基于Spark的有效载荷参数解析处理方法
2020-03-07张文彬王春梅
张文彬,王春梅,王 静,陈 托,智 佳
(1.中国科学院 国家空间科学中心,北京 100190;2.中国科学院大学 计算机科学与技术学院,北京 100049)
0 引 言
科学卫星有效载荷产生的科学探测数据具有数据量大、参数多、处理实时性要求高的特点,其中参数解析是有效载荷数据实时处理的关键环节,其参数越多数据量越大,解析过程就越复杂越耗时。目前有效载荷数据的实时参数解析主要采用单机多线程处理方法[1],其存在吞吐率低、扩展能力弱的不足,因此,提高有效载荷参数解析的速率具有必要性。
当前主流的大数据流式计算框架Storm、Spark Streaming等具有低延迟、高吞吐、可扩展等优势[2,3],本文结合卫星有效载荷数据流的特点[4],利用大数据计算框架良好的实时处理性能和易扩展的能力,以提高有效载荷参数解析的吞吐率[5]。其中Spark[6,7]提供的生态系统具备同时支持批处理、交互式查询和流数据处理的优势,可实现数据的无缝共享。Spark Streaming是Spark计算引擎内的流式计算框架,因此,本文结合Spark Streaming和Kafka[8,9],设计并实现了一种有效载荷实时参数解析的处理方法,以提高有效载荷数据参数解析处理的实时性。
1 有效载荷参数解析的数据源
有效载荷数传数据,其格式遵循国际空间数据系统咨询委员会(consultative committee for space data systems,CCSDS)的高级在轨系统(advanced orbit system,AOS)标准[10],有效载荷数传数据结构见表1。
有效载荷数传数据的处理[11,12]步骤如图1所示,在对CCSDS格式的数传/遥测数据进行AOS帧同步、解密、解扰、分包、拼接等预处理之后,形成中间数据格式,称为数据帧,其主要结构见表2,其中,数据段部分存放各类参数的二进制编码,参数解析过程即是针对数据段中的各个参数编码进行处理,将其按要求解析为电流、温度等物理量。

表1 有效载荷数传数据结构
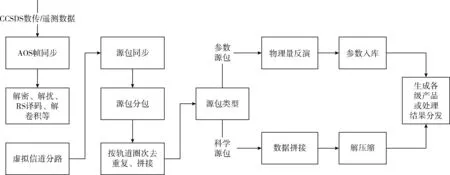
图1 数据处理流程

传输标签卫星标识消息长度帧计数卫星时间码状态量计数2B2B4B6B1B2B数据段应用数据变长
2 参数解析处理方法
为提高有效载荷数据的实时参数解析吞吐率,采用基于Spark Streaming与Kafka相结合的方法,处理流程如图2所示,利用Kafka集群作为消息中间件实现数据分流,为数据接入提供保障,流式计算部分采用Spark Streaming集群作为计算平台,通过Spark Streaming获取Kafka消息队列的数据[13],并对参数进行解析,然后将解析结果发送给Kafka作为数据缓冲区进行合并,最终将计算结果发送给实现参数录入的软件。
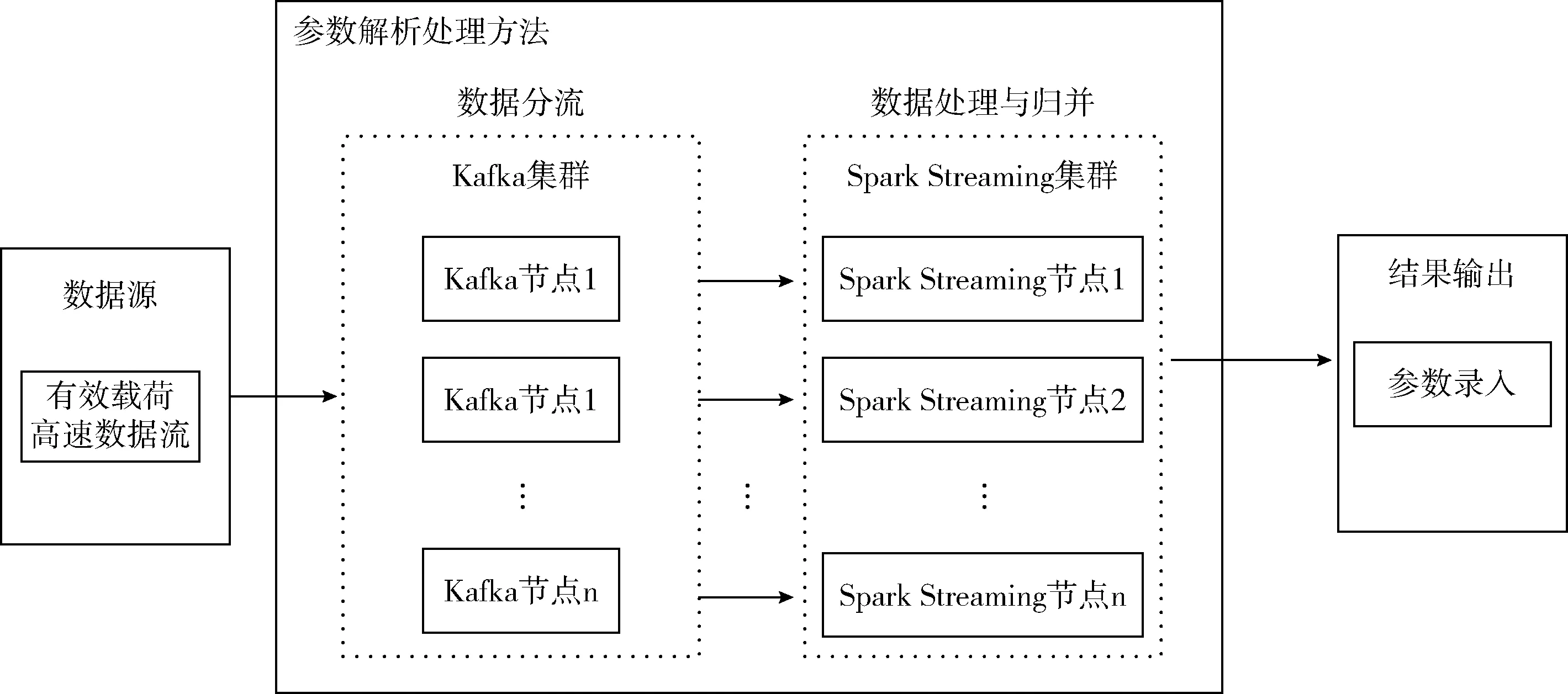
图2 系统处理流程
为避免数据源产生堆积,提高数据处理的速率,采用Kafka集群实现数据分流。Kafka是一种基于发布/订阅的分布式消息系统,可以在多个分布式生产者、消费者并发的情况下,保证消息的有序性和负载均衡,可同时支持离线数据和实时数据的处理,其吞吐量可随集群的扩展而线性增加,且消息持久化的时间复杂度为O(1)[14],具有高吞吐率、高可靠性和易扩展的优点。
Kafka集群部署模式如图3所示,在Kafka集群部署架构中,可以存在多个Producer(生产者),生产者负责收集消息并将消息发布到Broker(代理)相应的Topic(主题)中,Broker接收消息,并将消息在本地持久化,数据按照Topic名存储在不同分类中,一个Topic可以分成多个Partition(分区),每个Partition内部消息强有序,将数据处理为多个分区的消息队列流,用以作为中间数据源,在队列底端存在多个Consumer(消费者)[15]。消费者是消息的真正使用者,从Topic中读取队列消息进行处理[16]。其中Broker1、Broker2分别部署在不同服务器上,Spark Streaming的实时计算程序充当消费者订阅Topic1,当Topic1中有数据,会将数据不停的从集群的指定消息队列中发送给消费者做参数解析处理。

图3 Kafka集群部署模式
Spark Streaming是在Spark架构上基于离散化数据流(discretized stream,DStream)模型扩展的分布式流式计算框架,其中,DStream表示持续不断的数据流,其可以是不同类型数据源的数据,包括文件流、套接字流、基于Kafka的输入数据流等[17]。Spark Streaming可以在多达100个节点上运行,实时处理吞吐率能达到秒级的延迟需求[18],可以有效实现高吞吐的参数解析处理,并且Spark Streaming支持节点的错误恢复,是具备容错机制的实时流数据的处理框架[19]。
因此,采用Spark Streaming实现有效载荷数据帧的实时参数解析,搭建Spark Streaming集群,设置集群中的主从节点,其中主节点负责资源分配,从节点负责监控本节点的CPU及内存情况,接收主节点命令。将Spark Strea-ming 作为消费者订阅Kafka集群中的Topic1,当Topic1中有数据时,消费者从消息队列中获取数据。Spark Strea-ming 处理进程在获取数据之后按照参数名、起止位置、转换公式等结构信息,对参数进行解析,其处理架构如图4所示,主要包括如下步骤。
(1)数据分流
利用Kafka将数据源转换为消息队列流,按FIFO(first input first output,先进先出)方式有序缓存于 Topic1 中的各个Partition中,等待Spark处理进程作为消费者消费数据。
(2)Spark处理进程
主节点为从节点的Executor(执行进程)分配内存、CPU内核等资源,并启动Executor进程,每个从节点运行若干Executor,每个Executor独立运行参数解析处理程序,即将数据帧按照数据格式中的参数名、起止位置、转换公式等信息进行解析,解析结果作为Producer发送给Kafka的Topic2。
(3)归并
将Topic2中各个Partition的参数结果按时间先后顺序进行归并。Kafka的Partition内部消息强有序,从各Partition中获取结果数据1~n,按时间顺序排序将参数解析结果合并,最后将参数存入数据库。
3 方法实现与仿真验证
搭建3台虚拟机组成Spark Streaming集群,集群配置见表3。
测试采用表2格式的仿真数据进行实验,对单机多线程方法与基于Spark Streaming的集群方法进行了仿真测试,令单机多线程方法运行在表3中的任一台从节点(Worker1或Worker2)虚拟机上,基于Spark Streaming的集群方法运行在表3中的3台虚拟机搭建的集群上,测试结果见表4,结果表明在相同的处理单元数量下,单机多线程处理方法的吞吐率为10.24 Mbps,基于Spark Streaming的集群方法为25.56 Mbps,相比单机多线程方法的数据处理吞吐率提高了150%,并且基于Spark Streaming的集群方法可以通过增加从节点的方式进一步提升处理速率,具有很强的扩展能力,在实时参数解析处理中更具优势。
4 结束语
本文提出并实现了一种基于Spark的有效载荷实时参数解析处理方法,采用了Apache Kafka和Spark Streaming相结合的处理方法,利用Kafka对有效载荷实时数据分流,Spark Streaming获取数据并进行实时参数解析,解决了单机多线程方法在吞吐率和扩展能力上的局限性,提高了有效载荷参数解析处理的实时吞吐率,仿真结果表明,所提方法相比目前的单机多线程方法在相同处理单元配置下的数据吞吐率提高了150%,具有更优的实时参数解析能力。
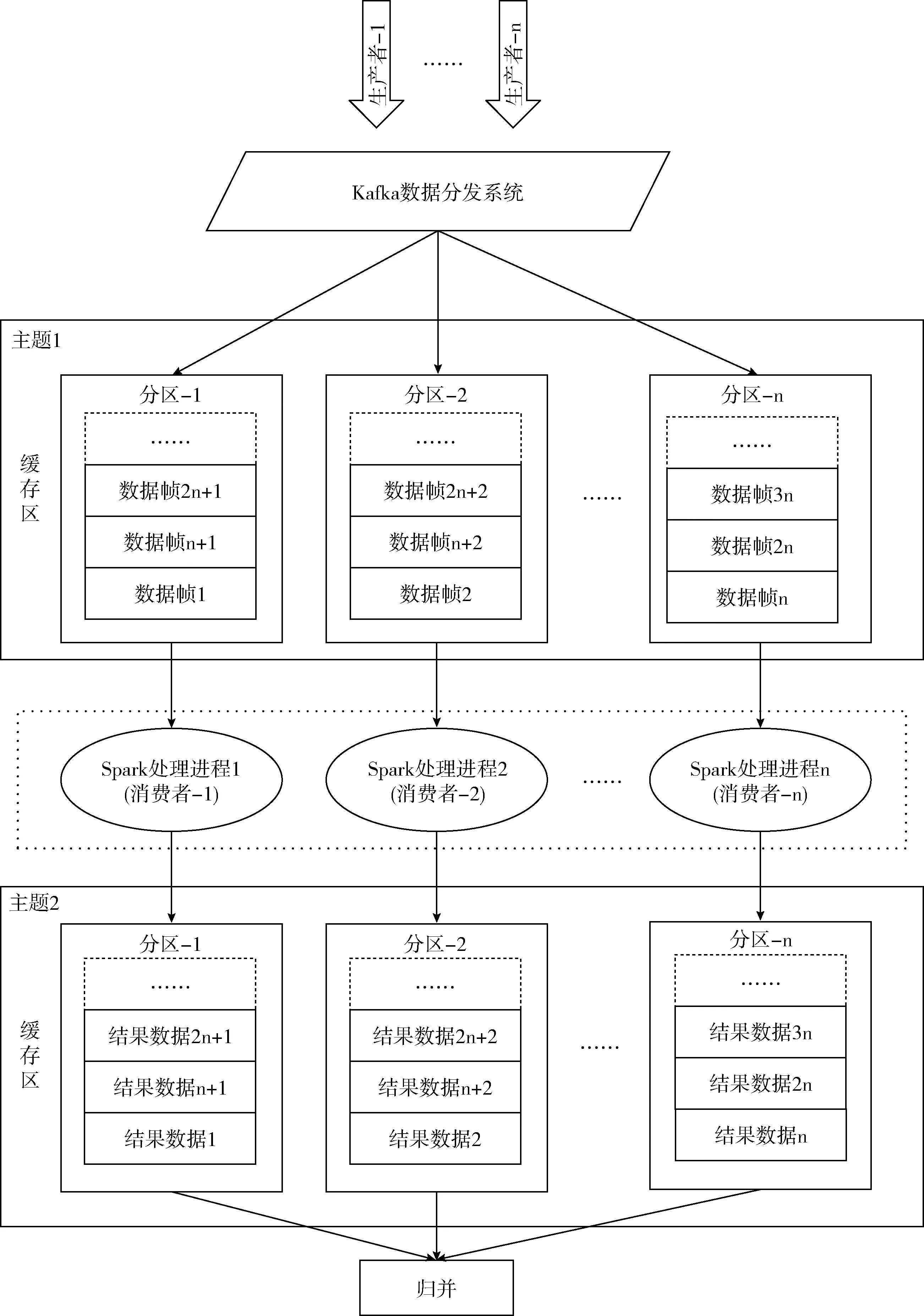
图4 参数解析处理架构

序号名称角色配置1Master主节点CPU:2.83 GHz,2核心;内存:6 G;硬盘:20 GB;操作系统:CentOS72Worker1从节点CPU:2.83 GHz,4核心;内存:4 G;硬盘:20 GB;操作系统:CentOS73Worker2从节点CPU:2.83 GHz,4核心;内存:4 G;硬盘:20 GB;操作系统:CentOS7

表4 两种方法测试结果比较
