基于深度运动图和密集轨迹的行为识别算法
2020-02-19李元祥谢林柏
李元祥,谢林柏
江南大学 物联网工程学院 物联网应用技术教育部工程中心,江苏 无锡214122
1 引言
近年来,随着计算机视觉技术的快速发展,人体行为识别被广泛用于视频监控、智能家居和人机交互等,已经成为机器视觉与模式识别最热门的研究领域之一。目前,人体行为识别依然面临着环境光照、物体相互遮挡和算法鲁棒性低等挑战。最新推出的3D体感传感器,如微软的Kinect,不仅能够提供RGB视频序列,还可以提供深度信息和骨骼位置信息,为人体行为识别提供了一种新的解决方式。
在传统的行为识别算法中,研究者主要集中于对RGB视频序列进行行为分析,如Laptev等[1]提出使用哈里斯角点检测器在时空3D空间检测兴趣点,从而识别出不同的行为。尽管上述算法取得了一定的识别效果,但识别准确率易受光照变化、阴影、物体遮挡和相机视角运动等因素干扰。随着Kinect深度传感器可以非常方便地获取深度信息后,Bulbul等[2]利用DMM计算基于轮廓梯度方向直方图特征(CT-HOG)、局部二值模式特征(LBP)和边缘方向直方图特征(EOH),并决策级融合上述特征来避免光照变化和物体遮挡等不利环境因素的影响,取得了较好的识别效果。Zhu等[3]使用了双流网络结构来分别独立训练深度图序列和深度运动图序列,提取网络高层次特征Conv5和fc6并使用早期融合的方法融合上述特征,取得了相对于传统方法更好的识别效果。近年来,许多研究者尝试融合RGB视频序列中纹理信息、深度运动图中的深度信息或骨骼图中的骨骼位置信息。许艳等[4]利用深度图提取时空梯度自相关向量特征和梯度局部自相关特征(GLAC),同时利用骨骼帧图像的静态姿态模型、运动模型和动态偏移模型表征动作的底层特征,并采用权重投票机制融合上述特征。Imran等[5]利用RGB序列与深度图序列分别计算运动历史图(MHI)和DMM。并输入到四路独立的卷积神经网络(CNN)中训练,最后融合每路CNN网络输出的分数。Luo等[6]分别提取RGB序列的中心对称局部运动特征(CS-Mltp)和深度图序列的三维位置信息特征,同时利用基于稀疏编码的时间金字塔(ScTPM)描述上述两种特征,并分别比较特征层融合、分数融合的识别效果。
为了融合RGB纹理信息和深度图中的深度信息,本文提出了一种基于DMM和密集轨迹的人体行为识别算法。为了得到更有效的DMM特征表示,将DMM帧图像输入到三路独立的VGG-16网络训练,提取高层次特征作为视频的静态特征。同时在计算DMM帧图像时,为了解决动作速度和幅度对动作识别的影响,引入表示能量大小的权值变量来保留深度图序列的更多细节信息。此外,为了降低静态特征和动态特征融合后的特征维度,结合静态显著性检测算法和运动边界区域确定动作主体区域,以减少密集轨迹数量。该算法结构框图如图1所示。
2 深度图静态特征提取
为了得到高性能的网络参数,需要大样本数据进行迭代训练,然而常用的RGBD数据集的数据量较少,直接进行网络训练容易导致过拟合。为了克服该问题,首先使用仿射变换[7]模拟深度图在相机视角变化的效果,同时通过改变DMM差分图像采样的时间间隔来模拟同一动作的不同执行速度,从而扩大数据样本量。然后,引入表示能量大小的权值变量来保留深度图序列的更多细节信息。将改进的DMM进行彩虹编码[8]处理,并输入到VGG-16网络训练进而提取Conv5和fc6特征,作为视频序列的静态特征表示。
2.1 数据扩增
2.1.1 相机视角扩增
由Kinect获得的深度图像是表征身体距离相机远近的灰度图,本文使用仿射变换模拟深度图在不同视角下的采集效果,以扩充深度图在不同视角下的样本数量。

图1 算法结构框图
Kinect相机成像模型如图2,三维空间坐标(x,y,z)和深度图的像素坐标(u,v,d)的对应关系为:
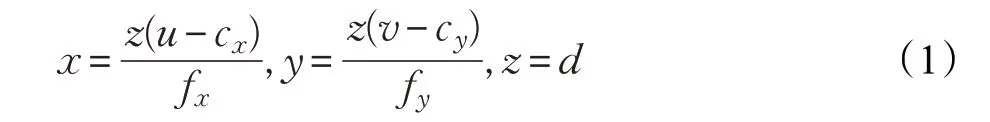
其中fx,fy指相机在两轴X,Y上的焦距,(cx,cy)指相机的光圈中心。对于KinectV1相机,fx=fy=580。Kinect相机的不同视角变换可以看作三维空间点的旋转,如图3所示。
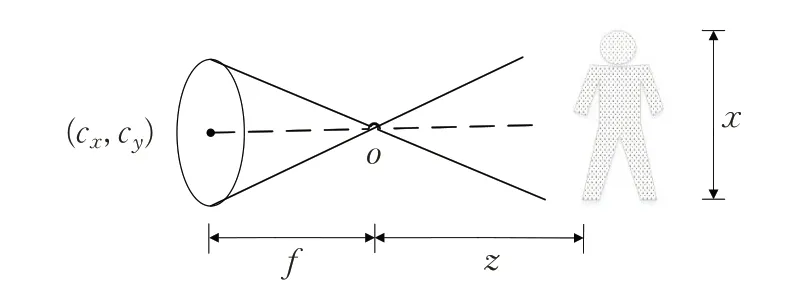
图2 Kinect相机成像模型
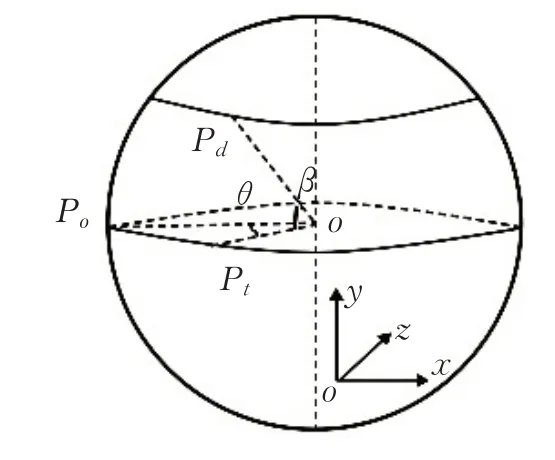
图3 相机视角变化
现在假设相机从P0位置移到Pd位置,那么该过程可以分解为P0旋转θ角度到Pt,Pt旋转β角度到Pd。设P0的位置坐标为(X,Y,Z),Pd的位置坐标为(X1,Y1,Z1),则该变换为:
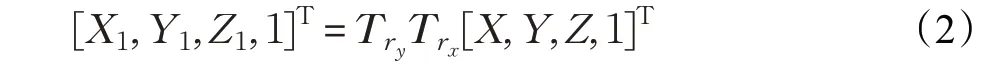
其中Try和Trx分别表示P0到Pt的绕y轴的变换矩阵,Pt到Pd的绕x轴的变换矩阵,可表示为:
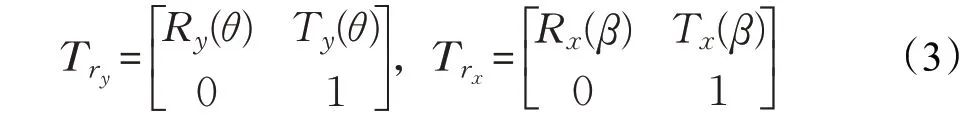
其中Ry(θ),Rx(β),Ty(θ),Tx(β)为:
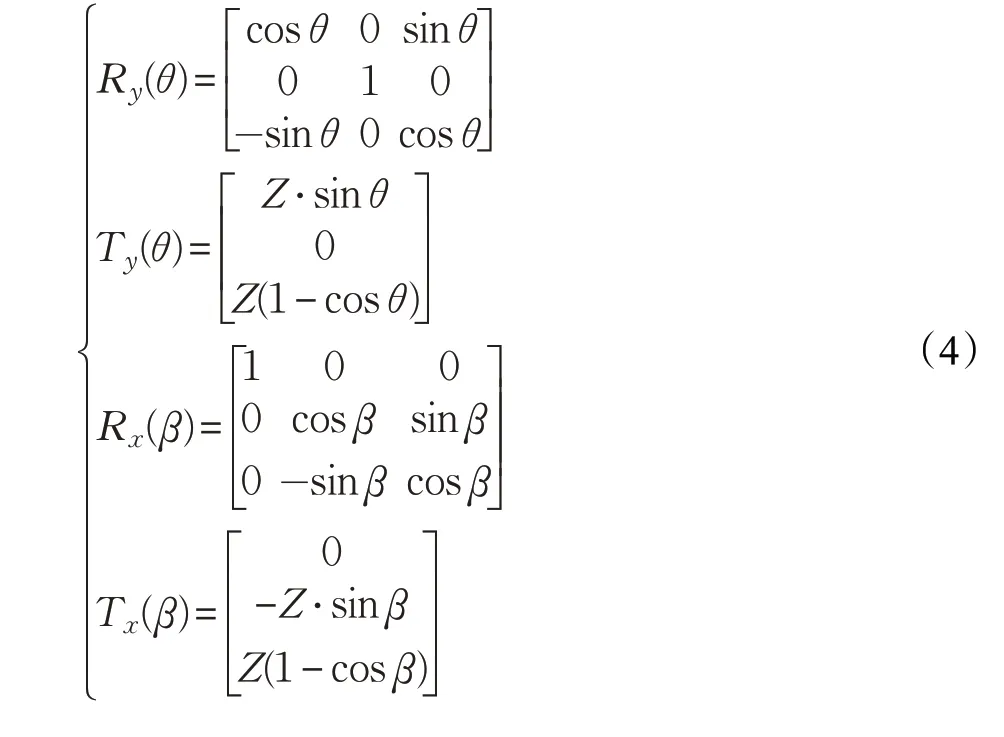
2.1.2 速度扩增
对于一个视频动作,为了模拟不同速度下执行的效果,需要对原视频以不同采样间隔进行下采样,计算公式为:
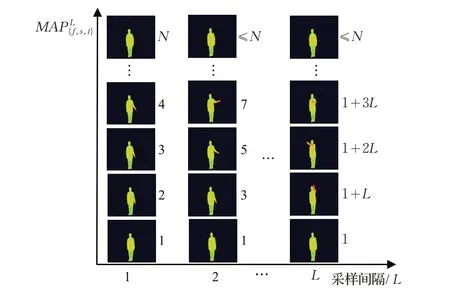
图4 下采样示意图
2.2 DMM改进
二维卷积神经网络更适合处理静态图像数据,因此采用DMM作为卷积神经网络数据层的输入。为了克服动作的速度和幅度对识别结果的影响,在将整个视频信息压缩到一帧DMM时,引入表示能量大小的权值变量来保留深度图序列更多的细节信息。DMM改进计算公式如下,其中表示第i帧的能量表示第i帧深度图投影到三个正交平面(正平面、侧平面和顶平面)得到的投影图像,表示下采样序列MAPL{f,s,t}中第i帧的深度图。

其中ξ为设定的阈值,sum(·)为计算深度图中非零的个数。
图5和图6分别为上述两种数据扩增手段(相机视角扩增和速度扩增)得到的帧图像。其中,图5为UTDMHAD数据集中“right hand wave”动作在同一视角下不同速度下的DMM图像。图6显示了该动作在同一速度下不同视角下的DMM图像。

图5“right hand wave”动作下不同速度的DMM图像

图6“right hand wave”动作下不同视角的DMM图像
2.3 VGG-16特征提取
目前已经出现了许多优秀的深度卷积神经网络框架如AlexNet、VGGNet和3D-CNN等,针对样本量偏少的人体行为数据集,小型卷积神经网络如AlexNet和VGGNet等应优先考虑使用。考虑到深度网络的特征表达能力和实际的硬件配置,本文使用VGG-16[9]网络提取DMM的特征信息。
卷积神经网络可以从零开始或通过迁移学习来训练,但由于公开数据集如UTD-MHAD和MSR Daily Activity 3D的样本数据量偏少,从零训练VGG-16网络容易出现过拟合,因此本文通过迁移学习来训练卷积神经网络。在预训练模型下,将改进DMM图像输入到VGG-16网络进行网络参数的微调。
将一帧深度图像投影到三个正交平面上,可以得到三幅不同投影平面的投影图像,因此一个深度图像序列可以提取三个不同投影平面下的高层次特征。为了将Conv5和fc6特征融合,首先对conv5特征进行空间金字塔池化[10],将维度从7×7×512变为50×512,然后根据文献[11],利用主成分分析(Principal Component Analysis,PCA)将Conv5维度降为128,同时利用高斯混合模型(GMM)[12]求取Conv5的Fisher向量,其中向量维度为2DK=2×128×256=65 536,最后将三个投影平面的Conv5特征串联,结合fc6特征得到208 896维向量作为行为视频的静态特征表示。
3 RGB动态特征提取
为了提取RGB视频序列的运动信息,本文基于密集轨迹[13]算法跟踪视频序列光流场中每个密集采样特征点并获得特征点运动轨迹,计算每个轨迹的轨迹形状、光流直方图(HOF)和运动边界直方图描述符(MBH)来表示其运动信息。文献[13]提出的密集轨迹是基于图像均匀采样计算得到,包含大量背景轨迹,计算量大,特征维度高,相机运动时存在大量不相关的背景轨迹会对识别效果产生不利影响。为此,本文在密集采样特征点前,首先利用显著性算法和运动边界区域检测出视频序列中的运动主体部分,然后对检测出的动作主体进行特征点采样,并计算每个轨迹的特征表示。
3.1 RGB视频序列的显著性检测
在显著性检测领域中,通常利用颜色特征计算图像的显著性值,但在行为识别数据集中,部分动作的执行者着装颜色常和背景接近,为了更准确检测出显著性区域,利用融合边界信息和颜色特征实现单帧图像中静态显著性区域的检测。
由文献[14-15]可以得出第i个超像素的边界信息含量为:

其中bi表示第i个超像素含有边界点的总量,K为利用SLIC分割法分割后的超像素数量。
将视频中每帧图像划分多个像素块,并转化到LAB颜色空间中计算这些像素块的显著性值,计算公式为:
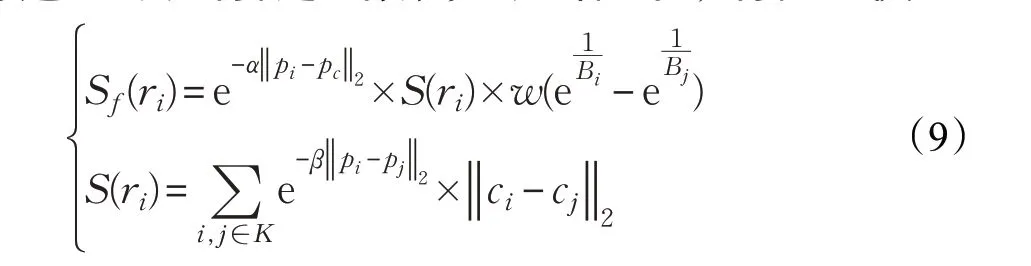
其中α为中心-边缘原则的控制因子,β为空间因子,w为平衡因子,在本文中分别取值为0.9、0.9和0.75;ci,cj和pi,pj分别表示第i、j超像素的颜色特征和空间特征;pc为图像中心位置向量。
尽管上述静态显著性检测算法能够检测出单帧图像中显著性区域,但对于检测行为视频中运动主体区域时,依然存在部分显著性区域过小导致提取的轨迹特征信息比较局限或者显著性区域含有部分背景区域等问题。受文献[16]启发,计算连续帧图像间的运动边界作为行为视频的运动区域,并将其与利用静态显著性检测算法得到的显著性区域进行线性融合,得到最终的运动主体区域。图7中(a)、(b)为动作“right arm swipe to the left”和对应的运动主体检测效果图,从图中可以看出能够较好地检测出运动主体区域。

图7 UTD-MHAD部分动作运动主体检测的结果
3.2 基于动作主体的密集轨迹特征计算
对运动主体部分进行均匀密集采样时,为了得到有效的轨迹特征,取每个采样点周围大小为N×N×L的时空区域,同时对每个时空区域进一步划分得到nσ×nσ×nτ份子时空区域。在每个子时空区域内提取一组特征(轨迹形状、光流直方图和运动边界直方图),并将每组特征进行8 bin量化,最终得到一个330维的轨迹描述子,其中轨迹形状特征为30维(15×2),HOF特征为108维(2×2×3×9)和MBH特征为192维(2×2×3×8×2)。由于每个输入视频都包含大量的密集轨迹,经过计算后会产生大量的轨迹特征组,因此首先利用PCA对轨迹描述子进行1∶2的降维,得到降维后的165维轨迹描述子,然后采用高斯混合模型(GMM)对轨迹描述子建模,取高斯分布个数K为256,并求得轨迹描述子的Fisher向量,其中向量维度为2DK=2×165×256=84 480,作为RGB视频序列的动态特征。
图8为UTD-MHAD数据集中动作“right arm swipe to the left”的密集采样,其中图(a)为原文算法(IDT)[13]密集采样和轨迹跟踪的效果图,图(b)为本文算法处理后的效果图,可以看出图(a)背景区域中包含大量密集采样特征点,不仅计算量大,特征维度高,且不相关的背景轨迹会对识别效果产生不利影响。

图8(a)原文算法

图8(b)本文算法的轨迹跟踪
4 实验结果与分析
4.1 参数设置
在提取深度图像的静态特征时,利用Caffe toolbox[17]实现VGG-16网络结构,其中网络模型采用动量值为0.9的批处理随机梯度下降法和误差反向传播更新模型参数。网络训练参数设置如文献[18],即在每个网络中的隐含层均采用RELU作为激活函数,同时在预训练模型ILSVRC-2012下,学习率设置为0.001,批次次数设置为32。训练的最大迭代次数设置为20 000次,其中每5 000次迭代后学习率下降一次。数据扩增处理中,为了保留更多细节信息,最大采样间隔L为5。在提取RGB动态特征时,对于密集采样和轨迹特征计算采用和文献[13]相同的参数设置,即设置8个空间尺度,并在每个空间尺度下使用W为5的采样步长密集采样得到特征点,时空区域中N和L分别取值为32和15,子时空区域中nσ和nτ分别取值为2和3。为了验证本文算法的识别效果,基于两个公开的人体行为识别数据集,开展了实验与分析。
4.2基于UTD-MHAD数据库的行为识别
UTD-MHAD是由Chen等人[19]利用Kinect深度传感器和穿戴式传感器制作的RGB-D行为数据集,其中Kinect深度传感器采集深度信息,RGB视频序列和骨骼位置,可穿戴式传感器采集表演者动作的加速度信息。该数据集包含了27种动作,每个动作分别由8个人执行4次,剔除3个损坏的行为序列,总共有861个行为序列。同时存在一些类似动作,如顺时针画圆、逆时针画圆、画三角形等,因此该数据集上的行为识别仍然有很强的挑战。
为增加样本数量,本文模拟相机视角变化来增广实验训练样本数量,θ,β在实验中取值范围为[-30°,30°],分别等间隔取5个离散值,原数据量可扩大25倍。在实验中,横向层数设为5,即采样间隔L=1,2,3,4,5,从而进一步扩增5倍,因此网络输入数据量总共可以扩增125倍。在8个表演者中,选择序号为奇数表演者的数据作为训练集,其余作为测试集。在网络训练阶段,为了得到鲁棒性能好的网络参数,使用了所有的训练样本数据。将视频的行为特征输入到线性SVM进行训练和测试时,由于扩增后的测试样本数量太多,同时为了保证测试样本中静态特征和动态特征的相互对应,本文仅使用原生测试样本进行测试。最后,对所有类别动作的识别率使用算术平均法得到最终的识别率。
该数据库上的混淆矩阵如图9所示,可以看出本文算法在许多动作下取得不错的识别效果,但对于一些相似动作依然存在误识别,如“向左滑动”与“向右滑动”,“顺时针画圆”与“逆时针画圆”,其中“顺时针画圆”与“逆时针画圆”相识度较高,仅是两者运动方向的不同,导致两者存在0.13~0.25的误识别率。表1对比了不同输入流下对应的识别效果,其中利用轨迹跟踪算法得到的识别率为80.87%;利用VGG-16卷积神经网络训练DMM数据得到的识别率为91.13%;将上述两种输入流得到的特征串联一起输入到线性SVM分类器,得到识别率为92.67%。表2对比了其他识别方法在UTDMHAD数据集的识别效果,相对于文献[2-3,20],本文算法分别提升了4.27%、1.47%和6.55%,主要原因是在计算DMM时引入了能量权重,并且从相机视角和采样速度上扩增DMM训练数据,同时融合深度视频序列中深度特征信息和RGB序列的动态运动信息。
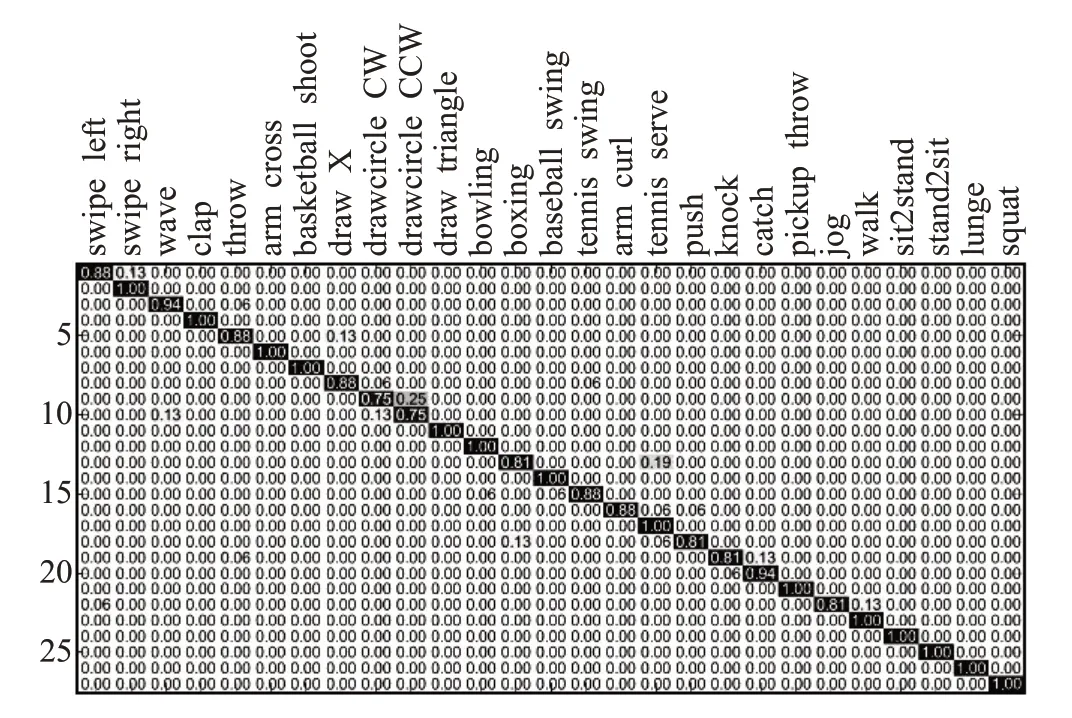
图9 UTD-MHAD数据集:混淆矩阵

表1在UTD-MHAD数据库上,不同输入流对应的识别效果

表2在UTD-MHAD数据库上,现有方法与本文方法的识别率比较
4.3 基于MSR Daily Activity 3D数据库的人体行为识别
MSR Daily Activity 3D[22]数据库是采用Kinect深度传感器录制的人体行为公共数据库,该数据库包含骨骼关节位置、深度信息和RGB视频三种数据,包含16类动作,每类行为分别由10个人执行两次(站立和坐下两种姿势),总共960(16×10×2×3)个文件。在本实验中仅使用了该数据库中的深度信息和RGB视频序列。该数据库数据量偏小,存在很多动作与物体交互的情况,如“看书”、“报纸上写字”等,且存在一些类似的动作,如“坐下”、“站起来”等,因此进行行为识别具有很大的挑战性。本文采用和UTD-MHAD数据库同样的扩增手段,θ,β在实验中取值范围为[-30°,30°],分别取五个离散值,原数据量可增加25倍。对于每个视频,模拟了五种速度下的情况,数据集可进一步扩增五倍。10个表演者中,选择序号为奇数表演者的数据作为训练集,其余作为测试集。在网络训练阶段,为了得到鲁棒性能好的网络参数,使用了所有的训练样本数据。将视频的行为特征输入到线性SVM进行训练和测试时,由于扩增后的测试样本数量太多,同时为了保证测试样本中静态特征和动态特征的相互对应,本文仅使用原生测试样本进行测试。
在该数据库上的混淆矩阵如图10所示,由图10可以看出一些相似动作依然存在误识别,如“看书”与“写字”。表3对比了不同输入流下对应的识别效果。表4对比了其他识别方法在数据库MSR Daily Activity 3D上的识别效果,相比于文献[6]和文献[25],本文算法分别提升了1.87%和1.2%。相对于UTD-MHAD数据库,MSR Daily Activity 3D数据库背景更为复杂,同时很多动作存在与物体交互的情况,因此识别率提升相对较低。

图10 MSR Daily Activity 3D数据集:混淆矩阵

表3 在MSR Daily Activity 3D数据库上,不同输入流对应的识别效果

表4 在MSR Daily Activity 3D数据库上,现有方法与本文方法的识别率比较
5 结束语
本文方法提出基于深度运动图和密集轨迹的行为识别算法,主要是为了解决目前行为识别算法在复杂场景下如遮挡,光照变化等识别率不高及算法鲁棒性较差的问题。为此,本文首先分别提取RGB视频序列的纹理特征和深度图序列的深度特征,然后,利用Fisher向量编码上述两种特征并将静态特征和动态特征串联作为整个动作视频的特征描述子。在两个公开数据集上实验表明,本文算法对相似动作具有一定的判别性,但本文算法存在计算复杂度高且识别速度有待提高的不足,因此如何提高算法的高效性是下一步工作的方向。
