基于测绘地理信息技术的山洪质灾害信息动态提取方法研究
2020-03-01陈济才李国明
陈济才 李国明
摘要:随着网络技术迅速发展,海量数据分布在万维网内,如何从数据中挖掘到特定的需要的数据成为时下研究的热点。网络爬虫是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。本文探讨使用网络爬虫的概念和方法,开发基于互联网的聚焦网络爬虫软件,迅速通过互联网搜索山洪灾害点相关及时的第一手资料,形成对灾害的第一认识。再经过人工判读,精确动态提取、更新山洪灾害信息专题成果。
关键词:万维网;聚焦网络爬虫;山洪灾害;动态提取
1.引言
随着网络的迅速发展,万维网成为大量信息的载体。网络信息更新及时,传递速度快,只要信息收集者及时发现信息,就可以保证较强的信息时效性。面对海量数据,如何有效地提取并利用这些信息成为一个巨大的挑战。定向抓取相关网页资源的聚焦爬虫可提取特定的需要的信息。
网络爬虫(又被称为网络机器人,网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
物联网蕴含了大量的动态灾害信息,是及时获取目标区域灾害点信息的重要途径。传统搜索引擎技术缺乏基于空间语义的认知和推理能力,无法识别灾害发生的空间位置信息,无法提供基于互联网的区域化灾害动态监控服务。本文基于聚焦网络爬虫有效收集网络上的灾害信息,精准过滤反映灾害信息内容的网页,获取灾害事件的时间、空间位置以及灾害点信息。依托该系统,可结合传统的人工判读技术,依据地物波谱特性、空间特征和成像机制以及所掌握的地学规律,通过分析地物影像特征来识别灾害点,准确提取、更新灾害信息专题数据,及时发布,辅助决策者参考使用。
2.聚焦网络爬虫概述
聚焦网络爬虫可以在较短的时间里,使用较少的硬件资源,获取到更多与主题相关的信息。
相对于通用网络爬虫,聚焦爬虫的工作原理较为复杂,根据一定的网页分析算法过滤掉主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
本文网络爬虫引擎采用聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网络爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
3.山洪灾害信息
山洪是指山区溪沟中发生的暴涨洪水。山洪具有突发性,水量集中流速大、冲刷破坏力强,水流中挟带泥沙甚至石块等,常造成局部性洪灾,一般分为暴雨山洪、融雪山洪、冰川山洪等。山洪灾害常伴有山体崩塌、山体滑坡、泥石流等。山洪灾害信息是救灾工作的重要决策依据,直接关系到自然灾害应急处置、救援救助等救灾工作的有效开展。
4.基于聚焦网络爬虫的灾害信息动态提取方法研究
开发基于互联网的网络爬虫软件,能迅速通过互联网搜索灾害点相关及时的第一手资料,形成对灾害的第一认识。通过已开发的网络爬虫软件,能将所有与某一主題相关的所有信息罗列并进行综合分析筛选。
通过借鉴国内外语义相似度在信息检索方面的研究成果,开发基于互联网的网络爬虫软件,从各类信息数据库中巨大的新闻事件类文本数据中及时发现并提取灾害专题新闻报道信息。结合高分遥感影像数据、基础地理信息矢量数据,辅以人工判读,以确定各灾害专题信息发生的空间们位置信息,输出灾害信息动态提取成果专题图,为灾害信息动态更新提供服务。具体的技术路线参见下图。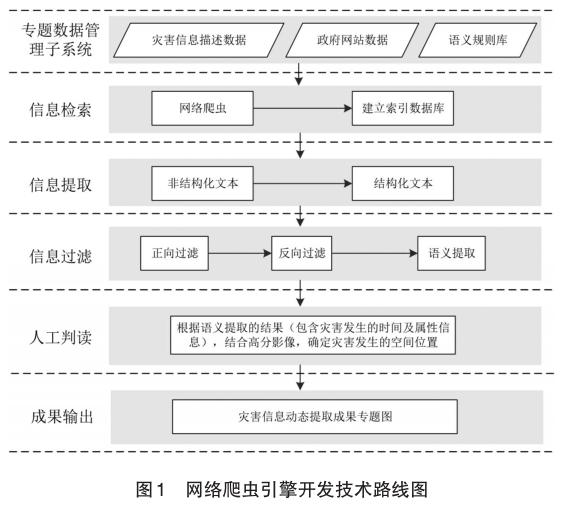
(1)专题数据管理子系统
负责灾害信息描述数据(如泥石流、山洪、暴雨、地震等)、政府网站数据(网络爬虫目标网站)、语义规则库(灾害专题信息检索模型的研究成果)的维护和更新。
(2)信息检索
利用网络爬虫工具,从政府网站中抓取相关网页并收集到本地,经过加工处理建立本地网页快照库,对本地网页快照库进行分析、整理,针对灾害信息描述关键词建立一种利于快速查找的数据结构即索引,并建立索引数据库,以便在抓取到的网页中进行快速深入的灾害信息提取。
(3)信息提取
网页信息数据库中存储的是HTML格式的文档,这类文档通常含有很多与网页主题信息不相关的内容,比如导航条、广告信息、版权信息等内容,它们只适合使用网页浏览器进行浏览,而不宜作为数据交换方式由计算机处理。因此,需要开发网页主题信息提取工具,从HTML这类非结构化的文档中提取出主题信息,输出并保存为结构化的文本,以便于对其进行下一步的分析处理。
(4)信息过滤
通过网页主题信息提取后获取的结构化文本数量多、数据冗余度高、不包含有效灾害信息描述的文本比重高,需要采用正向过滤(文本中必须包含的关键词组合)、反向过滤(文本中不能包含的关键词组合)等技术手段尽可能删除那些不包含有效灾害信息的文本。最后,根据灾害专题信息检索模型,从剩下的文本中检索并提取出有效的灾害信息描述内容。
(5)人工判读
通过软件自动提取到的灾害信息属性并不精确,需要后期进行人工辅助判读,结合高分影像,确定灾害发生的具体位置、进一步明确灾害属性信息,同时剔除通过程序获取到的重复信息。人工判读确认的灾害信息主要包括空间信息及属性信息。空间信息包括灾害发生的位置信息及灾害发生的几何类型;属性信息包括灾害分类、灾害发生时间信息、灾害发生的区域、灾害发生的文字描述等信息。
(6)成果输出及发布
经过人工判读后的灾情信息是比较准确的,可直接用于更新灾害专题信息数据库。结合其他影像、矢量等数据发布灾情信息动态提取成果专题,将山洪灾害信息及时发布并打印输出。
同时提供网络调用的服务接口,能通过设置地名关键词、灾害类型、发生时间范围、行政区域或坐标范围等筛选条件,可以将某一个位置周围的历史灾害相关信息全部罗列出来供决策者辅助参考。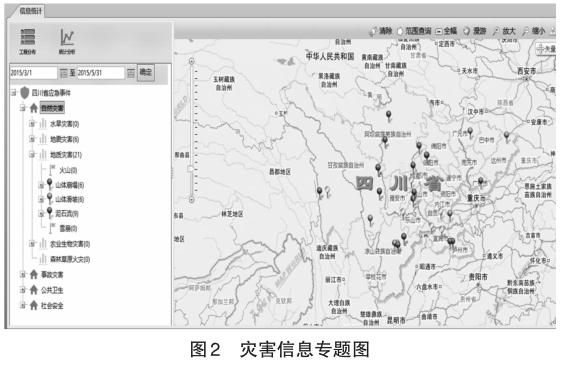
5.结语
在山洪灾害信息提取中,基于聚焦网络爬虫方法对物联网中海量数据信息利用程度较高,能够综合考虑灾害事件的时间、空间位置以及灾害点信息,快速获取第一手资料数据,再结合人工判读,即可精确动态提取、更新山洪灾害专题成果。也可以采集往年信息,建立预报模型,预测未来灾害发生区域,灾害种类等,可为决策者提供预防。本文基于聚焦网络爬虫,通过动态提取灾害信息,结合人工判读,研究了山洪灾害信息的提取、更新方法,可为决策者提供辅助依据。本文关于采集往年信息,建立模型,预测未来灾害发生区域、灾害种类,未作进一步研究,希望拋砖引玉,引发一些思考。
参考文献:
[1]袁文,袁武,张海冬.基于互联网的区域性灾害空间信息动态监测技术[C].国家综合防灾减灾与可持续发展论坛, 2010:200-207.
[2]程向荣.分析测绘技术在地质灾害中的作用[J].西部资源, 2018(01):123-124.
[3]YADAV P,KALRA M M,YADAC K P.Enhancing the performance of web focused crawler using ontology [J].International Journal of Computers & Technology, 2013:4(2):477-482.
[4]RUNGSAWANG A,ANGKAWATTANAWIT N.Learnable topic specific web crawler[J].Journal of Network and Computer Applications,2005(28):97-114.
[5]MENEZER F.Complementing search engines with online web agents [J]. Decision Support Systems Archive, 2003, 35:195-212.
[6]孙立伟,何国辉,吴礼发.网络爬虫技术的研究:电脑知识与技术, 2010.
[7]张玉东,郭俊锋,王林生.测绘技术在地质灾害中的作用[J].科技与企业, 2012(20):251+253.
[8]尹训志,王俊亮,张杰.测绘技术在地质灾害中的作用探究[J].大科技, 2018, 000(030):221-222.
