基于DSSD的静态手势实时识别方法
2020-02-19周文军王昱洁
周文军,张 勇,王昱洁
(合肥工业大学 计算机与信息学院,合肥 230601)
0 概述
人机交互[1]是实现用户与计算机之间信息交换的通路,而基于计算机视觉的手势识别则提供了一种更加自然和谐的人机交互方式,成为人机交互领域的研究热点。手势识别的研究促进了远程操控、VR[2]等相关技术的发展,同时也对手语识别发挥着重要作用。
一般的静态手势识别方法通常分为检测分割、特征分析、分类器识别3个阶段[3]。此类方法易受背景干扰,且由于需先分割再识别,因此实时性不高。针对上述问题,研究者采用基于卷积神经网络(Convolutional Neural Networks,CNN)[4]的方法进行手势识别。这类方法无需将手势从图片中分割出来,图像可以直接输入神经网络,省去了传统识别算法中手动提取特征的复杂操作[5]。文献[6]提出一种基于CNN的手势识别方法来识别图片中人类日常生活的手势动作。文献[7]将CNN应用于手势识别,并通过大量仿真实验证明了该方法的有效性及鲁棒性。文献[8]提出一种基于Faster R-CNN的手势识别算法,并在多个手势数据集上取得了较好的检测结果。
上述基于CNN的手势识别方法提高了实时性,但由于未融合各个特征提取层的语义信息,因此检测精度未能得到进一步提高。DSSD[9]算法是一种基于深度CNN的算法,其通过反卷积模块融合了各个特征提取层的语义信息,检测精度较高并对小目标较为鲁棒。本文提出一种静态手势实时识别方法,在DSSD网络模型的基础上,针对自制的数据集,利用K-means算法[10-11]及手肘法选取先验框的宽高比以提高检测精度,采用迁移学习[12]的方法,对比不同基础网络(AlexNet[13]、VGG16[14]、ResNet101[15])对DSSD网络模型的影响,同时解决数据量小所导致的检测精度低下的问题。
1 DSSD网络
1.1 基础网络
DSSD的结构如图1所示,其基础网络为ResNet101,其中conv3_x层为ResNet101中的卷积层,之后5层是一系列逐渐变小的卷积层,上述卷积层作为DSSD网络的特征层(共6层)。在这之后DSSD添加了一系列反卷积层并设计了反卷积模块来融合先前的特征层(conv3_x、卷积层)和反卷积层。此外,DSSD还设计了新的预测模块并将预测移到了反卷积层上进行。
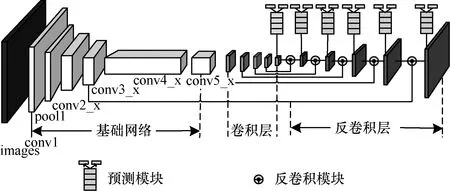
图1 DSSD网络结构
1.2 反卷积模块
反卷积模块的功能是将高层特征映射信息与低层特征映射信息进行融合,其结构如图2所示。可见,DSSD使用已学习好的反卷积层代替双线性上采样,并在每个卷积层之后添加归一化层。另外,DSSD在结合高层特征映射和低层特征映射时,采用基于元素点积的方式以获得更好的精度。
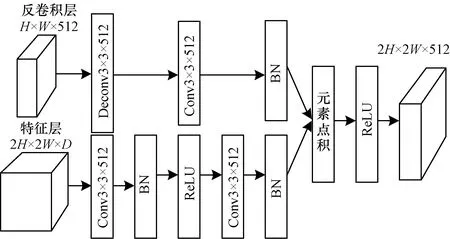
图2 反卷积模块
1.3 预测模块
SSD预测模块如图3(a)所示,图3(b)是在SSD预测模块的基础上添加了一个残差单元,并在残差旁路将原先的特征图做卷积处理后与网络主干道的特征图做通道间加法,从而形成一个新的预测模块。

图3 预测模块
1.4 DSSD识别手势过程
DSSD识别手势是一个回归与分类的过程,其中,生成识别边框是一个回归的过程,判断识别框内手势所属类别是一个分类过程[16]。因此,总体目标损失函数可表示为定位损失和置信损失的加权和:
(1)
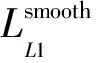
(2)
置信损失Lconf(x,c)是多类置信度的Softmax损失,表示为:
(3)
DSSD识别手势具体步骤如下:
步骤16个特征层可得到6个大小不同的特征图,每个n×n大小的特征图有n×n个特征图小格,每个特征图小格产生K个先验框。其中K=2+2m(m为宽高比的个数),代表着2个大小不同的正方形先验框与2m个长方形先验框。
步骤2对于每个真实手势目标g,找到与其交并比最大的先验框以及任何与其交并比大于阈值(例如0.5)的先验框,这些先验框与其进行匹配,称为正样本,反之则为负样本。将真实目标的位置信息和类别信息映射到先验框上。
步骤3对于各个特征图中的正负样本,分别对其进行预测(通过2个3×3卷积核对特征图进行卷积操作)从而获得预测框l的置信度和位置信息。将其与经步骤1、步骤2后得到的先验框进行损失计算,损失函数为定位损失和置信损失的加权和,如式(1)所示。
步骤4对于每个预测框,按照类别置信度确定其手势类别并过滤属于背景的预测框,根据置信度阈值(如0.5)过滤阈值较低的预测框,执行NMS算法[17]过滤重叠度较大的预测框,剩余的预测框就是检测结果。
2 数据集制作与模型训练
2.1 手势数据集的采集与制作
本文利用普通网络摄像头mosengsm rqeso008在不同背景、光照强度下采集了4 800张手势图片,部分图片如图4所示。每张图片中有1个~3个不等的手势,手势总个数为10 000个,分为10类手势,它们在中国手语中分别代表着10种不同的意思,如图5所示。

图4 训练图片样例

图5 应用于中国手语的10种手势
图片采集完毕后,利用标签标注工具LabelImage对感兴趣的手势部位进行人工标注,得到真实目标的标签文件并将数据集转换为ldbm格式。针对自制的数据集数据量不足的问题,本文采用数据增强[18]方法,对每个训练图像,从下列3种采样策略中随机选取一种进行采样。
1)使用完整的原始图片。
2)截取图片中的一块使其与真实目标的交并比为0.1、0.3、0.5、0.7 或 0.9。
3)在原始图片上随机截取一块,截取比例为原图片的[0.1,1]。
采样后,每个采样块被调整至固定大小,并进行随机的光学畸变及0.5倍概率的水平翻转。
2.2 先验框宽高比的选取
由DSSD识别过程可知,宽高比的个数越多,先验框的数量也就越多,越能找到与真实目标更匹配的先验框从而提高检测精度,但同时也会在预测及进行NMS时花费更多的时间。因此,选取一个合适的宽高比十分重要,针对自制的数据集,本文重新选取了先验框的宽高比。
本文使用K-means聚类算法来获得手势宽高比的k个聚类中心,并且使用手肘法来确定最优k值。手肘法的核心指标是误差平方和(Sum of Squared Errors,SSE),计算公式如下:
(4)
其中,ci是第i个簇,p是ci中的样本点,mi是ci的质心(ci中所有样本的均值)。SSE是所有样本的聚类误差,代表了聚类效果的好坏。当k小于真实聚类数时,SSE的下降幅度会较大,而当k到达真实聚类数时,SSE的下降幅度会骤减。
本文首先从标签文件中获取手势的宽和高从而得到宽高比,然后以宽高比为特征运行K-means算法,从k=3开始,不断增大k值,实验结果如图6所示。可以看出,当k=5时SSE的下降幅度开始减缓。因此,k=5为本文最优k值,此时的宽高比聚类结果如表1所示。

图6 k值与SSE的关系

表1 不同宽高比对应的聚类结果
可见,先验框的宽高比在1~3之间,本文选取1、1.5、2、3作为先验框的宽高比。
2.3 迁移学习
迁移学习一般是将从源域学习到的关系应用到目标域。迁移学习能够很好地解决数据量不足的问题,而且有利于缩短训练时间,提高模型的识别率。
由于本文数据集较小,直接训练的效果较差且训练时间较长,因此使用在 PASCAL VOC 数据集下训练得到的残差网络参数来对DSSD 模型的基础网络进行初始化,再对网络进行训练(训练时先验框宽高比为1、1.5、2、3),训练结果为迁移 Resnet101 模型。同样,将DSSD的基础网络分别换为去掉全连接层的VGG16和AlexNet,选取VGG16中的卷积层conv4_3、AlexNet中的卷积层conv5,分别与额外的5层卷积层一起作为特征层进行特征提取与融合,并使用在PASCAL VOC数据集下训练得到的参数来初始化DSSD 模型的基础网络,之后对网络进行训练,训练结果分别为迁移VGG16 模型以及迁移AlexNet模型。作为对照,不引入迁移学习即不使用已训练好的参数,直接对本文数据集进行训练得到无迁移Resnet101模型、无迁移VGG16模型以及无迁移AlexNet模型。
3 实验与结果分析
3.1 实验条件
本文实验计算机的操作系统为Ubuntu16.04,CPU为英特尔i7,GPU为INVDIA GTX Titan X,内存为32 GB,CUDA为cuda8.0。实验使用深度学习计算框架Caffe。
3.2 网络训练
从收集的4 800张图片中,随机选择3 600张图片作为训练集,其余1 200张图片作为测试集。
第1阶段:以去掉全连接层的AlexNet、VGG16及ResNet101分别作为SSD的基础网络,训练得到3个不同的SSD模型,输入图片的大小为321像素×321像素。在训练时,前5 000次迭代使用学习率10-3,5 000次~7 000 次迭代使用学习率10-4,7 000次~8 000次迭代使用学习率10-5,经过80 000次迭代模型收敛。
第2阶段:加载上一阶段训练好得到的3个SSD模型来分别初始化DSSD网络,冻结SSD网络的参数,训练反卷积模型。前20 000迭代使用学习率10-3,后20 000次使用学习率10-4,40 000次迭代后得到收敛的3个最优DSSD模型。
3.3 迁移学习结果
为了验证迁移学习是否产生作用,对2.3节中训练得到无迁移Resnet101模型、无迁移VGG16模型、无迁移AlexNet模型、迁移 Resnet101模型、迁移VGG16模型以及迁移AlexNet模型分别进行测试,结果如表2所示。由表2可以看出,在数据量较少的情况下,迁移学习确实可以提高模型的识别精度,本文以平均精度均值(Mean Average Precision,mAP)作为评价指标。以基础网络Resnet101为例,迁移学习将mAP从0.748提高至0.945。此外,作为DSSD的基础网络,相比于AlexNet和VGG16,ResNet101有着更高的识别率。因此,本文选用ResNet101作为DSSD的基础网络进行后续实验。

表2 迁移学习结果
3.4 先验框宽高比
本文选定了基础网络ResNet101后,验证2.2节中重新选取的宽高比是否使识别精度得到了提高。在其他条件不变的情况下,使用原始宽高比{1,2,3}重新训练一个迁移Resnet101模型进行对比实验,识别结果如表3所示。由表3可以看出,本文重新选取的宽高比{1,1.5,2,3}相对于原宽高比{1,2,3}可使识别精度提高了1.9%。
表3 不同宽高比的DSSD算法识别结果
Table 3 Recognition results of DSSD algorithm with different aspect ratios

宽高比mAP原始:{1,2,3}0.926新选取:{1,1.5,2,3}0.945
3.5 输入图片尺寸
为了进一步提高识别精度,针对Resnet101网络,本文通过增大输入尺寸的办法来使深层的feature map仍然保持空间信息。因此,本文将输入图片的尺寸增大至513像素×513像素进行对比实验,测试结果如表4所示。
表4 不同输入图片尺寸的DSSD算法识别结果
Table 4 Recognition results of DSSD algorithm with different input image sizes

图片尺寸/像素mAP识别速度/(frame·s-1)321×3210.94515513×5130.9568
从表4可以看出,当输入图片的尺寸较小时,DSSD算法的mAP为0.945;当输入图片的尺寸增大时,DSSD的mAP提高了0.011,达到了0.956。但是,随着图片尺寸的增大,识别速度也随之降低。因此,在实时性要求不高的场合,可以通过增大输入图片尺寸来提高检测精度。
3.6 模型对比实验
为了说明本文方法的性能优劣,基于相同的数据集,分别采用Faster R-CNN[19]、YOLO[20]和SSD[21]神经网络来训练手势识别模型以作为对比。为确保实验的公平性,通过调参将各方法的手势识别模型均训练至最佳。参照各方法在PASCAL VOC数据集下训练得到的训练参数值,针对本文数据集,采用以下策略选取了各方法几个主要训练参数的最优值:
1)通过观测模型收敛速度(即损失函数值的变化率)来选择基础学习率,以收敛速度最快的学习率作为基础学习率。
2)采用变化的学习率来训练模型,每当损失函数值的变化率小于一定阈值时(据观测及经验值,此处阈值选择为0.005),便将学习率调整至原来的0.1倍,从而使模型更有效地学习以降低训练损失。
3)权重衰减沿用经验值0.000 5。
4)当损失函数值趋于0、训练精度不再提高时,认为模型训练完毕,此时的迭代次数作为总迭代次数。
本文采用上述策略选取得到的最优训练参数参与训练得到了各方法的最佳手势识别模型,各方法的最优训练参数值如表5所示。训练结束后,分别测试各方法的最佳手势识别模型,其识别结果如表6所示。其中,SSD(300×300)代表该方法输入SSD模型的图像尺寸为300像素×300像素,其他方法类推。可以看出,2种DSSD方法的识别精度分别高达0.945和0.956,均优于其他方法。但由于DSSD采用了更深的网络结构,并增加了额外的预测模块和反卷积模块,因此其检测速度较其他方法稍慢,但仍保持了15 frame/s和8 frame/s的合理检测速度。因此,相较于其他方法,本文方法在保持合理速度的同时获得了较好的精度。

表5 各方法的最优训练参数值

表6 各方法最优模型的识别结果
3.7 不同环境下的识别结果
上述实验对比了本文方法与其他方法的识别精度,本节进一步实验统计其在4种不同环境下的识别精度,结果如表7所示。由表7可以看出,该方法在明亮、简单背景环境下的识别效果最好,mAP达到了0.956和0.965,而在较暗、复杂背景的环境下识别精度最差,但其mAP仍达到了0.935和0.949,可见本文方法受环境的干扰不明显,可完成多种环境下的检测任务。
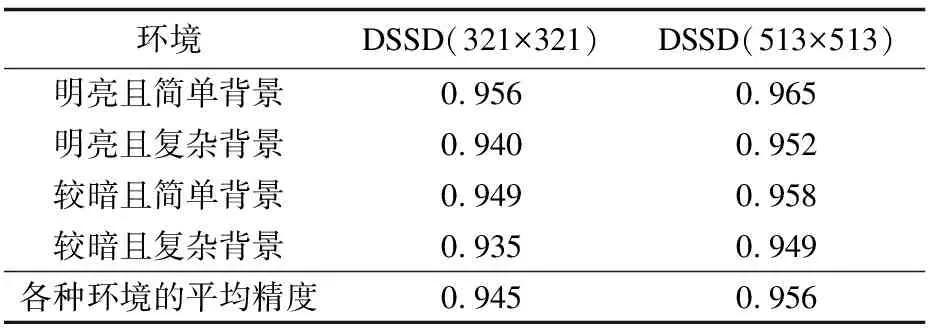
表7 不同环境下的mAP值
3.8 小手势目标的检测能力
由于DSSD设计一个反卷积模块来融合各个特征提取层的语义信息,因此本文方法在检测小手势目标方面也具有较好的能力。为了证明这一点,本文拍摄了300张测试照片(距离摄像头约8 m),其中手势相对于图片非常小。与表6中识别精度表现较好的SSD(512×512)方法进行比较,结果如表8所示。其中2个检测示例如图7和图8所示。可以看出,本文方法在小手势目标的检测能力上优于SSD(512×512)方法,可实现较远距离的手势识别。
表8 SSD与DSSD对于小手势目标的检测结果
Table 8 Detection results of SSD and DSSD for small gesture targets

方法mAPSSD(512×512)0.757DSSD(513×513)0.817

图7 SSD(512×512)方法对小手势目标的检测结果

图8 DSSD(513×513)方法对小手势目标的检测结果
4 结束语
本文提出一种基于DSSD的识别方法用于实时识别静态手势。在自制的数据集中,采用K-means聚类算法及手肘法选取先验框的宽高比,并以ResNet101作为基础网络,利用迁移学习解决小数据集带来的检测精度低的问题。实验结果表明,经过训练,得到2个手势识别模型DSSD(321×321)和DSSD(513×513)的mAP分别为0.945和0.956,优于基于Faster R-CNN、YOLO及SSD等网络的手势识别方法,并且其检测速度可达15 frame/s和8 frame/s,可满足实时识别的需求。此外,本文方法对小手势目标也有较好的检测性能,能够实现相对远距离的手势识别。后续将尝试用简单的双线性上采样来代替反卷积层,进一步提高检测速度。
