基于深度学习的场景识别方法综述
2020-03-11李新叶麻丽娜
李新叶,朱 婧,麻丽娜
1.华北电力大学 电子与通信工程系,河北 保定071003
2.华北电力大学 科技学院,河北 保定071003
1 引言
场景识别是计算机视觉领域的基础任务之一,近年来得到了广泛关注。因其在图像检索、人机交互、自动驾驶、视觉监控等多项应用中发挥关键作用,帮助人们理解图像,因而在计算机视觉领域扮演着重要的角色,越来越多的工作[1-3]对其进行了研究。
现有的综述[4-5]主要对基于手工特征的传统场景识别法进行研究,而手工特征在表达图像语义方面能力有限,因此传统场景识别法识别精度比较低。文献[6]仅对早期(2016 年之前)少数基于深度学习的场景识别法进行了简单介绍,这些方法虽然较传统方法有所提高,但识别准确率仍不高。
近年来,随着深度学习技术的发展,越来越多的研究工作开始利用深度学习方法解决场景识别任务,并取得了显著的效果,与之前的研究相比,识别率有了明显提升。本文对近年来基于深度学习的场景识别方法进行分析和比较,对各种方法的优劣进行总结,为未来的场景识别研究提供帮助。
2 场景识别问题
场景识别,即根据场景图像中包含的内容为场景图像分配语义标签。与目标识别不同,场景识别任务更为复杂,不仅要考虑目标、背景、空间布局等信息,对图像中存在的各种依赖关系进行挖掘也十分重要。因此,场景识别仍然是一项非常具有挑战性的任务。另外,场景识别还面临着许多其他的问题,例如:场景图像类内变化大,类间相似度高;数据分布不均衡等,这些问题又一定程度上增加了场景识别的难度。
早期的场景识别任务主要研究利用各种底层特征表示图像,例如,SIFT[7]、GIST[8]、HOG[9]、CENTRIST[10]等,操作简单但语义表达能力有限。OB(Object Bank)[11]、词袋模型(Bag-of-Words)[12]等基于语义的识别方法缩小了特征与语义之间的鸿沟,但是想要实现识别性能的进一步提升非常困难。自AlexNet[13]开始,随着卷积神经网络(Convolutional Neural Networks,CNN)的快速发展,人们开始利用深度学习方法进行场景识别。利用深度学习方法进行场景识别有以下优势:首先,CNN可以从输入图像中自动提取包含更多语义和结构信息的特征,且经过网络结构中的非线性变换后变得更具有判别力;其次,有研究[14]说明深度层次结构能更好解释场景中的空间分布。
3 基于深度学习的场景识别方法分类
在对近年来基于深度学习的场景识别方法进行总结后,本文将它们大体分为以下四类:深度学习与视觉词袋结合场景识别法、基于显著部分的场景识别法、多层特征融合场景识别法、融合知识表示的场景识别法。
3.1 深度学习与视觉词袋结合场景识别法
词袋模型基于文本处理的思想,把图像看作视觉词汇的无序集合,对由图像得到的图像块进行特征提取并聚类,构建视觉码本表示图像,在一些研究[15]中取得了不错的效果。利用深度特征代替传统词袋模型中的手工特征是提高识别精度最直接的方法,该类方法的基本流程如图1所示。
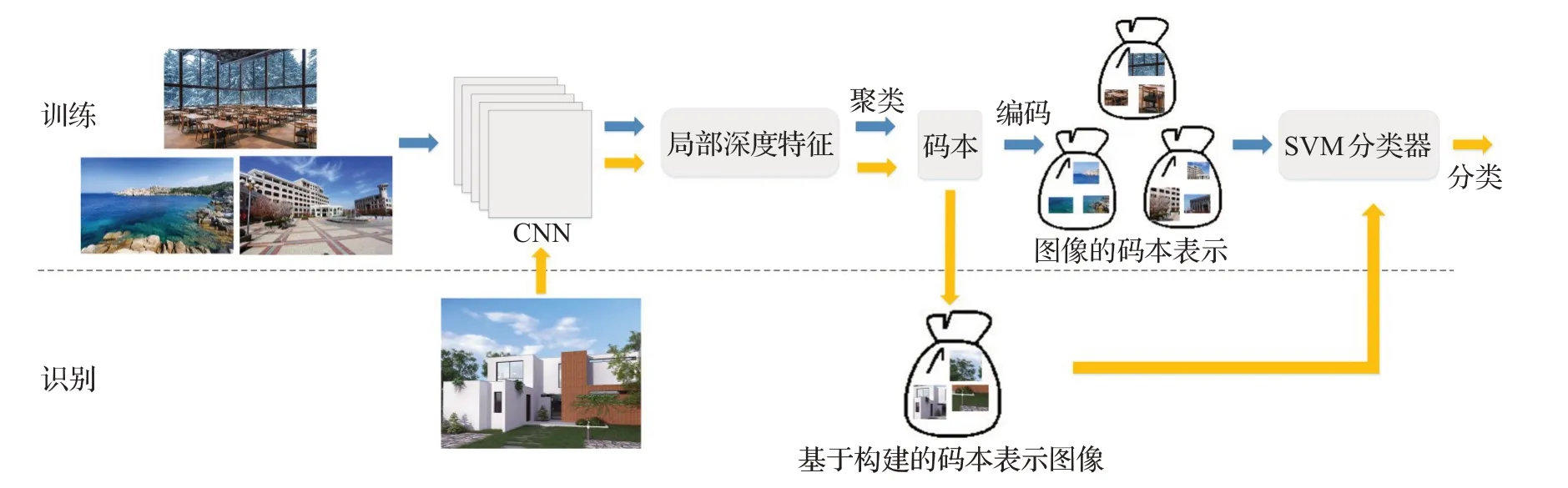
图1 基于深度特征的视觉词袋模型场景识别法
许多工作以此为基础,将深度学习与传统视觉词袋模型进行了结合。文献[16]在ImageNet 和Places 以及两者混合的数据集上对CNN 模型进行预训练,提取图像块特征,并对应生成三种码本表示图像,涵盖了目标属性及场景属性。由训练混合数据集提取的特征中同时包含了这两种信息,因此可针对不同的场景分类任务自适应地提取共享码本特征,与原始码本特征结合,为场景识别提供更全面的图像表示。这种方法避免了额外的码本训练,提高了识别效率,但根据具体任务自适应选择子码本的算法有待于进一步改进。文献[17]将CNN全连接层特征FCR与中层局部表示MLR(Mid-level Local Representation)、卷积Fisher 向量CFV(Convolutional Fisher Vector)两种字典表示结合描述图像。其中,FCR提供了全局信息;MLR通过聚类生成了类间通用的字典和特定于某一类的字典对多尺度图像输入进行操作,生成中层表示,挖掘局部信息;CFV 基于CNN最后一个卷积层,采用多尺度比例高斯混合模型训练策略生成Fisher矢量,增强了识别性能。该图像表示由三部分组成,CNN 模型与另外两种字典表示并没有在一个统一的框架下进行联合训练,同时,不可避免的,该方案具有一定的参数复杂性和时间复杂性。文献[18]提出了一种弱监督网络结构PatchNet,该结构设计采用了VGGNet16[19],以图像块为输入,场景标签为输出,分别在ImageNet 和Places 上进行训练得到object-PatchNet和scene-PatchNet两种模型,并由object-PatchNet提取的局部特征构建码本。识别过程中,scene-PatchNet 提取深度特征描述图像块,object-PatchNet 输出的语义类别概率分布代替了传统FV 编码中的高斯混合模型,作为后验概率对图像块进行整合,构成了一种新的编码机制
VSAD(Vector of Semantically Aggregated Descriptors),基于构建的码本表示图像。
主题模型即在词袋模型中引入主题元素,对视觉词汇进行二次抽象,是词袋模型的一种扩展。文献[20]提出了一种局部类共享主题潜在狄利克雷分布来学习特定于类或类之间共享的主题,但该方法没有考虑场景内主题之间的相关性。考虑到这一点,文献[21]利用相关主题模型CTM(Correlated Topic Model)构建了相关主题矢量表示,CTM 中的逻辑正态分布包含了主题之间的协方差计算,挖掘了主题之间的相关性。
相对于传统词袋模型而言,利用深度特征构建码本直接提高了场景识别精度,另外针对词袋模型中固有的图像表示方式缺乏空间信息的问题,CNN 可以自动提取空间特征,对这一问题进行弥补。词袋模型简单易用,但仍有其自身的局限性:码本的构建过程需要根据要解决的具体任务进行考量,不合适的码本会在一定程度上对识别效果造成影响;结合了深度特征的视觉词袋场景识别法仍然需要对大量的图像块特征进行聚类处理,这在计算上造成了一定的负担。
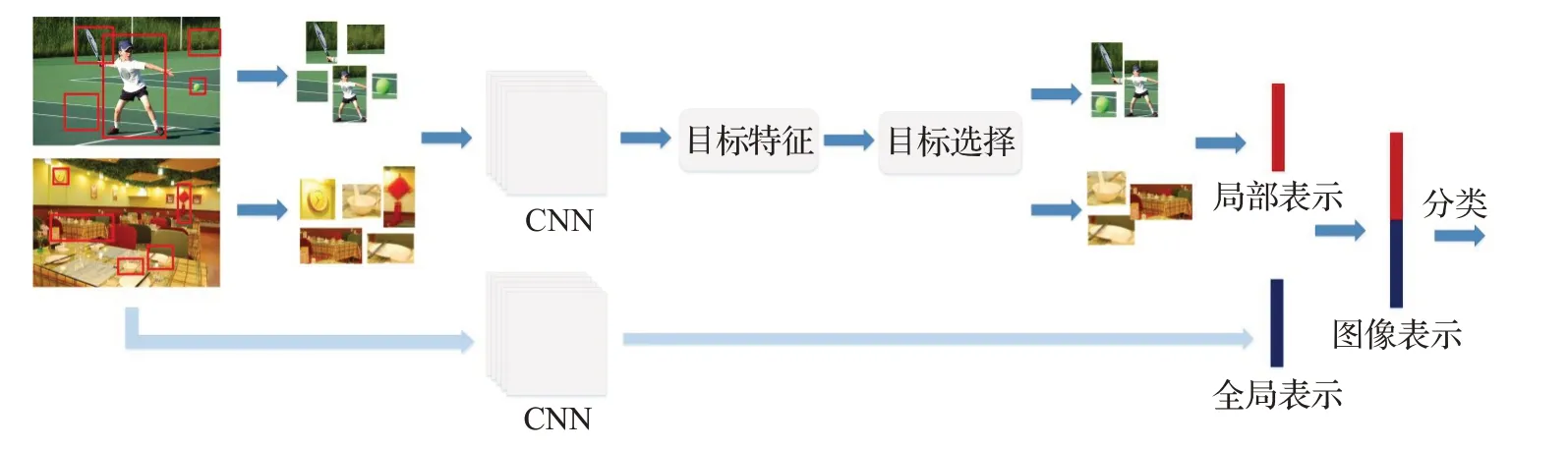
图2 基于显著目标的场景识别法基本流程
3.2 基于显著部分的场景识别法
人眼往往可以只根据图像中最具代表性的部分判断场景的类别,这一特性也激发了计算机视觉中利用显著部分(显著目标、显著区域及显著形状)提高识别准确率的灵感。
一些研究[22-23]发现用于场景识别的CNN 可以定位出图像中能提供有用信息的目标,即图像中的显著目标对于提高识别精度作用更大,这类方法的基本流程如图2 所示。文献[24]中对于检测到的每个目标,都有一个计数比率来表示目标和场景类别之间的关联强度,计数比率高的目标在决定场景类别时贡献更大。文献[25]利用选择搜索算法提取目标块并用CNN 模型提取特征后,为了选择能代表场景类别的目标块,针对每一类图像特征进行光谱聚类并对每一簇训练一个二分类SVM,在测试阶段将用训练好的SVM 来选择有代表性的特征。文献[26]提出了一种特征描述SDO(Semantic Descriptor with Objectness),将图像块送入CNN,由输出向量计算目标多项式分布,使用贝叶斯法则计算后验概率,利用目标的共现模式在场景中选择有判别力的目标对图像块进行筛选,并进一步对Softmax输出向量进行降维。文献[25-26]中采用的方案与基于词袋模型的场景识别法面临相同的问题,即都需要对大量的图像块进行聚类和筛选操作,这对计算资源提出了挑战。为了解决类似的问题,在计算时间和存储空间上进行优化,文献[27]提出显著目标共享的策略,对不同场景中的目标模式进行学习并将一些显著目标进行共享,实验证明平均只需要四个关键目标就足够对某一场景类别图像进行表示。该方法有效提高了识别效率,数据集很大时效果更为明显。上述基于目标块的识别方法中首先实现了对大量图像块的显著程度度量,对目标进行选择的操作有效提高了场景图像表示的判别性,增大了不同类别场景之间的可区分度。但是这些方法并没有考虑不同场景的特殊属性,即复杂场景与简单场景的显著目标数量可能不同(例如室内场景相对于自然场景而言场景构成更复杂,显著目标数量也更多),相对固定的显著目标数量可能会在一些简单场景中引入噪声。从这一出发点进行考量,文献[28]提出了一种自适应识别判别性目标块的方法Adi-Red,通过计算最后一个卷积层的所有激活映射的加权和得到判别映射图,使用滑动窗口搜索映射图的局部极大值,对高于设定阈值的部分进行目标选择,使得显著目标块的数量可以自适应地变化,既不引入噪声又不丢失重要信息。另外,该方法直接利用CNN 分类器提取目标块信息,无需经过目标检测等操作,有效解决了传统基于显著目标的场景识别法计算量大的问题。文献[29]为场景图像分配软标签作为目标分布表示,与多分辨率CNN 框架结合进行场景识别。在基于显著目标的场景识别方法中,将局部目标特征作为场景全局特征的补充有效提高了场景识别的准确率,但也存在一些局限性。首先,目标检测的准确度将会影响场景识别准确度,一旦目标识别有误将造成场景识别率下降的连锁后果;第二,在这类方法中,尽管利用了目标共现等手段对目标显著度进行度量,但这仍是一种orderless 式的特征聚合,没有考虑目标间的关系也是一种具有强判别性的因素,缺乏对场景基于目标的结构化表示的研究。
文献[30]根据一幅图像中目标框的分布计算出场景中每个位置的目标密度,提取目标密度最高的一个区域作为显著区域,利用几种尺度下显著区域的融合特征表示图像进行场景识别。该方法并未用到整幅图像的全局特征,可能会造成信息丢失;另外,场景具有相对不受控制的结构,关键的辨别性识别线索可能分布在不同区域,只利用目标最集中的区域作为显著部分缺乏说服力。
此外,轮廓作为一种显著形状也被应用到场景识别任务中。文献[31]指出,人类可以从由轮廓构成的线条图准确地分辨场景类别,并依此提出了一种基于中轴的轮廓显著性测量方法,进行局部分离、带状对称和锥度的轮廓显著性测量,选择能提供更多信息的轮廓像素子集送入CNN中进行场景识别。实验证明单独利用线条图进行场景识别效果并不好,轮廓信息只能作为场景图像的一种补充。
基于显著部分的场景识别法中,最关键的部分在于如何得到更稳健的补充信息(目标特征、区域特征、形状特征等),补充性特征提取有误将影响最终的识别效果。
3.3 多层特征融合场景识别法
CNN 模型的每一层结构都能学习到不同的特征,层次越深学到的特征越抽象也越具有判别力,将CNN多层特征进行融合是一种常见的提高识别精度的方法。
文献[32]用在Places 上预训练的CNN 模型提取场景图像特征,连接最后两个全连接层的输出作为图像表示,另外为了解决该操作造成的特征冗余,对特征进行了选择。与文献[32]相同,文献[33]同样连接最后两个全连接层的输出表示图像。以上两种方法都集中在利用更为抽象的全连接层特征进行图像表示,忽视了卷积层中丰富的局部信息。
对于场景识别任务而言,需要从场景布局及细节信息两方面进行考虑。利用场景布局信息可以轻易对一些场景进行区分(例如沙滩与教室的布局明显不同);但在一些相似的场景类别中(例如餐厅与咖啡厅),细小的差异决定了最终的识别结果。全连接层特征对于区分以布局为主导的场景图像效果较好,在细节处理上,卷积层特征往往能提供更多具体的信息。文献[34]提出了一种局部卷积监督层(LCS),通过绕过CNN 中的一个卷积层并直接连接到最终损失函数来增强局部卷积特性,并用Fisher 卷积矢量(Fisher Convolutional Vector,FCV)对局部信息进行编码,与全连接层特征相结合构成LS-DHM 表示。文献[35]提出了一种基于GoogleNet 的多级模型G-MS2F,针对GoogleNet的网络结构,根据辅助损失函数的位置分为三部分并得到对应卷积特征进行融合。GoogleNet本身在增加网络深度和宽度的同时就对参数和计算量进行了控制,以此为结构基础的G-MS2F 模型在训练阶段的模型复杂度并没有增加,测试时由于要对三个阶段的特征进行单独提取,因此该模型会具有一定的时间复杂度。文献[36]提出了一个两阶段的深度特征融合识别法,首先,对预训练的CaffeNet 和VGG-VD-16 进行操作,将卷积层和全连接层的信息进行整合,在每一个池化层后插入一个分支CNN,分支CNN包括三部分:1×1卷积层、非线性激活函数ReLU 和全局平均池化层;其次,对操作完成的两个CNN 进行线性结合,生成一个复合CNN,提高识别性能。文献[37]以在ImageNet上训练的18层ResNet为迁移学习模型基础,在残差块之间提取多个特征并进行融合,融合向量直接与K 维输出层相连。该方法得到的结果受数据增强操作影响较大。文献[38]将特征图经可视化后发现,如果场景的关键目标太小,其特征会随着网络层数的加深而变得不明显或消失,但在较低层却比较完整,基于此现象,提出了一种多层集成网络来提高关键目标比较小的场景的识别率,在多个低层后增加分类器,利用多个低层特征进行单独预测,在网络中进行集成学习后做最终预测。增加分类器会影响深层网络进一步利用低层特征,因此设计了一条特征迁移路径,使得低层特征也能跨过分类器直接送入深层。深层特征作为低层特征的补充,与其融合,确保低层特征可用来预测复杂场景。文献[39]针对传统的语义流形法在场景识别任务中的一些限制,提出了一种基于多尺度CNN 构建语义流形的混合体系结构,对多个特征进行融合。
在基于多层特征融合的场景识别法中,关键在于如何根据不同CNN 模型(例如VGGNet、GoogleNet、ResNet 等)的结构特点来提取多层特征,特别要注意模型的参数复杂度和计算复杂度。
3.4 融合知识表示的场景识别法
随着深度学习的快速发展,计算机视觉领域中各种视觉处理任务的效果都得到了巨大的提升,为了取得进一步的突破,许多研究工作开始从人类视觉特性角度出发,结合额外的知识表示进行图像处理。场景图像中包含着丰富的知识信息,将这些知识融入到场景识别中将有效提高识别精度。
文献[40]除了融合了保留空间布局的目标语义特征(SOSF)和全局外观特征(GAF)外,还加入了外观上下文特征(CFA),提出了一种结合CNN层和LSTM层的混合深度神经网络结构。在CNN中将两个不同中间卷积层输出分别送入两组多向LSTM层,并将LSTM的输出连接起来得到CFA。其作为目标语义和全局特征的补充,提供了场景图像多向上下文信息,保留了图像的空间布局。
现有的仅依靠目标特征及目标共现模式进行场景识别的方法能取得不错的效果,但也无法消除场景标签歧义的问题,不同的场景类别可能具有相似的目标共现模式,因此必须加入更具有判别力的信息(例如目标间关系)来解决这一问题。文献[41]利用场景图对图像中各目标之间的关系进行挖掘。在构建场景子图时,提出一个概率框架对目标进行选择,并确定一个最优目标个数上限进行构建。考虑到即使是在同一类场景中目标属性和关系类型也是在不断变化的,因此只定义了两目标间是否有关系而不关注关系类型。该方案采用一个目标堆叠网络将场景子图中的目标和关系映射到一个潜在语义表示空间,同时用另一个CNN 模型将整个图像也映射到这个空间,通过对场景子图特征和全局特征进行迭代学习,实现了二次增强,最终利用增强后的全局表示进行场景识别。该方法的缺点在于仅仅对目标间关系进行了初步表示,并没有对关系类型进行精确定义,也没有采用高效的推理机制对图中信息进行处理。在现有的表示关系的方法中,图结构是最常见有效的一种。一个通用的图模型通常由节点和边两种重要元素构成,其中节点v 代表目标,边e 代表关系,如图3 所示。一些研究采用GRU(Gated Recurrent Unit)等模块作为存储器,传递并更新节点信息。另外,为了对这类图数据进行高效的学习,文献[42]提出了一种图卷积网络(Graph Convolutional Network),以图结构中节点的特征矩阵和图的邻接矩阵为输入,每一个隐藏层都对应一个特征矩阵表示各节点的特征,并利用传播规则对信息进行整合形成下一层更抽象的特征。图结构在计算机视觉多个任务中得到了应用,例如目标检测[43-45]、场景图生成[46]、多标签图像识别[47]等,当然图的实例化方式、信息传播机制等都高度依赖具体的任务域,要依具体任务而定。将上述思想应用到由场景图像构建的图结构中能充分挖掘场景中目标之间的关系以及相互影响,可以作为未来研究的一个关注点。但是这种做法内存开销比较大,如何在大型数据集上实现较好的识别效果有待于进一步研究。
4 场景识别中常用数据集介绍
(1)ImageNet[48]:包含1 500万张图片,涵盖2万多个类别,是用于计算机视觉研究的大型数据库。
(2)Places[49]:包含1 000万张图片,涵盖包括室内场景、自然场景、城市场景等在内的434个类别。文献[50]认为在Places上预训练的CNN与在ImageNet上预训练的CNN相比可以学习到场景图像中更多不同的特征。
(3)MIT Indoor67[51]:包含15 620张图片,涵盖67个室内场景类别,每个场景类别至少包含100 张图片,其中80张图片用来训练,20张图片用来测试。
(4)SUN397[52]:包含超过10 万张图片,涵盖397 个室内、室外场景类别,每个场景类别至少包含100 张图片,其中50张图片用来训练,50张图片用来测试。
(5)Scene 15[53]:包含4 485 张灰度图像,涵盖包括室内场景、室外场景在内的15 个场景类别。每个类别包含200~400张图片,其中100张图片用来训练,其余用作测试。
(6)UIUC-Sports[54]:包含1 792 张图片,涵盖8 个体育活动场景类别,每个类别包含137~250 张图片,其中70张图片用来训练,60张图片用来测试。
5 典型深度场景识别方法特点及结果比较
5.1 方法特点比较
表1 中列出了各方法的特点以及同时解决的特定问题。

图3 图结构表示
5.2 结果比较
为了对上述各种方法进行比较,本文整理了各种方法在MIT Indoor67、SUN397、Scene 15及其他数据集上的结果,其中以正确率(Accuracy)为评价指标。注意,以下所列实验在MIT67、SUN397、Scene 15、UIUC-Sports数据集上进行的训练集/测试集划分均按标准进行,即如第4章所述。对于Places205,训练集中共有2 448 873张图像,每类5 000 到15 000 不等,对应的,另外100 张图像用来验证,200 张图像用来测试。对于Places365,训练集共有1 803 460张图像,每类3 068到5 000不等,另50张图像用来验证,900张图像用来测试;在文献[40]中,GAF 直接由Place 数据集主页上公布的预训练的VGG16模型中提取,训练 提取SOSF和CFA时,每类随机选择100 张图像进行训练,100 张图像进行测试。结果比较如表2所示。
MIT Indoor67、SUN397、Scene 15数据集是场景识别任务中最常用的数据集。由表2可以发现,在对网络进行预训练时,除了用到以目标为中心的大型数据集ImageNet外,大多数方法都在大型场景数据集Places或其子集上对网络进行了训练,这一步有利于卷积神经网络能针对场景图像学习到更多丰富的特征。另外,通过表格可以看出,识别率较高的几个方法中都采用了数据增强操作,特别是文献[37]中效果提升最明显,进行数据增强一方面解决了数据量少的问题,一方面也有效防止了过拟合。从识别准确率来看,除了利用目标特征作为全局特征的补充特征外,结合有效的知识表示(例如文献[40]中的图像上下文特征)能有效帮助理解图像、提高场景识别率。利用显著性测量方法对场景中存在的目标进行选择,目标判别力越强越能代表一类场景,越能有效区分不同的场景类别,如文献[26],达到了相对较高的识别率;在文献[29]中,显著目标选择作为多分辨率网络结构的补充,一定程度上解决了标签模糊的问题,也帮助提升了识别效果;另外,文献[41]在构建场景子图时也对目标进行了选择。利用目标集中的显著区域或场景轮廓线条信息作为场景辨别性线索来进行场景识别效果并不理想。从文献[25,33,35]不同数据集上的实验结果来看,在SUN397(混合场景)上能达到相对较高精度的方法在MIT67(室内场景)上的效果却不突出,说明识别效果与数据集有关。

表1 典型基于深度学习的场景识别方法比较

表2 实验结果比较(正确率) %
6 结束语
本文对最近的基于深度学习的场景识别方法进行了总结与分析,尽管这些方法已经取得了显著的成果,但准确率还有待于进一步提高,未来仍然面临着诸多挑战:
(1)随着图像数据的不断增长,场景类别也在急剧增加,将不可避免地出现类别重叠的问题,导致场景标签模糊化,如何提高大规模场景识别的准确率变得十分关键。
(2)与目标识别不同,场景识别任务更为复杂,要考虑到图像中的目标、背景、空间布局以及内在联系,因此场景图像中存在的类内差异性和类间相似性问题也比目标图像的类内差异性和类间相似性问题更复杂。
(3)场景图像具有数据分布不均衡问题,一些场景类别样本数据严重缺乏,如果不对这部分场景类别作特殊考虑将严重影响识别的精确度。
(4)室内场景识别始终是场景识别任务中最具挑战性的部分,一些在室外场景上能达到很好识别效果的场景识别模型在室内场景数据集上的表现却不尽如人意。室内场景相比于室外场景而言,布局变化更大,目标信息更丰富,且受光线、角度变化的影响较大,如何从室内场景特性角度出发提高识别效果也是难点之一。
未来的研究趋势可以从以下几点考虑:
(1)针对场景图像的类间相似问题,挖掘细节信息可以对不同场景类进行区分,例如充分利用全连接层特征与卷积层特征的互补性,从场景整体布局和细节信息两方面考虑。
利用显著目标进行场景识别仍然是十分有效的方法,仍值得进一步研究。但只利用目标本身的特征及目标共现模式也无法避免相似场景造成的歧义,结合更具判别力的信息(如目标间关系)将缓解这一问题。结合图结构等丰富的知识表达工具,应用视觉推理模型,充分挖掘场景内部的各种联系,将进一步提高场景识别性能。
(2)对于场景图像中存在的数据分布不均衡问题,特别是数据量小的类别,可能会出现过拟合,使得测试阶段效果不好。数据增强是解决过拟合最有效的方法,在数据量小的类别中创造更多的数据,使数据分布达到平衡,即可提高模型的识别效果。传统的数据增强法包括:人工添加新数据,但成本太高,不易实现;另外,可以通过对图像进行平移、翻转、裁剪、缩放等操作增加数据,是相对简单易实现的操作。除此之外,可以采用元学习法[55]进行解决,通过将元学习者与学习者相结合,在其他额外的图像训练集上训练产生额外训练样例的“幻觉者”,实现数据增强,并与正则化技术相结合,减少数据分布不均衡的影响。
(3)对于室内场景识别问题,在全局特征的基础上,除了要更充分利用目标信息外,可以增加场景属性作为补充信息进一步增加不同类别图像的可区分度。场景属性作为场景的构成元素之一,不仅能反映目标等内容信息,还能从其他角度(例如场景功能属性等)对场景进行区分。挖掘特定于场景的属性信息将为场景识别提供有效的帮助。
