一种基于高校学生行为数据的改进关联算法
2020-02-22孙新杰孙国营管彦允李伟
孙新杰 孙国营 管彦允 李伟
摘要:随着高校数字化校园的建立,越来越多的学生行为数据可以通过电子的形式得以存储,针对这些数据提出一些关注的特征值,并针对这些特征值进行进一步的处理达到一种切合实际的数据模型,并针对该模型提出一种改进的Apriori关联算法,通过修改权重,对原始统计数据进行区间化处理等技巧,实现了W_S_Apriori算法,并通过实验严重了该算法的有效性。
关键词:数字化;特征值;关联;W_S_Apriori算法
中图分类号:TP391 文献标识码: A
文章编号:1009-3044(2020)36-0024-03
1 引言
随着互联网的高速发展及越发强大数据收集管理工具的诞生,如何高效找到数据之间的关系显得至关重要。关联分析是数据挖掘领域一个重要处理数据关系的手段,能够从大数据中找出数据之间的关联并进一步挖掘出数据之间潜在价值是关联分析的重要使命。
关联分析已经应用于生活中的很多方面,如购物、交通等。随着近几年国家对高等教育的不断投入,大学校园基本已经建立起了一套完善的数据采集与存储设备,学生在校园中使用网络留下的数据都以不同形式存在于存储设置之中。但是近年来对于高校学生数据的研究并没有进行过多针对性的关联分析算法研究,如何在教育领域,对教育大数据进行预测与关联分析显得十分有必要。
2 相关概念及技术基础
分析教育大数据之间的关联行为,必须首选确定好教育大数据的来源。校园一卡通数据基本包含了学生的教育大数据的来源,如成绩、图书借阅、寝室门禁、食堂就餐等数据。通过针对性的数据挖掘技术从一卡通数据中找出未知有价值的信息,从而指导改善学生在校期间的校园行为,有针对性地提出提高学科成绩模型[3]。
关联分析技术是一种使用频繁项目集来寻找数据之间的关联性的。下面就常见的关联分析算法的优缺点进行简单的阐述。
Apriori算法是通过首选确立频繁1项集,然后在该1项集的基础上进一步寻找频繁2项集,以此类推直到达到设定的阈值为止。该算法的优缺点都非常的明显,对整个数据源需要多次的访问,保证了数据了完整性,但是也大大削弱了算法的时间效能;该算法的运行特性导致产生大量的候选数据项集,浪费运行空间;而且该算法采用的支持度不能发生变化,导致该算法无法对各个指标进行个性化的考虑使用。
FP-Growth算法采用的不同于Apriori的算法技巧,它使用的是“分治”的方法。该算法是把频繁项集进行高度的压缩,然后再把压缩后的数据项集按条件进行拆分,然后分别对拆分后的数据库进行关联分析的挖掘。但是该算法也有它自己的不足之处,比如生成的树的叶子节点过多,而且该树只生成了前缀树,这样进一步削弱了算法的效能,由于“分治”的思想实现是采用递归的这种思维模式,该模式需要消耗大量的计算内存,导致该算法应用面缩小。
3 教育大数据的预处理与特征提取
要想对教育大数据进行挖掘,同样需要对这些数据进行处理,对数据的预处理的质量直接绝对数据挖掘的质量。本论文主要对学生行为中的图书资料借阅信息、一卡通等记录进行格式化的预处理。下面分别对这些原始数据信息进行预处理。
3.1 图书资料借阅信息特征提取
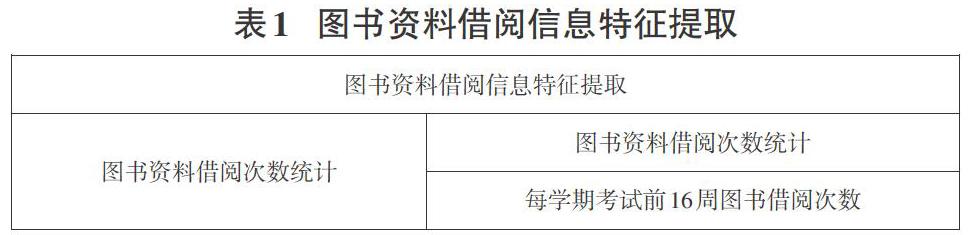
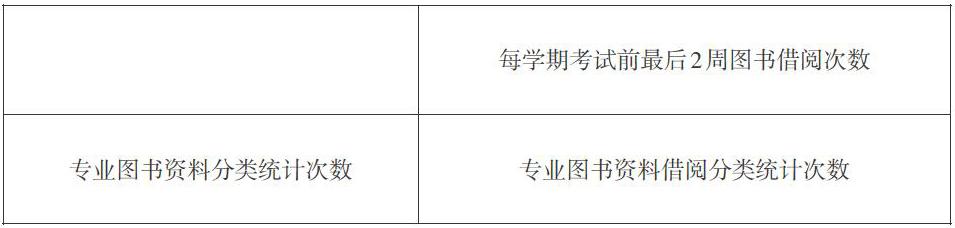
图书资料借阅信息的提取直接关系到学生行为对成绩的影响[1],该项权数据意义重大,提取的图书借阅特征有“图书借阅学生学号”“图书借阅时间”“图书借阅ISBN号”“图书分类识别号”。通过对“图书借阅学生学号”进行统计可以得出该生某段时间内的借阅图书的总次数,以及通过“图书借阅学生学号”和“图书分类识别号”可以统计出学生借阅专业书籍的次数。通常情况下根据我校(六盘水师范学院)实际情况,每到期末考试前的最后2周都是学生集中借阅专业资料的黄金时段,该时段的借阅图书统计科研单独列出进行数据的挖掘,具体提取指标如表1所示。
3.2 自习时间特征提取
很多自习室需要使用一卡通进行刷卡才能进入进行学习(包括图书馆内部的自习室),这就为数据的统计带来了方便,通过统计学生自习室的开放时间以及学生进入自习室自习的时间可以很好地获取学生投入到学习中的时间占比。这里需要进行一些更加复杂的时间处理,首先应获取学生的课表时间,在课表之外的时间进行学习占比的统计会更加的客观,次数占比是除课表外的不低于1个小时的空闲时间进行时间段的统计,有效时间长度占比以每次自习时间不低于20分钟进行占比统计。这里的统计方式与图书资料借阅基本类似,不再进行详细的阐述,具体见表2所示。
3.3 食堂就餐特征提取
食堂就餐数据的处理相对比较烦琐,不同地域不同家庭的同学就餐的样书及就餐的金额差距都比较大,没办法给出一个标准来衡量不同学生的这些数据的优劣程度。这里为了公平起见,需要对某些数据进行归一化处理,并且对处理后的数据只统计每学期就餐时间的平均值,分别按早餐、午餐、晚餐三餐时间进行统计[2],并通过拉格朗日填充数据的方式对空缺值进行填充处理,详情如表3所示。
4 实验分析
在进行关联分析中,支持度是统计频繁项集在总数据中的占比,如公式(1)所示。
置信度是指当某个事件A发生时,另外一个事件B发生的概率问题,如公式(2)所示。
提升度是某事件A出现的时候,事件A和B一起出现的概率与事件B独自出现的概率的比值,如公式(3)所示。
4.1 就餐时间依据范围归一化
采用Apriori算法思想非常的简单就是不断地扫描数据然后统计K-项集,只要满足支持度的要求都可以进入下一轮的计算,但是这样导致有些数据出现的频率不高,但是可能起到十分重要的作用的数据不能在该算法中得到有效的利用。特别是就餐时间统计,由于每个人生活习惯的不同,比如不能简单地把早上6:30起床吃早饭的同学认为优于喜欢晚吃早饭的同学,这样就导致在进行数据关联时容易出现无效的关联。本文的处理方式是把就餐均值进行范围式重定义,如早餐时间落在6:30-7:30之间的统一设定一個时间均值,其他就餐时间依据一小时为间隔范围进行重新归一化处理,认为在该段时间内就餐是没有区别的,不然根据Apriori算法思想很难进行进一步的处理。时间处理如公式4所示,T_mixi代表就餐均值时间,Scan{T1|T2|T3……|TN}代表规定的好的区间,在不同区间给出不同的值赋值给Avg_Mixi,Avg_Mixi就代表最终的该项值并参与关联规则的建立。
4.2 加权的项集
传统的Apriori算法对所有的数据处理方式都是进行直接计数的方式,这种方式就是用起来比较简单,但是容易把一些不是常出现,但是可能起到很重要的数据过滤掉,本文采用一种加权的方式对数据进行进一步的处理,在关注的学生行为数据中图书借阅相关数据首先应进行处理,因为学校对每个学生的借阅数量有硬性要求,每个学期不得少于多少,这样就导致虽然学生借阅图书的数据是真實的,但是无意义的数据很多,如果进行处理,更多的时候更需要关注期末阶段学生借阅的图书数量及图书与专业之间的关系度,所以依据上述特征统计到的数据应该适当降低该项权重。
对于自习时间的处理,由于我校(六盘水师范学院)的自习室并没有完全采用电子化的处理方式,很多学生的自习得不到有效的统计,只能统计到部分教室的情况,而且有些自习是学院内部强调上的,效果也可能大打折扣,所以应对该项数据首先进行统一上自习的数据的删除,然后对于其他时间地点统计到的数据进行提升权重的方式来处理,而且也要把自习时间进行范围归一化处理,如有效自习时间以3次为基准,没增加3次为该生的自习进行一个更新。公式如5所示,[Z_countY]代表原始统计的有效自习次数,[Zcount]代表最终进行处理话之后的自习次数统计。
通过对数据的分析发现就餐时间的权重也应进行适当的降低,大部分学生采用外卖的形式就餐,这样导致很多数据的不完整,虽然通过某些数据处理技巧进行的简单的处理,但是该项数据实际的完整意义已经发生了改变,所以应适当降低该项数据的权重。
4.3 实验测试
通过对数据的预处理之后发现,要把自习的数据提高5倍以满足支持度的要求,不然就导致自习数据基本在关联分析中无效。需要对图书借阅次数数据进行缩小4倍进行处理,这样才能有效地得出考前两周内的借阅书籍的比例,继而参与有效关联。同时需要对就餐数据降低10倍来进行数据的关联分析,不然可能出现就餐数据支持度远远高于其他两项。
修改的Apriori算法记为W_S_Apriori。
通过使用W_S_Apriori算法对六盘水师范学院学生行为数据进行分析可得出支持度计数如表4所示。
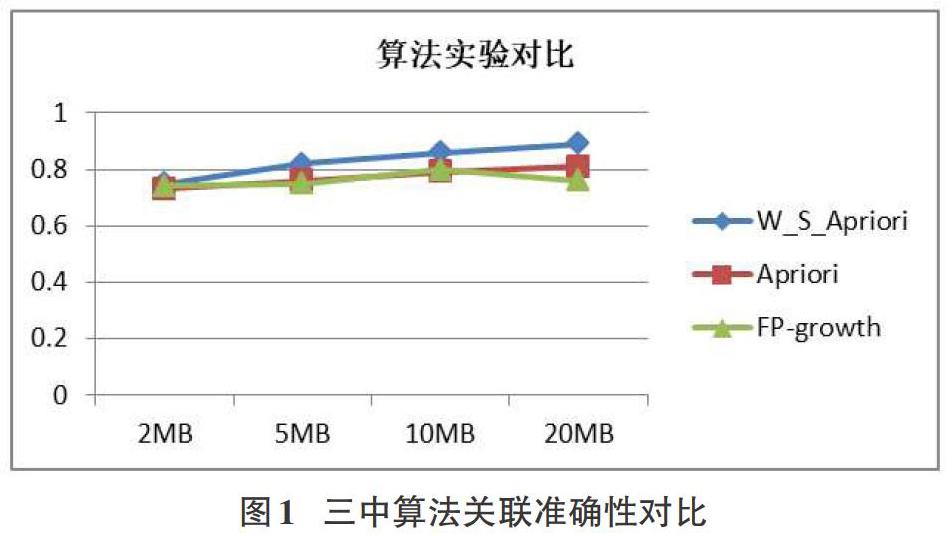
下面分别使用2MB、5MB、10MB、20MB的数据量对三种算法对比发现W_S_Apriori算法在关联预测方面做得更好。如图1所示,衡中代表数据量的大小,纵轴代表关联准确性。
5 总结
本文针对学生行为数据进行处理分析,并提出了一种加权修正区间值的一种改进Apriori算法W_S_Apriori,该算法相对于传统的关联算法更能够准确地进行数据的关联,大大提高了算法的可靠性,但是由于W_S_Apriori算法本身是基于Apriori的算法的改进,所以大规模数据使用该算法效率会大大降低。
参考文献:
[1] 戎荷婷,王瑞玲,武晶,等.学生行为对学生成绩的影响探究[J].现代商贸工业,2016,37(23):185-186.
[2] 姜楠,许维胜.基于数据挖掘技术的学生校园消费行为分析[J].大众科技,2015,17(1):26-28,39.
[3] 马丹.基于数据挖掘技术的学生成绩分析系统的设计与实现[D].长春:吉林大学,2015.
[4] 王凤军.大学生行为习惯养成教育的措施与方法研究[J].当代教育理论与实践,2014,6(12):129-130.
【通联编辑:梁书】
