基于自适应Siamese网络的无人机目标跟踪算法
2020-03-02刘芳杨安喆吴志威
刘芳,杨安喆,吴志威
北京工业大学 信息学部,北京 100124
相比于载人飞机,无人机因其体积小、隐蔽性强、反应快速、对作战环境要求低和能迅速到达现场等优势,被广泛应用于军事和民用领域。而无人机的广泛应用需要目标跟踪技术,它能极大增强无人机的自主飞行和监控能力,使得无人机能够完成更多种类的任务,并且适应更复杂多变的环境[1]。因此,研究有效而稳定的目标跟踪算法对于无人机的应用具有重大的意义[2]。
无人机在飞行过程中拍摄视角和飞行速度经常会发生改变,导致目标易发生形变、遮挡等情况,经典跟踪算法效果较差。近年来,基于相关滤波的跟踪算法如KCF(Kernelized Correlation Filters)[3]、SAMF[4]和MUSTer[5]等在跟踪精度和跟踪速度上有着较好的效果,相关滤波逐渐成为跟踪领域的重要研究方向之一[6]。目标的特征表达是影响其性能的重要因素之一,传统的人工特征对目标状态变化不鲁棒,而无人机在很多实际应用中往往要面对复杂的环境,基于传统特征算法的跟踪效果不理想。深度网络因其具有良好的特征表达能力,研究人员采用深度特征代替手工特征,比较有代表性的跟踪方法有DeepSRDCF[7]、SiamFC[8]、CFNet[9]和DCFNet[10]等。尽管上述跟踪算法在跟踪成功率和精度上取得了显著的提升,但是在目标发生形变、遮挡等情况下,仍然容易发生漂移现象,导致算法的准确度降低。Danelljan等[11]提出一种生成模型提升了训练样本的多样化,并对目标函数进行了完善和改进,优化了样本分布,减轻了形变情况对性能的影响,但由于更新过程计算较为复杂,跟踪速率较低。Liu等[12]提出了一种新颖的模板匹配式跟踪算法,使用K近邻法从以往的跟踪结果中找出最准确的结果,但算法只是使用简单机器学习算法对样本进行分类,导致算法的性能不理想、准确率较低。
综上所述,针对无人机视频中目标易受到遮挡、形变等问题,提出一种基于自适应Siamese网络的无人机目标跟踪算法(SiamRAT)。首先,利用两个全卷积网络构建Siamese网络,将2个网络的输出特征进行卷积得到响应图(Response map)从而预测目标位置,采用神经网络模拟相关滤波的整个过程,能够有效提升跟踪精度和速度。然后,利用高斯混合模型对以往的预测结果进行聚类并建立目标模板库。高斯混合模型拥有强大的数据描述能力,能够将相似的数据聚集到一起,并且不同类别之间拥有较大的差异性,从而保证模板的多样性。经过此模型得到的模板库能够让网络充分学习到目标的多种状态信息,提升特征的有效性。其次对每一帧的预测结果进行判别,当模板库中存在类似的样本可以直接替换Siamese网络中模板分支的输入,让算法从以往的跟踪结果中挑选出最可靠的目标状态,以应对目标的外观变化,同时可以避免重复的计算操作。最后,引入回归模型进一步精确目标位置,提升跟踪算法的精确率。仿真实验结果表明,该算法有效降低了形变、遮挡等情况对算法性能的影响,有效提高了跟踪算法的准确度。
1 自适应Siamese网络模型与跟踪算法
针对无人机视频中目标易发生形变、遮挡等问题,提出一种基于自适应Siamese网络的无人机目标跟踪算法。网络共有2个分支,如图1所示。其中网络上半部分为模板分支,下半部分为检测分支,并通过学习相似度函数f(z,x)在空间φ中比较目标模板图像z和当前帧图像x,从中找出与目标模板图像最相似的样本作为预测目标,表达式为
f(z,x)=φ(z)*φ(x)+b
(1)
式中:*表示将两个特征图矩阵进行互相关计算;b为一个偏置,并在每个位置都是相同的。
为了构造有效的损失函数,对响应图的位置点进行了正负样本的区分,即目标一定范围内的点作为正样本,范围外的点作为负样本。对于响应图中每个点的损失函数为
l(y,v)=lg(1+exp(-yv))
(2)
式中:v为每个点的真实值;y∈{+1,-1}为这个点所对应的标签。
对于响应图的整体损失则采用全部点的损失均值,即
(3)
式中:u∈D为响应图中的位置;y(u)表示为

(4)
其中:k为网络步长;c为中心点;R为搜索区域半径。
卷积网络的参数θ使用SGD(Stochastic Gradient Descent)优化去计算:
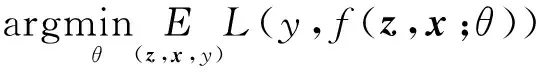
(5)
网络的具体参数如表1所示。最大池化层分别部署在前两个卷积层之后,ReLU非线性激活函数部署在除了最后一层外的每个卷积层之后,BN(Batch Normalization)[13]层被嵌入每个线性层之后,网络中没有填充操作。网络分为2个输入,一个输入目标图像,大小为127×127×3,另一个输入当前帧搜索区域图像,大小为255×255×3,搜索区域为上一帧目标大小的4倍,并将余弦窗添加到响应图中以惩罚最大位移。

图1 自适应Siamese网络模型Fig.1 Adaptive Siamese network model
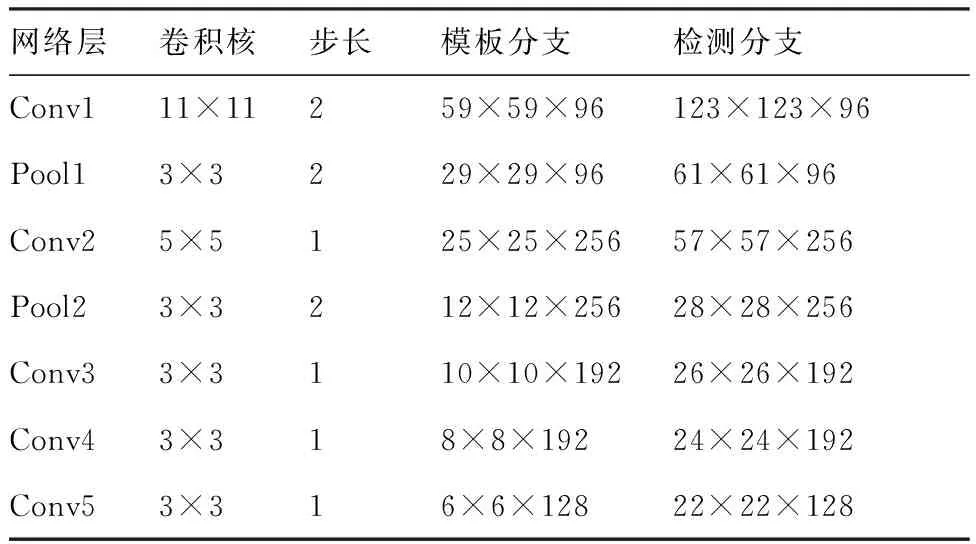
表1 网络参数Table 1 Network parameters
1.1 自适应模板更新策略
无人机在飞行过程中,背景是不断变化的,目标也是运动的,当无人机自身姿态和摄像头视点发生变化时,容易造成拍摄视频中的目标发生形变、遮挡等情况。目前基于Siamese网络的跟踪算法未能将跟踪过程中代表目标各种状态的多个实例样本考虑在内,面对形变、遮挡情况时跟踪准确度还有待提升[14]。由于Siamese网络跟踪算法是基于相似度匹配的跟踪算法,当匹配模板不足以表达当前时间段的目标状态时,就会造成跟踪性能的下降,这就需要对匹配的模板进行更新,以适应跟踪目标的变化。如果每一帧都更新网络的输入模板,不仅会大幅提升计算量,而且会造成模板冗余的情况。针对此问题,提出一种自适应模板更新策略,如图2所示。利用目标在跟踪过程中的多个状态建立实例模型,在时间序列上构建多个实例样本模型,模型之间相互独立,既能重

图2 自适应更新策略Fig.2 Strategy of adaptive update
复表征目标的最新状态,又降低了模型漂移对跟踪算法的影响。
在跟踪过程中,目标不可避免地会发生多种形态变化或者被障碍物遮挡。当发生这种情况时,如果不及时对网络的匹配模板进行更新将会导致算法性能的降低。这就要求跟踪算法能够保存目标的多种状态信息,当目标发生变化时能够及时进行更新,从而保证网络能够适应目标的变化。为了保存跟踪过程中目标的多种状态信息,本文采用高斯混合模型对目标的状态进行建模,高斯混合模型(GMM)是一种广泛使用的聚类算法,该算法使用多个高斯分布作为参数模型并刻画数据分布。相比K-Means,高斯混合模型算法能够提升更强的描述能力,不同类别之间具有较大的差异性,而同一类别的数据相似性大,如图3所示。

图3 不同样本集对比Fig.3 Comparison of different sample sets
设随机变量x,则高斯混合模型可以表示为
(6)
式中:N(x;μk;I)为高斯混合模型中的第k个类型,若有K种类型需要聚类,则可以用K个高斯分布来表示,μk∈X为均值,协方差矩阵被设置为单位矩阵I以避免高维样本空间中复杂计算;πk为混合系数,相当于每个类型的权重,且满足:
(7)
为了提升算法的计算速度,根据Declercq和Piater的方法[15],使用一个简易算法去更新GMM。当得到一个新的预测图像xj,如果为新的类别,则初始化一个新类型样本集m和其中的2个参数πm=γ和μm=xj。当样本类型的数量大于所设定的阈值K时,去掉权值πk最小的那一类,保留当前图像作为新的一类,并设置其权值为中间值,防止漂移现象。如果存在相似模板,则把这两个类型k和l合并为一种类别样本集n,合并方法为
(8)
式中:距离的计算是将其变换到频域中并使用Parseval公式来计算,大大减少时间损耗。
对Siamese网络的匹配模板进行更新可以让网络在跟踪过程中适应目标的变化,提升跟踪的可靠性。若每一帧都更新模板分支的特征,会导致算法每一帧都要进行两个卷积网络的特征提取步骤,这样势必会增加很多计算负担,造成算法速率下降。如何在提升算法性能的条件下,尽可能减少速率的损耗是当前亟待解决的问题。
为了判别当前帧状态是否与之前保存过的状态类似,使用一种感知哈希算法进行简单的状态类别判断。图像中的高频信息可以提供图像的细节内容,低频信息可以描述图像中物体的框架,感知哈希算法(Hash)就是利用图像的低频信息去检测图像相似度的方法。首先将图像通过下采样方法缩小到8×8的尺寸,去除图像的高频信息,同时摒弃不同尺寸图像带来的差异性;其次将图像转化为灰度图像,并计算其灰度平均值;之后将图像中每个像素的灰度值与平均灰度值进行比较,大于等于则记为1,小于则记为0;将这64个比较值组合在一起就构成了这幅图像的Hash指纹。这种计算方法快速高效,不受图像大小尺度的影响。
通过计算两幅图像的Hash指纹,可以快速有效计算两幅图像的相似度,并判断出当前预测图像是否为目标的新状态,将每种状态信息保存下来,不仅可以使网络模型自适应目标的变化,同时可以一定程度上降低模型的冗余度。主要过程为将预测的目标图像从原图像中裁剪下来,计算此图像与模板集中每个模板图像的Hash指纹。由于Hash指纹个数只有64个,当两幅图像的Hash指纹差值<10%时,即两个Hash指纹不同位的个数<6.4,可以认为两幅图像相似度较高;当差值>20%时,即两个Hash指纹不同位的个数>12.8,可以认为两幅图像相似度较低。实验中采用以下判别数值:当两个Hash指纹不同位的个数<5时说明两张图像相似度较高,可以认为是同一状态图像,2个Hash指纹不同位的个数>5且<10时说明两幅图像有些不同,但比较相近,说明是目标的新状态图像,2个Hash指纹不同位的个数>10则说明图像距离较远,相似性程度低,可以判断为是遮挡或跟踪错误的情况,不进行更新操作。
跟踪过程中不可避免地会遇到相似目标的干扰,由于相邻两帧目标的移动距离不会过大,若当前响应图中较大的响应值离中心较远,这时会通过余弦窗进行惩罚,降低该响应值的干扰,从而处理相似目标干扰的情况。
通过状态类别判断和建立模板集2个部分操作之后,可以生成最适合当前帧的精确目标模板,因而将此模板替换网络中模板分支的输入,可以使网络自适应目标的各种状态变化,提升网络性能。自适应模板更新策略的主要过程如下:
1) 使用第1帧目标图像建立高斯混合模型,并定义为第1类目标状态。
2) 计算每一帧预测结果与所有模板图像的Hash指纹,计算其不同位的个数。
3) 如果不同位的个数<5,则认为与此模板类似,直接将此模板特征作为下一帧的模板特征。
4) 如果不同位的个数>5且<10,则建立或更新高斯混合模型,并利用模板分支提取此特征。
5) 如果不同位的个数>10,则不考虑此图像。
1.2 区域建议回归模型
基于Siamese网络的跟踪算法仅仅考虑响应图中最大响应点,而忽略了其他响应点重要性,没有对其进行综合考虑,这样可能会降低对目标位置预测的精确性。同时在尺度方面,大多数算法只取几个不同的系数对目标尺度进行预测或借鉴R-CNN[16]中的回归思想对目标周围截取大量图像进行回归预测来定位目标的精确位置。前者算法只是对目标尺度乘以不同的尺度系数,并找出响应值最高的尺度框作为目标的最终位置,当目标发生较大尺度变化时缺少相应的尺度系数,预测能力显著降低;后者算法在回归预测环节提取大量图像样本特征,增加算法的运算量,降低算法效率。针对以上问题,提出一种基于区域建议的回归模型,提取响应图中高于一定阈值的响应点,得到包含目标信息的候选图像,并放入训练好的回归模型进行位置预测,能够在不损失过多性能下降低算法复杂度,提升算法效率,同时还能提升目标位置准确性。

传统的回归模型在回归预测阶段也会提取大量的样本图像做回归预测得到最终目标框,大量的样本图像导致算法的计算量大幅增加,降低算法效率。针对此问题提出一种基于区域建议的回归模型。首先,使用视频中第1帧图像的Conv5层特征训练回归模型并得到回归函数,之后提取Siamese网络的目标实例特征和当前帧的图像特征进行互相关计算,得到17×17大小的响应图,提取响应图中高于阈值的响应点作为待预测的目标中心点,根据上一帧的目标尺度大小得到每个中心点的目标框,之后把每个目标框内的图像送入回归模型进行预测,最终得到目标的精确位置信息,如图4所示。此模型与传统回归模型中在预测环节提取目标周围大量的样本图像相比,降低了预测环节中输入图像的数量,降低了算法的计算量,在不损失过多性能的条件下提升了算法效率。

图4 基于区域建议的回归模型Fig.4 Regression model based on region proposals
1.3 跟踪算法步骤
步骤1利用模板分支提取第1帧目标图像特征fe,之后提取目标周围N个样本图像的Conv5特征训练回归模型。
步骤2利用检测分支提取当前帧图像中搜索区域的图像特征fi。
步骤3对特征fe和fi进行互相关计算得到响应图。
步骤4提取响应图中高于阈值的响应点图像作为预测回归的样本图像,利用区域建议回归模型得到回归后的目标图像。
步骤5计算当前帧预测结果与模板库图像的相似度,建立或更新高斯混合模型,并得到最适合当前目标状态的模板图像。
步骤6若当前状态为新状态则通过模板分支提取目标特征作为新的fe,若为旧状态则直接替换Siamese网络的模板特征。
步骤7重复步骤2~6直到视频结束。
跟踪算法流程如图5所示。
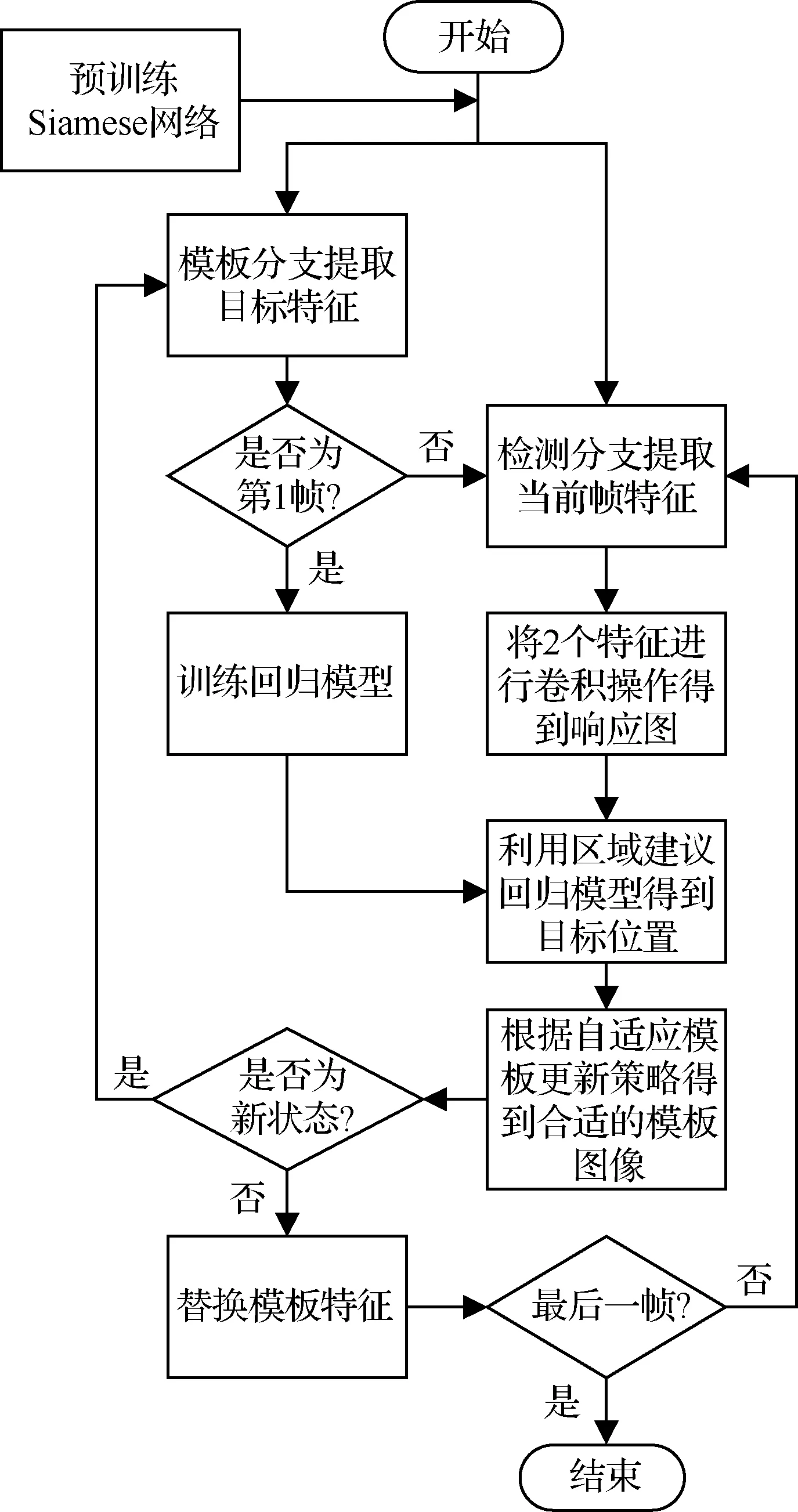
图5 跟踪算法流程图Fig.5 Flowchart of tracking algorithm
2 仿真实验
2.1 实验数据
为验证本文算法的有效性,选取UAV123数据集和无人机实际采集的视频图像序列作为测试数据集。UAV123[17]数据集包含123个视频序列,涉及12种属性变化,主要涉及无人机在低空环境下对目标的拍摄场景,由于无人机拍摄的角度与高度不一致,导致目标角度多变及尺度多变,挑战难度也很大。实验采用跟踪成功率和跟踪精确率2个通用的评价指标来进行定量分析。跟踪成功率反映跟踪得到的目标框和给定的实际目标框的重叠程度大于给定阈值的视频帧数占总视频帧数的比例,因此,随着对重叠程度的要求越高,即阈值越大,反而成功率曲线不断下降。跟踪精确率反映跟踪得到的目标中心位置和给定的实际目标中心位置的距离小于给定的某个阈值的视频帧数占总视频帧数的比例,因此,随着阈值的增大,精确率曲线不断上升。其中图例中的数字分别表示中心位置误差取值为20时对应的跟踪精确率和覆盖率取值为0.5时对应的跟踪成功率。
实验中,训练数据集为ILSVC-2015_VID,包含4 500个视频,100万张有标注信息的图像。实验平台为Inter core i7-7700K CPU 4.2 GHz,GPU为GeForce GTX 1070 8 G,训练采用MatConvNet工具,迭代50次,每次迭代包含5 000个样本对,每次迭代的mini-batch设置为8,学习率为10-2~10-5,算法跟踪速率约为20帧/s。其中所对比算法的结果均为其论文中的结果或其开源程序在上述实验平台上的结果。
为了降低网络过拟合的影响,在网络训练阶段使用ILSVC-2015[18](ImageNet Large Scale Visual Recognition Challenge)目标检测数据集。ILSVC-2015数据集中包含一些目标占据整个画面的视频,而这些视频不符合真实场景的跟踪任务,所以对这些视频进行筛选,最终选出4 500个视频,大约包含100多万标注过的视频帧图像。这个数据集不仅拥有庞大的规模,而且与标准跟踪数据集中的目标和场景不同,所以可以尽量减少过拟合的影响。
2.2 实验结果与分析
为验证所提算法(SiamRAT)在目标发生遮挡、形变等情况下的有效性,将所提算法与SiameseFC、STRCF[19]和EAST[20]算法进行对比,其中STRCF和EAST是针对形变、遮挡情况而改进的跟踪算法。实验数据采用UAV123@10fps数据集中发生遮挡、形变的视频,共60个。实验结果如表2所示。在形变、遮挡场景下,相比于单实例模型的SiameseFC跟踪算法,所提算法能够有效提升22.65%和31.51%的精确率,同时优于其他改进算法。这其中的原因一方面是跟踪算法建立在多个状态实例样本之上,相比于建立在单个实例样本之上的SiameseFC跟踪算法,抓住了跟踪目标特有的状态信息,能够更好地适应目标的形变;另一方面,通过对状态信息的判别,有效降低了遮挡情况对跟踪性能的影响,相比于利用时间正则化对遮挡情况处理的STRCF算法,所提算法避免了多次的参数更新,利用哈希感知算法有效判别遮挡情况,故能提升算法速率并有效减轻遮挡对算法性能的影响。
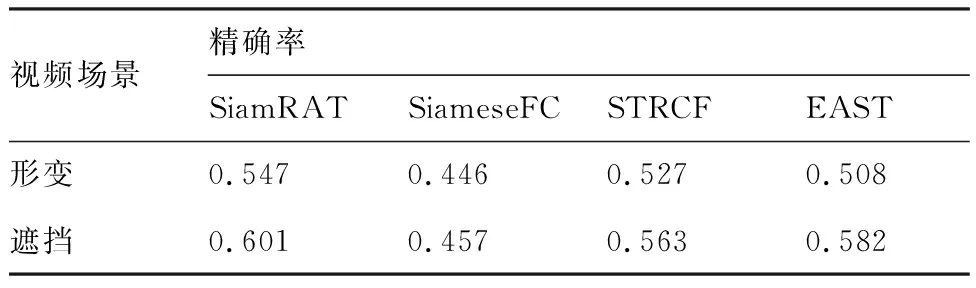
表2 针对形变、遮挡情况的算法精确率对比
为验证所提算法在实际任务中的有效性,在实际采集的4个无人机视频中使用了4种算法进行对比分析,结果如图6所示。前2个视频中跟踪目标为大巴车和黑色小轿车,在跟踪的过程中被遮挡物遮挡,影响了部分算法性能,当目标离开遮挡物时,所提算法能够稳定跟踪目标;后2个视频中跟踪目标为骑车的人和卡车,由于目标行径方向发生改变,造成视频中目标状态发生了变化,使得当前状态与第1帧的目标状态有很大区别,而所提算法由于在跟踪过程中动态更新模板,使得算法依然能够稳定跟踪目标。
为验证自适应更新策略的有效性,在所提算法(SiamRAT)的基础上去掉自适应更新部分,使用UAV123数据集进行测试分析,如图7所示。其中2种算法分别为所提算法和不自适应更新目标状态的算法(Not Updated)。结果表明:所提算法能够有效提升15.24%的成功率和7.26%的精确率,从而可以证明自适应更新的Siamese网络模型是有效的。不论从精确率还是从成功率来看,不加入自适应模板更新策略的算法性能都下降很大,说明模板的更新对跟踪性能至关重要。

图6 部分视频仿真结果图Fig.6 Results for partial video simulations
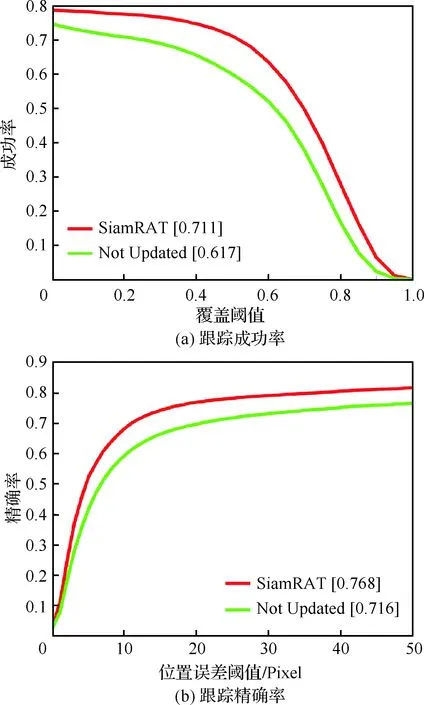
图7 对比分析Fig.7 Comparative analysis
2.3 算法比较
为了验证所提算法(SiamRAT)的有效性,选取UAV123数据集中的123个视频序列作为测试序列,对所提算法进行测试,并与文献[21-29]中主流跟踪算法进行实验效果对比,对比算法包含ECO、ECO-HC、SRDCF[21]、MEEM[22]、SiameseFC、MUSTER、SAMF、Struck[23]、DSST[24]、TLD[25]、ASLA[26]、CSK[27]、SiamRPN[28]、DSiam[29]。分别采用跟踪成功率和跟踪精确率的评价指标来进行定量分析,不同场景下跟踪性能比较结果如图8所示,比较场景分别为摄像机移动、视角变化、部分遮挡、完全遮挡、宽高比变化、尺度变化,在UAV123数据集下整体性能比较如图9所示,场景名称后的数字代表此场景的视频序列数量。
面对这些较为复杂的场景,通过对图8中的对比结果进行分析可以发现:所提算法在视角变化、遮挡、形变、尺度变化等场景下具有较好的性能,能够较好地处理这些视频,并对于其他场景下的测试视频,所提算法的性能也是较好的,这也充分验证所提算法在跟踪准确性、稳定性和鲁棒性方面具有优异的整体性能。其中的主要原因是采用了基于自适应Siamese网络结构,跟踪算法在不同时期建立在不同的实例样本之上,抓住了跟踪目标在不同状态下特有的状态信息,相比于只建立在单个实例模板上的SiameseFC算法,能够更好地适应目标的各种变化,整体效果提升大约18%。从图9也可以看出所提算法(SiamRAT)整体的跟踪成功率为0.725,精度为0.771,其原因主要是由于采用了回归模型进行目标位置预测,极大地提高了跟踪精度和目标位置的准确性,同时基于区域建议的回归模型能够在不损失过多性能的情况下减小计算量,提高跟踪速率。所提算法在所有算法的比较中性能只略低于SiamRPN算法,其原因主要是训练集的大小相差过大,若使用更大的数据集进行训练,算法性能会有一定的提升。
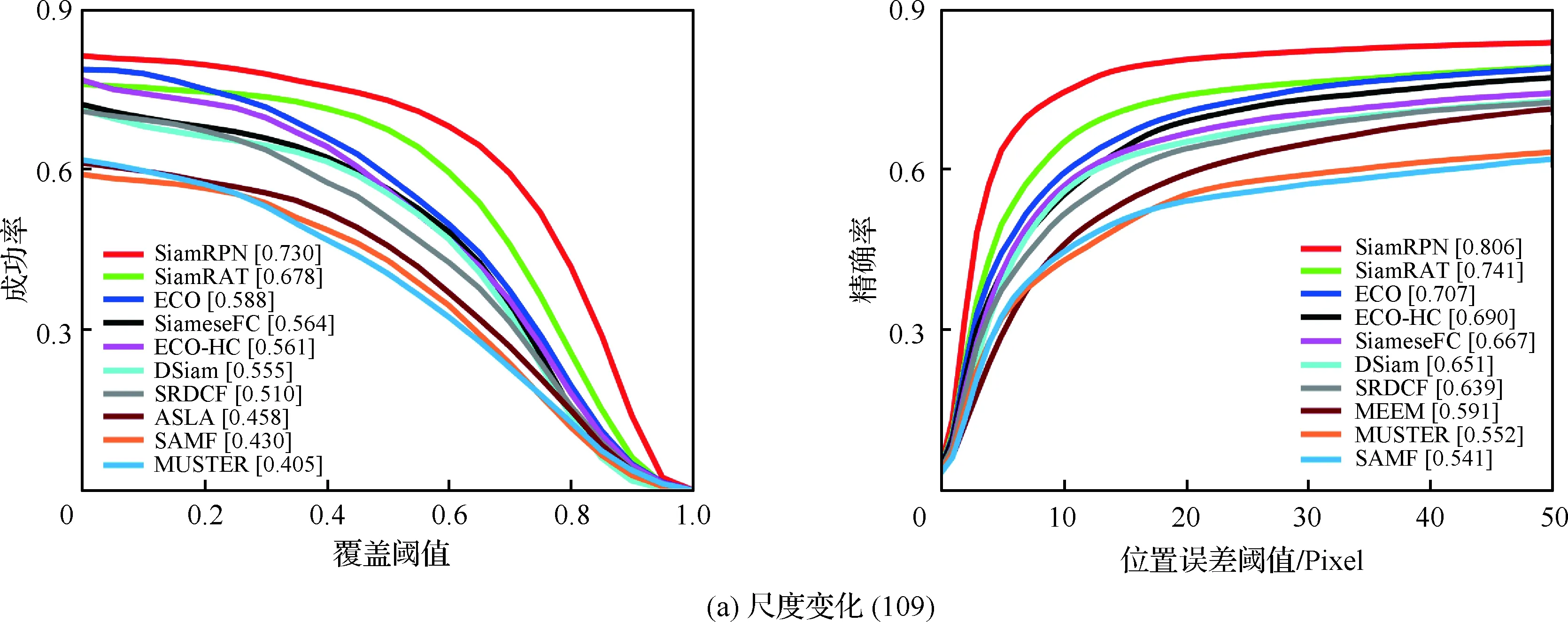

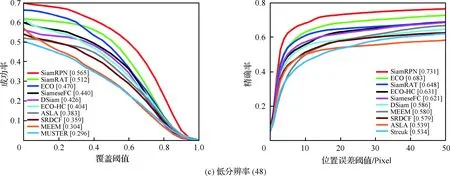

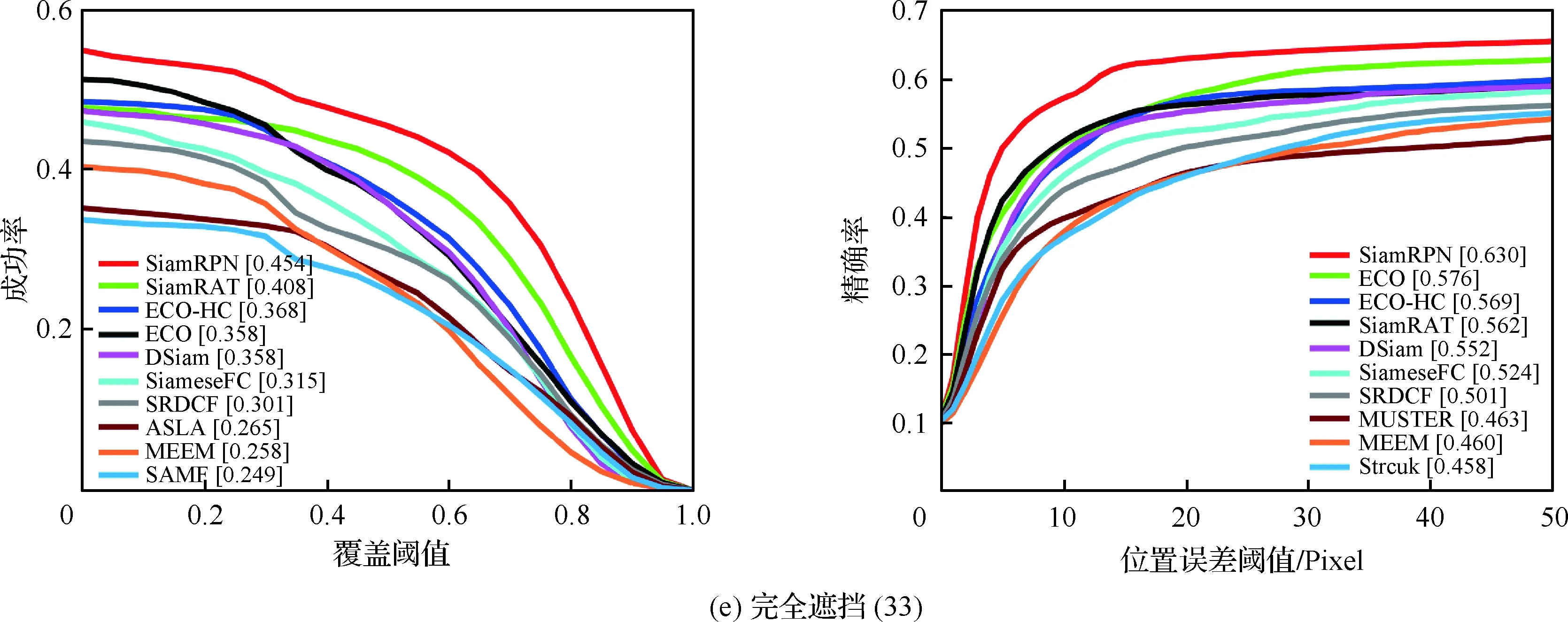
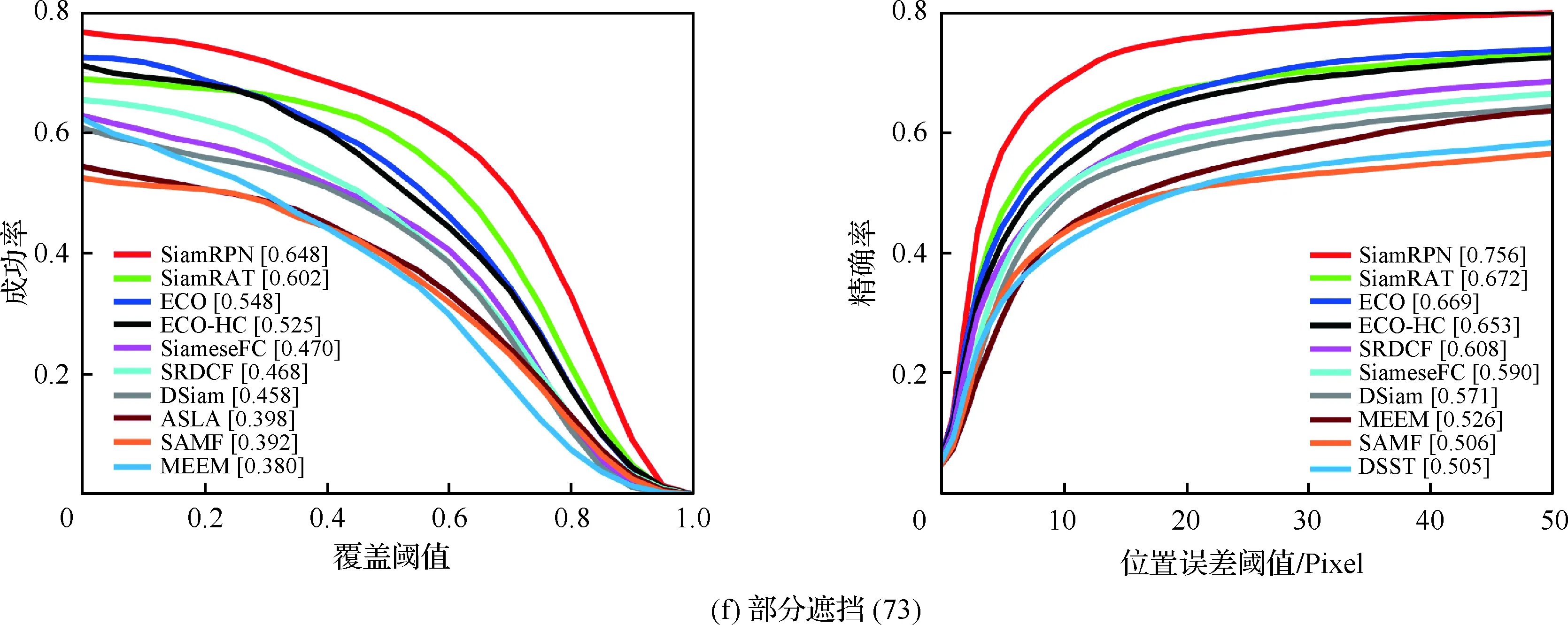
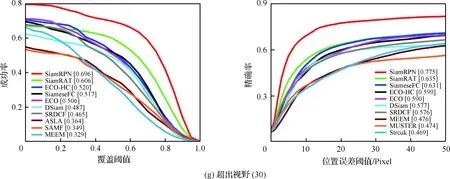
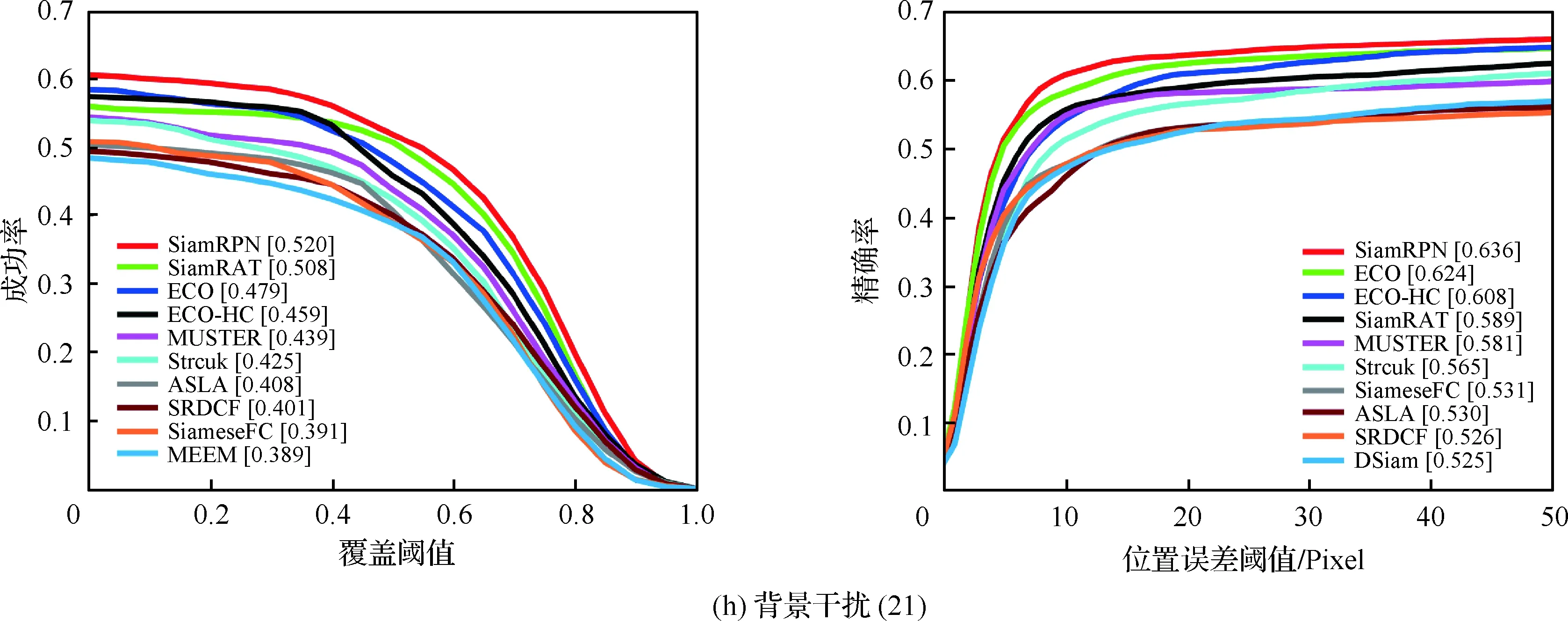


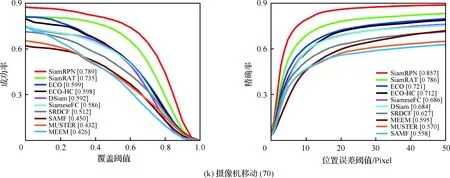

图8 不同场景下的性能比较Fig.8 Comparison of performance in different scenarios
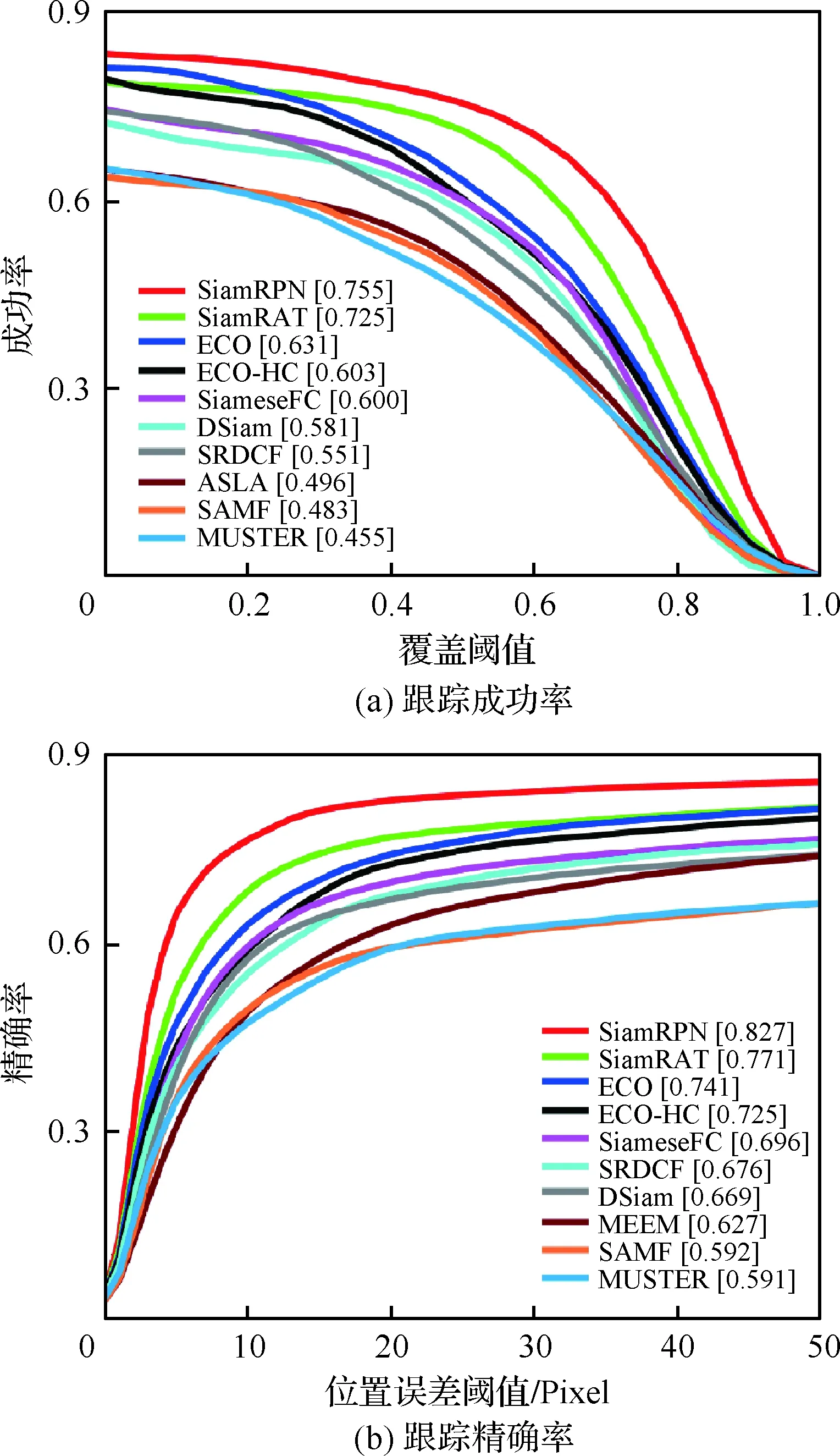
图9 整体性能比较Fig.9 Overall performance comparison
3 结 论
针对无人机视频中目标易发生形态变化、易被遮挡等问题,提出了一种基于Siamese网络的无人机视频目标跟踪算法。
1) 针对无人机视频中目标易发生形态变化、易被遮挡等问题,需要较准确的目标模板信息以供算法预测目标,结合Siamese网络和自适应策略构建了自适应Siamese网络模型。
2) 根据所构建的模板图像集对每一帧所预测的目标进行处理优化,得到较为精确的目标模板,代替网络中第1个分支的模板图像,较好地提升了网络对目标变化的适应性,同时引入回归模型提升了预测准确度和精确度,降低了周围背景对网络性能的影响。
