Big Data Analytics in Telecommunications: Literature Review and Architecture Recommendations
2020-02-29HiraZahidTariqMahmoodAhsanMorshedandTimosSellis
Hira Zahid, Tariq Mahmood, Ahsan Morshed, and Timos Sellis,
Abstract—This paper focuses on facilitating state-of-the-art applications of big data analytics (BDA) architectures and infrastructures to telecommunications (telecom) industrial sector.Telecom companies are dealing with terabytes to petabytes of data on a daily basis. IoT applications in telecom are further contributing to this data deluge. Recent advances in BDA have exposed new opportunities to get actionable insights from telecom big data. These benefits and the fast-changing BDA technology landscape make it important to investigate existing BDA applications to telecom sector. For this, we initially determine published research on BDA applications to telecom through a systematic literature review through which we filter 38 articles and categorize them in frameworks, use cases, literature reviews, white papers and experimental validations. We also discuss the benefits and challenges mentioned in these articles. We find that experiments are all proof of concepts (POC) on a severely limited BDA technology stack (as compared to the available technology stack), i.e.,we did not find any work focusing on full-fledged BDA implementation in an operational telecom environment. To facilitate these applications at research-level, we propose a state-of-the-art lambda architecture for BDA pipeline implementation (called LambdaTel) based completely on open source BDA technologies and the standard Python language, along with relevant guidelines.We discovered only one research paper which presented a relatively-limited lambda architecture using the proprietary AWS cloud infrastructure. We believe LambdaTel presents a clear roadmap for telecom industry practitioners to implement and enhance BDA applications in their enterprises.
II. INTRODUCTION
THE telecommunications (telecom) industry is facing an avalanche of data on a daily basis due to smart phone usage and boom of social media and IoT along with availability of next generation communication networks. Data occurs in both batch and real-time modes. Notable data examples are call detail records, user clickstream, mobile network usage,geographical user data, network performance, network monitoring, customer/subcriber profiles, hardware and VOIP data.In telecom, big data can be characterized by the standard 3V’s:volume, variety and velocity[1]-[4]. The value of this data(generally the 4th V) is Big Data Analytics (BDA) [5], [6]which is the process of extracting valuable insights from big data streams that can help align business strategies to meet critical KPIs. BDA can harness big data for telecom by employing knowledge from diverse domains notably machine learning, statistics, pattern recognition, and business intelligence. BDA is mostly implemented in the context of NoSQL databases which tear away from the tight relational storage to more loose, unstructured and semi-structured data models [7],[8]. Well-known examples include MongoDB (which stores data as JSON documents) and Redis (which stores data as key-value pairs), along with Apache Hadoop and its ecosystem [2], [9], [10]. These databases are capable of addressing the ACID (Atomicity, Consistency, Integrity and Durability)requirements of relational databases [8]. In telecom, BDA can enhance customer relationship management through more efficient resource management, identification of root causes of service failure, more intelligent marketing campaigns, boosted-up sales, detection of high-velocity fraud activities in real time, and timely inception of new business partnerships [5],[11].
BDA is an expensive, resource-intensive and a complicated process which is plagued by many problems leading to significant project failures in different industries [5], [6],[12]-[19]. According to Gartner, up to 85% of BDA projects were failing in 2017 [15]. A McKinsey survey has determined the impact of investment in BDA initiatives by telecom companies on the actual benefits; of the 273 telecom companies who invested in BDA, only 5% companies are getting more than 10% benefit. Also, 75% to 80% companies ran into a loss due to BDA application [11]. The more important problems in BDA initiatives are lack of data quality,poor data management, mistakes in selecting the analytical model, lack of an existing BDA infrastructure, lack of expenditure, making non-scalable BDA infrastructures,difficulty in creating a roadmap for BDA skills, and a rising complexity in integrating heterogeneous big data [20]. The BDA landscape is also increasing at an exponential pace;termed as “firing on all cylinders” in industry [21]. Hence, the speed of innovation largely outpaces the speed of adoption.Most of these tools are open-source initiatives and require expert skills to understand and employ directly in an operational environment. This time for learning slows down adoption and demotivates a majority of businesses to invest in BDA [5], [6], [17], [22].
BDA complexity is another challenge. In a BDA process, a considerable number of activities/tasks are executed as apipeline. Each of these activities can be implemented through an increasing diversity of both open-source and proprietary tools. There is a lack of skilled BDA pipeline developers due to the diversity of tasks to be performed, e.g., data upload,data transformation/clearning, statistical analysis,communication of the back-end activities with front-end GUIs, along with different types of analytics and visualization activities. Each tool has a learning curve, and the problem becomes severe when BDA developers need to integrate several tools together in the same pipeline. Moreover, the BDA pipeline runs perpetually until the analytical requirement is fulfilled, which requires the automation of core tasks like ETL and Machine Learning. The progress and now the domination of Python as a pipelining language has largely facilitated development of BDA pipelines in the last decade[20]. Some tools have also matured and have seeded the rise of BDA applications in telecom, for instance, MongoDB,Redis, Hbase, Spark, Flink, and Hadoop (described in Section 2). Due to these technologies, the BDA applications in telecom are increasing and likely to increase further [5], [6],[23], [24]. For instance, BDA can identify traffic delay sensitivity and accurate identification of small packet traffic,and brings much-reduced delay and processing complexity from data [25]-[28].
In this paper, our intent is to determine the extent to which the huge potential of BDA has been realized by the telecom sector in academic research, and to identify and address the concrete challenges. We focus on academic research because the fast-changing BDA landscape leaves much space for formal research activities and projects to determine the impact of BDA tools on telecom. In other words, we want to gauge the actual benefits of BDA that the research community has brought to the telecom sector. For this, we formulate three research questions:
1) RQ1:How much research literature is focused on BDA applications to telecom sector and what is the BDA technology stack in these articles?
2) RQ2:What are the benefits and challenges mentioned in these articles and how much benefit has been actually realized?
3) RQ3:How can the challenges be strongly addressed to facilitate BDA applications to telecom sector?
To investigate these questions, we conduct a Systematic Literature Review (SLR) according to standard guidelines[29], [30]. To the best of our knowledge, this is the first SLR application for telecom sector. We have modeled the SLR and this paper from a big data perspective and avoid any operational detail of telecom domains and technologies. For this latter knowledge, we refer the readers to [31], [32]. Later on, we address the BDA challenges in telecom by proposing and describing a comprehensive, state-of-the-art BDA architecture called LambdaTel for telecom practitioners.
II. BACKGROUND
Gartner defines big data as “high volume, high velocity and high variety information assets that demand cost effective,innovative forms of information processing for enhanced insight and decision making” [33 ]. Here, four properties pertinent to our SLR are: 1) Volume is the large size of big data reaching generally from terabytes and petabytes, 2)Velocity is the speed of data generation and required processing of both batch and real-time data, 3) Variety is different types of data from heterogenous data sources,grouped as structured, unstructured and semi-structured data,and 4) Value indicates the hidden, previously unknown information or knowledge in data that is potentially useful for business decision making. The process of extracting value from big data sets is called big data analytics (BDA) [5], [6],[12], [13].
A. Apache Hadoop and MapReduce
A big challenge facing telecommunication companies today is the difficulty of employing a software and hardware infrastructure to handle big data. Apache’s Hadoop is an open source framework used for distributed processing of big data across a cluster of commodity hardware [34]. Each Hadoop cluster is highly available and fault tolerant. Hadoop version 2.x is a three-layered model classified as storage layer,processing layer and management layer (Fig. 1) described as follows. HDFS is Hadoop’s file system which provides faulttolerance and high throughput over low-cost commodity hardware. Large files are split into smaller blocks in a redundant fashion to achieve fault tolerance and stored across multiple machines to provide easy access. HDFS also provides file permission and authentication rights.MapReduce is the batch processing framework which works over Hadoop based on divide and conquer rule. It comprises of a ‘Map’ and ‘Reduce’ function. Input key-value pairs process during map step which generates intermediate keyvalue pairs. Then, all the intermediate values related to the same key will combine so that reduce function is able to access them and compress the value set into a smaller set.Overhead of steps like data scheduling, fault-tolerance, and inter-node communications are eliminated in MapReduce[18]. YARN is Hadoop’s resource management framework which abstracts MapReduce from managing resources (as was the case in Hadoop version 1.x). Finally, we have the common utilities which are components needed to operate Hadoop submodules and projects. Shared libraries support other operations like error detection, compression codes implementation, and I/O utilities etc.

Fig. 1. Hadoop V2.x Architecture.
Hadoop’s data management occurs through a master-slave architecture (Fig. 2). Master is called Name Node and slaves are Data Nodes. Name Node manages the file system name space, regulates clients access to files and executes file system operations such as renaming, closing, and opening files and directories. Data nodes perform read-write operations on HDFS, as per client request. They also perform operations such as block creation, deletion, and replication. Name Node runs the Job Tracker process to process MapReduce tasks that distributes and assigns work to Task Tracker daemon processes running on Data Nodes. The Hadoop ecosystem is a set of software APIs available as open source Apache projects which use Hadoop to provide different functionalities, e.g.,database (Hbase), data warehouse (Hive), SQL Querying(Hive and Drill), stream processing (Spark, Storm, Flink),machine learning (Mahout, H2O), MapReduce programming(Pig) and cluster coordination (Zookeper) [34]-[36]. The ecosystem relevant to our SLR is:

Fig. 2. Master slave architecture of hadoop.
1) Apache Hbase:This is Hadoop’s database built on HDFS[37]. It is capable of providing real-time read and write operations on big data sets stored as a wide columnar store(discussed below). In Hbase, data is stored column wise, with each row having a sorted key indexed with timestamp.Columns can be grouped together to formcolumn familieswhich can be grouped insuper column families.These column families are the basic units for access control. The time stamps are 64-bit integers to maintain different editions for a cell’s content in Hbase. Clients flexibly determine the number of cell editions stored. These editions are sequenced in the descending order of time stamps, so the latest edition will always be read. Fig. 3 shows column families overvoiceandsmsentities being grouped into a single super column family.
2) Apache Hive:Hive provides the SQL interface and a relational model for big data processing over Hadoop [34].Hive is also considered a data warehousing application infrastructure on top of Hadoop that provides summarization,query and analysis.

Fig. 3. A snapshot of a super column family for the choice of services. (Adapted from [35]).
3) Apache Pig:Pig Latin is an ETL-level language which facilitates textual programming, parallel execution and optimization of complex tasks comprised of multiple interrelated data transformations, by encoding them as data flow sequences [34]. It also provides users the facility to encode their own user defined functions.
4) Apache Spark:Spark is an execution engine in which data streams are interpreted as a series of deterministic batchprocessing jobs, making traditional MapReduce 100 times faster [38]. Spark is based on master/slave architecture.Master instance runs on user-defined driver program and can launch a set of workers in the cluster and read data from HDFS. Spark uses resilient distributed datasets (RDDs) that are partitioned across multiples machines to achieve faulttolerance and slaves create partitions on RAM for RDDS as defined by the driver program. Spark Streaming is a Spark API for stream data processing.
5) Apache Kafka:Kafka is an ingestion API which processes real-time data streams and stores them into the queue [39]. Each queue has a topic component and it is a user defined category. The topic decides which event put in which queue. As events arrive randomly, they are sorted and arranged in a queue so that they consumed by the message broker component easily, which are servers consuming the queue. Servers can be based on Apache Spark, Apache Flink or Apache Storm.
6) Apache Flink:Flink is a data flow streaming engine and implements “true streaming” in that the whole job is deployed concurrently in the cluster [40]. Operators in the long run continuously consume input and produce output. These output tuples are immediately forwarded to further processing by next level operators which enables pipeline parallelism.
7) Apache Storm:Apache Storm is a distributed realtime computation system which can reliably process data streams[41]. In Storm, spouts represent information sources and bolts represent data manipulations. Storm architecture is a processing pipeline modeled as directed acyclic graph with spouts and bolts as vertices and data streams as edges.Streams can be repartitioned as per need to enhance efficiency(over a million tuples processed per second per node). It is efficient, fault-tolerant and can integrate with database sources.
Spark Streaming, Flink, Storm (along with Kafka ingestion)have successful use cases in realtime analytics, online machine learning, continuous computation, distributed RPC,and data preprocessing (ETL). From SLR, we found that social network analysis (SNA), machine learning, stochastic modeling, data mining, cluster computing and cloud computing have been proposed/applied. As these domains are vast and generally well-known we do not present any background here.
B. Big Data Storage Technologies
NoSQL (Not Only SQL) is a new breed of databases that address the high scalability, complexity, and elastic schema requirements of big data [42]. They allow storage over four data models:wide columns, documents, key-value pairs, andgraphs. Initially NoSQL compromised somewhat on ACID,formalized through CAP (Consistency, Availability and Partition Tolerance), i.e., given a tolerance to definite partitioning of nodes through system failures, we can provide availability at cost of consistency, or vice versa. In the case of latter, the system was in BASE, i.e., basically available in a soft (temporarily inconsistent) state which will eventually become consistent with time. CAP and BASE are still used in NoSQL, e.g., in Amazon’s DynamoDB which forms the storage backbone of Amazon Web Services. However,NoSQL now largely caters for ACID in powerful databases such as MongoDB and Redis [42].
We now define key-value, columnar, document and graph stores with examples of telecom data as shown in Fig. 4.
1) Key-Value Data Stores:In key-value stores, data is input and accessed using key-value pairs. Keys are randomly generated and value can be any data type associated with inbuilt database objects. Notable examples include Redis and DynamoDb. Keys are stored in hash tables and logically grouped into a ‘bucket’. Both bucket and key can be used to access the value as they are hashed for unique indexing. Keyvalue stores provide much faster query response times than relational or other NoSQL stores due to indexing and simplicity of storage. They also support adhoc querying for complicated unstructured analytical applications like web usage, social network feeds, and real-time response processes.Fig. 4(a) shows telecom call detail records (CDRs) contained in a key-value schema. In this scenario, a CDR instance (or a collection of instances) can be inserted as value while key is a set of CDR flags.
2) Document Data Stores:In document stores, data is stored in documents comprising a collection of key-value pair data.Every document has its unique identifier (key) and serializes data in semi-structured formats, particularly JSON which provides a widespread, flexible and information-rich structure for data modeling. A new field can be added at anytime without considering its schema. The document data model maintains data locality and is hence easy to distribute. It is useful to store complicated data formats related to web applications, blogs, mobile/smart phone usage, chat applications, and social media clients. MongoDB is a worldrenowned NewSQL document store. A sample document model for a telecom’s data is shown in Fig. 4(b). Here, JSON document with key 1001 is storing a set of key-value pairs(attributes) related to a CDR instance.
3) Wide Columnar Data Stores:In wide columnar stores,data is stored and processed in the form of tables which are schema-free; it is not necessary to provide a value for each cell and each row can have its own schema. For instance, data in HBase is stored intableswhich are further stored in logical spaces calledregions. Due to large size of Hbase table, it is partitioned into multiple regions and assigned toregion serversacross the cluster. Each region server contains multiple regions and each region contain multiple storage units. Fig. 4(c) shows an Hbase table of telecom CDR data segmented in threeregionsbeing managed by tworegion servers. The data model is a multi-dimensional sorted map as discussed above (refer to Fig. 3). Each row is indexed by key and columns can be combined together to formcolumn families. Two or more column families form asuper column family.
4) Graph Data Stores:Graph data stores store data consisting of objects (nodes) and edges linking nodes through relationships. Indexes are used to traverse the graph (either directed or undirected) which can be scaled out and distributed across nodes. Frequent analytical queries include identification of clusters, shortest path between two nodes and community detection. New edges can be added and existing edges removed so that social graph entities like friends,followers, endorsements, messages, and responses can be accommodated along with their relationships. Time-evolving graphs can be analyzed by monitoring changes to architecture over time. Fig 4(d) shows a sample graph store for telecom.Nodes are entities (company, call date, voice call, call from,call to) or actions (connect) with relevant attributes(connection time, company name). Edge labels are characterized by their roles, e.g., caller, callee, type of call etc.
III. SLR RESEARCH METHODOLOGY
We focus our SLR on the following domains of research:
telecom analytics, big data applications to telecom, big data analytics (BDA) applications to telecom,andNoSQL applications to telecom. We selected these domains to be generic enough to constitute all the possible (hundreds of)different BDA solutions available in the market today and so,this domain list is complete to the best of our knowledge. We use the more common and popular terms from these domains to develop our search queries (described below). We targeted digital sources commonly known for computer science related publications, i.e., Institute of Electrical & Electronics Engineers (IEEE), Association for Computing Machinery(ACM), Elsevier, Springer and Google Scholar. We relied on Google Scholar for coverage of the remaining digital sources as it is the most frequently referenced digital source in 2018 and continues to approach and make contracts with sources for indexing their research databases [3], [43]1The complete list of indexed resources is not made public by Google.. To ensure state of the art results, we focused on research content from 2010 onwards but decided to include past content also if we deemed it critical. To manage the retrieved articles, we used the Mendeley tool as we found it to be more acclaimed and comprehensive for our needs. It is also broadly connected in scholarly groups and has large online community [44].

Fig. 4. NoSQL stores’ examples for telecom: (a) key value store; (b) document data store; (c) wide columnar data store; (d) graph data store.
To formulate search queries, we selected eleven (11)keywords related to big data, i.e.,big data, NoSQL, NewSQL,Hadoop, columnar store, key-value store, document store,graph database, big data tools, big data techniques,andbig data analytics.We also selected three keywords related to telecom, i.e.,telecommunications, VoIP,andmobile communication. Then, we combined each big data keyword with a telecom keyword to generate 33 queries, for instance big data AND telecommunications. We executed these queries on our selected digital sources.
We adopted a three-step methodology to extract the relevant research articles pertaining to our research questions. In the first step, we scanned the title of each paper (on each digital source) to determine its significance to our scope. We excluded completely irrelevant papers but we did not exclude papers which had fuzzy or unclear titles. This gave us 233 articles, which we added to our Mendeley database.We considered the most appropriate resulting literature papers from each source that are closely related to the topic. We used Mendeley to remove articles duplicated through Google Scholar, leaving us with 222 articles. In the second step, we read the abstracts of the papers filtered from first step. This provided more insights about the scope and helped in further filtering out irrelevant papers. This gave us 61 papers. In the third step, we read the first two sections of the articles filtered from second step, to perform a final filtration of papers which did not map our scope. This finally gave us 38 articles matching our scope, which we review in this paper. The breakdown of our 222 papers filtered in initial step with respect to digital sources is shown in Fig. 5. Google Scholar retrieved the maximum articles (60), followed closely by IEEE (57) and ACM (56), while Elsevier provided the least hits (23). Moreover, Fig. 6 shows the distribution of our selected 38 articles with respect to the complete set of 33 search strings, summed over all digital sources. The horizontal axis shows the big data keywords, and different colors represent different telecom keywords. There were no articles for search strings combining any telecom keyword withNewSQL, columnar store, key-value store, document storeandgraph database(hence, we do not display them). This shows that our selected literature does not use the more technical terms related to BDA. Also, a majority of the articles are retrieved through combination withtelecomkeyword followed bymobile communicationandsparsely byVoIP.

Fig. 5. Distribution of 222 articles in first step of filtration with respect to digital sources.

Fig. 6. Distribution of selected 38 articles with respect to 33 search strings over all digital sources. BD=big data, BDA=big data analytics, BDTch = big data techniques, BDTls = big data tools, Mob = mobile communication.
In Table I, we show the distribution of selected articles with respect to type of research content. Majority of the content came from the top conferences (17), and journals (8) followed by a couple of magazines. master thesis, workshop or symposium papers and commentaries had limited contributions. We did not find any book matching our scope.
Finally, we show the distribution with respect to citation year in Fig 7. From 2011-2015, no more than 5 articles were published each year. A spike was observed in 2016 with 18 publications, signaling the time when major interest and research was generated. This again fell in 2017.

Fig. 7. Distribution of selected 38 papers with respect to year of citation.
A. Quality Assessment
We assessed the quality of the selected 38 studies against eight (8) selected quality criteria (QC), to determine whether our selected research articles suitably address our research objectives. We created 8 questions to assess the quality of our articles, with “Yes”/“No” responses having weights “1” and“0” respectively. After these responses, we evaluated the results through Cohen’s score for inter-rater agreement. We debated on the discrepancies using the Delphi method [77]until consensus was reached on filtered articles. This activity was carried out by five researchers who are faculty members of three different universities in Pakistan (not anyone in the authors’ universities), including three females and two males.Based on a selected threshold of 5, our QC process did not exclude any of the 38 selected articles (all obtained a score ≥5(see Table II which records the mode response for each QC).Following are our quality checklist questions:
1) QC 1:Are research objectives clearly stated?
2) QC 2:Is methodology well-defined?
3) QC 3:Is big data tool utilization present?
4) QC 4:Any characteristics of big data out of 4V’s catered in the study clearly described and its solution with respect to telecommunication?
5) QC 5:Is the process of BDA or any one step of BDA process clearly stated to resolve telecom’s big data major issues?
6) QC 6:Does the study perform the comparison of proposed approach with existing baseline approaches?
7) QC 7:Were the performance metrics fully defined?
8) QC 8:Are results properly interpreted and discussed and does the conclusion reflect the research findings?
IV. RESULTS
We now discuss the 38 articles extracted from SLR. Article frequency distribution over telecom domain is shown in Fig. 8;mobile telecom is most frequent (23), followed by general telecom (12) and VoIP (3). In mobile, 20 articles (87%)discuss BDA applications to 2G, 3G, 4G and 5G networks, 2 on cellular networks and 1 on wireless networks. In Table III,we show a classification of our 38 articles with respect to telecom domain, big data technology stack and the type of article. We identified 4 such types:literature reviews,frameworks, use cases, white papers,andvalidation(with experiments). BDA frameworks have been proposed in 23(61%) articles, out of which 15 (40%) include validation with experiments, 5 (13%) present a use case without experiments,while 3 (8%) discuss only the framework without any use case or experiments. Also, in 7 (18%) articles, the authors do an experimental validation without proposing any framework.There are 4 (11%) literature reviews, a single white paper(commentary), and 3 (8%) use cases. Of the 22 (58%) articles on experimental validation, 16 (42%) employ Hadoop or its ecosystem APIs, and remaining use different NoSQL databases. Of the 16 (42%) papers that do not involve any experiments, only 5 (13%) papers employ Hadoop while the remaining focus on NoSQL. Of these 16, 2 papers also focus on stream analytics. The analytical applications targeted in our articles focus on Hadoop ecosystem, machine learning/data mining, deep learning, distributed databases, self organizing networks, computational visualization, graph analytics, Monte Carlo simulations, social network analysis and cloud computing-based data processing particularly for mobile telecom. Finally, Spark has also been used in 2 works for experimental validation and also once in a case study. We also estimated the number of articles focusing on BDA benefits and challenges of its implementation, along with future research directions and characteristics of telecom big data(shown in Fig 9). The authors discuss benefits most frequently, probably due to hype of big data and BDA,followed by challenges which are significant as outlined in Section I. Apparently, benefits/opportunities of BDA are clearly known and also its implementation challenges.However, experimental validations to realize these benefits and address the challenges remain very limited in research literature. We now discuss our 38 papers in detail. We have further classified them according topics (labels) and subtopics of telecom domain which we identified during our SLR(shown in Fig 10 and Table 4).
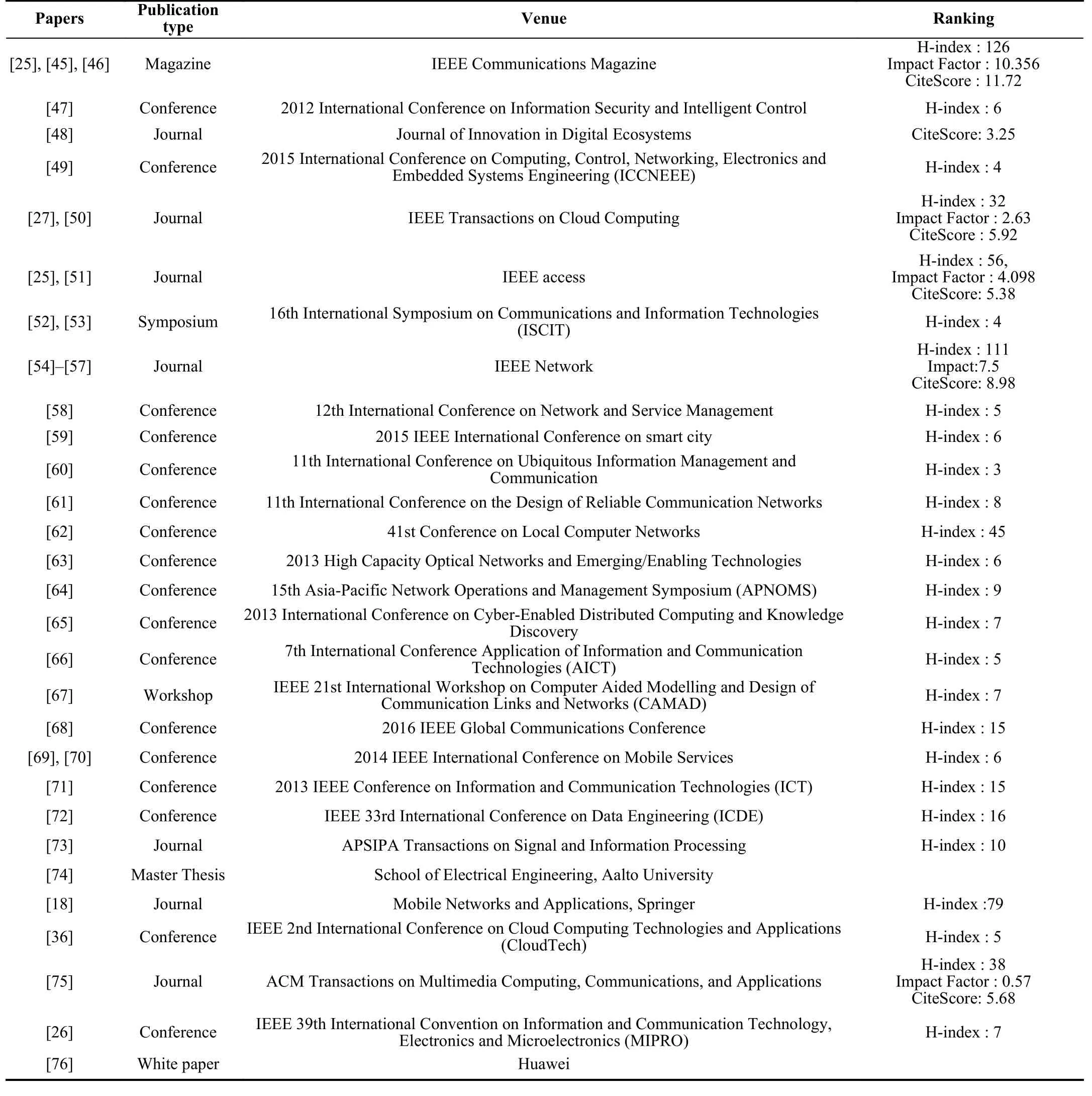
TABLE I CLASSIFICATION OF PAPERS WITH RESPECT TO ARTICLE TYPE AND THEIR RANKING
A. Frameworks
We now discuss big data frameworks over following five topics:mobile network operators, 5G, network optimization,CDR analyticsandstreaming data.
1) Mobile Network Operators:Authors target MNO’s2Mobile Network Operators.in[36], [45], [51] to address challenges in BDA implementation.One framework proposed automation of a manual reporting system of a Moroccan MNO to deal with unstructured data and CDRs, server logs, billing, and social network data. Kafka is used for data ingestion and Flink to process HDFS data in both streaming and batch mode, with final visualizations being shown on dashboards. Another framework uses Hadoop, Spark and machine learning to achieve network KPIs and enhance revenue and the third proposes alambdaarchitecture that caters for both batch and stream data processing, and the self-organizing network (SON) approach[78] work by inferencing data from a relevant knowledge base. Case studies are presented which extend previous works to create data intervals for data reduction, identify sleeping telecom cells, and find correlations in telecom data, all employing MapReduce to estimate parameters before a selforganizing network (SON) application. Generally, authors propose key-value data stores for storing mobile data.

Fig. 8. Distribution of 38 papers with respect to telecom domain.

Fig. 9. Distribution of 38 articles with respect to telecom big data characteristics, benefits of applying BDA, challenges faced and specification of future research directions.
2) 5G:In [54], the authors discuss a novel SON-based approach for 5G networks. They first identify challenges hindering SONs to meet 5G requirements and then propose a BDA framework for SON geared towards 5G based on machine learning and data analytics which could be exploited to extract insights for creating end-to-end network intelligence. Through a case study, they show how this approach can diagnose a sleeping telecom network cell.Authors also conduct simulations to demonstrate superior performance over 3G/4G SON. Also, in [25], the authors propose a BDA architecture for mobile wireless 5G communication to achieve optimized resource allocation,mobile content distribution and network optimization. The authors categorize four types of big data, i.e., application,user, network and link channel data, and describe the protocol stack, procedure for signaling as well as operations at the physical layer. It is claimed that this architecture can provide a drilled-down view of operations and customers. There is no mention of any specific big data storage or processing technology in this paper although the benefits of machine learning are mentioned.
3) Network Optimization:Authors expound on the benefits of using machine learning and deep learning approaches [28],[54], [56] for network optimization. To meet the network requirements (for e.g. 5G services), generalized BDA framework is presented. NoSQL databases are proposed in ETL step. BDA through machine learning extracts insights for creating end-to-end network intelligence and generates network optimization solutions for different types of big data(private, redundant, distributed etc.) Also authors investigate the application of BDA to 5G in [28] and show that it can produce architectures which are flat, both green and soft, i.e.,more agile and efficient.
4) CDR Analytics:In [49], the authors consider CDRs and prove it is a big data source and a candidate for BDA with respect to storage, processing and CDR analysis. Considerable research has been done to address the CDR analytics challenges along specification of BDA architecture, utilization of big data tools and techniques, and use case scenarios that presents better performance measures and cost efficient solutions in batch processing and real time. Authors stress the importance of using Apache Hive for querying with HDFS as a file system, while using Apache Cassandra for storing streaming data.
5) Streaming Data:In [26], the author presents an architecture for real-time predictive BDA for telecom domain.This model has four BDA capabilities: a) real-time analytics,b) detecting most probable cause of network failure, c)modeling the users’ telecom usage experience, and d) realtime actuation of business goals. There are three relevant business areas: a) optimizing management of telecom customer experience, b) enhancing business efficiency through real-time (stream) processing, and c) social network analysis (SNA) to analyze social and business relations among telco customers. The salient features of proposed architecture are: a) gathering more reatime data from all nodes, b) ETL connectors for extracting data from any source (NoSQL,relational etc.), c) real-time analytics, opinion mining of users along with real-time SNA, d) developing business processes and rules within the organization, and e) measurement of relevant KPIs.
B. Literature Reviews, White Papers, Use Cases
We now explain literature reviews, white papers and use cases over two topics:BDA applications to telecom sectorandBDA usecases.
1) BDA Applications to Telecom Sector:In order to reap BDA benefits for wireless telecom, authors in [46], [74]present actionable steps such as to identify big data sources in their domain, selection of new technology (particularly opensource), vendors, resource management including employees,BDA architecture, its execution with optimization. Further,identified BDA techniques according to network type particularly for wireless are stochastic modeling (e.g., Markov models, time series), machine learning (e.g., classification,regression, dimensionality reduction, reinforcement learning,deep learning) and data mining (pattern matching, clustering)algorithms as a solution to a specific problem such as predicting mobility of a user.
The authors in [57] direct attention towards format of inputdata generated by IoT, crowdsourcing and social media in structured, semi-structured or unstructured format, and either pseudo-random sampling, compressive sampling or distributed source coding being used to shred the streams for management. Such a streaming situation occurs when Internet-based mobile networking being performed in realtime on the cloud and there is a need to manage the off-loaded and uploaded streams in a real-time fashion. Therefore, a case study on BDA for streaming big mobile telecom data is presented via streaming architecture which utilizes distributed database technology to manage the streams; none of the wellknown BDA tools like Spark, Storm and Kafka have been used.

TABLE II QUALITY ASSESSMENT OF 38 SELECTED ARTICLES WITH DELPHI METHOD OVER 8 QUESTIONS QCI-QC8; MODE RESPONSE IS SHOWN FOR EACH QC FOR FIVE DIFFERENT RATERS

Fig. 10. Classification and sub-classifications of article types of our 38 SLR papers.
2) BDA Usecases:Hadoop, NoSQL and machine learning are the primary big data technologies being employed by the companies. In [24], [59], [65], [73], authors review BDA usecases identified through interviews, online research and through critical analysis from a representative sample of global telecom companies. The domains identified are marketing, sales, customer analysis, security, business development, innovation of new business models, products and services development, billing, intelligent transportation service, quality control, partner analysis, cost and contribution analysis, public sector, healthcare, media and entertainment,banking and insurance, quality of experience (QoE) or satisfaction, mobile retail shopping, mobile pricing analysis of products and SIM box detection, i.e., recognizing fraudsters who do not use their mobile sims as per policy.
The findings of review show that the remarkable benefits can be achieved through the earlier adoption of BDA with significant challenges. Also, real-time analytics and data management are core BDA requirements nowadays in telecom, which is expected to get serious due to IoT boom
[79]. The primary motivation for a BDA initiative is to enhance customer satisfaction by providing a unique customer experience each time. The author recommends telecom companies to focus BDA efforts on satisfying customers,develop BDA architectures that are applicable to the complete organizational business process, not to wait for more data but to initiate BDA with currently available data to achieve streaming results, build BDA skillset based on business requirements through defining measurable outcomes.
C. Validation
We now discuss experimental validation articles based on the following architectural topics:performance, accuracy,scalability, reliability, securityandusability. In some cases,we identified classifications of these aspects and discuss papers according to these classifications3Where necessary, we have itemized the paper discussion of validation-related papers to enhance readability..
1) Performance:We found following six sub-classifications of articles related to performance of BDA applications to telecom:NoSQL Data Stores, Cloud Computing, Machine Learning, Use of Hadoop with Spark,andUse of R Language.A. NoSQL Data Stores:The objective is to highlight the role of NoSQL in improving performance of a system and provide some guidelines for selecting the data store that is most efficient in terms of computational complexity.
● In [35], the authors present the method of migrating from a relational store to a NoSQL store and prove superior performance of Apache Cassandra over PostgreSQL relational store in a telecom scenario. The data model consists ofcustomer data, customer account data, bucket(balance of customer),bucket type, subscribed service, service type,andtariff plan. The specific query is determining the list of services subscribed by a customer (ordered by priority) and account information on receiving an in-coming call. The authors create a super column family for each user (row key is the caller number) where super columns contain the list of services (and details) being subscribed by each user. Aregular dayworkload and aChristmas workloadis created. In the former, Cassandra is able to handle 0.24 million calls over 600 seconds and in the latter 0.34 million calls, as compared to 0.16 million and 0.18 million respectively for PostgreSQL.Similarly, In [69], the authors utilize the NoSQL data storage technology
● In [66], the authors employ a NoSQL document store in an enterprise BDA telecommunication application. This system collects, merges and analyzes data from several subsystems, with major entities being staff, shift, permit, work activity, service, turnstile transaction, and department.Traditional relational storage is converted to document model;for instance, shift, permit, work activity, and turnstile transaction tables are combined into a document structure called Activity Package through a synchronization service.The use of NoSQL facilitates much better automatic load balancing in case of heavy querying load. The author’s do notmention the specific document store they have implemented and detailed experimentation is not shown.

TABLE III DIST RIBUTION OF 38 ARTICLES WITH RESPECT TO TELECOM DOMAIN, BIG DATA TECHNOLOGY STACK AND ARTICLE TYPE
● In [52], the authors implement a BDA cellular network planning system which is based on a common telecom use case of combining OLAP and OLTP technologies for a realworld concurrency scenario. The authors focus on HP’s Vertica, which is a MPP columnar warehouse providing support for both OLTP and OLAP type queries. In a cluster with standard configuration, inserting 10 K records in a table consumes an average of 200 ms, updating 10 K records consumes 3500 ms on average and deleting 10 K records consumes 2000 ms on average. A theoretical comparison with SAP HANA is also presented, which caters for the limitation in older versions of Hadoop to provide transaction processing,i.e., low-latency, SQL-oriented Hadoop solution was inefficient. The authors then propose a BDA architecturewhich can perform unified data processing to process analytical and highly concurrent transactional tasks efficiently within one system which run above various applications with loaded data and answering different end users requests.

TABLE IV CLASSIFICATION AND SUB-CLASSIFICATIONS (IN ITALICS) OF ARTICLE TYPES OF OUR 38 SLR PAPERS
B. Cloud Computing: Latency problem effects the quality of service and thus lowers the performance as well. This section highlight the importance of cloud computing as this solution is found abundantly.
● In [67], [68], the authors tackle the problem of delayed transfer of mobile data from smartphones and related devices to mobile cloud computing data centers over wireless channels. To overcome this latency, an efficient BDA-based data transfer approach is proposed that employs overlapping features of heterogeneous wireless networks (HetNets) by splitting data into chunks transferred simultaneously. In this way, data is first transferred to small clouds called cloudlets(associated with small telecom cells) which then transmit to public cloud. Through Monte Carlo simulations, the efficiency of the proposed approach is demonstrated. The authors do not mention any use of standard NoSQL databases for big data storage management.
● In a similar vein, the authors in [58] justify the complexity of maintaining QoS guarantees in a cloud computing(software defined network) scenario, due to un optimized network design, load balancing, access control and prioritization of traffic. Here, we report the findings from a couple of papers to exhibit the role of ML algorithm in improving the performance of the telecom big data system.
C. Machine Learning: A number of ML algorithms are available that can be leveraged. These ML algorithms range from supervised learning (e.g., Logistic Regression, Support Vector Machine, Naive Bayes, Random Forest, and Decision Trees) to unsupervised learning algorithms 14 (e.g., K-means and Neural Networks). When selecting a ML algorithm,several factors need to be considered. These factors include the time complexity, incremental update capability,offline/online mode, and generalization capacity of the algorithm, and most importantly the impact of the algorithm on the detection rate (accuracy) of a system. Due to the diverse role of the algorithm, it is quite challenging to pick the most appropriate and efficient algorithm.
● The authors in [58] propose and implement a BDA approach for QoS optimization, based on quantifying the correlation between telecom KPIs (e.g., packet size, number of packets transmitted, length of queues) and QoS metrics(e.g., end-to-end delay, throughput, packet loss etc). Initially,correlation coefficients are computed for each KPI and then machine learning using a combination of decision trees and linear regression is used to predict the QoS metrics. One core finding shows that CPU utilization is correlated with number of packets transmitted and packet loss with average communication delay. There are some unexpected results,e.g., bi-directional delay increases end-to-end delay by a factor of 4. Similarly to above, the authors do not mention any use of standard NoSQL databases for big data storage management.
● In [53], the authors combined the output of random forest,logistic regression and support vector machines algorithms to build a predictive model for their customers In [70], machine learning algorithms are also involved specifically neural networks, decision trees and logistic regression to identify influential telecom subscribers
D. Use of Hadoop With Spark: In [62], the authors propose an efficient statistical BDA solution to identify encrypted,non-encrypted, or tunneled VoIP media (voice) flows. A system is also proposed to efficiently process high-speed realtime network traffic. The BDA solution uses association rule mining to extract rules regarding VoIP parameters/KPIs, for instance, packet size, current flow, and packet transmission time. The authors treat this as a classification problem, with classes depicting different outputs being generated by the rules’ combination. A single-node Hadoop setup is used for batch processing along with Spark for processing of streaming VoIP data. The authors demonstrate that the system efficiency in terms of number of packets transmitted outperforms performance of existing VoIP analytics systems.
E. Use of R Language: In [60], the authors tackle the problem of understanding and analyzing VoIP applications through standard parameters such as bandwidth, packet loss rate, delay, jitter, codec type and CPU power of the end devices. Performing ETL on VoIP big data is a challenge due to the diversity of Internet data being generated by a single device. As part of a performance measurement research, a robust ETL approach is proposed which is based on execution of certain scripts during extraction, conversion to XLS and txt formats of extracted data in transformation, and loading of data into R for analytics in loading phase. More important results show that GoogleTalk, Skype and Express Talk are sensitive to packet loss rate and jitter rather than to delay.Also, bandwidth and de-jitter buffer and gateway CPU and memory are important in order to produce a good quality VoIP service.
2) Accuracy:The following articles dealing with accuracy of BDA application results have used Spark:
● In [53], the authors attempt to increase the adoption of 4G technology by predicting the relevant customers currently using 2G/3G from big data streams of a Chinese telecommunication firm. The exact work is to enhance 4G transfer rates through prediction of peer influence in CDR graphs of customers with data like service subscription,service usage, demographic information, and calling and messaging history. The graph contains 0.15 million nodes and 62000 edges. In a field study, the authors first perform feature selection and then build a predictive model that combines outputs of ML algorithms using an Apache Spark cluster setup. The authors demonstrate excellent predictive accuracy by comparing real-vs-predicted values.
● In [75], the authors propose a deep learning framework for video analytics. Specifically, convolution neural networks are used to classify each frame of the video in real-time to determine its importance, in which case it will be retained.This activity controls the size of the input video hence leading to load reduction by discarding frames unnecessary for analytics. The action decision to discard is taken by determining correlation between consecutive frames in a streaming fashion. The authors show that their system has better accuracy as compared to other deep learning models for stream processing (temporal stream convnet and two stream model).
● The authors in [27] also use neural networks to predict the anomalies in their mobile network when implementing a BDA framework for analyzing customer-centric mobile wireless big data using Hadoop for processing and Apache Pig for ETL.Initially, customer CDR data are used to detect anomalous behavior using k-means and hierarchical clustering, for instance, unusual traffic at a given location and time. These outputs are compared with ground truths for verification, and held identify regions in the network for specific actions such as resource allocation.
3) Scalability:We now discuss papers that have implemented scalable BDA applications, over two classifications:Use of HadoopandSocial Network Analysis.
a) Use of Hadoop:
● In[55], [63], MapReduce is used for processing and analysis of data sets at different layers of a telecom platform.For this purpose, employ Apache pig or hive for programming MapReduce. Hbase is used as persistent NoSQL data store The authors in [64] implement a NoSQL infrastructure for criminal investigation through telecom CDRs. The infrastructure uses Apache Hive with Apache Hadoop/HDFS at backend. The authors vary several parameters including block and partition size in HDFS. The ideal parameters demonstrate the superiority of using Hive, with considerable improvements to the efficiency of query execution and scalability along with reducing cost of cloud usage.
● In [55], the authors implement a scalable network traffic monitoring for a large scale telecommunications company based in China. MapReduce is used to execute traffic analysis,application analysis, and user behavior analysis on telecom big data streams. Some specific KPIs which are estimated are traffic statistics in terms of bytes and packets, traffic classification at the application level, web service provider analytics from the perspective of mobile Internet, and clustering the user behavior data to extract useful homogeneous groups. The authors persist data in Hbase and employ Apache Pig for programming MapReduce. It is shown that Hadoop can efficiently processes 4.2 terabytes of traffic daily from 123 Gb/s links with high performance and reduced cost.
● In [63], the authors implement a big data platform with a domain specific language (DSL) for telecom sector, which uses MapReduce for processing and HBase as persistent NoSQL store, along with a visualization layer for displaying results. A specific type of file descriptor is also created for organizing communication in the above process. DSL is a high level Language which abstracts the user from directly writing MapReduce code or performing ETL through Apache Pig or Hive. It transforms the datasets in such a way that various information about a particular grid such as multiple calls and SMS activities on a particular date and time could be done with few lines of code. The authors demonstrate the scalability (rate of change throughput is more than the increase in number of nodes), reduced average execution times and linearly increasing write performance of HBase with increase in data.
● In [69], the authors propose a three-tiered BDA architecture for the agriculture domain to solve the problems of farmers not being able to access crop yield information online due to unstable nature of wireless communication. A middleware allows farmers to access the data with WiFi or 3G/4G connection. Another tier stores farmers’ requests in a NoSQL database which acts as a cache to avoid DoS messages. Finally, in an offline mode, farmers can communicate through Bluetooth to synchronize information.Strangely enough, the authors do not specify the exact NoSQL technology which could be useful in their application.
b) Social Network Analysis: In [70], the authors propose a scalable BDA solution for identifying influential telecom subscribers through several social network analysis metrics combined through machine learning, specifically neural networks, decision trees and logistic regression. To support scalability, a prototype system is implemented on Hadoop and algorithms are executed through MapReduce. Results show that the system can scale to millions of users through actual data from a telecom company with 2.4 million subscribers and experimental data for networks with 100 million subscribers.
4) Reliability:We now discuss articles focusing on reliability aspect of validating BDA applications to telecom sector, on following classifications:Use of Hadoop, Use of SplunkandNoSQL databases as Caching Mechanism in Service Oriented Architectures (SOAs).
a) Use of Hadoop:
● In [27], the authors implement a BDA framework for analyzing customer-centric mobile wireless big data using Hadoop for processing and Apache Pig for ETL. Initially,customer CDR data are used to detect anomalous behavior using k-means and hierarchical clustering, for instance,unusual traffic at a given location and time. These outputs are compared with ground truths for verification, and held identify regions in the network for specific actions such as resource allocation. The authors also use neural networks to predict these anomalies in advance.
● In [50], the authors develop a MapReduce framework over a previously implemented distributed system for mobile cloud computing (MDFS). In this way, due to the parallel processing nature of Hadoop, no single mobile device can become a bottleneck for the mobile cloud. Also, resource allocation and task management are handled efficiently by Hadoop in a fault-tolerant manner, and Hadoop has proven its worth in many applications in varied domains. The authors do not employ HDFS as it does not cater for the energy limitations of mobile devices and it requires heavy I/O processing to maintain fault-tolerance, as compared to the lightweight nature of mobile data processes. In experiments,authors achieve optimal parametric settings for HDFS block size, Hadoop cluster size, and node failure rate, along with the effect of changing input sizes on the throughput. The superior performance of MDFS over traditional HDFS is also validated.
● In [47], a real-time video/voice over IP (VVoIP)application is implemented using Hadoop cloud computing system to resolve head-of-line blocking, handover interruption, and non-real-time transmission problems in VoIP communication. The authors employ TCP-based Real Time Messaging Protocol instead of the traditional Stream Control Transmission Protocol, and also employ a neural network to tune parameters to optimize handover and analyzing network traffic at any time. VoIP data is moved from user devices to Hadoop cloud with access control to implement rapid facial/fingerprint identifications and reduce the amount of processing data. The authors demonstrate that their system has a faster response time and lesser misclassification rate in access control.
● In [71], the authors employ a Hadoop application to solve the problem of detecting signal discontinuity regions for 3G connectivity through a combination of standard KPIs.Experiments are performed through simulations over a cluster of 3 nodes with commodity configuration, where the cluster received around 1 million messages from different access regions daily and MapReduce is used to execute the queries using KPI values. The results prove that the Hadoop system has superior accuracy and efficiency as compared to traditional approaches.
b) Use of Splunk: In [61], the authors evaluate the health of network of a university wireless network, in order to analyze patterns of outages and failures for reliability improvement.For this, the proprietary Splunk tool is used for analyzing the huge volume big data generated by node outages, link failures and topology information. Simple Network Management Protocol and syslog data are used to investigate reliability along with standard documents of causes and recommended actions, and input of network operators’ on special events and actions. The overall result is that wireless networks are less reliable as compared to wired network.
c) NoSQL Databases as Caching Mechanisms in SOA: In[69], the authors propose a three-tiered BDA architecture for the agriculture domain to solve the problems of farmers not being able to access crop yield information online due to unstable nature of wireless communication. A middleware allows farmers to access the data with WiFi or 3G/4G connection. Another tier stores farmers’ requests in a NoSQL database which acts as a cache to avoid DoS messages.Finally, in an offline mode, farmers can communicate through Bluetooth to synchronize information. Strangely enough, the authors do not specify the exact NoSQL technology which could be useful in their application.
5) Security:In this section, we discuss the single paper related to security aspects of BDA applications to telecom.Particularly, in [48], a graph analytics platform is implemented which provides the network operator with an extended toolkit to obtain an overview of the whole network and allowing the operator to gradually focus on the desired information and acquiring useful insights. It facilitates data mining by providing modules for extraction of behavioral patterns, detection of attacks against network, behavioral similarity and detection of anomalies and attacks against networks. For validation, the authors perform root cause analysis of denial of service (DoS) attacks on a mobile network operators, along with early detection of an emerging(hot) event in Twitter streams. Most of the previous solutions have not managed graph based data mining at this level of adequate depth and GAP is a much better visualization platform for big data. The authors do not mention about any NoSQL graph database in their work.
6) Usability:Finally, this section discusses the single paper related to usability aspect of BDA applications to telecom. In[72], the authors implement a BDA application called SPATE,which is an innovative big data exploration framework for telecom data using Hadoop and Spark to achieve comparable response times with orders of magnitude lesser storage space for spatio-temporal queries. The authors use lossless compression to ingest streaming telecom data and use a concept ofdecayingto distinguish between ‘old’ and ‘new’data. Experiments have been conducted using network data traces and a variety of telecom analytics tasks. SPATE’s future includes advanced smart city application scenarios namely an automated car traffic mapping system and an emergency recovery system which is critical after natural disasters.
V. CHALLENGES AND BENEFITS
We now mention the challenges and benefits of telecom BDA applications described in our 38 papers. We also enlist concrete gaps identified from challenges to realize the benefits properly.
A. Benefits of BDA in Telecom
We have categorized the benefits of BDA applications to telecom as follows:
1) BDA As a Smart Solution:BDA brings special infrastructures and tools that provide considerable advantages for telecom industry in terms of infrastructure, programming models, high performance schema free databases and process analysis, all of which offer new and innovative opportunities to telcos, for instance, lesser power consumption and optimized resource management and network performance[35], [36], [46], [59], [63].
2) Cost Reduction and Revenue Generation:BDA can assist in reducing cost of different operations of communication networks. BDA stream processing technologies help to process complex events with real time requirements which reduce risks, cost, and improve decision making and revenues[76], [80].
3) Improving Customer Care Services:Business case for big data is substantially focused on addressing customercentric objectives. Companies can use BDA to enhance the customer care services as a result of being able to truly understand customer needs and anticipate future behaviors.Operators can make automated procedure to meet customer requirements such as faster calling [65], [80].
4) Improving Diverse Usecases:BDA can be applied for Sim-box detection and quality of experience (QoE), the two most compelling use cases in the telecom domain. Important telecom applications that can benefit from big data include QoE analysis, churn prediction, target marketing, and fraud detection [73].
5) BDA for Next Generation Mobile Communication:BDA can be used to analyze 4G LTE and 5G network from multiple dimensions and provide optimized solutions. Some examples include end-to-end visibility of the wireless network, selfcoordination among network functions and entities, building faster and proactive network, smart and proactive caching and energy efficient network operation [27], [74]. The future 5G network design will be greener and softer and will better meet the user requirements of mobile communication [28].
6) Future BDA:Future BDA will encapsulate many different data models and algorithms as well as data integration components, for instance, advanced probes and adapters for retrieving data from all network nodes in realtime, advanced adapters for pulling relevant customer data from traditional big data and data warehouse systems, realtime analytics for customer activities, quality indexes for sentiment analysis, and opinion mining in real-time [26].
B. Challenges of BDA Application in Telecom
In the research papers which address challenges [36], [46],[48], [51], [54], [60], [65], [72], [73], [76], we have identified three categories:
1) Lack of a formal Architecture for BDA Pipeline Implementation:BDA initiatives are posing serious challenges in integration of different data sources, complicated and timeconsuming ETL activities and ensuring quality of the BDA outputs by uncovering correlations and actionable insights using distributed machine learning. In fact, BDA offers two types of architectures (pipelines) to streamline the process and solve these problems, i.e.,lambdaandkappa[17]. Briefly,lambda allows processing of streaming and batch data in parallel, while kappa considers everything as streaming data;first data has to be processed as stream and then in batchmode (if required). We have not found any lambda or kappa implementations or proposals in any of our reviewed papers.Perhaps the best match is the work done in [81] who propose an AWS-based (Amazon’s cloud service) lambda architecture for IoT data processing. However, this paper does not propose any much innovation (due to the already available AWS infrastructure) and lacks several important components(shown in next section) which are critical to deal with the heterogeneous nature of telecom’s BDA requirements.Surprisingly, state-of-the-art NoSQL solutions (e.g.,MongoDB and CouchDB document stores and Redis and Riak key-value stores) which have had a global impact are not demonstrated in published research [82], [83].
2) Lack of BDA Expertise and Knowledge:The BDA technology stack is increasing exponentially and it is difficult to find the relevant human resource who are technology experts for operational BDA architecture implementations.Definitely, guidance is needed in selecting the best architecture and the best combination of BDA technologies in this architecture. We also need to select the standard Python development language which has a massive online community in BDA pipeline development.
3) Lack of Security Policies:The problems of ensuring data security, privacy, confidentiality and protection are quite significant in a BDA application for telecom companies. Many companies will avoid a BDA initiative if the security policy are not specified or enforced. Cloud computing (through Amazon AWS and Microsoft Azure) have resolved doubts over privacy invasion of companies of diverse types [84], [85]. However, it is still not an acceptable solution for many companies in general because the ‘data is not available within the company’s data center’ and its increased cost as compared to an in-house BDA architecture based on open-source technologies where the data security policies as specified by the IT department can be applied on the BDA pipeline.
In our opinion, the only solution to these challenges is to propose a formal BDA architecture for the telecom sector, to be implemented in-house with standard open-source technologies and programming languages in order to reduce cost and increase privacy. We firmly believe this is the need of the moment and it will provide a clear roadmap for telecom’s BDA practitioners.
VI. LAMBDATEL: PROPOSED LAMBDA ARCHITECTURE (BDA PIPELINE) FOR TELECOM SECTOR
Our proposed BDA architecture for the telecom sector called LambdaTel is shown in Fig 11. The engineering behind LambdaTel is lambda in nature, allowing both batch and streaming data processing to execute in parallel with each other4We have adapted this architecture from one of our previous works [86].. It consists of seven layers which we describe below.
1) Connection Layer:The Connection layer allows the different types of telecom data sources to feed data to our BDA pipeline. In other words, this layer implements an application programming interface (API) of data connectors for a potentially large set of standard No-SQL databases, SQL databases, IoT feeds and other streaming or batch telecom data feeds. Python’s support for connecting to NoSQL and other databases facilitates the implementation of this layer,e.g.,pymongoAPI for connecting to a MongoDB instance andredis-pyAPI for connecting to Redis database instance.

Fig. 11. LambdaTel: Proposed Lambda Architecture (BDA Pipeline) for Telecommunication Companies (adapted from our previous work [86]).
2) Integration Layer:The Integration layer is responsible for integrating telecom data from the Connection layer and inserting that in an integrated data lake. We propose to deploy a master database (either on a single or multiple servers) to store the data lake. We also propose to use MongoDB for this purpose for its flexibility of storage schema and support for both batch and streaming data. The actual integration of data can be done by storing each individual telecom source data in its relevant database (preferably NoSQL) and then implementing a controller API over these different stores for coordination. For example, newsfeeds from social networks can be continuously stored in Neo4J and call detail records in MongoDB where the controller keeps meta-data information of associations, data, storage capacity activities to provide access. Redis is our recommendation for metadata store to encourage quicker recovery and storage with minimize management overhead. Talend and Pentaho tools are not suitable here for data incorporation.In order to maintain the efficiency of BDA process, our proposal is towards Python programming for every stage.
3) Batch Layer:The Batch layer is responsible for batch(static) processing of big telecom data from the master database. We recommend a using a Hadoop cluster to tackle the major ETL tasks for telecom big data in this layer. If some tasks are required to be processed faster, these can be done through Apache Spark and the more lengthy and time-taking tasks can be processed through MapReduce, for instance,computing the average call time for five years over 250 TB of data through MapReduce [87]. The Batch layer provides a thorough drilled-down analysis to supplement the processing done in the streaming layer.
4) Streaming Layer:The Streaming layer is responsible for processing of real-time/dynamic) telecom streams. This layer presents real-time views and basic analytics at an abstract level. We recommend the use of Apache Kafka for ingesting the streams Apache Spark’s SparkStreaming feature for processing. Another competitor to Kafka is Flume (geared particularly for log analysis) although Kafka’s usecases outnumber Flume’s by a large margin. Similarly, Apache’s Storm API is a competitor to SparkStreaming but the latter is considered to be more applicable with respect to usecases. The selection of the tool should be preceded by a concrete analysis as BDA technologies continue to evolve. High velocity dynamic data streams could be stored in MongoDB or Redis if any use case occur otherwise it could be inefficient [88].
5) Serving Layer:The Serving layer consolidates the results of both Batch and Streaming layers. It acts as a staging area where the batch and stream processing results are integrated together as per the requirements of the end-users, e.g., C-level executives of the telecom company. We recommend implementing the layer on a separate server machine, which we call the analytical data lake. This layer prepares processed data for displaying the end-user dashboards.
6) Interface Layer:The Interface layer combines all the back-end layers (Connection, Integration, Batch, Streaming and Serving) with the front-end layer (Dashboard layer). Here,the well-known Python API’s for implementation of REST interfaces, e.g., Flask and Dash can be employed. Along with this, we recommend using Node.JS web server technology due to its enhanced scalability.
7) Dashboard Layer:The Dashboard layer involves displays a series of dashboards to be seen by various telecom end-users. Every dashboard connects through the Serving layer through standard connectors, e.g., BI connectors given by various BI tools (such as Tableau, Oracle’s NI and QlikView), or Apache’s Sqoop. Plotly, an on open-source Python APIs is useful to create dashboards. As per client needs, the whole pipeline (or simply the front-end) could be deployed on any of the well-know cloud service providers,e.g., Amazon’s AWS, Microsoft’s Azue or Google’s Cloud;we recommend using SSL technology to connect dashboards to Serving layer through Interface layer.
Parallel and exclusive data streams can be process by both layers. Static and dynamic both layers ought to include ETL(data cleaning) exercises and statistical modeling, e.g., big data predictive analytics can be marked as BigML. During this process, program the data management modules in python which further develop the background routines for processing static and dynamic data:
8) Workflow Management:This module manages the large assortment of potential workflows that are possible in a BDA pipeline for telecom data. Apache’s Oozie is recommended here as a task scheduler. Oozie is Python-compatible and allows creation of formation of Hive, MapReduce, and Sqoop tasks as Directed Acyclic Graphs (DAGs).
9) Session Management:This modules stores the session of every activity in the BDA pipeline in a stateless manner. As this is likely to generate much big data itself with high velocity, we recommend creating archives with respect to a windowing period. Here, our recommendation is to use Redis as the session database. In case of storage requirement over a larger timeframe, we can employ Apache Cassandra or HBase.
10) Cache Management:This module speeds up telecom BDA processing through implementation of a separate caching mechanism. Redis data structure is highly robust in nature and is the best to use for cache management with more usecases, variety of data structures better strategies for removing data from main memory. [89], [90].
11) Log Management:Client logging, server preparing and troubleshooting information can be served through log management, as indicated by standard practice. There should no negligence on administrator side for coverage of client clickstream in sessions and logs. Logged information can be acquired through Flume and processed as MapReduce tasks.
12) Queue Management:Due to the diverse requirement of analytical task at different events, queuing up the tasks (e.g.,in an Oozie instantiation) can be required. Kafka is an ideal data queueing system for streaming real-time data. For static data, we recommend RQ (Redis Queue) programming, which executes queues in Redis scripted in Python. RQ is also utilized for real-time data incase Kafka is not applicable.
13) Resource Management:This module coordinates the different BDA pipeline resources and activities. The best software for this task is Apache’s Zookeeper which can detect master node and slave node failures and help recover from such faults. It also provides interfaces to manage cluster resources in an effective and efficient manner.
In our opinion, the aforementioned BDA pipeline is standard as per the current BDA technology stack. Last but not the least, we recommend implementing this pipeline in a Dockerized manner, with each activity running in its own docker container for more efficient processing and ease of coordination with other dockers. Also, BDA pipelining requires a development operations (DevOps) type of structure,with continuous integration and continuous deployment being managed by the standard Jenkins tool. All data and results being generated should be stored in private GitHub repositories for enhanced security and identity and access management (IAM) solution.
It is important to discuss the strengths and weaknesses of both lambda and kappa architectures to justify our selection. Our motivation for selecting lambda is that telecommunication analytics use cases all require both batch-level analyses as well as real-time analyses (primarily due to the requirement of data cleaning and machine learning at the batch level). In a kappa architecture, there is no operational component for batch-level analyses and analyses are computed on-the-fly. As proof, let us discuss two important use cases of telecom industry for LambdaTel: a) Customer Relationship Management (CRM):call detail records (CDRs) of customers (streaming in nature)are fed into both batch layer and streaming layer in parallel. In batch layer, the CDRs are pre-processed and cleaned and then machine learning is applied to extract important customer segments, all in batch mode over a period of one hour. These segments are then fed to the serving layer. In streaming layer,real-time analytics starts to immediately show basic results like customer call throughput and average calling time per unit time,which are also fed to the serving layer. Here, real-time results are then shown with respect to segments available from batch layer, to present the required CRM picture to business decision makers. This use case can also be applied for other machine learning applications like prediction (classification, regression,time series forecasting) of telecom KPIs (calling time, SMS per second, mobile data usage frequency, revenue, sales, etc.) b)Customer Attrition: CDRs and historical attrition data are fed to the batch and streaming layer in real-time, while marketing data and competitors’ data are fed to the batch layer only at a predetermined time. The batch layer performs ETL to clean all data to predict customer churn, with result sent to serving layer. The streaming layer presents basic attrition analytics with respect to customer segments (computed previously), and in serving layer,the results are combined to present attrition prediction for each segment. We can similarly prove the need for batch-level analytics in other use cases related to marketing, cross-selling/up-selling, human resource management and operational analyses.
Also, lambda architecture guarantees an error-free data execution process due to the presence of batch layer, hence maintaining a good balance between speed and reliability along with a fault-tolerant and scalable architecture due to Hadoop (plus Spark) implementation at batch level. It is interesting to note a blog questioning the lambda architecture by Kreps in 2014 [91], who actually proposed kappa.According to him, lambda brings much coding overhead for ETL at batch layer, primarily required for machine learning.However, the conquest of Python as a data science and big data language has made coding practices much simpler in the last 5 years. In lambda, we may need to re-process or repeat executions per batch but this can be catered by using inmemory and/or columnar storage solutions, which have also matured since 2014. Finally, a lambda architecture is still difficult to migrate or re-organize but considering the lack of any published lambda architecture for telecom, we think the time for this migration is still far; the need of the moment is to first implement and use it. The kappa use case allows execution of real-time queries, either on real-time data or data previously stored in some in-memory or streaming database without focusing on ETL. These situations can also be tackled by lambda, in which we can temporarily disable the batch layer for such requirements (for more information, kindly refer to [17], [91]-[95]).
A. An On-Going Application of LambdaTel
We are currently implementing LambdaTel for a local company (jazz.com.pk) to conduct a proof of concept (POC)application for their use case related to cross-selling/up-selling of customer services for marketing division. This is an ongoing work in which we can mention the current results without providing sensitive information. The company currently maintains an enterprise resource planning (ERP)implementation of SAP, with an Oracle back-end consisting of 5 different databases and around 1450 tables in all. There was no analytical infrastructure in-place previously. All queries were executed through structured query language(SQL) which was generating delays for several complex queries. Results were shown through a standard business intelligence (BI) tool. We also discovered a major problem of data quality in these tables, particularly missing values,incomplete values, inconsistent data, and data entry errors. For the cross-selling/up-selling use case, the requirement was to get the customers to purchase more than one service or upgrade in a single attempt; specifically, to predict which customer will purchase in this manner. For this, we identified 410 relevant tables, measuring around 825 GB. We extracted this data through connection layer, and inserted it in a MongoDB cluster (Master Database) with the metadata. This activity consumed two months. Then, we implemented the batch layer through a Hadoop cluster with Spark front-end.We cleaned data thoroughly through ETL functions encoded in Pig Latin and running on Hadoop. We then used processed data for prediction through MLLib over Hadoop, and fed the results to serving layer. This activity also consumed two months. Once the customers to target were identified, we started inserting their real-time CDRs to streaming layer to compute day-to-day behavioral analyses of mobile phone usage, which were all fed to serving layer. This layer now shows the predictions of customers to target for cross-sell/upsell, along with their real-time behavior to put things in perspective. This activity consumed one month. Currently (as of September 2019), the marketing division is testing the predictions at serving layer, and has demonstrated a small increase in customer loyalty due to some successful predictions. We have used exactly the same technology stack as proposed for LambdaTel. For the company, LambdaTel has brought the following advantages: a) implementation of a complete data quality execution pipeline which can be replicated for different use cases, b) implementation of a master database (data lake) for analytics which was previously unavailable, c) a combination of both real-time analyses and batch-level machine learning to understand the consumers more deeply, and d) implementation of a personalized dashboard using Apache Flask which was more convenient for top-level management as compared to the current BI tool implementation. The batch layer keeps on updating its machine learning model on a daily basis, while the streaming layer always gets the CDR’s for the predicted customers, and all this in an automated manner through Python scripts. All of this has been very effective, efficient and reliable for the marketing department.
We must mention that LambdaTel is not a solution for companies which do not require machine learning or real-time analytics on-the-fly, or do not tend to focus much on maintaining data lakes for multiple analytical use cases.
VII. ANSWERING THE RESEARCH QUESTIONS
We now answer our research questions as follows:
1) RQ1:How much research literature is focused on BDA applications to telecom sector and what is the BDA technology stack in these articles? Answer: In all, 38 articles are focused on BDA applications to telecom sector (primarily from 2010 - March 2018). Technology stack includes Hadoop and some of its ecosystem APIs, MapReduce, Spark and some of its component APIs, Kafka, Flink, R, NoSQL databases,statistical analysis, machine learning, deep learning, cloud computing and social network analysis.
2) RQ2:What are the benefits and challenges mentioned in these articles and how much benefit has been actually realized? Answer: Optimized costs and better customer experience, revenues and security are the major benefits.Challenges include lack of a standard BDA architecture for implementation in industries, along with a lack of security and BDA expertise. Benefits are realized in a limited manner in academic research with respect to frequency of articles and experimental validations in industry and use of standard tools from ever-expanding BDA landscape. Although cloud service providers like AWS and Azure can address data security concerns of telecom practitioners, many telcos’ policies prevent data from leaving the premises [96], [97].
3) RQ3:How can the challenges be strongly addressed to facilitate BDA applications to telecom sector? Answer: We have answered this by proposing a state-of-the-art lambda architecture for telecom practitioners called LambdaTel; we specify the exact components of this architecture and propose the use of Python to implement it due to its massive online community and availability of Python’s APIs in all NoSQL solutions.
VIII. CONCLUSIONS AND FUTURE WORK
Big data analytics (BDA) has much to offer for telecommunications industry and its importance can hardly be underestimated. In this paper, we determined through a systematic literature review that the practical applications of BDA to telecom are limited in academic research with respect to a lack of architecture and usage of latest solutions in an expanding technology stack. To solve this problem and address other challenges, we have proposed and described LambdaTel, a state-of-the-art lambda architecture for BDA implementations in telecom sector. It is important to note that we have successfully implemented LambdaTel in a telecom solution called Darbi (https://www.darbi.io/). Darbi currently has one implementation in the military but the experiments cannot be discussed due to the confidential nature of the application. A limitation of LambdaTel is that the BDA implementation solutions it proposes are not eternal in nature,e.g., MongoDB could be replaced by another better NoSQL document store five years later. This defines our future work also: there is a need to “keep up” with the pace of BDA innovation and “ keep on” modifying LambdaTel's implementation solutions accordingly. We believe LambdaTel gives a strong opportunity to telecom practitioners to implement BDA pipelines now in their own enterprises. In fact, fulfilling the requirements of [15], LambdaTel presents a type of roadmap for BDA application to telecom sector through technology and process improvements. We strongly believe that it can be directly implemented in the industry with minor modifications if needed. As future work, we intend to target BDA applications to Telecom (and related sectors) with respect to IoT domain, which has an apparently rapidlyexpanding user base with many companies/startups planning IoT applications in their business operations along with increasing publication of research papers [98], [99]. We would be interested in determining the exact number of Telecom applications and then to propose and implement an IoT-BDA framework for Telecom sector.
ACKNOWLEDGMENT
We acknowledge useful inputs regarding LambdaTel with Mr Uzair Ahmed (Project Lead for Darbi) and with Muhammad Zahid Raza (Assistant Vice President IT) from Meezan Bank (www.meezanbank.com).
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Networked Control Systems:A Survey of Trends and Techniques
- A Stable Analytical Solution Method for Car-Like Robot Trajectory Tracking and Optimization
- A New Robust Adaptive Neural Network Backstepping Control for Single Machine Infinite Power System With TCSC
- Algorithms to Compute the Largest Invariant Set Contained in an Algebraic Set for Continuous-Time and Discrete-Time Nonlinear Systems
- Asynchronous Observer Design for Switched Linear Systems: A Tube-Based Approach
- Deep Imitation Learning for Autonomous Vehicles Based on Convolutional Neural Networks