基于TextRank的新闻关键词抽取系统的设计与开发
2020-02-22欧霖赵永标
欧霖 赵永标


摘 要:对新闻标注关键词有助于用户快速了解新闻内容,也有利于新闻的分类及检索。鉴于人工选取关键词效率太低,设计并实现了一个基于TextRank的新闻关键词抽取系统。该系统包含五个模块:用户登录、用户注册、分词与词性标注、候选词提取、关键词提取。该系统可以辅助新闻编辑人员进行关键词抽取和筛选。经过测试,该系统达到了一定的准确度,而且界面友好,易于使用。
关键词:TextRank;关键词抽取;新闻
中图分类号:TP391.3 文献标识码:A 文章编号:2096-4706(2020)18-0023-04
Abstract:Tagging news with keywords helps users quickly understand the content of the news,and is also conducive to news classification and retrieval. In view of the low efficiency of manual keyword selection,a news keyword extraction system based on TextRank was designed and implemented. The system includes five modules:user login,user registration,word segmentation and part-of-speech tagging,candidate word extraction,and keyword extraction. The system can assist news editors in keyword extraction and screening. After testing,the system has reached a certain degree of accuracy,and the interface is friendly and easy to use.
Keywords:TextRank;keywords extraction;news
0 引 言
隨着互联网的飞速发展,人们获取新闻的方式发生了很大的改变,已从电视、报纸等传统媒体转向新闻网站等互联网媒体。新闻关键词能勾勒新闻的轮廓,反映新闻的主题;同时,新闻关键词也可以用于新闻的分类和检索,因此,对新闻标注关键词是十分必要的[1]。人工选取关键词虽然准确性高,但效率低。为了提高效率,必须利用相关算法自动抽取新闻关键词。
关键词抽取方法分为有监督和无监督两种。有监督方法将关键词抽取转化为二分类问题,即首先构造一个词表,再针对文档集中的每一个文档,标注词表中的哪些词是该文档的关键词,然后用标注的文档集训练分类器。有监督方法需要构造词表,标注语料,代价太大,而无监督方法没有这些要求,因而应用更广泛。无监督关键词抽取算法主要有三类:基于统计特征的抽取算法,常用的统计特征是TF-IDF;基于词图模型的抽取算法,如TextRank算法;基于主题模型的抽取算法,如LDA[2]。其中,基于词图模型的抽取算法,特别是TextRank算法具有理论完备、实现简单、性能优良的特点而被广泛应用。鉴于此,本文将其应用于新闻文本关键词抽取,设计并实现了基于TextRank算法的新闻文本关键词抽取系统。该系统可以辅助新闻编辑人员标注新闻关键词,提高工作效率。
1 关键词抽取的相关技术
1.1 TextRank算法
TextRank算法的思想源于Google的PageRank算法[3]。用一个有向有权图G=(V,E)来表示TextRank普通模型,由点集合V和边集合E组成,E为V×V的子集。用wji表示任两点vi,vj之间边的权重,对于一个给定的点vi,In(vi)表示指向该点的点集合,Out(vj)表示点vi指向的点集合,点vi的权重ws定义为:
其中,d为阻尼系数,取值范围为0到1,代表从图中某一特定点指向其余任意点的概率,一般取值为0.85[4]。
基于TextRank的关键词提取步骤为:
(1)把给定的文本T按照完整句子进行分割,即:T=[S1,S2,…,Sm],其中,m为句子数量。
(2)关于每个句子Si∈T,对其进行分词和词性标注处理,并除去掉停用词,只留下指定词性的单词,如名词、动词、形容词,即Si=[S(i,1),S(i,2),…,S(i,n)]为候选关键词,n为候选关键词的个数。
(3)构建候选关键词图G=(V,E),其中,V为节点集,由步骤(2)生成的候选关键词组成,而后运用共现关系构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K为窗口大小,即最多共现K个单词。其中,在这里K值的设定不同,可能导致抽取的关键词可能会有所区别。
(4)根据上面的权重计算公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,即为关键词。
1.2 中文分词与词性标注
与英文不同,中文文本词语之间没有界限。在对中文文本进行处理前,一般需要对其进行分词,根据具体情况还需要同时进行词性标注。经过多年的研究,中文分词技术取得了很大的进展,出现了不少成熟的分词软件,例如:结巴分词、哈工大的LTP、复旦大学的FudanNLP、北京理工大的NLPIR-ICTCLAS等。本系统选择NLPIR-ICTCLAS系统,该分词系统采用层叠形马尔科夫模型(CHMM)进行分词,通过分层,既增加了分词的准确性,又保证了分词的效率。NLPIR-ICTCLAS系统采用北大标准/中科院标准的词性对照表。表1展示了本系统涉及的名词、动词、副词、形容词的词性对照表。
2 基于TextRank的新闻关键词抽取系统
2.1 系统总体设计
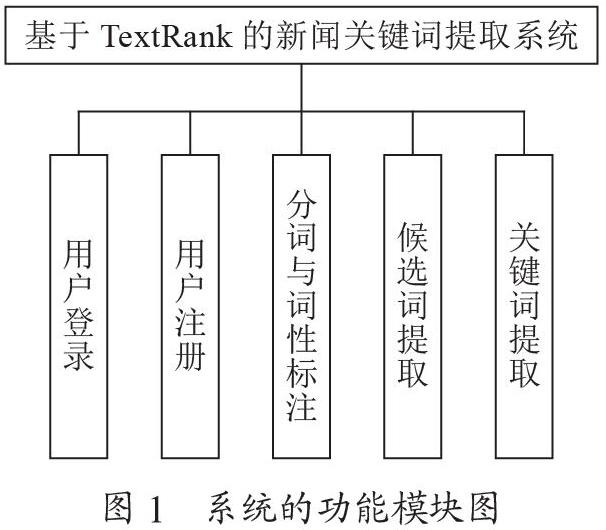
系统的功能模块图如图1所示。
系统主要包含5个功能模块,分别是“用户登录”“用户注册”“分词与词性标注”“候选词提取”“关键词提取”。
系统启动后,首先进入“用户登录”界面,如果登录成功,即进入“分词与词性标注”界面,然后依次进入“候选词提取”界面,“关键词提取”界面,如果是新用户,则首先需要注册,然后才能登录。系统的运行流程图如图2所示。
2.2 系统详细设计与实现
本软件用Java语言编写,包含5个界面,分别对应于5个功能模块。其中“用户登录”“用户注册”功能与一般软件类似,在此略过,重点介绍另外3个模块的功能。
2.2.1 分词与词性标注模块
首先在文本框中输入或者粘贴新闻文本,“分词与词性标注”模块通过调用NLPIR-ICTCLAS汉语分词系统(2016版)对待提取关键词的文本进行分词和词性标注,并显示结果,如图3所示。
2.2.2 候选词提取模块
“候选词提取”模块用于从已分词和标注词性的文本中挑选出候选关键词。候選关键词一般为名词,也可以增加动词,形容词或者副词,用户可以根据实际情况选取,名词必选。选择候选关键词的词性后,点击候选词提取,所有候选关键词即出现在下部文本框中,如图4所示。
2.2.3 关键词提取模块
“关键词提取”是本软件的核心模块。关键词提取采用TextRank算法。对于关键词提取功能,需要设置两个参数,一个是TextRank算法所需要的窗口大小,另一个是关键词的个数。参数设置好后,点击“提取关键词”按钮,左边的文本框即显示所提取的关键词以及关键词的TextRank值,如图5所示。
2.3 软件性能测试
为了测试本软件对新闻文本抽取的关键词的准确性,本文从凤凰网新闻板块随机选取了10篇新闻进行测试。这些新闻均已标注了关键词,以下为其中一篇新闻的部分页面HTML代码:
上述HTML代码中,名称为“keywords”的meta数据即为关键词。
通过观察,这10篇新闻的关键词均为名词,个数平均为6个。基于此,将系统中三个的参数分别设置为:候选关键词的词性只选名词,窗口大小设置为10个,关键词个数设置为6个。将系统抽取的关键词与已标注的关键词进行对比,准确率为69%,即6个关键词中平均有约4个属于已标注的关键词。
3 结 论
本文设计并实现了基于TextRank的新闻关键词抽取系统。设置相关参数后,系统可以运用TextRank算法抽取新闻文本中的关键词。通过在一定数量的实际新闻文本上进行测试,结果表明该系统具有较高的准确性。本系统采用的是经典的TextRank算法。虽然该算法简单高效,但也具有主题相关性不高以及忽视新词等缺点,下一步将考虑引入改进的TextRank算法。
参考文献:
[1] 陶洁.基于新闻文本的关键词提取 [D].武汉:华中师范大学,2019.
[2] 田脉.新闻文本关键词提取算法研究与实现 [D].武汉:中南财经政法大学,2019.
[3] MIHALCEA R,TARAU P.TextRank:Bringing Order into Texts [C]//Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing.Barcelona:Association for Computational Linguistics,2004:404-411.
[4] Together_CZ.TextRank杂谈 [EB/OL].(2017-04-09).https://blog.csdn.net/together_cz/article/details/69935286.
作者简介:欧霖(1998—),男,汉族,广东惠州人,本科,研究方向:自然语言处理;赵永标(1980—),男,汉族,湖北洪湖人,讲师,硕士,研究方向:自然语言处理。
