维吾尔语复杂形态对汉维机器翻译的影响研究
2020-02-19穆妮热穆合塔尔杨雅婷
穆妮热·穆合塔尔,李 晓,杨雅婷
(1.中国科学院新疆理化技术研究所,乌鲁木齐 830011; 2.中国科学院大学,北京 100049;3.新疆民族语音语言信息处理实验室,乌鲁木齐 830011)
0 概述
维吾尔语是典型的黏着语,其词汇是通过词干(词根)和词缀连接而衍生的,该属性使其生成大量的语素组合,呈现出丰富且复杂的形态变化,大幅增加了词汇量的规模,从而在汉语与维吾尔语之间的机器翻译中造成了未登录词的增多和统计模型的数据稀疏性问题,为降低数据稀疏度,词干、词尾分解后只保留词干而无条件地丢弃词尾会失去很多有用的信息,相反若保留所有的词尾则导致句子过长,会被词语对齐工具过滤掉[1]。对维吾尔语词尾粒度的切分采取选择性的保留方法,可以降低因不同形态带来的数据稀疏性问题,尽可能地增加汉语到维吾尔语的词对齐的数量来提高词对齐的正确率,从而可以达到提高汉维机器翻译的质量的目的[2]。
本文搭建基于统计的汉维统计机器翻译系统,通过词语对齐质量和语言模型困惑度等对不同粒度的维吾尔语与汉维机器翻译质量进行对比,最终根据实验来选择最佳粒度的维吾尔语语料。
1 维吾尔语形态特点

2 维吾尔语的复杂形态
维吾尔语词类大致分为实词、虚词、感叹词等,而实词分为动词和静词,虚词可分为后置词、连词、语气词等[5]。实词包含具有表达意义和形态变化的词类,虚词包含没有形态变化的词类。维吾尔语中的名词、形容词、数词等属于静词范围,在形态变化上具有一定的相似性。因为静词与动词是并列关系,静词与动词形态系统的差异较大[6]。维吾尔语静词构形词缀有 65 个不同的词缀,名词有49 个词缀,数词有 57个词缀,形容词有55个词缀,动词有150个多词缀。当一个词干缀接不同的词尾时会表现出不同的语法功能,在汉语跟维吾尔之间互相翻译时会出现一个维吾尔词语对应到汉语中一个短语的情况[7]。图1是维吾尔语在没有进行形态分析前的汉维对齐的情况。
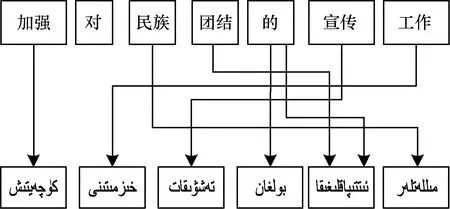
图1 未进行形态分析前汉维词语对齐的情况
如果对维吾尔语词本身进行词干与词缀之间的切分,并且去除所有词缀只保留词干形式进行汉维词语对齐时,其结果如图2和图3所示。

图2 基于词干的汉维词语对齐情况

图3 去掉词尾后的词干汉维词语对齐情况
图2和图3显示不同粒度的词干词语对齐结果,不同粒度的词干指的是维吾尔语最小词干(图2)和去掉最后一个词尾以后剩下的词干部分(图3),本文中均成最大词干[9]。显然基于不同粒度的词干词语对齐时没有多对多的情况,能明显降低数据稀疏性问题。当然,去掉词缀后的词干对齐虽然没有多对多的情况,但是会导致词缀自带的部分重要语法信息的丢失[10]。因此,下一步对不同粒度的词干-词缀进行词语对齐,如图4(词干+词缀)和图5(词干+词尾)所示。

图4 基于词干-词缀的汉维词语对齐情况
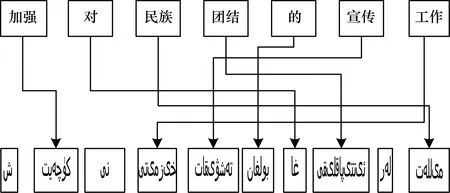
图5 基于词干-词尾的汉维词语对齐
3 实验系统搭建
本文使用开源的Moses翻译解码器中基于短语的加码器分别以不同粒度的维吾尔语语料为目标语言,并以汉语语料为源语言进行基于双语平行语料的汉维翻译。图6所示为翻译系统基本框架[14]。

图6 汉维翻译训练及解码流程
Fig.6Flowchart of Chinese-Uygher translation training and decoding
该系统由语料预处理、语言模型训练、翻译模型训练和解码等4个模块组成。其中翻译模型可以被Moses识别,一组特殊格式的文件集,其结构复杂,但是整体描述的是从汉语的“某个短语”翻译成维吾尔语的“某个词或者短语”。语料的预处理和语言模型训练的过程将在3.1节介绍[15]。
3.1 语料预处理
在基于语料库的汉维统计机器翻译中进行翻译时,由于语料的来源和获取方式的不同,可以在训练和翻译过程中使用的语料需得进行预处理,除了用中科院计算技术研究所开发的分词工具对汉语语料进行分词外,还可用其他的工具对维吾尔语语料进行词例化,本文用艾则孜等人开发出来的维吾尔语词法分析工具,将维吾尔语语料进行预处理并准备了不同粒度的语料,如词、词干、词干+词缀、词干+词尾、最大词干等5种不同粒度的维吾尔语语料以及已分词好的汉语语料,2种语言语料是平行语料[16]。
3.2 词语对齐
对现有的语料进行处理以后,训练双语语料时利用GIZA++进行无监督的汉语维吾尔语对齐训练,在读取要翻译的输入文件时GIZA++构造IBM模型的各个模型,然后通过期望最大化算法(EM)进行反复迭代训练,生成最有可能性的对齐信息结果供下一步规则抽出使用。EM算法是一种从不太完整的或者有数据丢失的数据集中求解概率模型参数的最大拟然估计方法,EM算法中循环E步骤是求在当前参数值和样本下的期望函数Q(随机变量z的概率密度函数),M步骤是利用期望函数重新计算模型中新的估计值[17]。E步骤对于每一个i的计算公式如式(1)所示。
Qi(zi):=p(z(i)|x(i);θ)
(1)
M步骤是利用期望函数重新计算模型中新的估计值。M步骤计算公式如式(2)所示。
(2)
3.3 语言模型训练
在统计机器翻译中,语言模型对于整个翻译系统而言是不可缺少的-部分,语言模型不仅能提高输出句子的流利度,而且对词汇顺序和词汇翻译的决策过程也起着重要的作用。简单来说,对本文语言模型函数的输入是维吾尔语,而输出是概率,最常用的语言模型建模方法是N-gram建模法,该模型是一个假设,即第N个词的出现只与前面N-1个词相关,整句的概率就是各个词出现的乘积,例如,对一个由m个词构成的句子t=w1,w2,…,wm,它的概率计算公式如式(3)所示[18]。本文中使用语言模型工具SRILM对汉维平行语料库的维吾尔语语料进行训练。
p(w1,w2,…,wn)=
p(w1)p(w2|pw1)…p(wn|w1,w2,…,wn-1)
(3)
本文分别对不同粒度的维吾尔语在不同单位的语料建立语言模型。在建立语言模型时,需要一个评价语言模型质量的测度,即困惑度,困惑度在交叉熵上的基础上进行简单变换。其基本思想是给测试集的句子赋予较高概率值,语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型在测试集上的概率越高越好[19],计算公式如式(4)所示。
PPP=2H(PLM)
(4)
由式(4)可知,困惑度越小,句子概率越大,语言模型也越好。表1是不同粒度语料在不同单位的N-gram语言模型的困惑度[20]。
表1 不同级别语言模型N-gram的困惑度
Table 1N-gram perplexity degree of different levels of language model

困惑度词词干词干-词缀最大词干词干-词尾1-gram2879.301003.10597.341619.97972.272-gram270.79145.3159.26198.6984.723-gram185.4693.9431.83132.8647.974-gram173.8985.6726.28122.7442.565-gram176.2486.4625.76124.2342.44
由表1数据可知,在不同粒度的语言模型中,基于词干-词缀粒度的4-gram 语言模型的困惑度最低,仅次于词干-词尾粒度的5-gram语言模型。其他粒度的语言模型性能随着N-gram单位的增加而增高。图7所示是不同语言模型的困惑度。
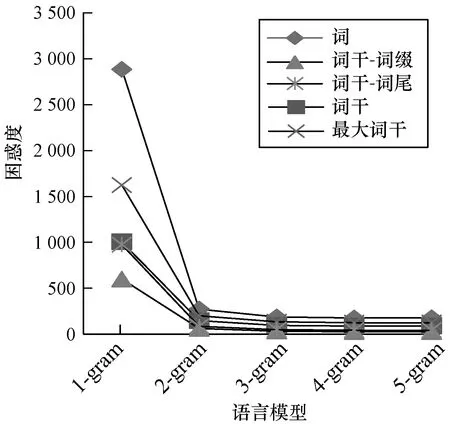
图7 不同N-gram语言模型的困惑度
4 实验结果与分析
本文在Linux工作环境下搭建了基于短语的汉维机器翻译系统,分别在同样规模和内容但级别不同的汉语-维吾尔语平行语料库上进行实验。上述级别分别是基于词的、基于词干的、基于词干-词缀的、基于词干词尾的和基于最大词干的语料,3种语料的汉语端完全相同,维语端是根据需要分成上述的3种级别供实验所用。实验数据规模如表2和表3所示。
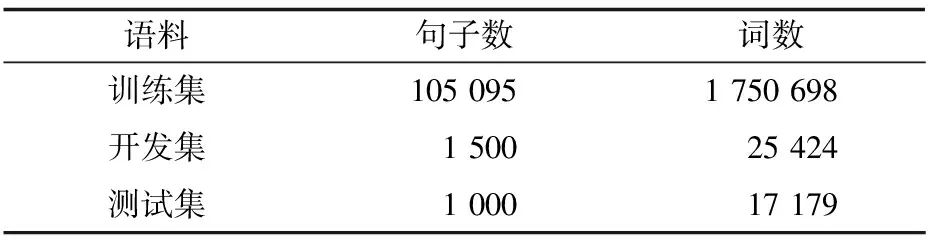
表2 汉语端语料信息统计
表3 基于不同粒度的维吾尔语语料端信息统计
Table 3 Information statistics Uyghur corpus based on different granularities

粒度语料句子数单词与词素数词级训练集1050951797453开发集150027116测试集100017072词干级训练集1050951784642开发集150027201测试集100016652最大词干级训练集1050851801105开发集150027233测试集100016656词干-词缀级训练集1050843055782开发集150045195测试集100028729词干-词尾级训练集1050952625988开发集150039245测试集100024525

表4 不同粒度汉维机器翻译实验结果
Table 4 Experimental results of Chinese-Uyghur machine translation with different granularities

粒度语料BLEU值词级测试集20.34开发集23.88词干级测试集21.73开发集26.66最大词干级测试集17.60开发集20.30词干-词缀级测试集23.71开发集27.00词干-词尾级测试集20.03开发集23.20
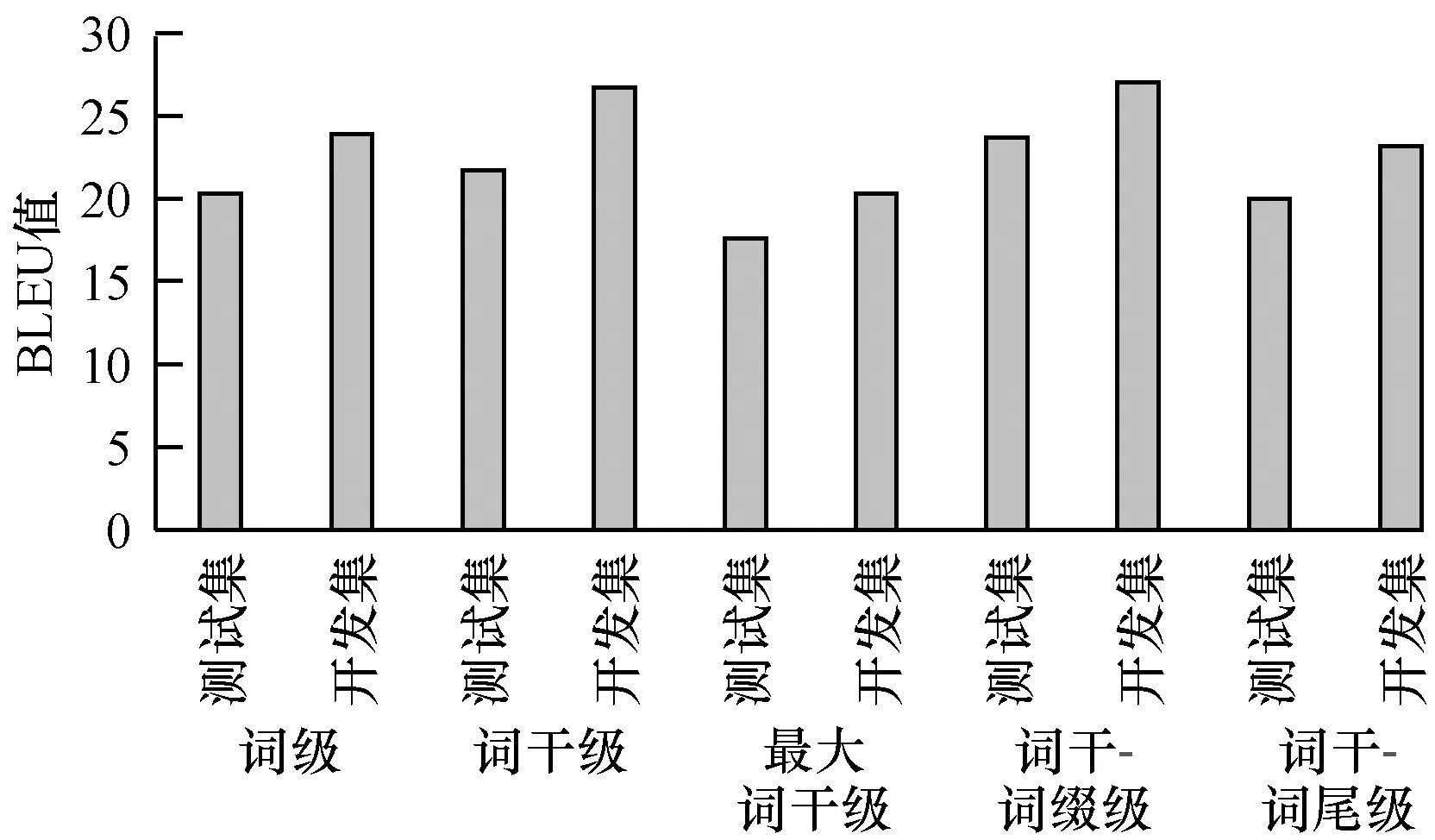
图8 不同粒度汉维机器翻译BLEU值对比结果
Fig.8 Comparison results of BLEU values of Chinese-uyghur machine translation with different granularities
从表4和图8可以看出,基于词干的翻译结果的BLUE值明显高于基于词级的翻译结果,但是因为基于词干的维吾尔语中所有构形词尾都被去除,所以词语对齐时训练不充分,导致一些重要的语法信息丢失,而基于词干-词缀级别的和基于词干-词尾级别粒度实验中汉语与维吾尔语词语对齐效果较好,其翻译质量也明显提升。
5 结束语
维吾尔语的复杂形态对基于统计的汉语与维吾尔语的词语对齐及语言模型的质量有较大影响,直接关系到两种语言之间的翻译结果。本文对比了不同粒度的5种维吾尔语汉语平行语料,维吾尔语词缀切分粒度的不同,基于不同粒度的N-Gram语言模型对BLEU值的提高幅度也不同。实验结果表明,基于词干的维吾尔语和基于词干-词尾的维吾尔语目标端语料的翻译质量明显高于其他3种语料。由于维吾尔语词干词缀自动切分工具功能的差异性影响最佳词干-词缀正确粒度的切分,导致部分的词缀形态信息缺乏,下一步将采用相关维吾尔语形态还原方法得到带有所需形态信息的完整句子,以保证翻译结果的流利度。
