大数据管理对分析师盈余预测准确性的影响
2020-02-22暨南大学管理学院徐飞鹏
○暨南大学管理学院 徐飞鹏
2014年我国首次将大数据写入了政府工作报告,同年十八届五中全会上提出实施国家大数据战略。2016年工信部正式印发《大数据产业发展规划(2016—2020年)》。2017年十九大报告进一步强调要推动大数据和实体经济的深度融合。这些都标志着大数据已上升为国家战略。
分析师作为资本市场的信息中介,对目标公司的盈余预测是投资者进行投资决策的重要信息来源和参考依据。现有文献表明影响分析师对上市公司盈余预测准确性的因素主要包括宏观环境、分析师个人特征以及公司规模、信息披露水平等公司层面因素。本文从资本市场的信息中介——分析师角度出发,研究企业实施大数据管理对分析师预测准确性的影响,发现企业实施大数据管理会提高分析师盈余预测的准确性,在一定程度上能够缓解资本市场的信息不对称,提高资源配置效率,丰富了大数据管理的经济后果和分析师盈余预测准确性影响因素的研究,同时为持续推进国家大数据战略,提供一些有建设性的政策建议。
一、 理论分析与假设提出
(一) 大数据管理与分析师盈余预测准确性
分析师通过挖掘和分析上市公司的信息,进而制定并发布对目标公司的盈余预测,因此分析师获取信息的数量和质量是其预测准确性的重要影响因素(王雄元等,2017)。上市公司公开披露的信息具有获取成本低的特性,成为分析师进行盈余预测的重要信息来源和决策依据(Baginski和Hassell,1997)。因此,上市公司信息披露的透明度即信息披露质量将会显著影响分析师盈余预测准确性。已有研究发现公司的信息披露政策越透明,该公司的分析师跟踪人数越多,分析师盈余预测更加准确(白晓宇,2009;方军雄,2007)。从具体披露的信息来看,李丹(2009)认为盈余信息作为一种重要且公开的会计信息,其质量越高,反映企业经营以及财务状况越准确,因此分析师的盈余预测准确度也更高。李馨子(2015)发现分析师可以从上市公司发布的管理层业绩预告中获得额外的盈余信息,从而提高其盈余预测准确性。而对于非财务信息披露质量对分析师盈余预测准确性的影响,有研究将企业社会责任报告作为非财务信息披露的代理变量,发现企业社会责任报告质量与分析师盈余预测准确性呈显著正相关关系(Dhaliwal et al,2012)。王雄元(2017)研究了上市公司年报中有关风险信息披露与分析师盈余预测之间的关系,结果表明年报中风险信息披露频率越高,分析师预测越准确。综上,现有文献表明上市公司的信息披露质量与分析师盈余预测准确性显著正相关(Byard和Shaw,2003;伍燕然等,2016)。
企业建立大数据系统,应用大数据的能力,实施大数据管理的过程对其信息披露质量产生了重大的影响,主要体现在对信息质量本身的影响及信息披露过程质量的影响两个方面。
1.大数据管理对信息质量本身的影响
从信息质量本身来看,企业实施大数据管理在一定程度上能够对会计信息质量产生积极影响。企业实施大数据管理能够提高会计信息的完整性、相关性、可理解性与及时性等质量要求(Warren et al.,2015)。企业实施大数据管理下的会计信息除了传统的、结构化的财务报表信息,还包括大量的非结构化数据信息,如视频、图像、音频、文本数据等,是对企业传统财务信息的有效补充,能够提高信息使用者的决策有效性(杨德明等,2020)。此外,企业运用大数据技术,能够更早、更深地跟踪和记录其经营活动(Vasarhelyi et al.,2015),搜集并挖掘经营活动数据背后蕴藏的潜在价值,为企业经营决策提供更加及时且更具预测价值的有效信息。对于会计信息的可靠性,有研究认为大数据管理下指数级增长的会计数据,大量是劣质和虚假的数据(成静和彭代斌,2018),这可能给会计信息的可靠性带来严重的挑战。事实上,大数据拥有真实性的特征,成熟的大数据系统,其数据质量均需遵循真实、准确、完整和及时等原则(Cockcroft和Russell,2018)。即企业成熟的大数据系统,能够自动识别并剔除劣质、虚假的数据,从而确保其数据质量。因此,本文认为企业实施大数据管理初期,由于其技术不够完善,可能会给会计信息可靠性带来一定的负面影响,但随着企业大数据能力趋于成熟,对可靠性的负面影响逐渐消失,以至保证和提高会计信息的可靠性。综上,企业实施大数据管理,其会计信息可靠性、相关性、完整性、可理解性和及时性等质量要求得到保证,在一定程度上提高了会计信息本身的质量,提高了企业的会计信息透明度(Warren et al.,2015;杨德明等,2020)。
2.大数据管理对信息披露过程质量的影响
从信息披露过程质量来看,企业实施大数据管理对信息披露过程的质量也具有正面影响。首先,传统的会计信息披露主要通过财务报告形式输出信息,存在较大的局限性,体现在输出内容有限和输出形式单一两个方面。大数据管理下的会计信息不仅包括传统的、结构化的财务报表信息,还包括了以视频、图像、音频、文本等为载体的非结构化的会计信息,形式更加丰富,内容更加全面,使不同信息使用者的个性化需求得到满足,体现了会计信息披露的完整性和公平性原则;其次,大数据的高速特征使得企业会计信息能够及时处理并进行披露,满足了信息披露的及时性要求;最后,对于信息披露的真实性,有学者认为大数据环境下,企业可能会延迟披露其内部真实的数据,甚至虚假披露(成静和彭代斌,2018)。但成熟的大数据系统的建立需遵循一项基本要求即具有可访问性和可追溯性(Mcclatechy et al.,2015),数据可追溯性是评价企业是否具有成熟的大数据能力的重要因素之一(Wang et al.,2018),在数据可追溯性的限制下,企业进行选择披露或虚假披露变得更加困难,企业会计信息披露真实性得以保证。因此,企业实施大数据管理下的信息能够得到更好、更真实的披露(Shastri et al.,2019)。综上,本文认为企业实施大数据管理可以提高会计信息披露过程的质量。
基于以上分析,本文预期企业实施大数据管理,能够提高公司的信息披露质量,且实施大数据管理程度越高,信息披露质量越高,分析师可以获取的信息数量更多、质量更高,其盈余预测准确性也更高。本文提出第一个假设H1:
H1:企业实施大数据管理提高了信息披露质量,进而提高了分析师盈余预测准确性。
(二)产权性质、大数据管理与分析师盈余预测准确性
现有文献关于企业产权性质对企业信息披露质量影响的结论不一致(尹开国等,2014)。本文认为相较于非国有企业,国有企业信息披露质量更高。首先,两者所追求的目标不同。非国有企业更加关注经济利润,追求企业经济利益最大化。因此,它们会有选择性地披露信息,表现为及时披露利好消息,而不披露或者延迟披露对企业不利的消息,导致企业信息披露的不充分、不及时;国有企业除了追求经济效益,同时还承担着一定的社会责任和社会目标,有着特殊的政策和经济职能,国家对其信息披露的要求比非国有企业更高。其次,国有企业与非国有企业信息披露受到的监管程度不同。与非国有企业相比,国有企业信息披露除了受到证监会以及证券交易所的监管,还受到各级国资委的监管,监管力度远大于非国有企业。第三,从融资需求和盈余管理的角度,也能补充解释。相较于国有企业,民营企业易受到信贷歧视(江伟和李斌,2006),为了获得银行贷款,满足企业融资需求,更有动机操控盈余,进行盈余管理,导致其信息披露质量降低(何平林等,2019)。
综合上述分析,本文认为在均未实施大数据管理的情况下非国有企业的信息披露质量低于国有企业,而非国有企业实施大数据管理通过提高信息披露质量的路径对分析师盈余预测准确性产生的影响较国有企业更显著。基于此,提出本文第二个假设H2:
H2:与国有企业相比,非国有企业实施大数据管理对分析师盈余预测准确性的影响更加显著。
二、 数据与研究设计
(一) 样本与数据
目前,只有深交所对外公布上市公司信息披露考核结果,故本文选取2013—2018年深市A股上市公司作为研究样本,剔除了ST公司,鉴于金融行业公司财务指标的特殊性,也将其剔除。此外,由于分析师盈余预测数据的特殊性,采取以下步骤进行筛选:①将样本中分析师预测数据缺失的观测值剔除;②保留每个证券分析师当年度对上市公司最新一次的盈余预测数据;③对公司当年度所有分析师最新一次的盈余预测取平均值。通过上述步骤筛选过后,剔除相关财务数据缺失的样本,最终得到6773个观测值。
本文数据来源于两个方面:①反映公司实施大数据管理的指数,该指数通过对上市公司年报的收集、整理得到。②研究涉及的其他财务数据和分析师预测数据均来自CSMAR数据库。为了消除极端值的影响,本文涉及的所有连续变量均采用了1%的Winsorise处理。本文使用的数据处理软件为stata15。
(二) 变量定义
1.被解释变量
借鉴褚剑等(2019)的研究,本文将分析师盈余预测准确性定义为t年度,所有分析师对公司i的最新一次EPS预测值的平均值与公司i本年度实际的 EPS之差的绝对值,与公司i期初股票价格的比值,该值越小,表明分析师对公司i的盈余预测越准确。具体为:
(1)
其中:NewEPSit为t年度所有分析师对公司i的最新一次EPS预测值的平均值;EPSit为t年度公司i实际的EPS;PRICEit为公司i期初股票价格。
2.解释变量
本文借鉴杨德明和史亚雅(2018)、杨德明等(2020)的做法,首先,甄别出大数据、大数据分析、大数据能力等关键词,根据关键词对中国深市A股上市公司2013—2018年的年报和公告进行搜索;其次,阅读每份年报中董事会报告部分,并统计关于大数据的相关描述。在此基础上,根据关键词的搜索结果以及董事会报告相关内容,分析每家公司在建立大数据系统、实施大数据管理等方面的投入和实施程度,并对其打分,构建大数据行动指标(bigdata1)。如果大数据管理是该企业年度的主要投资方向,且该企业年度已建立完善的大数据系统、拥有成熟的大数据能力,则bigdata1为 3分;如果大数据管理尽管是该企业年度的主要投资方向,但该企业年度大数据系统不够完善、大数据能力尚未成熟,则为2分;如果该企业年度仅仅是有所涉及大数据、或是被动的跟随大流参与大数据系统和能力的建设,则为1分;如果年报中未提及大数据或是反映该年度企业未实施大数据管理,则为0分。本文是采用人工打分的方式构建的bigdata1指标,因此存在一定的主观判断的问题,为了解决这个问题,本文采取了以下两种方法:①三位研究人员同时为一份上市公司年报打分,如果同一份年报的评分差异很大,则三位研究人员需重新进行审核并打分,在此基础上,对三人的打分取平均值;②根据年报搜索结果,本文同时构建了不存在主观判断的大数据披露指标即bigdata2。如果年报中披露了大数据管理的相关信息,则bigdata2赋值为1,否则bigdata2为0。
3.中介变量
本文借鉴刘永泽和高嵩(2014)的做法,采用深交所对上市公司的信息披露评级(Rank)作为衡量公司信息披露质量的指标,从深交所网站手工搜集了2013—2018年深市A股上市公司信息披露评级,其中信息披露质量评级实行打分制,由低到高依次取值为1分、2分、3分、4分,分别对应“不合格”、“合格”、“良好”和“优秀”四个等级。
4.控制变量
参照已有文献,本文控制了企业规模(Size)、财务杠杆(Lev)、企业成长性(Growth)、企业总资产收益率(Roa)、企业的权益市账比(Mtb)、企业上市年限(Listage)、企业股票回报波动率(Vol)、企业是否亏损(Loss)、企业是否经四大审计(Big4)、是否两职合一(Two)、企业产权性质(Soe)、分析师跟踪人数(Follow)等,同时还控制了行业和年度固定效应。相关变量的定义见表1。
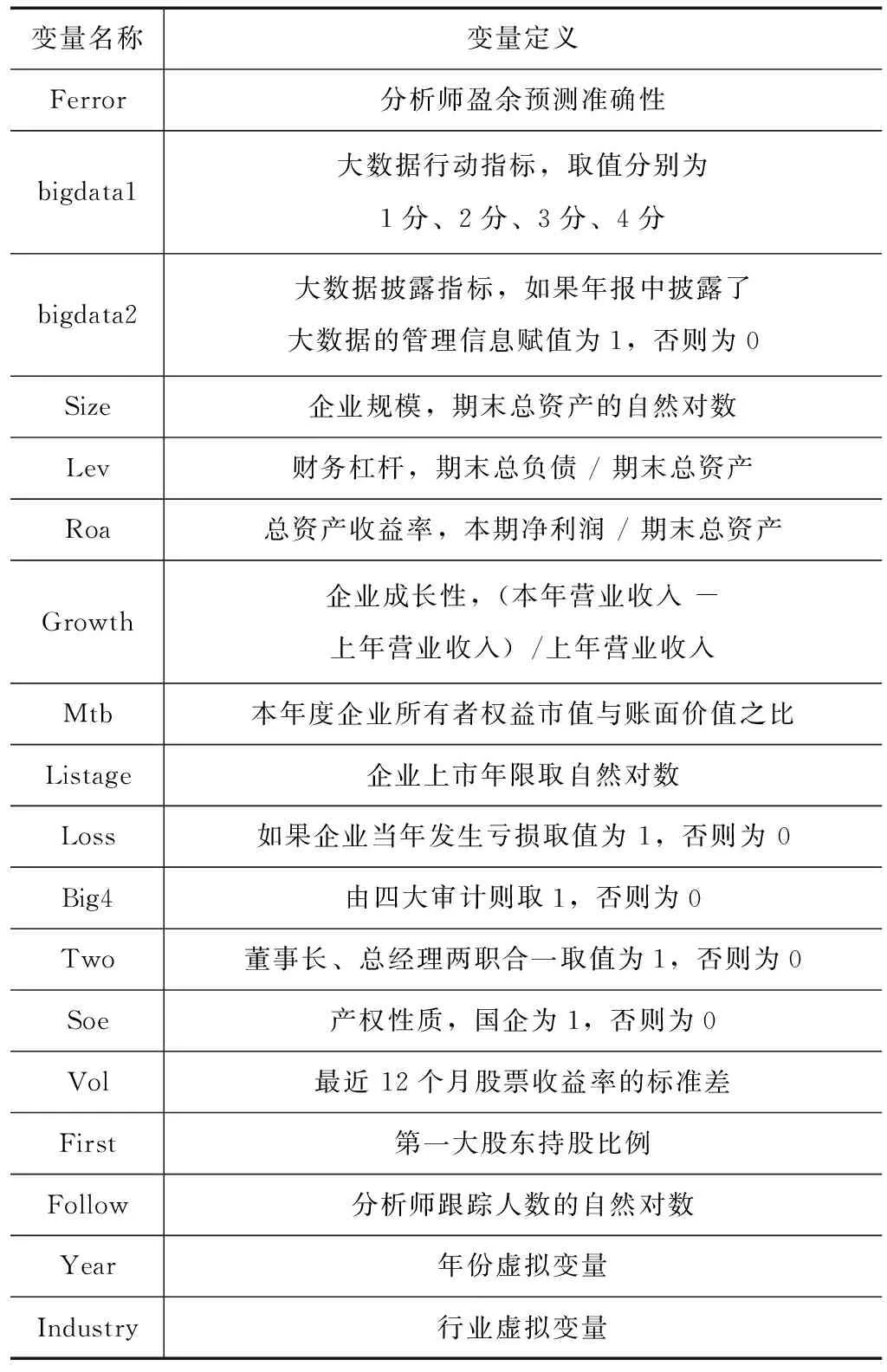
表1 变量定义表
(三) 研究设计
为了检验本文假设1,参考温忠麟等(2004)中介效应检验方法,构建了如下模型:
Ferror=β0+β1bigdata1/bigdata2+β2Size+β3Lev+β4Roa+β5Mtb+β6Vol+β7Growth+β8First+β9Listage+β10Follow+β11Soe+β12Two+β13Big4+β14Loss+β15∑ind+β16∑year+εit
(2)
Rank=β0+β1bigdata1/bigdata2+β2Size+β3Lev+β4Roa+β5Mtb+β6Vol+β7Growth+β8First+β9Listage+β10Follow+β11Soe+β12Two+β13Big4+β14Loss+β15∑ind+β16∑year+εit
(3)
Ferror=β0+β1bigdata1/bigdata2+β2Rank+β3Size+β4Lev+β5Roa+β6Mtb+β7Vol+β8Growth+β9First+β10Listage+β11Follow+β12Soe+β13Two+β14Big4+β15Loss+β16∑ind+β17∑year+εit
(4)
第一步,用模型(2)检验企业实施大数据管理对分析师盈余预测准确性影响的总效应;如果模型(2)中系数β1显著为负,则继续进行第二步,用模型(3)检验企业实施大数据管理对信息披露质量(Rank)的影响以及用模型(4)检验信息披露质量(Rank)是否存在中介效应;如果模型(3)中系数β1显著为正且模型(4)中系数β2显著为负,则进行第三步,即检验模型(4)中系数β1的显著性,如果β1显著为负说明部分中介效应显著,否则表明该中介效应是完全中介效应。若第二步中,模型(3)中β1和模型(4)中β2至少有一个不显著,则进行sobel检验。
对于假设2,将样本以产权性质即是否为国有企业为依据分组,运用模型2进行分组回归检验。
三、 实证检验
(一) 变量的描述性统计
表2是各变量的描述性统计。分析师盈余预测准确性(Ferror)的平均值为0.0105,中位数为0.006,标准差为0.013,该结果与前人的研究基本一致。大数据行动指标bigdata1的均值为0.555,中位数为0;大数据披露指标bigdata2的平均值为0.224,中位数为0。这两个指标中位数均为0,说明样本期间,绝大部分上市公司未实施大数据管理。

表2 主要变量的描述性统计
表3按是否实施大数据管理分组进行单变量分析,通过均值和中位数检验,初步验证了企业实施大数据管理对分析师预测准确性的影响。从表3可以看出,相比未实施大数据管理的样本,实施了大数据管理的样本公司的分析师盈余预测更加准确(无论是均值T检验还是Wilcoxon检验均在1%的置信水平上显著)。

表3 差异性分析
(二) 主要变量之间的相关性分析
表4列示了主要变量之间的 Pearson 相关系数矩阵。从表中可以发现大数据行动指标(bigdata1)和大数据披露指标(bigdata2)均与分析师盈余预测准确性(Ferror)显著负相关。从各自变量之间的相关系数来看,总体上各自变量之间不存在明显的多重共线性问题。
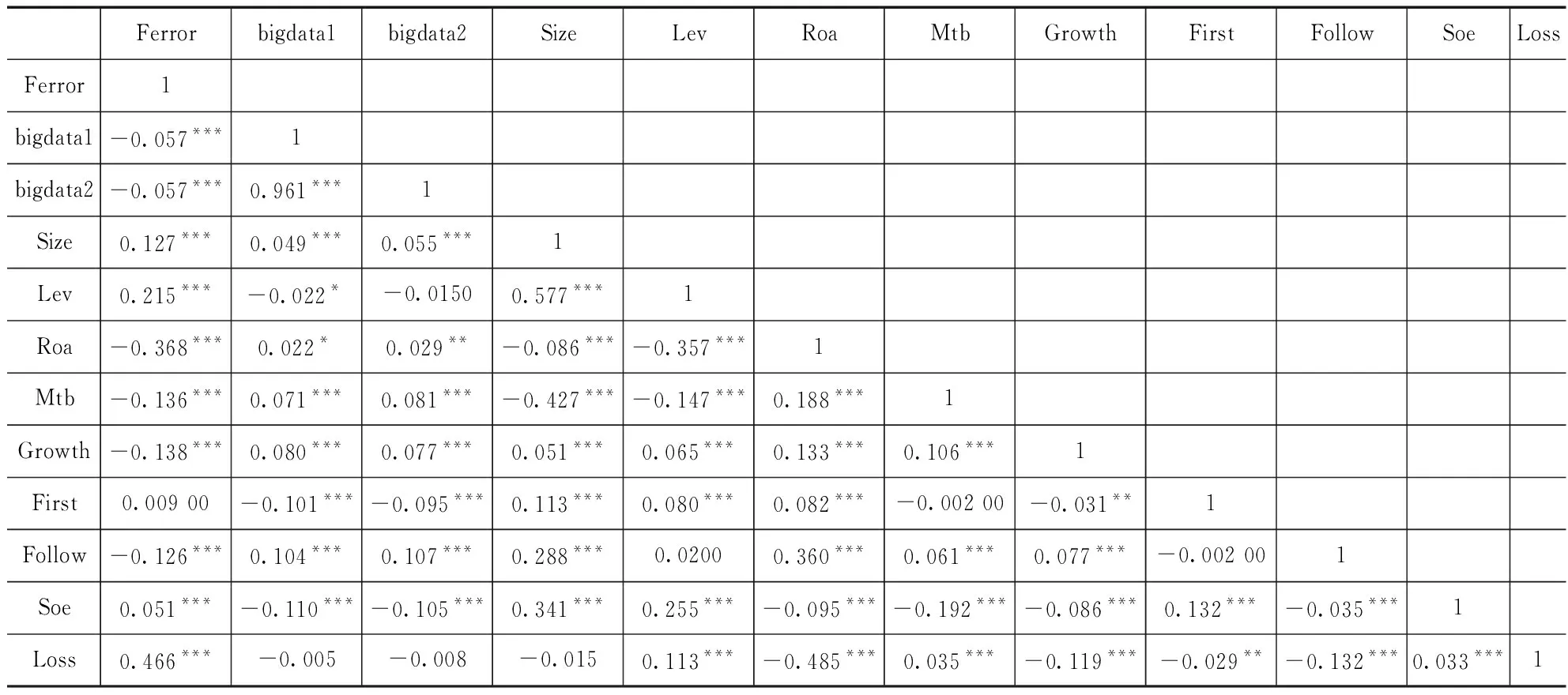
表4 主要变量之间的pearson相关性系数表
(三) 回归分析
表5提供了企业实施大数据管理与分析师盈余预测准确性的多元回归结果。从表中可以看出,大数据行动指标(bigdata1)和大数据披露指标(bigdata2)的系数均在5%的水平上显著为负,表明企业实施大数据管理提高了分析师盈余预测准确性,且实施大数据管理程度越高,分析师盈余预测越准确。
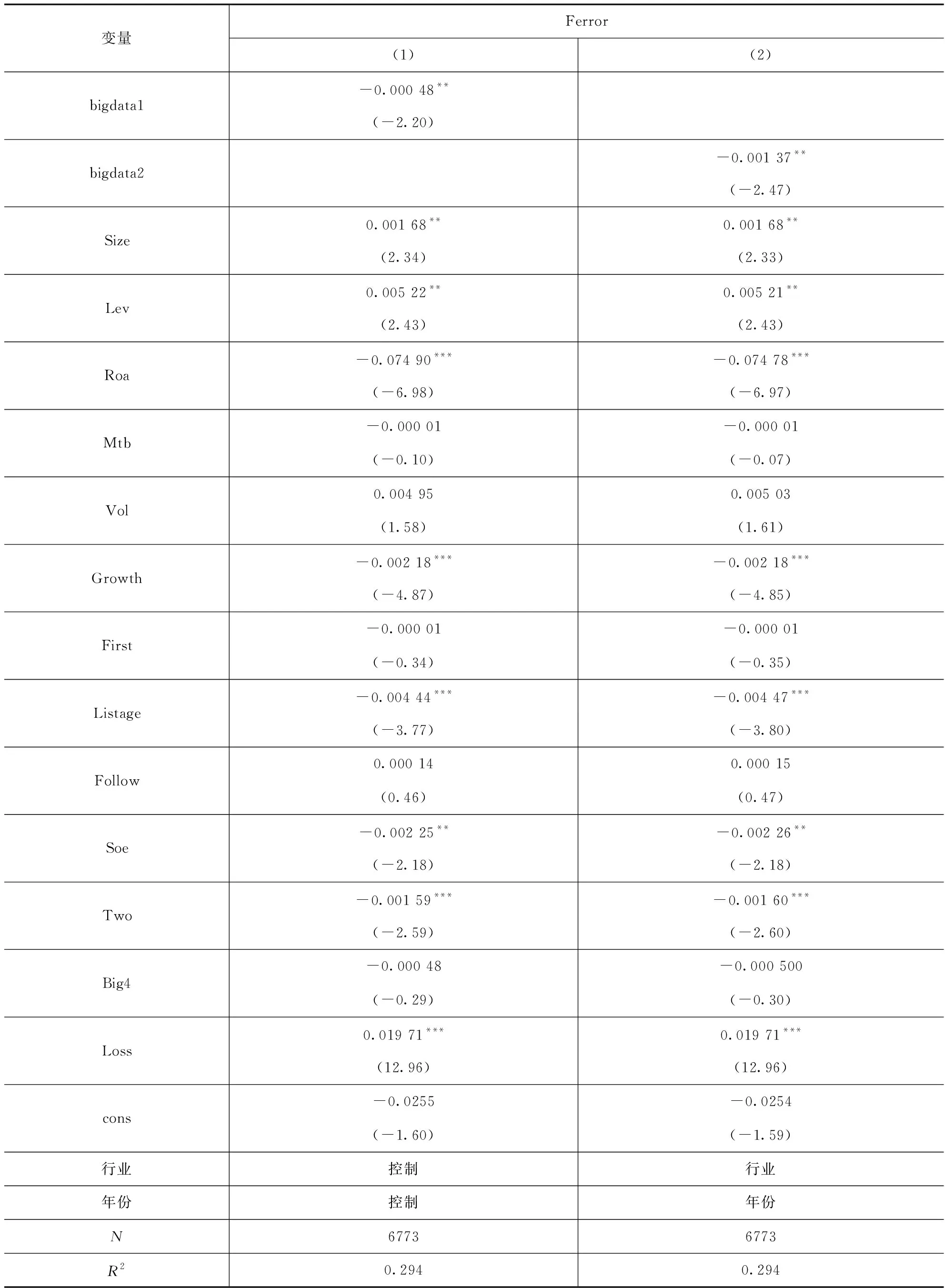
表5 大数据管理与分析师盈余预测准确性
表6提供了中介效应的检验结果。从表6中可以发现,信息披露质量是大数据管理影响分析师盈余预测准确性的一个重要中介变量。具体回归结果如下:第一,第(1)和(4)列bigdata1和bigdata2的系数均在5%的水平上显著为负。第二,第(2)和(5)列bigdata1和bigdata2的系数分别在1%和5%的水平上显著为正,表明大数据管理会显著提高企业的信息披露质量。第三,第(3)和(6)列Rank的系数均在5%的水平上显著为负,表明信息披露质量越高,分析师盈余预测准确性越高;bigdata1和bigdata2的回归系数较未控制Rank时降低且均在5%的水平上显著为负,表明部分中介效应显著,即信息披露质量是一个重要的中介变量。综合上述分析,H1得到验证,即企业实施大数据管理通过提高企业信息披露质量的路径,提高了分析师盈余预测准确性。
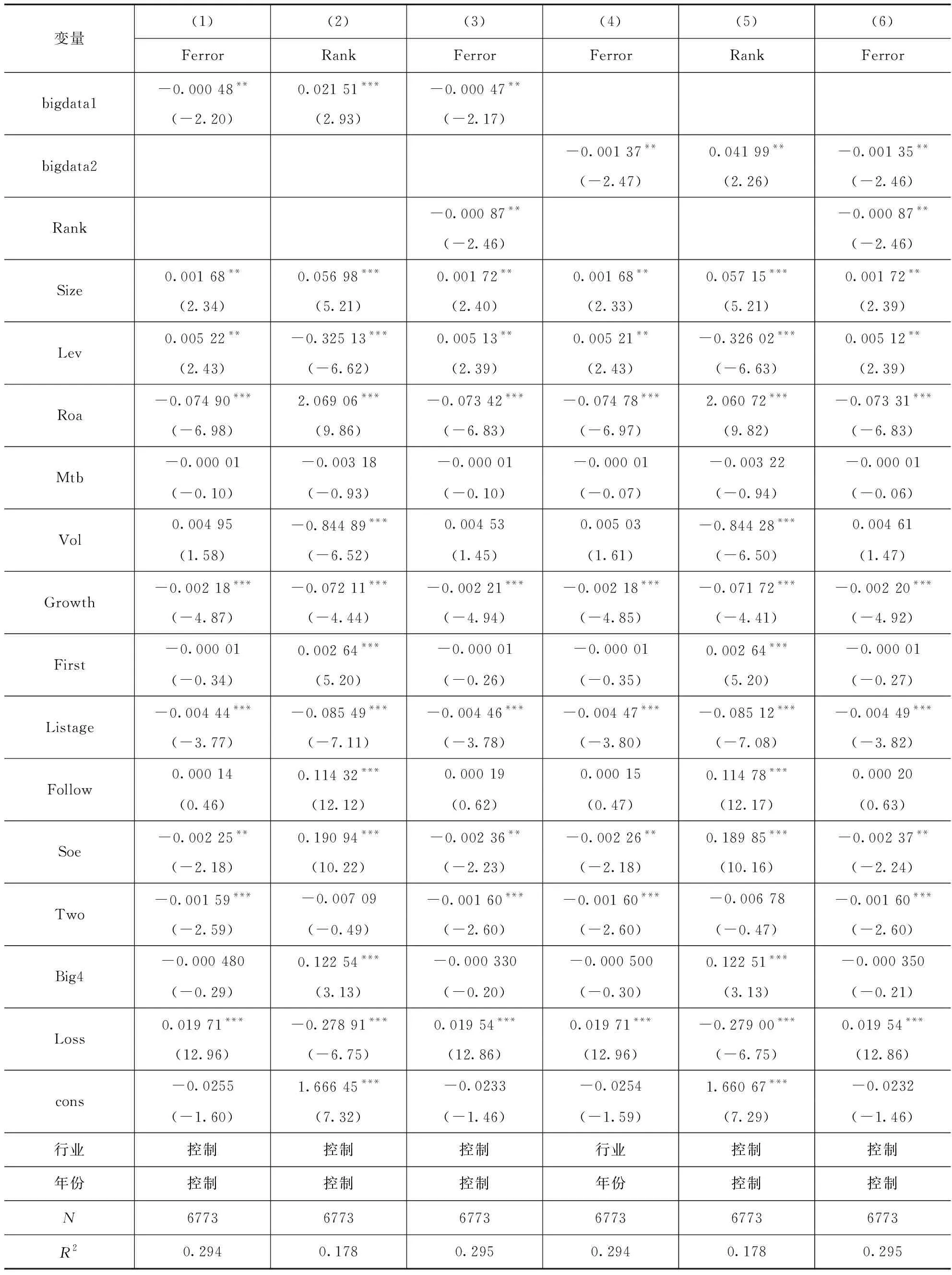
表6 中介效应检验
表7提供了假设2的检验结果。由表7可知,在国有样本回归中,bigdata1和bigdata2的回归系数均为负数,但均不显著,表明国有企业在实施大数据管理前后,分析师盈余预测准确性未发生显著变化;而非国有样本回归中,bigdata1和bigdata2的回归系数均在5%的水平上显著为负,表明非国有企业实施大数据管理会显著提高分析师盈余预测准确性。H2得到了验证,即与国有企业相比,非国有企业实施大数据管理对分析师盈余预测准确性的影响更加显著。
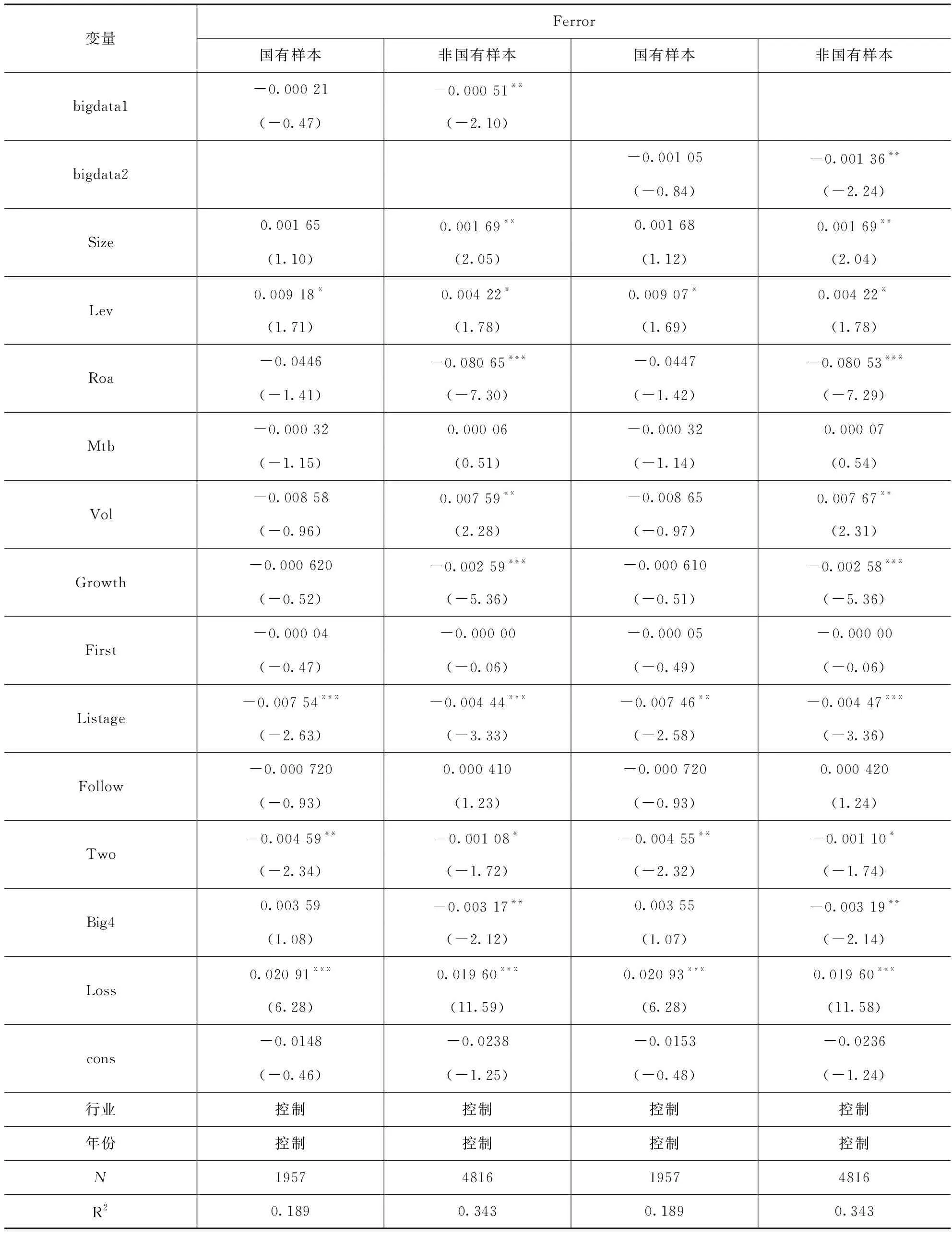
表7 假设2的检验(分组回归)
四、 稳健性检验
为了使本文得出的结论更加可靠,采用以下两种方法进行稳健性检验,相关结果未发生实质性改变。
(一) 工具变量回归
本文的研究可能存在测量误差而导致的内生性问题,使用工具变量法解决,选择城市大数据发展水平即“city”这一外生变量作为工具变量。当城市为深圳市、上海市、北京市、杭州市、成都市、广州市、天津市、南京市、东莞市和武汉市时,City取值为1,否则为0。显然,这是一个外生变量,且这个变量与bigdata1、bigdata2均高度相关(相关系数分别为0.200和0.207),此外弱工具变量检验F统计量达到了67.52,远大于10,这些均表明不存在弱工具变量问题。表8、表9结果表明在解决内生性问题后,假设1和假设2依然成立。

表8 稳健性检验:工具变量回归(假设1)
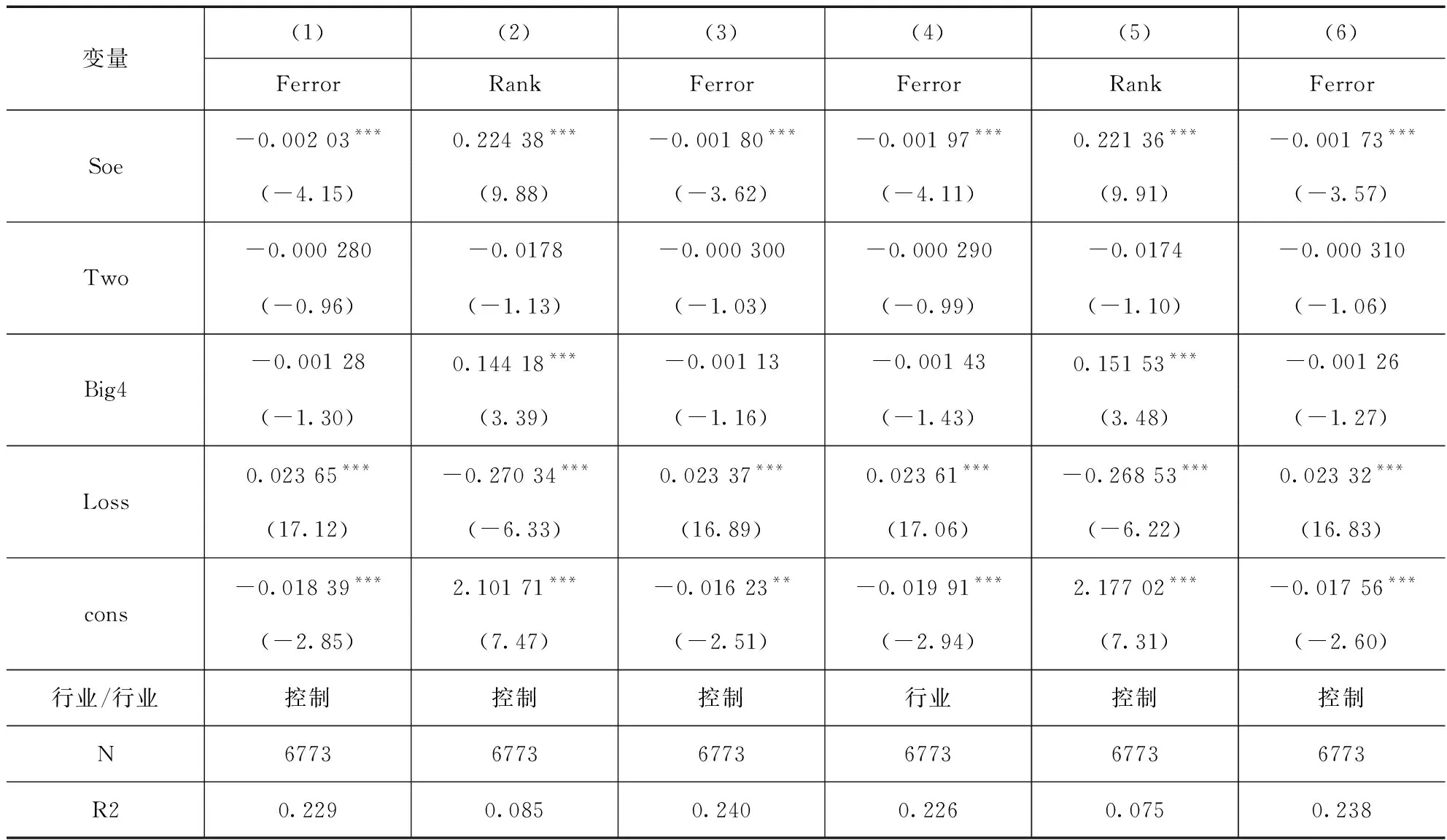
续表8
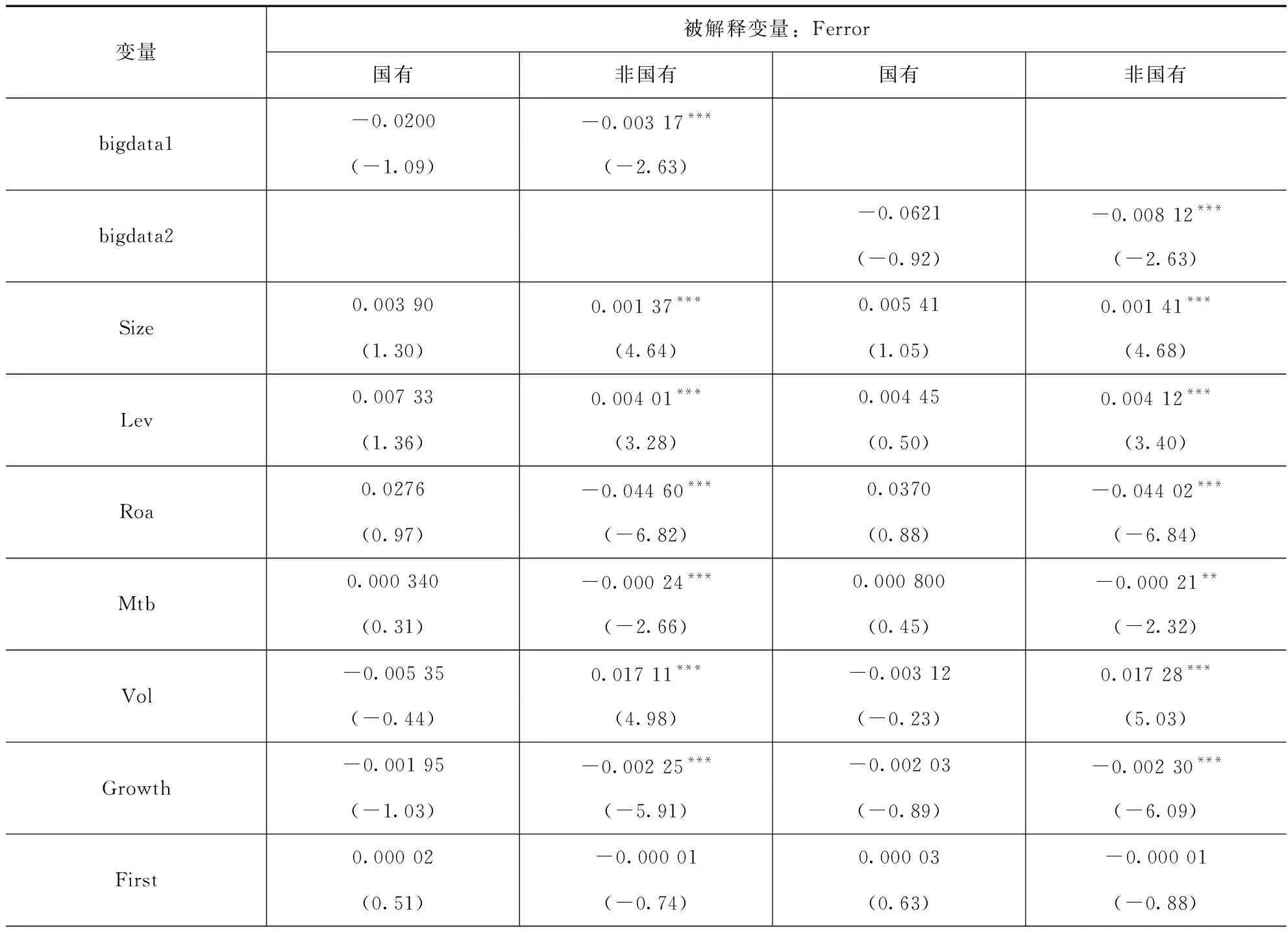
表9 稳健性检验:工具变量回归(假设2)

续表9
(二) 变量的重新度量
1.由于大数据行动指标(bigdata1)不可避免地存在一定的主观判断问题,本文构建了一个无主观判断的反映企业是否实施大数据管理的大数据披露指标bigdata2,如前文所述,与大数据行动指标bigdata1得到的结论一致。
2.对于被解释变量即分析师盈余预测准确性的度量,借鉴王雄元(2017)的研究,将分析师盈余预测准确性重新定义为t年度,所有分析师对公司i的最新一次EPS预测值的平均值与公司i实际的 EPS之差的绝对值,该绝对值与公司i的实际EPS绝对值加上0.5之和的比值,结论进一步得到验证。
3.对于中介变量的重新度量,借鉴何平林等(2019)的做法,采用可操控性应计利润(DA)重新度量信息披露质量,DA的绝对值越大,表明企业越有可能存在盈余管理行为,因此其信息披露质量越低。可操控性应计利润采用修正琼斯模型(Dechow et al.,1995)估计,结论未发生实质性改变。
五、 结论
本文通过构建量化企业实施大数据管理的指数即大数据行动指标,利用2013—2018年深市A股上市公司的财务数据和分析师对目标公司的盈余预测数据,研究了企业实施大数据管理对分析师盈余预测准确性的影响。第一,企业实施大数据管理显著提高了分析师盈余预测准确性,且实施大数据管理程度越高,分析师盈余预测越准确,进一步研究发现,企业实施大数据管理通过提高企业的信息披露质量这一路径,进而提高了分析师盈余预测准确性;第二,与国有企业相比,非国有企业实施大数据管理对分析师盈余预测准确性的影响更加显著。
本文的研究结论丰富了大数据管理的经济后果研究,同时也拓展了分析师盈余预测准确性影响因素的研究,具有一定的理论意义。此外,结论表明企业实施大数据管理通过提高企业的信息披露质量,进而提高分析师的盈余预测准确性,在一定程度上能够降低资本市场信息不对称,提高资源配置效率。因此,政府有必要继续大力推进大数据与实体经济深度融合,通过税收优惠、财政补贴等手段缓解企业培育大数据能力的资金压力,同时建立健全相关法律法规制度,保障企业商业秘密、个人隐私以及国家信息安全;企业应当充分认识大数据的重要性,积极开发大数据系统,培育大数据能力,实施大数据管理,实现价值创造。
