。文献[27]初步验证了深度学习方法在SAR成像中的可行性,但该方法的可学习参数较少,因此对迭代算法的依赖性更强,而对数据的“学习”能力弱,另外该方法并未解决复数信号的网络训练问题,对场景的重构质量有待进一步提高。
本文提出的基于“数据驱动+智能学习”的SAR学习成像网络将非线性激活函数、损失函数等网络参数纳入可学习范围,进一步拓展了数据在基于智能学习的SAR成像中的应用范围。首先给出SAR学习成像网络结构,然后详细介绍网络参数的选取及训练方法,并在第5节给出仿真实验和分析。
4.1 网络结构
传统神经网络的某一层输出可以用式(1)来表示,即在一个线性模型的基础上增加一层非线性激活函数。该网络结构的优势是方便进行误差反向传播和参数调优。根据3.1节的分析,SAR成像同样可以表示为一个矩阵-向量相乘的线性模型,称为1维SAR观测模型。图3给出了该模型的示意图。假设SAR发射线性调频(Linear Frequency Modulation,LFM)信号,那么在条带成像模式下,观测矩阵Φ的具体表达式可以写为
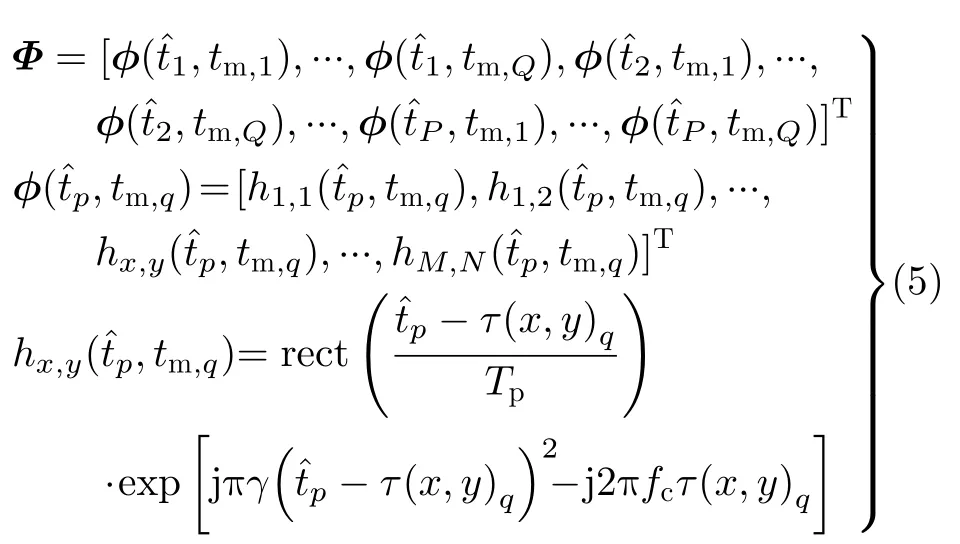
其中,rect()为矩形时间窗,γ为调频率,Tp为发射脉冲宽度,fc为载频,为第p=1,2,···,P个距离向采样对应的快时间,tm,q为第q=1,2,···,Q个方位向采样对应的慢时间,τ(x,y)q表示坐标(x,y)处的场景网格点在慢时间tm,q时刻的回波时延。可以看出,Φ中包含了雷达窗函数、载机到目标斜距、回波相位等信息,当雷达参数无误差,且SAR平台沿已知轨迹做匀速运动时,可以认为Φ是精确已知的。假设噪声为加性白噪声(Additive White Gaussian Noise,AWGN)时,该线性模型就可以通过求解最优化问题得到


图3 1维SAR观测模型示意图Fig.3 One dimensional SAR observation model
本文提出的SAR学习成像网络建立在1维SAR观测模型基础上,将对1维线性模型的求解过程映射到神经网络的一层中,通过多层网络的堆叠和展开实现对场景散射系数的求解。所提成像网络有两方面优势:一是可以将原先固定的成像观测矩阵、正则化参数、迭代步长等模型参数变为可学习的网络参数,通过深度学习中无监督或监督的网络训练方式,让网络自主学习得到不同输入回波数据、不同观测场景下成像质量最优的模型参数,从而实现对线性模型中未知误差的逼近,提升成像方法对SAR数据的普适性和泛化能力;另一方面,所提SAR学习成像网络利用1维线性模型设计网络结构,可以通过迭代优化算法对神经网络结构进行约束,按照迭代优化算法的计算步骤设计网络层级的数学表达式以及权重项、偏置项的具体形式,从而指导神经网络的拓扑结构设计,减少网络可学习参数,降低网络对SAR回波的数据量需求。具体而言,单层神经网络结构可以采用传统神经网络的“权重+偏置”形式,即式(3)的形式,将其重新写为式(7)
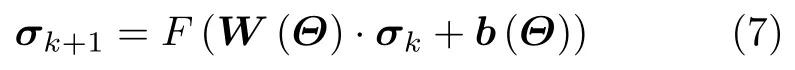
其中,W(Θ),b(Θ)分别为网络的权重和偏置,Θ={Φ,s,λ,···}表示与雷达回波、观测矩阵、正则化参数有关的待学习参数,F()为非线性激活函数。图4给出了本文提出的SAR学习成像网络结构图,其中蓝色方框内均为可学习变量。
该网络结构与深层展开(Deep Unfolding,DU)网络的结构基本一致,即将多层结构相同的单层网络进行堆叠,每一层都可以得到关于散射系数的重构结果。关于深层展开网络,文献[28]中已经证明,每一层网络采用不同的权重系数仅能带来极少的性能提升,但会极大增加网络的训练复杂难度和数据量需求。为了降低参变量数量,减少对样本数据集的完备性需求,所提方法同样令所有层中的权重和偏置相同。F()括号内的具体表达式可以应用任意迭代优化算法实现,如迭代软阈值法(Iterative Soft Thresholding Algorithm,ISTA)、交替方向乘子法(Alternating Direction Method of Multipilers,ADMM)、近似消息传递(Approximate Message Passing,AMP)算法等。以ISTA算法为例,ISTA算法首先计算第k次迭代的残差rk,再通过与正则化参数λ有关的阈值函数F(v;λ)计算第k+1步的预测值
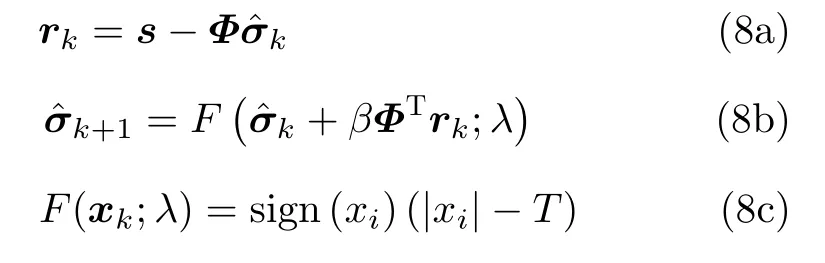
其中β为算法步长,T为迭代阈值。按照ISTA算法步骤,可以将其映射为深度神经网络的单层拓扑结构,即:
(1)算子更新层:对场景散射系数进行更新,实现式8(a),式8(b)的功能。将式8(a)和式8(b)合并,可以转化为
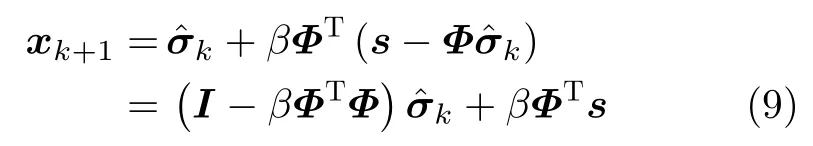
可以看出,式(9)中的W=I −βΦTΦ,b=βΦTs;
本层包含的可学习参数:观测矩阵Φ;算法步长β。
(2)非线性变换层:对网络进行非线性变换,输出下一层的场景散射系数k+1,表达式可以与式8(c)相同,也可以是其他非线性激活函数。
本层包含的可学习参数:非线性函数F,正则化参数λ。
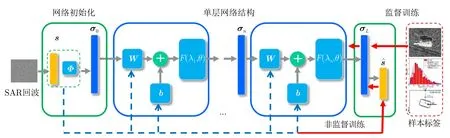
图4 SAR学习成像网络结构图Fig.4 Network structure of SAR learning-imaging
算子更新层和非线性变换层共同构成了SAR成像网络的单层拓扑结构,其中待学习参数为Θ={Φ,λ,β,F}。同样地,其它迭代优化算法如ADMM算法、AMP算法等同样可以表示为不同的网络层级,对应的层级表达式和待学习参数需要根据算法的具体表达式进行改变。
4.2 网络参数选取
在确定了网络中权重和偏置的表达式后,另一个重要的网络参数就是非线性激活函数。目前深度学习中常用的激活函数有sigmoid函数、tanh函数、ReLU函数等,理论上任意满足条件的非线性激活函数都可以作为SAR学习成像的激活函数。考虑到SAR成像场景很可能满足稀疏特性,因此一种可行的方案是使激活函数的输出值尽可能稀疏,例如ISTA算法中的各种软阈值函数,如
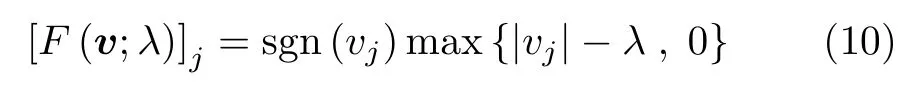
另一种方案是利用类似ReLU函数的分段线性函数。ReLU函数弥补了sigmoid函数以及tanh函数的梯度消失问题,因此得到了广泛的应用。SAR学习成像方法同样可以应用分段线性函数,分段过程中可以在分段点和不同线性区域增加可学习参数,从而使激活函数变为可学习函数。
除了基于现有的神经网络激活函数外,还可以专门设计与回波数据噪声分布和场景先验分布有关的自适应激活函数。文献[28]针对AMP算法设计了一种基于最小均方误差的非线性阈值函数,利用数据本身的先验分布计算该分布条件下的最优非线性函数。但在SAR学习成像中,回波数据与场景的先验分布构造的激活函数能否满足可微性、单调性等激活函数条件还需要展开进一步研究。
4.3 网络训练方法
(1)非监督训练:如图4所示,提出的SAR学习成像网络既可以进行非监督训练,也可以利用已知的SAR目标几何尺寸、形状、统计分布等特征信息进行监督训练。由于SAR成像的场景未知,因此无法直接利用场景散射系数进行误差反向传播。针对这一问题,可以利用网络最后一层得到的场景散射系数估计与观测矩阵Φ相乘,得到SAR回波的估计值,从而与原始SAR回波数据进行对比,实现对模型的非监督训练。在无监督样本数据方面,可以对原始回波数据进行降采样、增加不同信噪比的系统噪声、增加回波相位扰动等方法实现无标记训练样本生成。以增加系统训练噪声为例,对于式(6)中的1维线性SAR成像模型,为数据拟合项,主要反映恢复信号与原始信号之间的拟合程度。该拟合项应用2范数的前提是假设噪声n为加性白噪声。因此,对原始回波数据增加不同输入信噪比的高斯白噪声,能够在不改变稀疏SAR成像模型表达式的前提下获取大量回波数据样本,还能在一定程度上提高成像网络在低信噪比条件下的鲁棒性。另外,还可以在雷达回波相位中增加不同幅度的一次相位扰动和二次相位扰动来实现回波数据的样本生成。该相位扰动模拟的是SAR平台可能出现的运动补偿误差,因此可以提升成像网络相对平台相位误差的鲁棒性。假设样本数据库为S={s1,s2,···,sN},N为样本数量,若采用均方误差代价函数,则代价函数可以写为
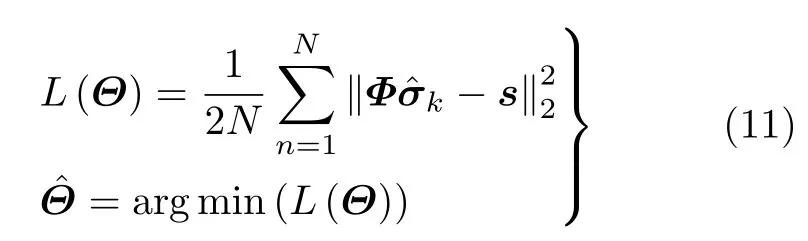
参数初始化方面,设定Φ0为式(5)获得的观测矩阵,,非线性激活函数为式(10)的形式。在进行回波误差反向传播时,为了避免梯度消失,可以设定一个较小的网络学习率η,并随着mini-batch的更新进一步减小。
非监督训练的优势是无需对SAR数据添加任何标记,从而大幅减小了SAR学习成像网络的训练成本。但非监督训练的缺点也很明显,一是对雷达回波的采样率和信噪比有一定要求,当采样率不足或者对回波进行压缩采样时,回波的数据量会大幅减少,从而影响代价函数的准确性;二是忽略了场景中目标的先验信息和已知特征,无法进一步提升对重点目标的成像能力。
(2)监督训练:监督训练的一大难点是成像场景未知,无法直接制作回波中有关场景散射系数的标签数据。但除了散射系数之外,不同SAR场景中的重点目标通常还存在一些共有的可分性特征,这些目标的可分性特征可以用来制作标记,从而提升对重点目标的成像精度。现阶段SAR解译中已经获取了大量重点目标的几何尺寸、形状、统计分布等特征信息,而在SAR成像前,同样可以设法获取一些有关成像场景和场景中可能包含的重点目标的先验信息。对于SAR成像场景,场景的统计分布特征,特定场景的语义特征等都可以作为观测场景的特征标记。SAR图像根据分辨率和场景内容可以服从G0分布、广义Gamma分布等分布形式,将场景的统计分布函数作为标记,构造基于统计分布函数的目标函数,令SAR成像网络输出的SAR图像满足该分辨率条件下的特定统计分布,能够进一步约束成像网络的待学习参数范围,提升网络训练速度。而SAR场景的语义特征同样可以作为成像场景的特征标记,来约束成像网络输出图像的幅值,将其对应到场景内的特定语义类别中,从而分离目标区域与背景区域,为后续SAR图像解译提供便利。假设χ(Θ,σ):Hσ →HD表示成像场景σ与目标可分性特征D={d1,d2,···,dk}之间的映射,k为特征数量,那么监督训练的代价函数可以写为
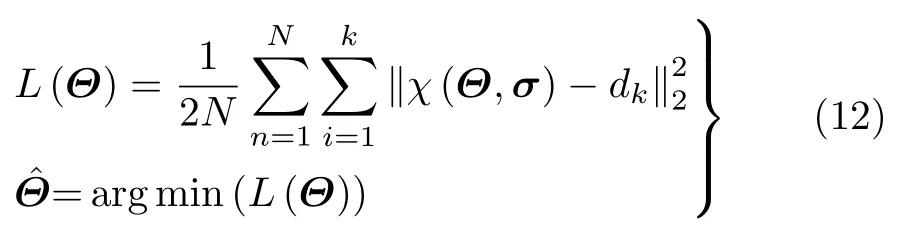
监督学习方法的优势是能够使散射系数估计值中包含已知的特征信息,从而更有利于下一步的SAR目标特征提取。缺点则是学习成本的大幅提升,另外,特征标记有可能与场景中的目标特征存在失配,导致对散射系数的估计出现误差。
需要注意的是,由于SAR回波信号是复数信号,因此为了保留相位信息,在对式(11),式(12)中的网络可学习参数进行调优时,必须利用复数进行反向传播。目前,一些基于复数的反向传播算法已经在神经网络中得到应用,例如基于Wirtinger导数的反向传播算法,可以作为SAR学习成像的网络训练方法。
5 仿真实验和分析
本节通过实验验证提出的基于“数据驱动+智能学习”的SAR学习成像方法的可行性和有效性。为了便于生成样本回波数据,以及测试不同噪声环境以及不同轨迹误差对成像性能的影响,本节采用仿真数据进行非监督训练成像实验验证。
5.1 噪声环境下点目标成像实验
首先测试噪声环境下所提方法对点目标的成像性能。将成像场景离散化为30×30的网格,场景内包含5个散射系数各不相同的散射点。表1给出了对应的仿真雷达参数和网络参数。网络结构方面,按照式(9)设计单层网络的权重项和偏置项,按照式(10)设计非线性激活函数。网络参数方面,按照式(5)初始化观测矩阵Φ0,设定场景散射系数的初值。λ0=0.5,β0=0.5。为了测试所提SAR学习成像网络在数据缺损条件下的成像能力,设定回波数据的随机降采样率为γ,定义为雷达实际采样点数与按奈奎斯特采样率采样的点数的比值。网络训练方面,通过在回波数据中增加随机加性噪声的方式构建回波数据训练样本集,设定输入信噪比为20 dB,同样对训练样本进行降采样,采样率设定为γ。样本集数量Ntrain=1000,回波数据中的场景同样为点目标场景。为了减小梯度消失问题对训练算法的影响,选取一个较小的网络学习率η=10-6。实际成像时,直接将训练得到的成像观测矩阵、正则化参数、迭代步长等参数输入成像网络,经过网络前向传播后输出成像结果。设定测试回波的输入信噪比为20 dB,数据量Ntest=30,成像质量参数取30次的平均值。选取stOMP算法以及基于l1/2范数的ISTA算法作为对比算法,这两种方法均属于盲稀疏算法,在SAR稀疏成像中有成熟的应用。
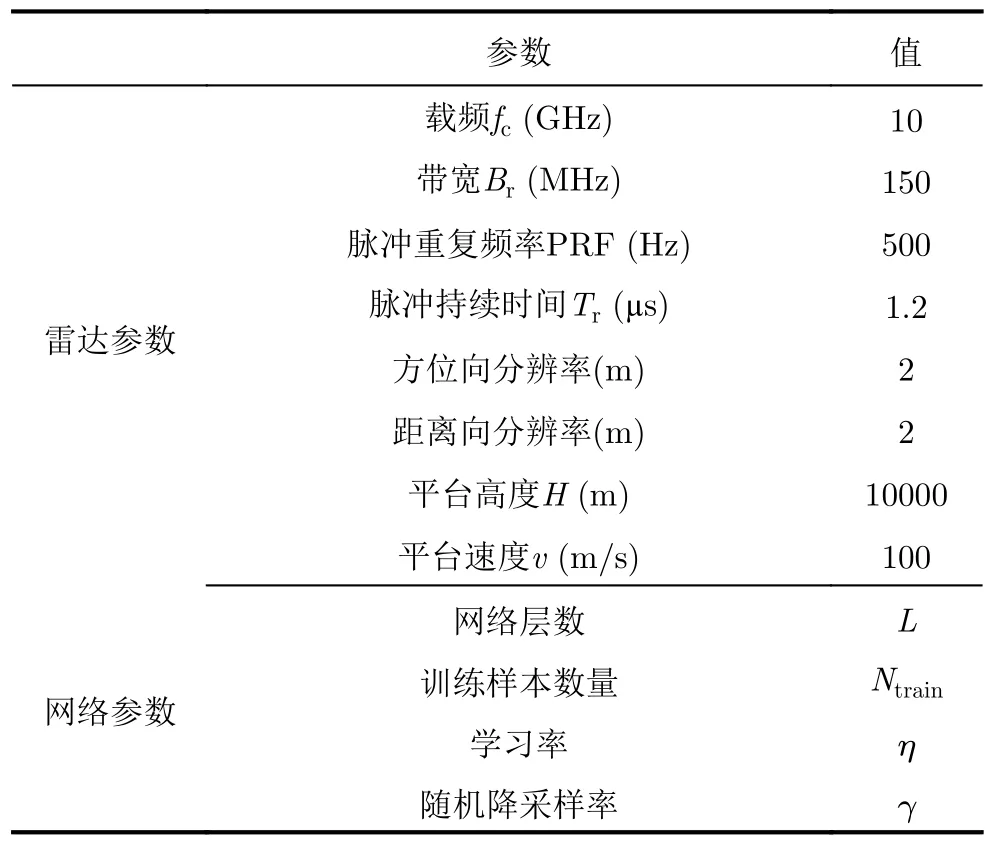
表1 雷达参数和网络参数Tab.1 Parameters of radar and network
下面给出非监督训练的成像结果对比。由于非监督训练需要与原始SAR回波数据进行对比,因此首先令γ=1,即数据无缺损条件下进行成像。设定训练阶段的样本数据量Ntrain=1000,图5给出了20 dB信噪比、不同网络层数L对应的成像结果对比图。
由图5可以看出,当γ=1,即在全采样条件下,所有方法均能正确重构出点目标的坐标位置和散射系数。所提方法当网络层数L=3时,点目标周围的旁瓣较高,当L=8时,可以明显看出旁瓣得到了抑制,而当L=11时成像结果与L=8时基本相同。进一步增大噪声能量,并对回波数据进行随机降采样来验证算法性能。图6给出了5 dB信噪比,降采样率γ=0.1时的成像结果对比图。
可以看出,在仅含有10%回波数据量且背景噪声较大的条件下,所有方法的成像质量都有所下降。对于所提方法,由于非监督训练的代价函数是利用估计的回波数据与原始回波数据进行对比,因此当原始数据大量丢失并被噪声严重污染时,非监督训练方法的成像质量无法得到进一步提升。表2给出了成像质量(峰值信噪比PSNR、均方误差NMSE值、峰值旁瓣比PLSR)与成像时间的对比结果,实验设定测试数据量Ntest=100次取平均值。所有实验在一台工作站(Intel i7 9700K,16 GB RAM)上完成,所提SAR学习成像网络利用Python Tensor-Flow编程实现,并利用1块英伟达GeForce RTX 2080 Ti显卡进行GPU加速。
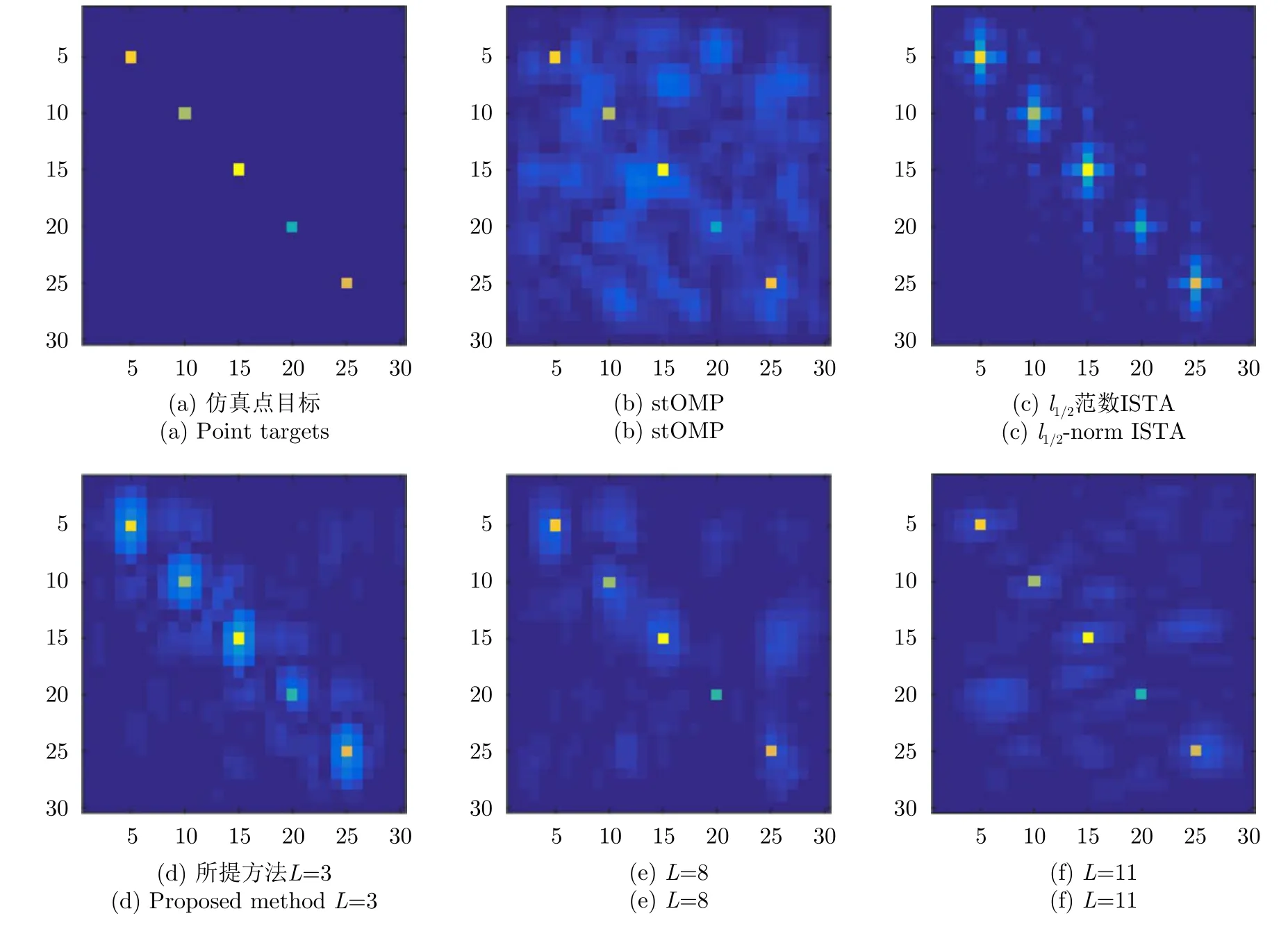
图5 非监督训练、γ=1,20 dB信噪比条件下成像结果对比Fig.5 Comparison of imaging results using unsupervised training,γ=1 and SNR=20 dB
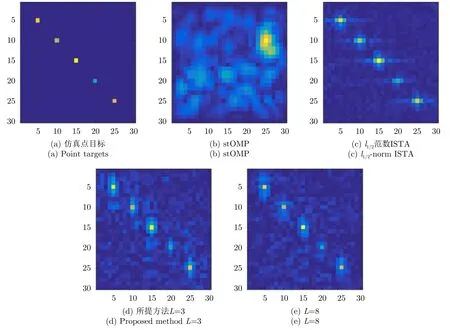
图6 非监督训练、γ=0.1,5 dB信噪比条件下成像结果对比Fig.6 Comparison of imaging results using unsupervised training,γ=0.1 and SNR=5 dB
表2给出的实验结果与图5,图6中的视觉结果基本一致,所提方法在非监督训练情况下,利用个位数的网络层数取得了优于现有主流迭代优化算法上千次迭代的成像结果。相比传统稀疏优化算法的迭代寻优,网络的后向传播算法是从第一层到最后一层进行全局优化,相当于应用了迭代优化算法迭代前后的所有信息,因此SAR学习成像网络的拟合能力更强,能够利用较少的层数达到现有迭代优化算法上千次迭代的效果。成像速度方面,SAR学习成像网络在训练好网络参数后,成像过程只需要一次前馈运算,且网络层数较少,因此成像速度极快。对于实验中的小场景SAR成像问题,成像速度在毫秒级,明显快于迭代优化算法。
另外,试验还仿真了低PRF情况下所提方法的成像结果。低PRF可以看作一种回波降采样方式,但现有稀疏SAR成像方法在降采样过程中需要遵循一定的规则以满足重构条件。低PRF情况下获取的观测矩阵可能并不满足条件,从而导致稀疏SAR成像方法重构质量下降。图7给出了PRF小于方位向多普勒带宽时不同方法的成像结果对比。可以看出基于匹配滤波的RD算法和稀疏SAR成像算法均不同程度的出现了方位向模糊,产生了假目标,而所提方法仍然具有较好的成像质量。
为了对比不同样本数据量对网络训练的影响,图8给出了20 dB信噪比情况下,3种不同样本数据量对应的训练重构误差结果。可以看出,在4.1节中构建的网络结构能够成功实现对样本回波数据的拟合,网络在训练到50次左右时收敛,此后重构误差将随着训练次数的增多而逐步增大,且训练样本越少增加的越快。通过3条不同样本数据量的重构误差曲线可以看出,当样本数据量增大到一定程度后,网络的重构误差将趋于稳定,这也说明了所提的成像网络能够在一定程度上减小深度学习对样本数据的需求。若想要进一步提升重构质量,则需要改变网络结构或者代价函数的形式。
5.2 含轨迹误差目标成像试验
下面通过点目标仿真来验证含平台轨迹误差时SAR学习成像网络的成像能力。在SAR回波样本数据中加入时变的、最大0.15 m的轨迹误差,设定Ntrain=500,系统输入信噪比为20 dB。图9给出了不同算法的成像效果对比。可以看出,在含轨迹误差的情况下,传统迭代优化算法在方位向出现了较大程度的模糊和散焦。所提成像网络的输出图像同样出现了散焦和模糊,但实现了对主散射点位置和散射系数的重构,相比stOMP和l1/2范数ISTA算法重构精度更高。
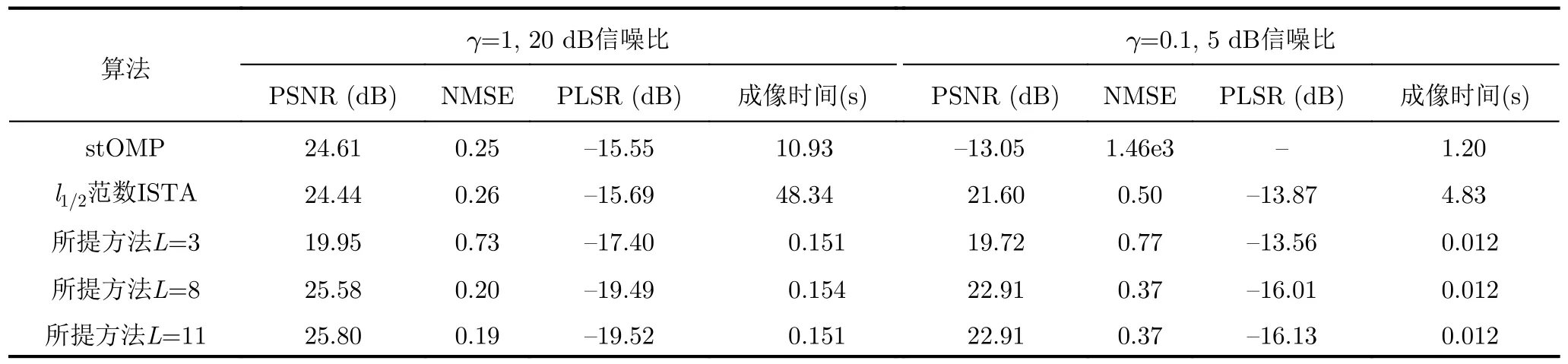
表2 成像质量与成像时间对比Tab.2 Comparison of imaging quality and imaging time
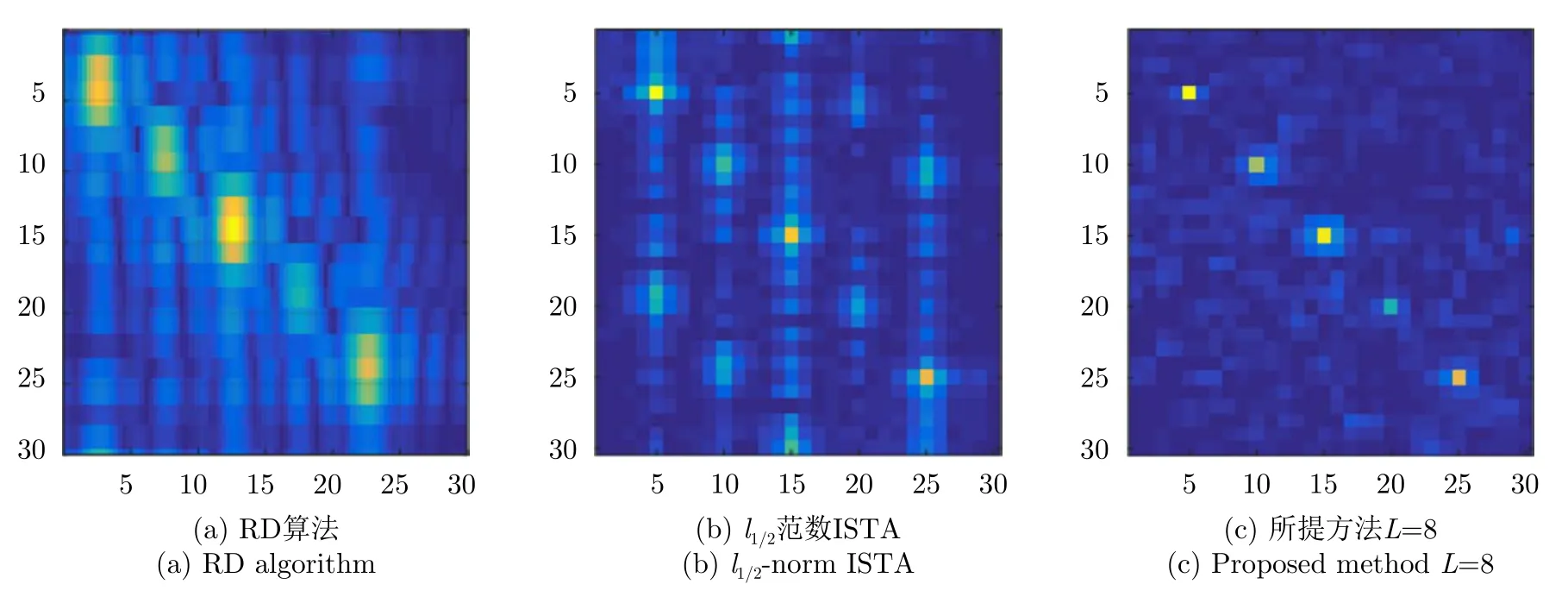
图7 低PRF条件下成像结果对比Fig.7 Imaging results under low PRF condition
5.3 稀疏场景面目标成像试验
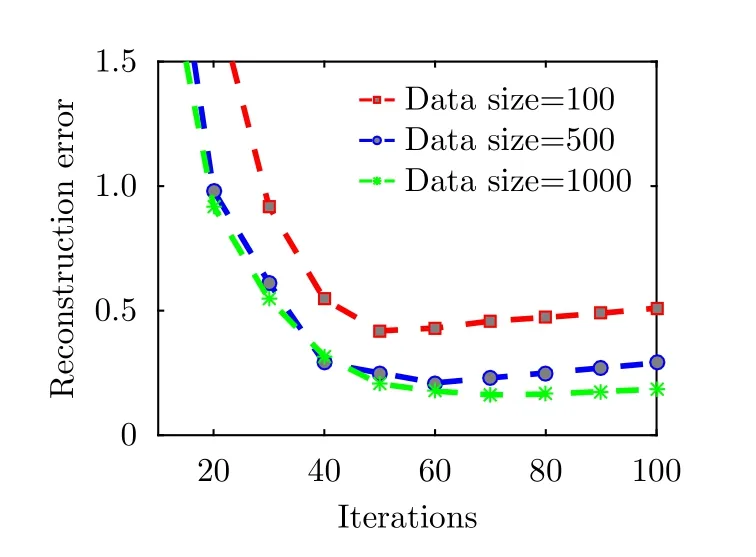
图8 不同样本数据量对应的网络训练误差Fig.8 Network training error corresponding to different number of training samples
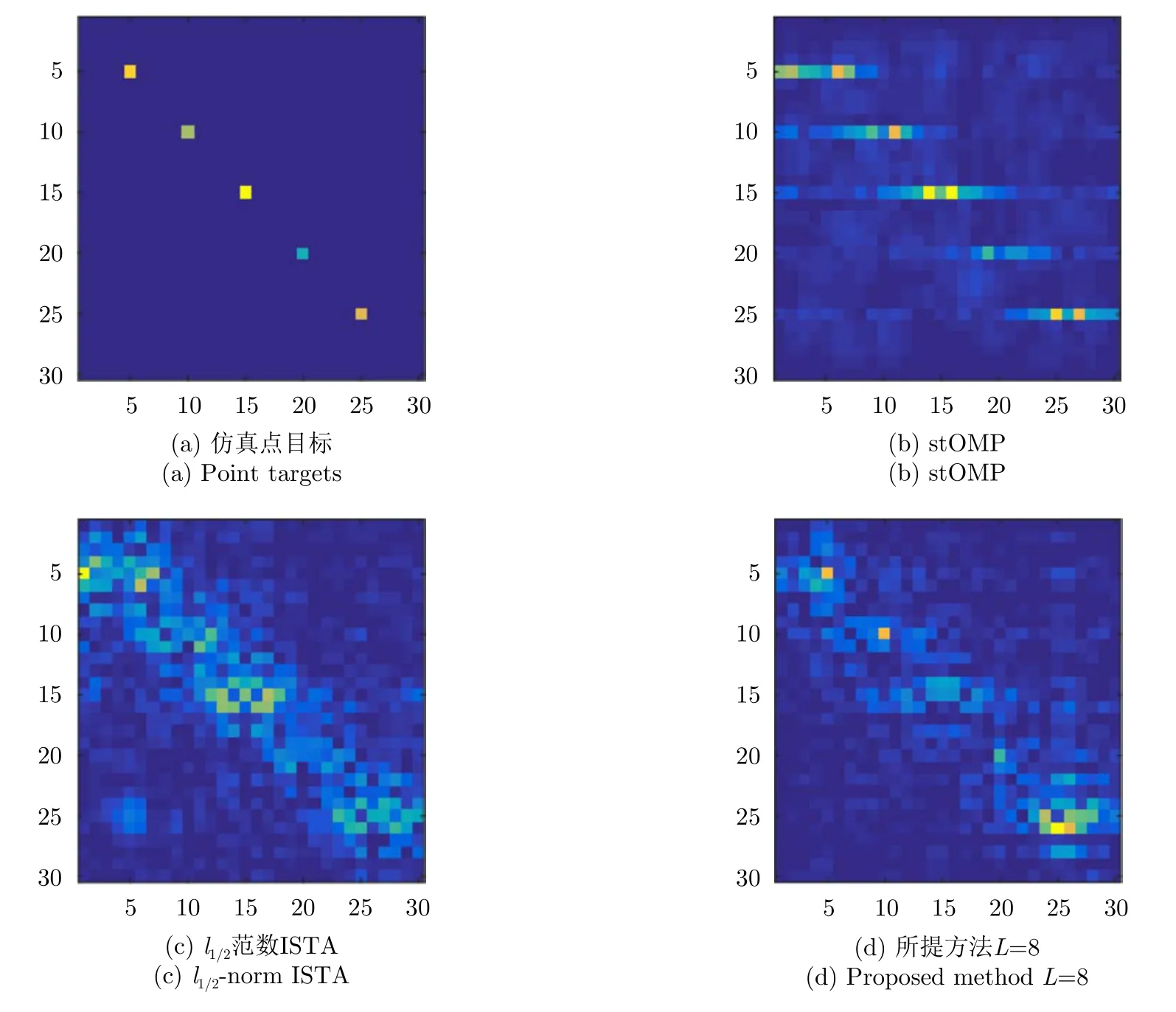
图9 含载机轨迹误差条件下成像结果对比Fig.9 Imaging results with platform trajectory error
下面进一步利用包含感兴趣目标的稀疏观测场景进行成像实验。观测场景采用MSTAR数据集中的车辆目标进行仿真验证。对于MSTAR数据,设定仿真回波数据的成像场景与雷达的位置关系与前述单点目标仿真实验一致,回波数据的相位信息可以通过对复图像数据做2D-DFT得到。为了测试所提SAR学习成像网络的性能,在回波中增加高斯白噪声使得输入信噪比为10 dB。实验采用固定参数的l1/2范数的ISTA算法作为对比算法,由于正则化参数λ需要手工设定,图10(b)-图10(d)分别给出了l1/2范数的ISTA算法在λ=0.5,10,100条件下的一幅2s1车辆目标成像结果。可以看出,对于传统稀疏SAR成像方法,当存在噪声时,成像质量有所下降,且手工设定参数将很大程度上决定最终的成像结果。对于所提方法,设定场景散射系数的初值,λ0=0.5,β0=0.5,初始网络学习率η=10-6,并随着mini-batch的更新逐渐减小。对回波添加高斯白噪声构建训练样本数据,令Ntrain=500,图10(e),图10(f)给出了8层网络和11层网络的成像效果对比。可以看出,在10 dB输入信噪比条件下,所提成像网络得到的SAR图像重构精度更高,且目标区域保留更好,背景也进一步得到抑制,其中网络自主学习得到图10(e)中的λ=37,图10(f)中的λ=63。图11给出了另外两幅车辆目标的成像结果,利用所提成像网络同样得到了较好的成像结果。

图10 MSTAR目标成像结果对比Fig.10 MSTAR target imaging results

图11 MSTAR其它两种目标成像结果对比Fig.11 Imaging results of two different targets in MSTAR dataset
6 结束语
现阶段SAR在分辨率、幅宽等成像方面的提升并未从本质上解决SAR图像解译困难、重点目标识别率低的问题,而SAR成像与SAR解译研究之间的相对独立是导致这一问题的重要原因之一。若能实现SAR成像与SAR解译之间的一体化处理,必将极大地提升SAR系统的整体数据处理能力和处理时效性。本文从SAR成像解译一体化角度出发,尝试利用“数据驱动+智能学习”的方法提升机载SAR对重点目标的参数获取和属性判别能力,分析表明,在现有条件下,直接利用海量数据学习得到“回波数据域”到“目标参数域”的映射关系还存在很大难度,但若能构造出成像网络来实现“回波数据域”到“目标图像域”的映射,再结合已有的SAR解译网络,将有望实现SAR成像解译一体化。因此,本文提出了一种“数据驱动+智能学习”的SAR学习成像方法,给出了学习成像框架、网络参数选取方法、网络训练方法和初步的仿真结果。然而,本文所提出的方法和开展的实验仅仅考虑了非常简单的成像场景,还存在大量关键技术需要予以研究。
(1)SAR观测模型问题:本文提出的SAR学习成像框架基于SAR 1维观测模型,SAR 1维观测模型的优势是符合现有线性求逆模型的矩阵-向量相乘形式,因此可以利用现有迭代优化算法推算得到网络的权重项和偏置项,从而直接设计单层网络结构,并利用现有反向传播算法对成像网络进行训练。但1维观测模型的向量化处理导致观测矩阵的维度急剧变大,当SAR成像幅宽大、分辨率高时将极大的占用计算机内存资源。因此,有必要构建基于SAR 2维观测模型的SAR学习成像方法,直接利用网络找寻从距离向-方位向耦合的回波矩阵到2维SAR图像的映射关系。针对这一问题,还需要进一步研究具体的学习成像网络结构、对应的权重项和偏置项表达式以及最重要的反向传播算法的设计问题。
(2)网络结构问题:为了方便进行误差反向传播和参数调优,所提方法采用典型神经网络的“权重+偏置”形式,并采用多层结构相同的单层网络进行堆叠实现。这种网络结构的优势是可学习参数较少,网络的训练和参数调整较为简单,但缺点是非线性拟合能力有限。因此,如何设计非线性拟合能力更强的单层学习成像网络结构,并约束可学习参数的数量和变化范围,是待解决的关键问题之一。
(3)网络训练问题:在网络训练方面,非监督训练和监督训练都有各自的优势,当SAR回波数据完好,噪声较小时,非监督训练可以达到较好的效果。但点目标仿真数据与实测SAR数据还存在一定偏差,真实条件下SAR回波数据量非常庞大,网络训练面临占用内存高、速度慢以及梯度消失问题。虽然可以对回波进行降采样从而减小数据量,但降采样率过高同样会影响成像质量,能否在数据降采样和重构精度之间找到平衡,如何加快非监督训练的速度都是值得研究的课题。在监督训练方面,由于点目标无法反映成像场景的几何特性、分布特性等先验信息,因此仿真实验中并未给出监督训练的试验结果。如何选取和设计监督训练中可添加的目标先验特征,有哪些先验特征能够更好地约束SAR学习成像网络,这些问题都值得进一步研究。
(4)动目标成像问题:与静止场景成像不同,动目标成像中的目标运动轨迹、运动参数未知。因此在成像过程中必须对目标速度进行有效估计,由于目标运动导致观测矩阵中参数发生很大变化,因此依靠本文提出的网络结构对观测矩阵进行学习优化存在欠拟合的问题,无法实现动目标精确成像。因此还需要专门设计针对动目标成像的SAR学习成像网络。一种可行的解决方案是在成像观测矩阵中增加基于目标运动速度的可学习参数,通过设计网络训练算法,在反向传播过程中不断优化该参数,实现对目标真实速度的逼近。
(5)成像网络与解译网络的级联问题:为了实现基于“数据驱动+智能学习”的SAR成像解译一体化,需要将成像网络和解译网络级联到一起。在级联过程中,一种较为简单的方法就是直接将训练好的成像网络和训练好的解译网络串联起来,成像网络输出SAR图像,然后裁切为尺寸较小的切片作为解译网络的输入,最终由解译网络输出目标参数。除此之外,还可以进一步考虑解译网络对输入SAR图像的预处理要求以及对目标的特征提取需求。例如感兴趣目标往往包含直线、圆、矩形等人造结构,这些人造结构特征是解译网络需要重点提取的区别目标与背景的重要特征。如果已知这些特征提取需求,就可以指导成像网络得到包含特定目标特征的SAR图像,从而突出目标,弱化背景,进一步提升后续解译网络的目标分类性能。
