基于机器学习的恐怖分子预测算法
2020-02-19张南南陈湘萍
李 慧,张南南,曹 卓,郑 海,陈湘萍
(贵州大学 a.电气工程学院; b.机械工程学院,贵阳 550025)
0 概述
当今世界,恐怖袭击事件频繁发生,由全球恐怖主义数据库(GTD)统计的数据可知,从1970年至今,记录在案的恐怖袭击事件高达180 000多起。恐怖袭击不仅具有极大的杀伤性与破坏力,直接造成大量的人员伤亡和财产损失,而且还给人们带来巨大的心理压力,导致社会一定程度的动荡不安,妨碍正常的工作与生活秩序,进而极大地阻碍经济的发展[1]。对恐怖袭击事件嫌疑人的分析预测有利于对恐怖分子进行针对性打击,能够为反恐和防恐工作提供有价值的信息支持,有助于提高破案效率以及尽早发现新生或者隐藏的恐怖分子,从而降低人员和财产损失。
目前国内外许多专家学者针对恐怖袭击风险评估进行了相关研究。文献[2]提出基于人口的简单风险指标和基于事件的RMS恐怖风险模型2种评估方法。还有一些研究利用事件树[3-4]、概率风险评估(Probabilistic Risk Assessment,PRA)[5-7]、贝叶斯网络[8-10]以及神经网络[11]等方法评估恐怖袭击风险。而有些研究依据事件特征发现犯罪嫌疑人,如文献[12]运用支持向量机(Support Vector Machine,SVM)预测犯罪嫌疑人。该方法根据历史犯罪记录进行特征选择,训练基于SVM的嫌疑人特征预测模型,通过此模型对案件嫌疑人的各个特征进行预测,将预测出的特征与备选嫌疑人库中人员特征进行相似度计算,进而预测出最有可能的嫌疑人。文献[13]基于随机森林模型组合分类器对犯罪行为进行分析。文献[14]基于一种混合神经模糊模型,通过从模拟的广域监视网络中提取的犯罪指示事件来预测在城市或地区中的犯罪行为。文献[15]采用聚类算法,提出了一种基于Probit模型的犯罪嫌疑人判定技术。文献[16]在分析财产犯罪时空规律的基础上,利用BP神经网络模型自动学习训练各因子与财产犯罪的非线性关系,建立了财产犯罪预测模型。文献[17]比较如K-Means、DBSCAN等聚类算法,分析其对案件的聚类效果,找出最适合犯罪检测的聚类算法。文献[18]提出一个综合框架,结合社会网络分析、小波变换和模式识别的方法预测恐怖组织的攻击行为。但上述方法的预测效果不理想,使用的数据量也较小,反映出的犯罪特征不够全面,且针对特殊的恐怖袭击犯罪事件的研究还较少。
本文使用GTD数据库中2015年和2016年30 000多条恐怖袭击事件数据,采用目前主流机器学习分类算法预测模型Bagging、决策树(Decision Tree,DT)、随机森林(Random Forest,RF)以及全连接神经网络(Fully Connected Neural Network,FCNN),对一个或多个恐怖袭击事件嫌疑人进行预测,并使用贝叶斯参数优化策略对各预测模型的超参数进行调节,从而找到最佳的预测模型超参数。
1 问题分析与数据收集
国内外学者对恐怖分子的犯罪心理[19]、动机特征[20]、发展特点等做了大量的定性研究。文献[21]对当代恐怖分子犯罪的目的和动机、主体构成、犯罪对象和结果以及犯罪手段进行了深入的探讨。然而这些定性分析的主观因素较多,并不能展示一个直观的结果。结合大量相关研究文献对已有的恐怖组织和个人进行详细剖析,发现每次恐怖袭击行为并不是任意的,而是有组织有目的的精心选择,相同组织和个人的袭击行为在一定程度上有着极大的关联性。针对这一现象,将每次袭击行为进行量化处理,对恐怖事件特征进行分析,根据已有的恐怖袭击事件制造者去预测未知恐怖事件的组织和个人。
依据特征对未知事件进行预测的方法有很多,机器学习算法是目前比较常见的一种。机器学习是一种关于研究“学习算法”的学问,依赖于已有数据建立模型算法,通过提供的经验数据,不断学习,找到最佳模型,在面对新的数据时,已经建立的模型会给出相应的判断[22]。本文研究的问题是将未知组织和个人的恐怖事件贴上已知的类别标签,即分类算法问题。依照机器学习的思想,将已有的恐怖事件特征数据输入分类算法模型中进行学习,得到最佳模型后对未知的数据集进行类别判断,从而预测出可能的恐怖组织和个人。
本文使用的数据均来源于全球恐怖主义数据库(GTD)。GTD是一个开源数据库,是世界上目前最全面的非机密恐怖袭击数据库,其包含1970年至今超过180 000次恐怖袭击事件的信息。每条GTD事件包括至少45个变量的信息,最近的事件包括超过120个变量的信息。这些变量的信息主要包含事件发生的日期和地点、使用的武器、目标的性质、伤亡人数以及可识别的负责团体或个人的信息等。本文在GTD中下载了2015年和2016年共发生的30 312起恐怖袭击事件特征数据作为实验的信息支撑。
2 恐怖袭击事件制造者预测模型
本文对下载数据进行特征选择后做标准化处理,将已经预处理的数据按犯罪组织名称或个人(gname)作为标签划分数据集。gname已知的作为训练集,未知的作为测试集。将训练集输入各个分类算法模型中学习训练,找到最佳机器学习算法模型,并用其预测测试集,对测试集进行分类并贴上标签。恐怖袭击事件制造嫌疑人预测流程如图1所示。

图1 恐怖袭击事件嫌疑人预测流程
2.1 数据处理
2.1.1 预处理
本文根据事件相关属性选取了12个特征。
1)事件发生的日期和地点:即年(iyear)、月(imonth)、地区(region)、附近地区(vicinity)、纬度(latitude)和经度(longitude)。其中,地区分为12类,每个类别如表1所示。

表1 地区类别
2)使用的武器和目标的性质:即攻击类型(attacktype1)、武器类型(weapontype1)、成功的攻击(success)和目标/受害者类型(targtype1)。其中,攻击类型共9类,如表2所示,武器类型共13类,目标/受害者类型共22类。

表2 攻击类型
3)伤亡人数:死亡总数(nkill)。
4)可识别的负责的团体或个人的信息:声称负责(claimed)共有两类,0表示没有人声称对事件负责,1表示一个组织或个人声称对袭击负责。
本文选择的特征数据包含不同的量纲,并且某些统一指标的数量级差距过大,为了使表征不同属性的特征有可比性,对其进行无量纲处理。数据标准化处理(Normalization),即归一化,可以保证各变量的变化幅度处于同一水平,使各指标处于相同数量级,从而消除数据之间数量级差距过大引起的误差。本文选取的30 000多条数据中,死亡总数这一特征各数值之间的数量级差距过大,因此,将其进行标准化处理。在机器学习分类问题中,多数算法基于向量空间中的度量进行计算,因此,特征之间的距离计算非常重要,而离散的特征值之间计算出的距离并不合理。为了使非偏序关系的变量取值不具有偏序性且到原点等距,本文采用one-hot编码处理特征,具体特征为年、月、地区、附近地区、纬度、经度、攻击类型、武器类型、成功的攻击、目标/受害者类型以及声称负责。由于gname字段包含实施攻击的组织的名称,因此以gname列作为分类标签并将其定性特征转换为定量特征。12个特征经过归一化和one-hot编码处理后,生成了一个1×76维的输入向量。
2.1.2 数据集划分
在训练模型时,首先将训练数据集划分为训练样本集和测试样本集,分别用来训练模型参数和评价预测效果。由于对数据集的划分会较大程度影响模型的预测结果,因此本文采用交叉验证策略来保证结果的稳定性。交叉验证法是一种常见的数据划分方法,它将数据集划分为K个大小相似的互斥子集,从而得到K组训练集和测试集,进而对模型进行K次训练。
本文选择K=10,即10折交叉验证。然而在10折交叉验证过程中,随机划分样本可能导致在训练样本集中不能包含所有类别的样本,即训练样本类别不全,且不同类别数据分布不匀。因此,本文对所有类别的事件个数分别进行统计,将统计的506个类分别按10折交叉验证的方法划分至训练样本集和测试样本集,即改进的10折交叉验证方法,如图2所示。

图2 改进的10折交叉验证方法
2.2 机器学习分类模型
根据恐怖袭击事件特征预测恐怖事件制造者属于机器学习中的分类问题,本文选择机器学习中主流分类算法Bagging、DT、RF和FCNN对恐怖袭击事件制造者进行预测,并对其性能进行评估比较。
Bagging,也称bootstrap aggregating,是并行式集成算法的代表[22]。集成学习的主要思路是先通过一定的规则生成多个学习器,然后通过对每个基分类器的预测结果投票来进行分类,最后综合判断输出分类结果。Bagging通过有放回的随机采样方法,得到n个含有m个训练样本的数据集,将这n个采样集分别送到n个基分类器中进行学习,并使用简单投票法对这n个分类器的预测结果进行表决。
随机森林[23]是在Bagging基础上的一个扩展,RF以决策树为基分类器,并且在决策树的训练过程中引入随机属性选择[22],增强了模型的泛化能力。
决策树[24-26]是一种从无次序、无规则的训练样本集中推理出决策树表示形式的分类规则方法。它主要由根节点、父节点和子节点、叶节点组成,决策树的生成过程包括构树和剪枝2个阶段。
神经网络是多个神经元按照一定的层次结构连接的一种网络结构[22]。机器学习中涉及的人工神经网络是模拟生物学上的神经网络,可将其视为包含许多参数的数学模型。根据KOHONEN于1988年的描述,神经网络可定义为由具有适应性的简单单元组成的广泛并行互连的网络,其能够模拟生物神经系统对真实世界物体所做出的交互反应。全连接是指神经网络的每层神经元都与下一层神经元全部连接,这种连接是神经网络最常见最基本的一种连接方式。通过三层神经网络可以拟合任意一种非线性函数,具有较强的自学习、自适应和泛化能力。
本文使用Python中scikit-learn[27]函数库实现决策树、随机森林、Bagging分类器,利用Python中keras函数库实现全连接神经网络。
2.3 评价指标
在使用机器学习模型进行预测之后,需要对预测结果做出评价。本文采用的评价指标为准确率A、精度P、召回率R和F1值。其中,准确率可以对预测结果做出直观反映,精度和召回率在准确率无法反映真实结果时对其做出补充。当P值和R值出现矛盾时,需要综合考虑2个指标,即综合评价指标F1值。
(1)
(2)
(3)
(4)
其中,TP为真正例,TN为真反例,FP为假正例,FN为假反例。
2.4 超参数优化
超参数[28-29]是机器学习模型中的框架参数,是在开始学习过程之前设置的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。它们跟训练过程中学习的参数(权重)不同,通常手工设定,然后不断试错调整,因此,大量的专家经验必不可少。为了避免重复试错的过程,采用非参数学习自动地优化模型参数选择。
贝叶斯优化[30-32]通过对模型进行拟合找到使获取函数最大化的超参数配置,对该配置进行评估,并重复这一过程。它是一种在没有目标函数的情况下根据已有的采样点预估函数最大值的自动寻优算法。该算法假设函数符合高斯过程,其主要目标为学习函数的形态和找到该函数的极值。本文输入超参数配置,通过贝叶斯优化算法对候选超参数配置进行预测,并且根据获取函数评估每个候选预测的效用,从而找到适用于每个学习模型的最优超参数。贝叶斯寻优的实现使用了Python中的Sherpa[33]函数库。
3 实验与结果分析
3.1 实验环境
本文实验的硬件平台为Intel(R)Core(TM)i5-4200M CPU @2.50 GHz、4 GB内存、1 000 GB硬盘以及Windows7操作系统,软件环境平台为Python3.6、keras、Sherpa以及scikit-learn。
3.2 结果分析
在将数据输入模型学习之前,使用贝叶斯优化对4种机器学习算法分别进行参数寻优。
1)Bagging算法的最佳模型内置参数:基分类器76个,最大特征数为61,最大样例数为7 557。
2)随机森林的最佳模型内置参数:基分类器51个,最大特征数为50,叶节点最小样本数为2。
3)决策树的最佳模型内置参数:分裂所需最小样本数为2,深度为30。
4)全连接神经网络的最佳模型内置参数:4个隐含层为全连接层,每层含118个神经元,激活函数为Relu,2个池化层(Dropout)分别舍弃1/3的神经元,输出层激活函数为Softmax。
对2015年和2016年的数据预处理后,分别输入4种分类算法中进行比较。实验通过改进的10折交叉验证分别训练10次,将每次训练的结果输出保留,并且计算10次输出结果的平均值,得到指标对比结果如表3和图3所示。

表3 4种算法预测结果
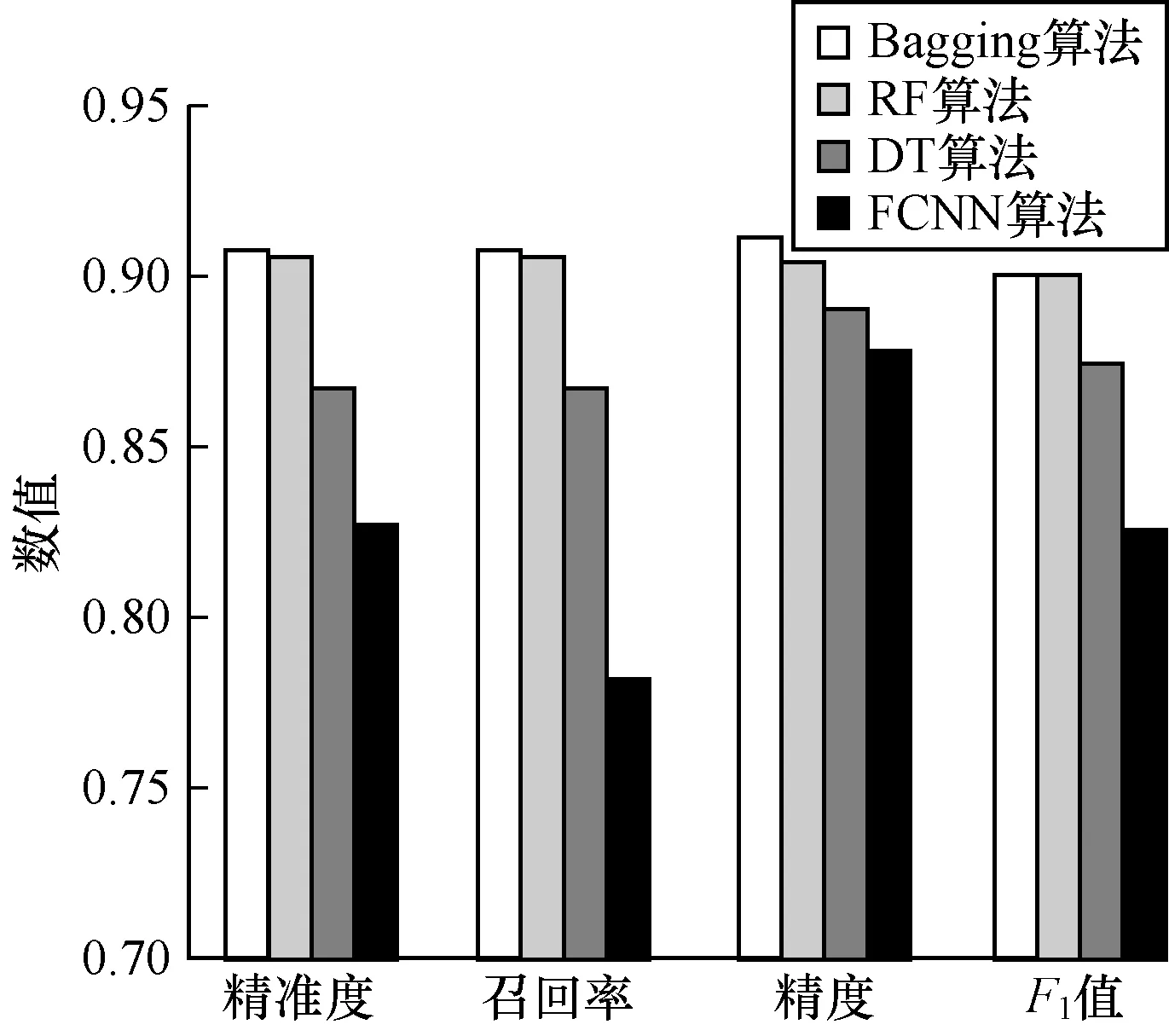
图3 4种算法预测结果对比
从表3可以看到,Bagging算法预测精度最高,为0.911 0,其准确率为0.906 5,综合评价指标F1值为0.899 8;其次是随机森林,其精度也达到了0.903 8;再次为决策树。由于这些算法都是基于树模型的分类算法,因此在本文实验中基于树模型的分类器预测精度都比较理想。
从图3可以看出,FCNN的4个评价指标中召回率较低,而精度较高。虽然精度和召回率的值越高越好,但是这2个指标在某些场景下却是互斥的,所以需要引进一定的约束,即权衡两者的F1值。FCNN的F1值高达0.825 3,说明在召回率较低的情况下,该算法仍然比较理想。
基于树的分类器精度固然比较高,但是也只能预测出相似度最高的一个结果,一旦出现误判就没有可供参考的其他选择,因此,本文引入全连接神经网络。从表3可以看出,全连接神经网络的预测精度为0.877 8,也达到了比较理想的状态,并且能够输出每个结果的概率大小。这样就可以在概率较大的前几个结果中进行排查,在一定的范围内锁定恐怖袭击犯罪嫌疑人。
4 结束语
本文比较Bagging、决策树、随机森林和全连接神经网络算法对恐怖袭击事件嫌疑人进行预测的结果。实验结果表明,基于树的算法可信度较高,其中Bagging算法的预测精度最高,但当出现误判或漏判时,该类算法只能输出一个置信度最高的结果而无法给出其他选择。全连接神经网络可以列出所有结果的可能性,并根据可能性大小,在排名靠前的结果中锁定目标,其预测精度为87%左右。根据实验结果,可以先以Bagging算法锁定头号恐怖袭击事件嫌疑人,再通过全连接神经网络算法在小范围内进行逐一排查,从而对恐怖分子作出针对性的打击。
