面向航天员训练的混合现实场景理解方法研究
2020-03-03晁建刚许振瑛
李 畅,晁建刚,2∗,何 宁,2,陈 炜,2,许振瑛
1 引言
航天员在轨空间操作及地面训练时,可以通过混合现实系统为其提供实时可视化的作业引导。当前的混合现实系统(Mixed Reality,MR)实现方法是工作人员在操作环境对虚拟物体放置位置进行人工标注,然后部署引导程序,通过系统空间实时定位技术[1]获取当前定位信息,依据此信息将虚拟对象混合叠加在真实环境中。
目前航天员混合现实系统都是事先设置好的“以计算机为中心”的程序化引导系统,当舱内场景发生变化时,混合现实系统无法自动对变化情况做出判断,并自动进入合适的引导流程,此时需要航天员进行人工干预操作实现程序引导。此局限性原因在于目前系统尚未实现对物理空间的场景理解功能。而对于复杂模式、未知模式以及应急模式,系统自主识别场景变化,并针对性对变化进行引导非常必要。
航天员混合现实辅助系统在国内外均有相应研究。NASA与微软联合开发的SideKick项目[3]使用Hololens眼镜为航天员提供辅助空间定位支持;DSH(Deep Space Habitat)深空栖息硬件定位器[4]以“X射线视觉”形式辅助空间设备目标定位,帮助工作人员找到特定设备;StowageApp[5]通过对于三维环境测量感知,获取货物定位信息与装载信息,动态指导航天员完成装载任务,打包和打开货物。上述研究仍是程序化流程系统,没有形成主动引导机制,普适能力差,无法做到自主识别与实时诱导反馈。
中国航天员科研训练中心研制了基于增强现实的航天员远程专家辅助系统,该系统为航天员复杂操作训练提供实时远程专家多模式支持,并在空间实验室任务组合体训练模拟器内进行实验验证。结果表明,采用远程专家模式与传统电子手册模式相比,总时长减少48%,可以提高航天员执行复杂工作的效率,但仍无法实现对物理场景变化的自主识别。
场景理解的关键是图像识别技术,主要分为传统的图像识别及基于深度学习的图像识别两种实现方式。传统图像识别通过人工设计局部特征描述子,如 FAST算子[6],Harris角点[7]等,主要通过选取图像中特征比较明显的点进行比较识别,对于纹理信息较弱的图像很难提取足够的信息。 SURF(Speeded Up Robust Features)[8]、SIFT(Sorting Intolerant From Tolerant)算子[9]是基于密集提取方式,信息更加丰富;Canny算子[10]、Sobel算子[11]、Hough变换[12]等更擅长提取轮廓边缘信息。但是这些都是通过人工设计方式,无法充分提取图像特征。随着人工智能和深度学习的发展,深度神经网络可以利用自身架构特点充分学习提取图像信息,仅输入图像和深度信息即可对操作对象完成识别,且效果优于基于计算机视觉的方法。比较典型的方法有基于候选区域方法如R-CNN[13]、fast R-CNN[14]、faster R-CNN[15]、RFCN[16]等,这些方法需要先划分候选区域,然后对每个候选区域分别进行目标识别,识别速度较慢。另有基于回归方法如 Multi-Box[17]、YOLO(You Only Look Once)[18]、SSD(Single Shot multibox Detector)[19]等,采用统一框架直接实现最终结果(类别和位置),可以有效提高识别速度。如 SSD其识别速度为 46 fps,同时在VOC2007[20]数据集上可以达到77.2%的准确率。
目前,计算机视觉方法较适合处理二维特征(色彩,纹理等)较为丰富的图像,由于计算量较大,更适合离线识别,且鲁棒性较差,在实践中识别准确率较低,难以满足航天复杂环境。深度学习方法在前期就通过大量数据集训练生成模型,后期直接利用模型进行识别,效率较高,且深度学习方法通过多层神经网络架构学习更复杂的特征信息表达方式,更适合在复杂空间环境中进行图像识别,且可以通过一些策略,在保证高识别率的同时,实现实时识别。因此深度学习方法更适用于航天环境。
在航天员混合现实训练环境中,场景理解可以实现在舱内物理环境发生变化时,对其进行快速识别,做出判断并自动导入正确引导流程,实现航天员混合现实系统的自主智能诱导能力。本文针对航天员混合现实系统舱内环境智能理解任务需求,建立原型系统,研究空间场景目标识别方法,重点通过深度学习方法训练设备识别模型,并通过混合现实技术,在航天员训练时为其提供设备识别信息,以提高航天员混合现实操作辅助系统智能性和可用性。
2 原型系统总体设计
2.1 混合现实系统框架
混合现实系统框架如图1中实线标识所示,佩戴MR设备的航天员通过手势或语音传递指令信息,视觉场景捕捉模块获取指令信息,并对当前环境进行信息获取。同时利用 SLAM(Simultaneous Localization and Mapping)技术,获取当前定位信息,传递给混合现实场景渲染模块。场景渲染模块再依据当前定位信息,从虚拟场景模型库和信息引导数据库中提取相关内容。
本文设计在已有混合现实系统框架中添加场景理解模块,如图1中虚线所示。在航天员通过手势或语音交互指令传达场景识别意图后,场景视觉捕捉模块获取当前场景信息,并将信息传递给场景理解模块,场景理解模块识别出内容,结合场景同步定位信息获取当前预知定位的配置信息,传递给混合现实场景渲染模块,结合信息引导数据库与虚拟场景模型库进行混合现实引导场景渲染。
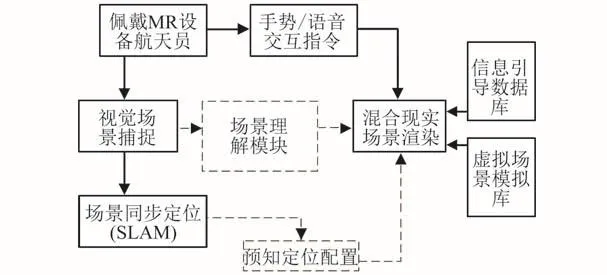
图1 混合现实系统框架图Fig.1 Block diagram of mixed reality system
2.2 场景理解模块框架
场景理解模块框架如图2所示,场景理解模块对场景视觉捕捉模块获取的场景图像进行理解分析,得到识别结果和对应的引导信息,然后发送给混合现实场景渲染模块,生成混合现实引导场景。

图2 场景理解模块框架图Fig.2 Block diagram of scene understanding
视觉场景捕捉模块主要为场景理解模块提供当前场景图像信息。场景理解模块在获取图像信息后,将信息传入深度学习模块,通过已训练好模型快速识别出场景中待识别目标,并将结果传递给自主引导模块,同时为混合现实场景渲染模块提供场景同步定位信息。
场景理解模块主要包括图像采集模块、深度学习模块、自主引导模块。其中自主引导模块与引导模型库、引导指令库相关联,当深度学习模块识别出结果后,自主引导模块依据深度学习识别结果从候选模型集中提取识别结果模型,从信息导引数据库提取模型导引数据和对应的导引指令,生成可视化引导数据,并传递给混合现实场景渲染模块进行渲染。
混合现实场景渲染模块收到可视化引导数据,利用当前场景同步定位信息,将可视化引导数据叠加到真实场景中,生成混合现实引导场景。
3 场景理解应用设计
场景理解的核心是视觉图像的识别。如前所述,传统图像理解方法在实践中准确率较低,深度学习图像识别方法可以在保证高质量识别的同时满足实时性要求,故本文重点研究基于深度学习的场景理解。
3.1 样本选择
航天器舱内环境具有以下特点:
1)空间狭小。目标会存在遮挡现象;
2)设备外观风格一致。材料相同,纹理相似且大部分为弱纹理;
3)大部分设备数量单一且基本固定。难以通过图像采集方式有效获取一定规模的数据集。
对于场景理解模块,舱内环境带来的限制有:舱内设备为专有设备,无法通过使用通用数据集对模型进行训练;舱内场景限制,本身设备所能获取的样本量有限。
对于深度学习方法,由于深度学习网络层数较多,使得深度学习分类器对应参数较多,为确定这些参数的取值,需要大量的训练样本,因此,如何生成大规模的有效数据集是深度学习方法主要需要克服的难点。
舱内设备大多为专有设备,且纹理较弱、色彩较为单一,故无法采用通用数据集进行模型训练。因此,为满足深度学习数据集对于信息丰富性和规模性的需求,本文采用一种合成的方法对舱内专有设备建立数据集。
在舱内进行数据集采集,选取结构信息较为明显的设备模型,提取其不同方位,不同角度的二维图像,并叠加在通用数据集VOC2007[20]上。如图3所示,(a)图为舱内阀门真实图像,(b)图为利用阀门的3D模型生成的合成图片,并将其随机叠加在VOC2007数据集上。
3.2 样本标注方法
对样本进行标注,也就是在数据集中增加真实值信息。通过对样本数据提取真实目标信息,并存储于数据集中,从而丰富数据集信息,有效提升深度学习效率。

图3 舱内样本集Fig.3 In-cabin sample set
具体方法为首先将原始图片压缩为同等大小的图片,然后建立对应的真实值标记数据,其中包含每张图片中目标类别信息和对应包围框位置信息,并存储为与图片相对应的XML文件。
参考 ImageNet[22]和 VOC2007数据集,设计本文的训练与测试集,步骤如下:
1)将图片按顺序进行编号;
2)获取图片的真实样本标注信息,将其以XML文件格式存储,并与图片名称相对应;
3)将数据集划分为训练验证集与测试集,其中训练验证集占数据集的80%,用于训练神经网络模型,测试集占数据集的20%,用于测试检验模型的准确度。训练验证集又按4∶1比例划分为训练集与验证集,训练集用于神经网络模型参数学习,验证集用于在训练过程中验证训练是否过拟合、以及用来调节训练参数。
3.3 深度学习算法选取
利用深度学习方法进行图像识别主要分为两种,基于候选区域方法和基于回归的方法。表1为当前较为经典的深度学习方法在通用数据集VOC2007上的识别结果对比。在采用相同VGG网络架构前提下,基于回归方法的如YOLO和SSD的识别速度可以达到比较良好的实时效果,而基于候选框模式的如R-CNN和R-FCN只能达到帧率为10 fps的速度,甚至更慢。而且,基于回归模式的方法,如SSD,也可以在保证识别速度的同时,达到与候选框模式相同水平的准确率。
混合现实系统对于场景理解模块具有较强的实时性要求,所以选取当前在图像识别方面实时性和准确性都比较突出的SSD深度学习架构。其主要通过回归的方法同时将目标位置与目标类别检测出来,也就是在深度学习过程中,同时考虑两者的可能概率。目前已有比较成熟的深度学习架构可以准确实现对于图像内的目标识别,如VGG-16[21]。但是VGG网络架构主要是实现图像特征提取,并不具备在识别物体的同时确定目标边界的能力。一种解决方案就是在VGG架构之后增加多层网络,实现目标边界确定与目标识别同时进行。主要网络设计架构图如图4所示。
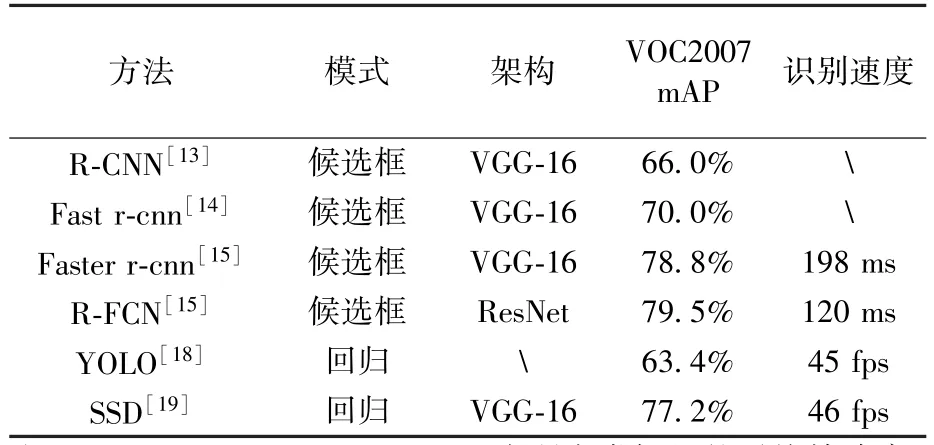
表1 深度学习方法对比Table 1 Comparison of deep learning methods
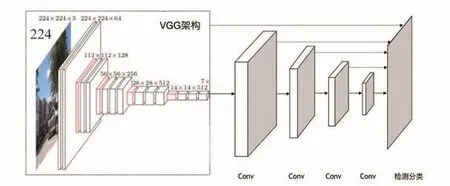
图4 网络架构图Fig.4 Diagram of network architecture
二维匹配架构在VGG架构中5层卷积基础上再增加数个特征提取卷积层,用于预测边界框和置信度。其中提取特征卷积层采用基于Multi-Box[17]的边界回归算法,这是一种通过多层不同尺寸的卷积网络实现金字塔式多尺寸图像边界确定方法。不同卷积层的网格尺寸不同,通过将上一层传递的特征图进行更细尺度的网格划分,并在每个网格中心设立目标检测器,如图5所示。通过将图像细化分为网格子区域,并在每个子区域上适当扩大范围,然后在此范围内进行目标识别,最终输出此范围大小和目标识别的置信度。
考虑到目标除了尺寸之外,还有形状、方向的不确定性,所以对每个目标检测器都增加不同大小的检测边界框,如图5所示。通过设立潜在边界框规则,见式(1),在检测边界框的大小时,可以包括以目标检测器所在网格为中心横向延伸和纵向延伸的潜在目标。
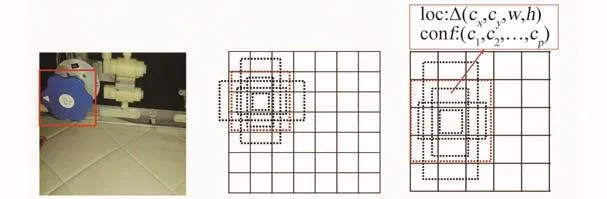
图5 Multi-box回归算法[17]示意图Fig.5 Schematic diagram of Multi-box regression[17]
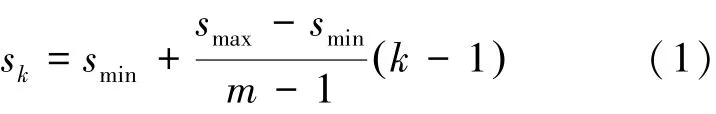
其中,k∈ 1,m[ ],m为潜在边界框数量,k为某层卷积网络中的边界框,smin和smax为人为设置参数,分别为0.1和0.9,及候选边界框大小从0.1到0.9的图片比例平均分布。检测策略是在卷积层对应的检测边界框中进行边界回归,同时计算边界框内图像属于某一物体的可能性,见式(2)。

其中,loss为检测回归中的损失函数,包含对于边界框的回归定位和对目标识别结果的最优提取。boxp是检测出来的边界框位置,通过SL1函数进行平滑优化,cp是判断目标属于某一类别的可能性,并通过Softmax函数提取最佳值。P(Ci)∗IOUtp为最终输出的结合置信度,见式(3),当P(O)>0时表示在检测框内存在物体,IOUtp表示其包围框置信度,P(Ci|O)代表检测物体属于类别 i的概率。IOU(Intersection Over Union)[13]通常用于描述两个样本集间相似度,表达形式见式(4),当IOU大于一个阈值时,则认为两者之间是匹配的。
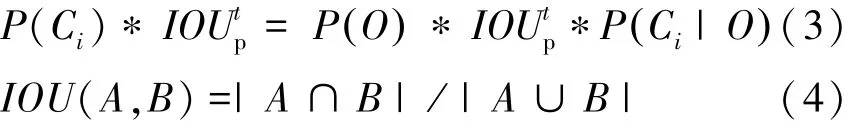
4 实验与验证
4.1 实验环境
本文将场景配置模块部署于Hololens混合现实设备中,将视觉分析模块部署于远程计算机中。HoloLens作为当前比较成熟的便携式混合现实设备,其可佩带性决定了其体积小和重量轻的特点,在相当程度上限制了其计算能力和功耗,因此无法将需要大量计算的视觉分析模块也部署于Hololens中。
1)实验设备:Hololens混合现实设备,Surface book笔记本,Intel i7 CPU,内存32G,配备Nvidia GeForce 1060显卡,显存6G;
2)运行环境:Ubuntu16.04系统,CUDA8.0,python3.6,tensorflow-gpu1.4;
3)目标场景:航天器舱内以其他室内场景。
4.2 实验数据
针对舱内环境特殊性,通过对真实环境采样的形式建立的真实数据集具有真实性,但是样本量有限;通过设备3D模型与真实图片相结合的合成数据,可以扩大样本量,但不可避免带来非真实数据,影响实际识别效果。因此,本文对合成数据集和真实采样数据集分别进行训练,并对结果进行比较。
合成数据集的生成方法是选取舱内环境中三维结构较为丰富的阀门模型,提取其不同方位,不同角度的二维图像,并叠加在已有图像数据集中。在VOC2007数据集随机选取3000张图片,并随机在其图片上叠加不同姿态的模型,最终形成数据集,同时生成对应XML文件。
为验证合成数据集的合理性,建立真实数据集进行对比,方式为通过相机在实际舱内场景中对目标物体通过不同角度,不同距离和不同方位分别进行拍照采样,图片存储为JPEG格式,同时通过人工标定方法记录图片中目标物体的类别与位置,存储为XML格式文件。
4.3 实验结果分析
4.3.1 合成数据集训练结果
图6为Tensorboard软件依据网络训练过程中数据生成的损失函数趋势变化图,其横坐标为迭代(训练)次数,纵坐标为损失函数值。神经网络学习成果可用合成数据集,包含3000张图片,其中2403张作为训练验证集,597张作为测试集。在训练时分为2个阶段:第一阶段只训练特征,提取卷积层,不调整VGG-16网络的默认参数,训练5000次;第二阶段对于整个网络架构进行参数微调,训练5000次。共进行10 000次。在第一阶段,学习率为0.001,学习率损失参数为0.94,权重损失率为0.0005。在第二阶段,学习率在0.00001,权重损失率为0.00005,学习率损失参数为0.94。训练中损失函数值趋于稳定,对597张测试集图片进行检测,并与真实标定结果进行比对,所得mAP为79.8%。
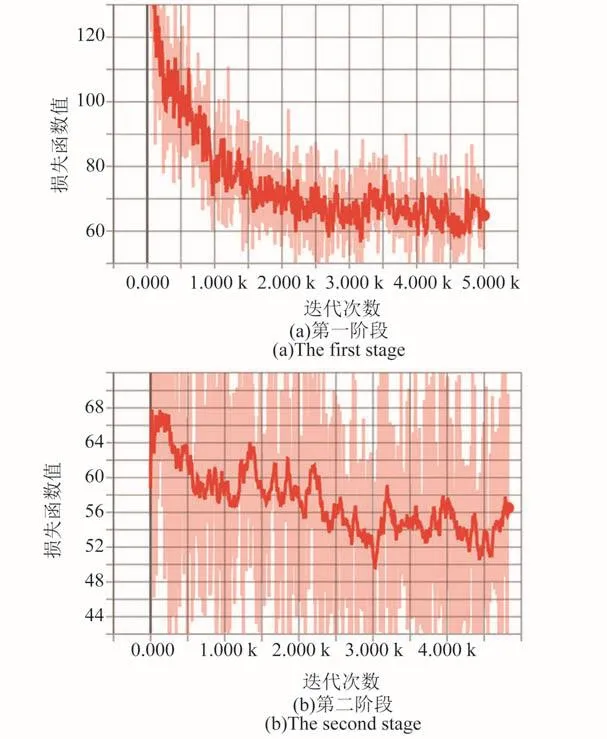
图6 合成数据集损失函数趋势变化Fig.6 Trends of synthetic data-set loss function

图7 合成数据集识别结果Fig.7 Results of synthetic data-set recognition
在本地计算机进行图像识别,所得结果如图7所示。图中标识出的细边框为识别出的边界框位置,[1|0.953]和[2|0.739]为识别出的目标物体的类别和概率值。
4.3.2 真实数据集训练结果
真实数据集包含403张图片,其中362张图片作为训练验证集,41张作为测试集。训练过程趋势图如图8所示。
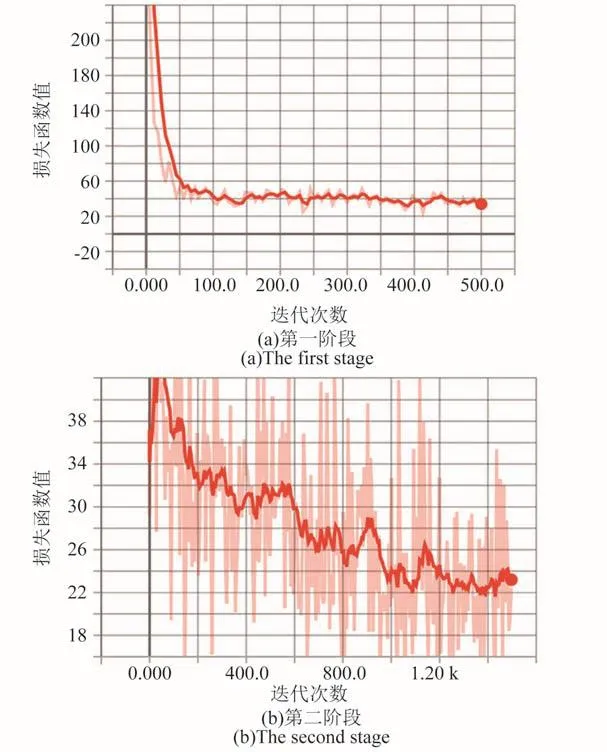
图8 真实数据集损失函数趋势变化Fig.8 Trends of real data-set loss function
整个训练过程参数与合成数据集相同。第一阶段训练500次,第二阶段训练次数为1500次。训练中损失函数值趋于稳定,测试集共包含41张图片,格式与训练验证集相同。对所有测试集图片进行检测,并与真实标定结果进行比对,所得mAP为72.88%。
视觉分析模块进行本地图像识别所得结果如图9所示。图中标识出的细边框为识别出的边界框位置,[1|0.825]和[2|0.570]为识别出的目标物体的类别和概率值。
4.3.3 训练结果对比
共在3个不同的数据集上进行了实验训练,结果如表2所示。结果表明,2种数据集的训练结果基本可以达到SSD在通用数据集上经过大量训练后达到的识别准确率,且识别速度为46 fps,与通用数据集识别速度相同,可实现实时识别。由于数据量较少,在真实数据集上的模型训练仅经过2000次后就趋于收敛,但精度较低。合成数据集的训练次数与通用数据集VOC相似,数据量较为丰富,故mAP值较优,验证了采用合成数据集在SSD网络架构上进行学习的方法优于真实数据集方法,更适用于舱内环境。

图9 真实数据集识别结果Fig.9 Recognition results of real data-set

表2 训练结果对比Table 2 Comparison of training results
4.4 混合现实空间场景原型系统实验结果
航天员混合现实训练环境如图10所示。航天员佩戴便携式混合现实眼镜,通过语音或手势指令与混合现实系统进行交互。混合现实系统对环境信息进行分析,得到可视化语义指导信息,叠加到现实环境中。航天员可通过透射式眼镜获取混合现实引导场景。

图10 混合现实训练环境Fig.10 Mixed reality training environment
经测试,通过Hololens混合现实设备捕捉场景图像,通过4G网络传至配有场景理解模块的电脑,平均时延为150 ms,场景理解模块对一张图片进行分析平均耗时约为10 ms,分析结果通过4G网络传回Hololens端约耗时30 ms,渲染处理大概10 ms,共耗时约200 ms,满足实时性要求,证明系统原型架构设计合理。
在本地运行场景理解,识别结果示意图如图11所示,可识别出目标在图片中的位置(边界框)、类别(3)以及对应的概率(0.905)。航天员混合现实系统根据场景理解模块识别结果,和场景定位信息,记录采集图片在真实环境中的位置,调用引导信息库和引导模型库中相关设备的操作引导流程,在采集图片位置上进行叠加。具体方式为依据识别出的模型类型,从引导信息库和模型库中提取相关虚拟模型,然后将虚拟模型放置在识别出的边界框中,并投射至采集图片的位置上。如图12所示,虚拟模型在混合现实场景中叠加在真实设备上,并显示虚拟箭头,提示航天员需对该设备进行操作。实验结果表明文中选择的深度学习方法识别有效。

图11 场景理解本地识别示意图Fig.11 Local recognition diagram of scene understanding

图12 航天员混合现实系统引导场景Fig.12 Guidance scene of astronaut mixed reality system
5 结论
1)研究航天员混合现实系统原型架构设计、场景理解应用设计,通过深度学习方法训练设备识别模型,并使用混合现实技术,在航天员在轨操作及训练时为其提供设备识别信息。
2)研究结果验证了系统原型架构设计和采用SSD深度学习方法以及远程终端的方式,可以满足混合现实空间场景理解原型系统的实时性需求,采用合成数据集方法可以克服舱内环境特殊性带来的对数据集建立的限制。
3)本文提出的原型架构和场景理解方法可以有效解决航天员在舱内训练时对于设备操作状态变化的自然识别需求,并通过自主引导模式在混合现实系统中实现实时引导。
