基于特征重要度的广告点击率预估模型
2020-02-22周菲
周菲


摘要:针对现有的点击率预估模型忽略了不同特征的重要程度的问题,提出了一种基于特征重要度的广告点击率预估模型,首先模型在DeepFM模型的基础上使用Squeeze-and-Excitation网络动态学习特征的重要性,其次将FM和DNN输出结果进行拼接,通过后续的多层感知机层进一步学习特征的高阶特征交互信息。通过对比了两个公开数据集,实验结果显示,基于特征重要度的广告点击率预估模型相比其他模型得到更好的表现。
关键词:广告点击率;特征重要度;DeepFM;多层感知机;特征交互
中图分类号:TP-18 文献标识码:A
文章编号:1009-3044(2020)36-0012-03
Abstract: As one of the core tasks of recommendation systems and online advertising, advertisement click-through rate prediction is an essential topic in academia and industry. Aiming at the problem that the existing click-through rate prediction models care less about the importance of features, this paper proposed a new model. On the one hand, the new model learned the importance of features via the Squeeze-and-Excitation network on the basis of the DeepFM. On the other hand, the model proposed to further concatenate the outputs of FM and DNN ,it is able to effectively learn the high order feature interactions via multi-layer-perception. By comparing two public data sets, the experimental results show that the new model shows better performance than other models.
Key words: click-through rate; importance of features; DeepFM; multi-layer-perception; feature interactions
1 引言
廣告点击率(Click-Through Rate,CTR)指的是给定用户和网页内容,广告被点击的次数占总展示次数的比例[1]。当前的大数据场景下,广告由过去的“粗放式”投放正在向“精准化”投放转变,以数据驱动的广告精准投放已经成为当前广告投放的主流方式,在广告需求方的程序化购买和在线投放过程中,需要预先评估用户对广告的偏好程度,而衡量这一重要指标的过程就是CTR预估,CTR的准确度不仅影响广告产品的收益,同时也影响用户的体验度和满意度。
传统的CTR预估主要采用逻辑回归(Logistic Rehression,LR)[2],POLY2模型[3],因子分解机模型(Factorization Machine,FM)[4]等。随着深度学习的兴起,基于深度学习的CTR预估模型在探索特征之间的高阶组合方面取得了大幅进展,其中,代表性的CTR预估模型:如微软的DeepCrossing[5]、谷歌的Wide&Deep[6]、华为的DeepFM[7]等,DeepFM由FM和DNN两个组件构成,它们共享相同的输入,从而可以同时从原始特征中学习出低阶和高阶特征交互信息。然而这些模型忽略了建模不同特征的重要程度,对于不同的预测目标来说,不同特征的重要程度是不同的。举例来说:目标任务为预测用户是否会买《机器学习》这本书,那么该用户的职业这个特征就比用户的其他特征如:性别、收入等重要得多。
文献[8]提出了Squeeze-and-Excitation(SENET)网络,该网络旨在显式地建模特征通道之间的相互依赖关系,使得模型自动学习图像不同通道的特征的重要程度,该网络赢得了ImageNet 2017分类任务竞赛的冠军。除了图像分类任务,SENET网络也被用于其他的领域,文献[9]将SENET模块用于语义分割任务。文献[10]将SENET模块扩展为一种综合全局和局部的注意力(global and local attention,GALA)。
综上,在DeepFM的基础上,本文提出一种SeDeepFM模型, SeDeepFM结构采用Squeeze-and-Excitation网络动态学习特征的重要程度,同时为了充分对特征进行交叉,本文将FM的输出和DNN的输出进行拼接并输送给后续的多层感知机,实验证明该模型有效提升了CTR预估的准确率。
2 基于特征重要度的广告点击率预估模型
本节将详细介绍论文提出的SeDeepFM模型,如图1所示。首先介绍特征的表征,然后自底向上地逐一介绍模型的各个组件,包括:1)嵌入层,用于将从原始特征转化为对应的嵌入向量;2)SENET层,用于动态学习特征之间的重要程度;3)DeepFM层,用于学习特征之间的低阶和高阶交叉信息;4)拼接层,将FM模块的输出结果和DNN模块的输出结果进行拼接,将拼接的结果输送给后续的多层感知机层;5)多层感知机层,通过多层神经网络进一步学习特征的高阶交叉信息。
2.1 特征的表征
原始类别型特征,如性别、手机型号等,需要经过onehot编码[11]轉化成onehot向量: [x=[x1,x2,...,xf]],[x∈Rd],[d]为onehot向量的维度,[f]为特征域的个数,数值型的特征为自身的值,通常onehot向量[x]是一个超高维且稀疏的向量。
2.2 嵌入层
嵌入层将onehot编码后的高维稀疏向量转化为低维稠密向量:[E=[e1,e2,...,eM]],[M]为稀疏特征的特征域个数,[ei]为第[i]个特征域的Embedding向量,[ei∈Rk],[K]为Embedding向量的维度。为了让类别型特征和数组型特征进行特征交叉,同样将数值型特征转化为一个[K]维的向量[en],[en∈Rk]。
2.3 SENET层
如图2所示,SENET模块主要包含压缩、激励、重标定这3个步骤,下面分别进行说明。
2.3.1 压缩Squeeze
该步骤用于特征的压缩,通过平均池化将原Embedding向量转化为统计向量,使得每个特征域的统计向量具有“全局信息”,压缩后的统计向量[S=[s1,...,si,...,sf]],[si]公式表示如下:
其中[S]为经过特征压缩后的统计向量,[K]为Embedding向量的维度,[si]为经过平均池化后的第[i]个特征域的统计向量。
2.3.2 激励Excitation
该操作主要由两层全连接层组成,通过对统计向量[S]的每个特征域生成权重向量[G],从而显式建模特征通道间的相关性,公式表示如下:
2.3.3 重标定Re-Weight
该操作用于将学习到的特征通道的相关性[G]按照相应的特征域加权到原Embedding向量上,从而完成对原Embedding向量的“重标定”。公式表示如下:
2.4 DeepFM层
DeepFM由FM和DNN两个组件构成,下面分别对FM和DNN进行说明。
2.4.1 FM
在FM中,通过对特征i、特征j的隐向量[Vi]、[Vj]计算內积,从而学习二阶的特征交叉。公式如下:
2.4.2 DNN
DNN是一个包含多个隐层的前向神经网络,用来学习特征之间的高阶交互信息。将SENET层的输出向量[L=[l1,...,li...,lf]]作为DNN的输入,公式如下:
其中H为前向神经网络的层数,[LH]分别为第H层的输出,同时作为H+1层的输入,[WH]、[bH]为第H层的权重和偏置。
2.5 拼接层
拼接层用于拼接FM和DNN的输出向量,将拼接后的结果[C]作为后续网络的输入,公式表示如下:
2.6 多层感知机层
多层感知机层是一个包含多个隐层的前向神经网络,用于对FM和DNN拼接后的结果进一步特征交叉,学习高阶特征的交互信息,公式如下:
其中[Y]为前向神经网络的层数,[CY]分别为第[Y]层的输出,同时作为[Y+1]层的输入,[WY]、[bY]为第[Y]层的权重和偏置,[WY∈RnY×nY+1],[nY]为第[Y]层隐节点个数,[nY+1]为第[Y+1]层隐节点个数。[σ]为激活函数,隐层节点的激活函数为ReLU[12]。前向神经网络的最后一层连接输出节点,输出节点的激活函数采用[Sigmoid][13]激活函数,预测点击率公式如下:
[WZ]为最后一个隐层到输出节点的权重向量,[CZ]为最后一个隐层的输出向量,[bZ]为输出节点的偏置。
2.7 计算模型的损失函数
为了对模型的权重和参数进行学习,论文中将对数损失函数(也称为logloss[14])作为模型的目标函数,公式表示如下:
其中, [L(θ)]为模型的对数损失函数, [θ]表示模型的参数,[p(xi,θ)]为样本[i]的特征向量[xi]基于当前模型的参数[θ]计算得到的预测点击率,[yi]为样本[i]的真实标签,有点击的为1,无点击的为0, [N]为样本的总数。
3 实验部分
为了对提出的SeDeepFM模型的预测结果进行评价,本文基于Criteo数据集和Avazu数据集这两个公开数据集完成了一系列实验。本节首先对数据集和评价指标进行介绍,其次简要介绍数据的处理及关键参数设置,最后通过实验展示SeDeepFM模型的预测性能,并对实验结果展开讨论。
3.1 数据集及评价指标
本文采用的Criteo数据集是Criteo公司在2014年 Kaggle平台发起的广告点击率预估的数据集,Avazu数据集为Avazu公司提供的10天的广告点击数据,采用的评估指标为AUC[15]和logloss[14]。AUC被认为是CTR预估问题的一个重要指标。AUC越大,说明CTR预估模型的性能越好,logloss越小说明CTR预估模型的性能越好。
3.2 数据的处理及关键参数设置
我们随机选择80%的样本作为训练集, 10%的样本作为测试集,剩下10%的样本作为验证集。Embedding的大小设置为16,DNN隐节点个数设置为[32,32],batch的大小为1000,模型的优化器为Adam[16],学习率设置为0.001。
3.3 实验结果及分析
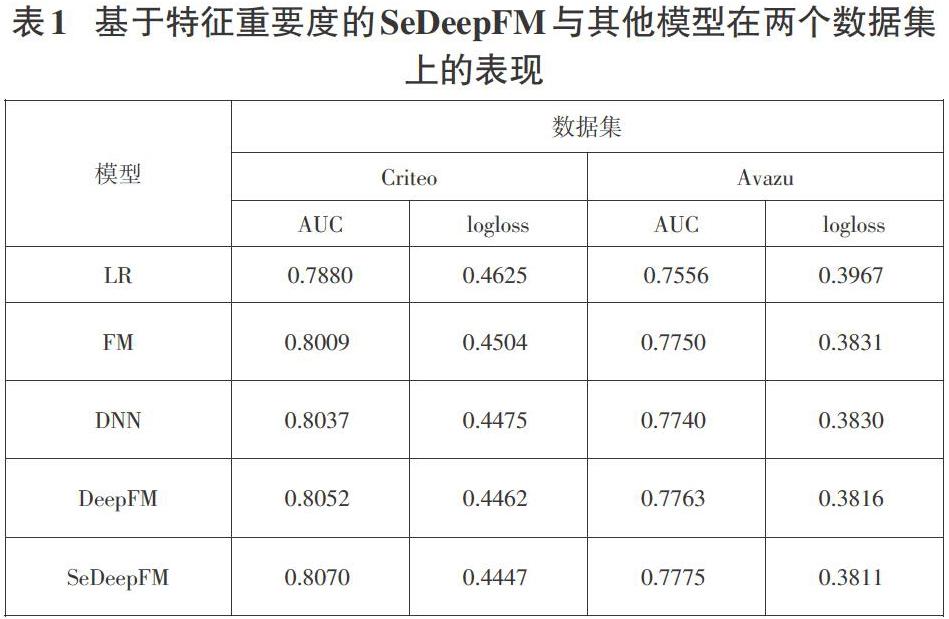
本次实验将LR设置为基线模型,从表1我们可以看出, FM和DNN的AUC相比LR有了大幅提升进一步说明特征交叉的重要性。SeDeepFM在DeepFM的基础上通过SENET模块动态学习特征的重要程度,同时将FM和DNN的输出进行拼接并通过多层感知机层进一步学习特征的高阶组合信息,从而在两个公开数据集上得到最好的表现。
4 结束语
本文中,我们提出了一个全新的CTR预估模型SeDeepFM。该模型提出了将SENET模块應用于CTR预估任务,本文展示了使用SENET学习特征重要度的细节,同时在DeepFM的基础上设计了多层感知机层进一步学习高阶特征交互,通过实验证明了SeDeepFM模型的有效性。
参考文献:
[1] 周傲英, 周敏奇, 宫学庆. 计算广告:以数据为核心的Web综合应用[J]. 计算机学报, 2011, 34(10): 1805-1819.
[2] Chapelle O, Manavoglu E, Rosales R. Simple and scalable response prediction for display advertising[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2014, 5(4): 1-34.
[3] Chang Y-W, Hsieh C-J, Chang K-W, et al. Training and testing low-degree polynomial data mappings via linear SVM[J]. Journal of Machine Learning Research, 2010, 11(4).
[4] Rendle S. Factorization machines[C]//Proc of the 2010 IEEE International Conference on Data Mining,IEEE.2010: 995-1000.
[5] Shan Y, Hoens T R, Jiao J, et al. Deep crossing: Web-scale modeling without manually crafted combinatorial features[C]//Proc of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining.2016: 255-262.
[6] Cheng H-T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proc of the 1st workshop on deep learning for recommender systems.2016: 7-10.
[7] Guo Huifeng, Tang Ruiming, Ye Yunming, et al. DeepFM:A factorization-machine based neural network for ctr prediction[C]//Proc of the International Joint Conference on Artificial ustralia, 2017: 1-7.
[8] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proc of the IEEE conference on computer vision and pattern recognition.2018: 7132-7141.
[9] Roy A G , Navab N , Wachinger C . Recalibrating Fully Convolutional Networks with Spatial and Channel 'Squeeze & Excitation' Blocks[J]. IEEE Transactions on Medical Imaging, 2018, 38(2):540-549.
[10] Linsley D , Scheibler D , Eberhardt S , et al. Global-and-local attention networks for visual recognition[J]. 2018.
[11] Weinan Z, Tianming D, Jun W. Deep learning over multi-field categorical data a case study on user response prediction[C]//Proc of the Conference on Information Retrieval.2016: 45-57.
[12] Nair V, Hinton G E. Rectified linear units improve restricted boltzmann machines[C]//Proc of the ICML.2010.
[13] Marreiros A C, Daunizeau J, Kiebel S J, et al. Population dynamics: variance and the sigmoid activation function[J]. Neuroimage, 2008, 42(1): 147-157.
[14] Altun Y, Johnson M, Hofmann T. Investigating loss functions and optimization methods for discriminative learning of label sequences[C]//Proc of the 2003 conference on Empirical methods in natural language processing.2003: 145-152.
[15] Lobo J M, Jimenez-Valverde, Real R. AUC: a misleading measure of the performance of predictive distribution models[J]. Global Eco-logy and Biogeography, 2008, 17(2): 145-151.
[16] Kingma D , Ba J . Adam: A Method for Stochastic Optimization[J]. Computer ence, 2014.
【通联编辑:梁书】
