浅说语音识别技术
2020-03-04袁冰清
袁冰清,于 淦,周 霞
(1.国家无线电监测中心上海监测站,上海 201419;2.国家无线电监测中心,北京 100037)
0 引言
语音识别(ASR,Auto Speech Recognize),是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言或者文字。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别目前是人工智能领域最成熟也是落地最快的技术。如今,语音识别系统在现代社会中的应用也越来越广泛,特别是在人机交互方面,如智能手机、智能家居等设备中的各类语音助手(苹果Siri,天猫精灵等);在专业领域的应用也是越来越广,比如在无线电监测与频谱管理中,对广播频段的监测,我们可以通过语音识别系统,对监测到的语音信号自动识别,及时发现非正常广播,比如调频广播中的黑电台、调幅广播中的FD电台,等等,这样可以实现自动监测,减少工作量。本文简单介绍语音识别原理,希望对语音识别系统在其他专业领域的应用有所启发。
1 传统的语音识别架构GMM+HMM
语音识别主要包括两个基本步骤,一个是系统“学习”或者“训练”,主要任务就是建立声学模型及语言模型。另一个就是识别,根据识别系统的类型选择合适的识别方法,提取语音的特征参数,按照一定的准则与系统模型比对,经过判决得出识别结果。实际上,在开始语音识别之前,需要对待识别的语音(一般先转为非压缩的纯波形文件也就是俗称的WAV文件)做预处理,把首尾端的静音切除,降低对后续步骤造成的干扰,这个操作称为语音端点检测(VAD,Voice Activity Detection)。后续特征提取部分的目的都是把声波信号分离成计算机能识别的信号。
1.1 特征提取
首先对声音进行分帧,也就是把声音切开成多个小段,每一段称为一帧。一帧信号通常为20~50ms,宏观上足够短,在一个音素之内,在宏观上足够长,至少包含2~3个周期。分帧之后,波形在时域上没有任何描述能力,必须做波形变换。首先把时域信息转换为频域信息,一般用离散信号的傅里叶变换FFT;再经过三角滤波之后,得到频谱包络;最后再做波形变换变成包含语音特征的序列。常见的波形变换的方法是提取MFCC(Mel Frequency Cepstral Coeff icient)特征[1],即根据人耳的生理特征,把每一帧波形变成一个多维向量,这个向量包含了每一帧语音的内容信息。至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵。每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。具体过程及结果如图1所示。这个MFCC序列就是整段语音的特征。

图1 特征提取过程及结果
1.2 GMM与HMM识别过程
这样待识别的语音信号变成一系列的带有语音特征的序列,待识别语音序列跟模板中最相似的一帧匹配,保持顺序,相同序列对齐,计算各帧之间的欧氏距离之和,总距离最小的就为识别结果。这种计算两个特征序列的算法为“动态弯算法”。
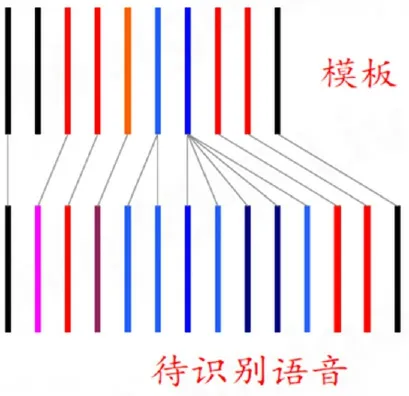
图2 单一模板的识别算法
但是在实际的语音识别中,每个人说法的音色音调等都不一样,导致同一个词的特征模板是不一样的,但是每个词的可能性都服从高斯分布,因此我们可以把模板拆分成多个小段,利用高斯分布叠加拟合,也就是高斯混合模型(GMM,Gaussian Mixture Model)。这样,对于任意一个词(特征向量)就有一个概率密度。还是用“动态弯”算法对齐待识别语音与模型,但是用GMM概率密度代替特征向量的欧式距离,相乘得到一个总概率,取概率最大的模型为识别结果,过程如图3[1]所示。
GMM不考虑时序特征,但是语音识别是包含时序特征的,因为句子由词组成,后面的词跟前面的词有关,一个词由几个音素组成,后一个音素跟前面的音素也是有关系的。而语音识别的过程其实就是:把帧识别成状态,三个状态组合成一个音素,音素再组合成单词。因此引入隐马尔科夫模型(HMM,Hidden Markov Model),引入转移概率(隐态),包括当前状态转移到自身或者其余状态的概率,如下图的0.3为转移到下一个状态的概率,0.7为转移到自身状态的概率,0.016为观察概率,即每一帧和每一个状态对应的概率,由上面的GMM决定。

图3 多个模版的高斯混合模型
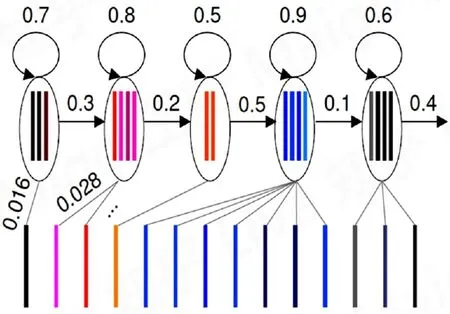
图4 HMM在状态识别中的过程
由此,我们可以把模型完全概率化,搭建一个状态网络,语音识别的结果就是从大的状态网络中找到与声音最匹配的路径。从概率上讲,语音识别的基本方程如下[2]:

式中,W*为识别结果;W任意单词;X待识别语音信号;P(X│W)声学模型得到(GMM+HMM);P(W)单词的先验概率。
1.3 连续语音识别
连续的语音识别也即是一句话的识别也由W*=argwmaxP(X│W)P(W)决定,只是这里的W和W^*由单词变成句子,句子的声学模型P(X│W)可以由单词的声学模型串起来。
2 深度学习网络与语音识别
2.1 基于DNN+HMM语音识别网络
上文介绍的传统的基于GMM+HMM的语音识别系统一直是主流的方法。特别是在1990~2010年,语音识别的基本框架没有变化,如图5所示,只是对其中某些部分进行完善和优化。

图5 1990~2010年语音识别基本框架
直到2006年,深度信念网络(DBN,Deep Belief Network)及其相应的非监督贪心逐层训练算法,解决了深层结构相关的优化难题,并以此引入了深度学习网络的概念。深度学习的横空出世,到2009年被引入到语音识别领域,慢慢地开始蚕食GMM+HMM框架。
深度学习最开始应用在语音识别中,是用在前端提取特征,替代MFCC。发展到后面,不再进行特征提取,输入为滤波器组的输出或者直接波形输入,而声学模型改为深度神经网络(DNN,Deep Neural network)与HMM模型,DNN提供P(状态|输入),并且成品系统中没有GMM,但是训练DNN时需要GMM+HMM系统提供标准答案。深度学习(Deeping Learning)常用模型卷积神经网络(CNN,Convolution Neural Network)和循环神经网络(RNN,Recurrent Neural Network)代替一般的DNN用于特征提取或者声学模型[3],又由于RNN训练时容易梯度消失或者梯度爆炸,导致RNN的记忆力有限,长短时记忆网络(LSTM,Long Short Term Memory Network)及其变体GRU(Gated Recurrent Unit)代替原先的RNN。这时候还保留着HMM,因为神经网络只进行逐帧判别,训练时,需要由HMM系统提供各音素起止时间(对齐),并且解码时,需要考虑状态转移概率。
2.2 端到端语音识别结构
传统的HMM模型中,需要模板对齐;DNN的声学模型用来输出状态对应的后验概率,也是需要用到GMM的对齐结果,来获得每一帧的标签。这就需要GMM的对齐结果比较准确,而语音的边界是不好界定的,这样给每一帧指定一个确定的标签本身是值得商榷的。所以端到端的模型就是只有一个神经网络,对于整个识别过程,模型的输入就是语音特征(输入端),输出就是识别出的文本,相当于一个黑盒子,只用一个损失函数作为训练的优化目标,不再去优化一些无用的目标了。目前,有两种主流的端到端的语音识别模型,连接时序分类算法(CTC,Connectionist temporal classif ication)和基于注意力机制(Attention Mechanism)的模型。
CTC不需要对语音模型对齐,只需要一个输入序列和一个输出序列即可以训练,直接输出序列预测的概率,不需要外部的后处理。传统的语音识别训练的时候需要进行语音和音素发音对齐,每一帧都有相应的状态标记,比如有5帧的输入x1,x2,x3,x4,x5,对应的标注分别就是状态a1,a2,a3,a4,a5。CTC的不同之处引入了空帧,不再进行逐帧判别,大部分帧输出为空,小部分输出为音素,只求输出音素串于标准答案相同,不要求位置对齐。多个输出序列可以映射到一个输出,但是假设各帧输出是相互独立的。跟传统的基于HMM模型相比,结构简单,没有转移概率,但是仍然需要词典跟语音模型。
基于注意力机制的方法与DNN-HMM或者CTC方法相比,没有做任何条件独立性假设,而是在概率链式法则的基础上直接预测后验概率。基于注意力机制的“编码-解码”模型主要由编码网络、解码网络和注意力子网络组成。编码网络将原始语音特征序列转换为高层特征序列,注意力子网络计算高层特征序列中每个元素的权重,并且将这些元素加权合并到一个目标向量。解码网络把目标向量作为输入逐个计算输出序列每个位置出现各个因素(字素)的后验概率,并通过解码算法生成音素(字素)序列。其中,注意力子网络计算出的权重(也被称为注意力系数)的大小能够反向序列输出序列的音素与输入特征之间关联程度的高低。该模型既不依赖先验对齐信息,也摆脱输出音素序列之间的独立性假设。两种端到端语音识别系统框架如图6[4]所示:

图6 端到端的语音识别系统架构
与传统的HMM的语音识别系统相比,端到端的语音识别系统把声学模型、发音词典和语音模型全部融合至一套神经网络中,让模型变得更加简洁的同时便于对参数直接优化。端到端模型更强的通用性。既减少对专业语言知识的依赖,又降低语音识别系统搭建难度;端到端模型的训练数据不需要对齐信息,可直接将带标注的语音用于训练。
3 结束语
目前,常用的端到端语音识别模型简洁,容易训练和使用,在理想情况下的性能可与人媲美。但是在恶劣的条件下,识别率不尽人意,特别是远场、高噪声等情况下的识别率较低。未来的语音识别系统,一方面在前端处理的时候,降低或者去除噪声,使语音增强;另一方面收集大量数据,让神经网络学习训练长见识,以适应各种恶劣条件下的应用场景。
