基于机器博弈的点格棋智能系统的优化研究
2020-02-22姚想
姚想
摘 要:人工智能的发展常以棋类为先锋。计算机博弈因其特点已成为人工智能发展的重要分支:棋中战术遵循规则,胜负可判,棋力可考,可复现性强,具有人机对抗与纯机器博弈两种测试方式,能直观反映出人工智能的发展水平。本文以点格棋为研究对象,通过创建棋盘数据结构、模拟招法选择、棋局树搜索及优化等方式,实现完整点格棋智能系统的构建;同时与传统的Alpha-Beta搜索进行对比,说明本文算法优化的提升效果及意义。
关键词:人工智能 计算机博弈 点格棋 优化
中图分类号:TP181 文献标识码:A 文章编号:1674-098X(2020)10(a)-0132-03
Abstract: Chess is often applied as a pioneer in development of AI (artificial intelligence). And computer game has become an essential branch of AI development due to the following characteristics: Tactics in chess obey certain rules; victory and level of the program can be judged or measured; great reproducibility can be shown. There are two test methods including man-machine counterwork and machine-machine counterwork, which can both reflect the level of development of AI intuitively. Dots-and-Boxes is chosen as the research object. Establishment of the AI system can be realized by basic chessboard data structure, simulation on choices of moves, tree search and optimization. Meanwhile, compared with the conventional Alpha-Beta search, innovative value and great meaning of this algorithm optimization can be shown clearly.
Key Words: Artificial intelligence; Computer game; Dots-and-Boxes; Optimization
計算机博弈(亦称机器博弈),是20世纪50年代产生的新兴领域。其根源最早可追溯到公元前古希腊的著名思想家亚里士多德,他奠定了形式逻辑的基础。计算机自发明以来发展迅猛, 机器博弈,作为典型的反映计算机智能水平的领域,逐渐成为热门研究方向。欧美国家起步较早,已经发展并研究出如“深蓝”、“AlphaGo”这样广为人知的顶级程序,在其他复杂、不适合人类对弈(因此鲜为人知)的棋类竞赛中,也占据着领先地位。国内对棋类的研究尚处在起步阶段,本文设计的点格棋的智能系统不同于国内常规,具有一定创新性和价值。
1 点格棋基本规则及术语
1.1 基本规则
点格棋(即Dots-and-Boxes),是法国数学家爱德华·卢卡斯于1891年推出的两人纸笔游戏,常用6X6规格的正方形棋盘。共两方选手,双方轮流走招法,所下的是棋盘上的边(纵向、横向),共60条边为有效招法。终局:当所有有效边均已被下则游戏结束。得分:当一方补全正方形最后一条边,则该方得一分。胜负判断:终局后得分更多的一方获胜。另一方失败。特殊规则:连下,当有一方得分,则不交换走棋方,必须继续填补其他边,直到未得分或终局。
1.2 术语
点格棋中存在一些固定的棋形术语。chain:长链,占有的格数固定且大于等于3,在长链中所有格子度均为2,且有两端在边界。short chain:短链,与长链类似,但占有格数小于3。circle;环,所有格子度为2,占据格子固定,但完全封闭。degree:度,起始每个格子度为4,终局应当每个格子度为0。度即为每个格子空闲边的数量。double cross:双交,对于长、短链或环来说,接下来走棋的一方走一步可以得两分,这样即为双交。
2 点格棋基础数据结构及算法实现
2.1 棋局表示
点格棋的棋盘是走边,与围棋、五子棋这样走交叉点的棋局有着显著区别,相比于五子棋的落子可以简单地用(x,y)二维坐标来表示,如何表示每条边、棋盘的数据结构就尤为重要。点格棋中弱化了点的作用,关键在于所下的边和占据得分的格子,分别用两个数据结构来表示边和格子。
struct BOXES{Edge_near near[4]; int degree;int id;int owner}; struct EDGES{int captured;Box_near box_near[2];int id;int flag;};BOXES结构即为格子。棋盘的全部格子存在boxes[boxes_size]数组中,结构内的near[4]数组用于存放一个格子周围的四条边,建立起格子对应的边的联系,其他有必备信息如记录格子占有方、下的边数,并将全部格子顺序编号。EDGES结构即代表边。棋盘上的边存在一维数组,通过box_near[2]数组存放该条边所属的两个(或一个)格子,建立起边对应的格子的联系。除此之外,还需要边在棋盘中的位置、编号、以及留待后续使用的信息。
2.2 招法产生
棋盘中所有没下过的边都可以作为接下来的有效招法。每当要产生招法时遍历棋盘上的全部owner=0的边即可。但需要注意,在点格棋中,存在chain(长链)的棋形,当一方在长链中下任意一条边,对方可将这条长链全部连下。如果未全部下完,则下回合轮到该方行棋时可补全,因此对于对方来讲,全部补全是一种较好的策略,此时纯随机显然不明智。这就为后续招法筛选和优化做了铺垫。
2.3 搜索
2.3.1 MC (Monte Carlo method)
蒙特卡洛方法,也称统计模拟方法,产生于20世纪40年代,主要基于概率统计和数值计算。模拟棋类博弈中对于一个已有的局面,每次行棋都随机下一条边(或落子),直到游戏终局。这样的下棋持续上千万次或更多,最后得到的一方胜率将近似成这个局面真实的胜率。将蒙特卡洛方法应用到计算机博弈上,可以有效地模拟并统计当前局面下,一盘棋局的胜率。双方按照规则随机下任意边,随着棋局的进行,每一个对方的招法对应的我方招法有多种,反之亦然。逐层扩展,少量的上层节点呈指数级展开到下层节点,就引入了招法树(蒙特卡洛树搜索)。
2.3.2 MCT (Monte Carlo Tree) 与UCT (Upper Confidence Bound Apply to Tree)
蒙特卡洛树,也即蒙特卡洛树搜索。每个节点存储的信息是当前棋局上一步的玩家、招法以及胜负信息。除此之外,规定sim_max与sim_min作为单个节点的最大、最小模拟量。player用于记录玩家;visit用于记录实际模拟量;win记录胜场;depth记录节点所在树的深度。对于一次模拟,首先把当前局面这个节点设为根节点,如果当前节点模拟量(visit)大于等于sim_max,就访问它的子节点,没有则扩展子节点。在子节点中寻找胜率最高的节点,继续设为当前节点,实质是递归的过程。对于模拟量小于sim_min的节点,默认初始给出一个极大值作为其胜率(rate),否则rate=win/total。这保证了模拟量小的节点优先访问,也就是所有节点均保证基础模拟量。对当前节点代表的棋局进行随机模拟,得出胜负,完成了一次模拟。这次模拟的结果会通过反向更新影响其上层节点。伪代码如下:for (从当前节点到根路径上的全部节点,包含现、根节点){节点visit自增1;if (该节点player与模拟的胜利玩家相同)该节点win自增1;}重复这样的模拟-更新过程,直到步时到达或访问量足够。而UCT(上限置信区间算法)则是对蒙特卡洛树搜索选取节点策略的改进。其综合了胜率与节点模拟量,为模拟量小,可能出现误判的节点增加了被选择的机会。
2.3.3 与传统算法对比
Alpha-Beta算法是对极大极小算法(min-max)的优化,也是一种对博弈树的剪枝策略。其在搜索时,需要扩展完全的一层节点后返回胜率视为有效。博弈树的扩展呈指数级,因此Alpha-Beta面对限时情况,不可避免地会在最后一层浪费巨大的模拟量,做无用功。而UCT因其搜索树非对称扩展的特性,可在搜索过程中随时中止并返回选择招法。Alpha-Beta算法的估值(Evaluation)函数也至关重要。它执掌评判局面、招法选择的大权。然而局面估值依据人类所认为的优势与劣势走棋进行赋值,棋力有限,长久以来围棋AI棋力不佳可作例证。UCT则以统计学为依据,其招法未必符合人类常识,却是经全盘考虑、基于数千万模拟次数得到的最佳招法。但Alpha-Beta方法也有可取之处。终局阶段Alpha-Beta借助估值函数收敛快,能走出最快取胜的招法;而UCT此时因为局面甚优,节点之间胜率差异不大,树处在平均扩展的状态,最终结果是取胜,但其过程很大几率会走弯路。因此残局阶段使用Alpha-Beta进行估值快速取胜,可作为今后的优化方向之一。整体看,二者各有利弊,然UCT表现出更多亮点,尤其是以模拟代替估值,去除了人类固有思维的影响,使得计算机博弈的发展有极广的探索空间。
4 算法优化
4.1 招法合并
对于点格棋,招法本身随机。但由于点格棋的连下机制,招法结果只可能为全吃或双交,所以在UCT过程中将连下的边合并成同一招法,记录并保存。这样做的结果会减少大量和重复的无用搜索过程,使棋力、智能性提升。
4.2 搜索改进实现:AMAF
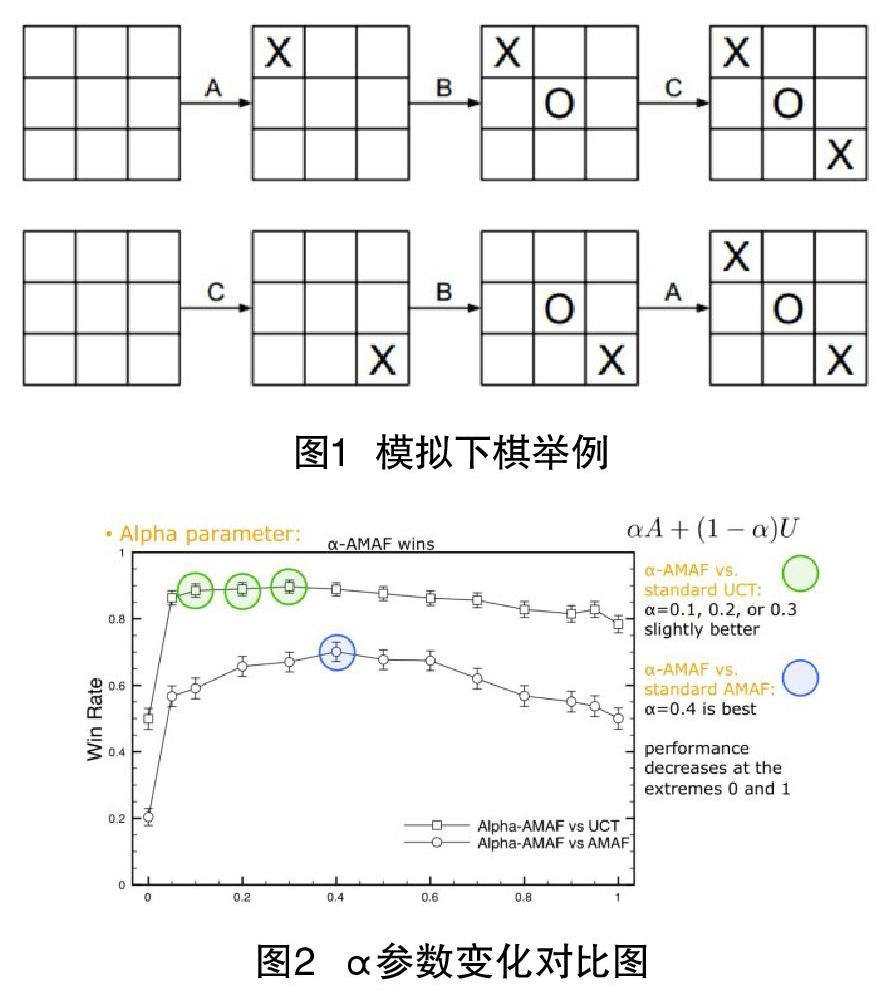
在AI模拟过程中,可能不同的节点在某次模拟中达到了相同的状态,但这时却把他们看作两个不同的节点。而AMAF算法,它认为使棋盘达到某一相同状态的所有的着法都是等价的,如图1所示。
經A、B、C三步后得到当前的盘面状态,这三步的顺序可能不同,但是得到状态是相同的,故视为等价。基本的AMAF算法在每次AI模拟下棋之后将UCT与AMAF更新相组合。该算法快速增长UCT树中的节点处的计数,并因此增加算法对胜率的置信度。另一方面,节点处的计数增加不是因为移动是在由父节点表示的位置进行的,而是因为它是在不同的模拟环境中进行的。改进的α-AMAF算法混合了来自标准更新和AMAF更新的值估计。它在每个节点保存两组计数,一个用标准UCT更新而其他更新用AMAF更新。α-AMAF估计节点的值为α乘以估计值AMAF更新计数加上(1-α)乘以来自标准UCT更新计数。因此,α= 0对应于标准UCT算法,α= 1对应于基本AMAF算法。其中α参数变化对比图如图2所示。
5 结语
本文通过巧妙构造的数据结构及算法解决了棋局表示和招法选择的难点,实现完整的点格棋智能系统。同时对已有的招法搜索模拟进行优化,在对弈方面取得了更好效果。采用的蒙特卡洛方法已在各领域作数值分析、计算等用途,应用广泛,因此优化亦可供多领域参考,作为将来研究的发展方向。
参考文献
[1] 唐霜霜.点格棋机器博弈系统的研究与实现[D].合肥:安徽大学,2015.
[2] 何轩,洪迎伟,王开译,等.机器博弈主要技术分析——以六子棋为例[D].吉首:吉首大学,2019.
[3] 邵向阳,许敏.计算机人工智能技术的应用及未来发展初探[J].科技创新导报,2019(29):114-116.
[4] 王玲玲.人工智能在计算机网络技术中的应用[J].科技创新导报,2019,16(34):152-153.
[5] 周珂,王祺.一种基于无监督学习的博弈算法设计[J].新技术新工艺,2020(4):30-33.
[6] 郑欢.基于SOPC的人机博弈系统设计与实现[J].四川水泥,2019(4):109.
