语音识别技术在智能审计中的运用初探
2020-02-14何若云杨天杨琦阮国蓓张玲
何若云 杨天 杨琦 阮国蓓 张玲

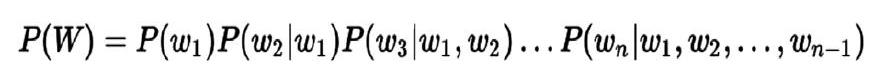
[摘要]本文从人工智能领域及其中语音识别技术的发展背景与应用情况入手,结合非结构化数据,分析阐述现有语音识别技术基础模型及特点,探析语音识别技术在商业银行智能审计领域运用的可能性。
[关键词]智能审计(SA) 非结构化数据 语音识别技术
一、绪论
(一)人工智能发展背景
诞生于20世纪中叶的人工智能(Artificial Intelligence, AI)技术是近几年最热门的科技词汇,在类别上可分为强人工智能与弱人工智能。目前几乎所有能接触到的人工智能应用,如图像识别、语音识别、棋类博弈、自然语言理解、自动驾驶等都属于弱人工智能范畴,强人工智能至今仍未突破瓶颈。
人工智能的发展经历了两次高潮及两次低谷,当前随着云计算的出现、计算机算力的飞跃、大数据的诞生以及神经网络算法进一步深度发展,人工智能步入了第三次繁荣期,“AI+”概念出现在各行各业中,审计领域的“智能审计”技术也应运而生。
(二)大数据时代的非结构化数据
1.结构化数据。简单来说即存储于关系型数据库的数据,也称为行数据,数据以行为单位,每一行数据表示一个实体的信息,各个字段在每一行数据中的属性是相同的,通过关系型数据库二维表结构来进行存储和管理。与此对应的是不适合用关系型数据库二维表来展现的半结构化数据及非结构化数据。
2.半结构化数据。即介于完全结构化数据与非结构化数据之间的一种数据形式,一方面包含了我们需要了解的数据细节,不能简单地将数据组织成任意的文件按照非结构化数据处理;另一方面由于结构变化区别很大,又不能够简单地建立关系型数据库表与之对应。半结构化数据通常使用半结构化的XML文档、JSON格式、文本文件等来描述。
3.非结构化数据。即数据本身没有数据结构模型进行预先定义,通常包括各种格式的办公文档、报表、图像、视频及音频等。因非结构化数据异构性程度高,目前还没有简便的非结构化数据处理工具方法。
(三)智能审计概念
在智能审计(Smart Audit,SA)技术出现之前,已被广泛使用的审计技术有两种:计算机辅助审计技术(Computer-Assisted Audit Techniques,CAATs)与非现场审计(Off-Site Audit),两种审计技术与审计信息化概念联系最为紧密,二者既有联系又有区别。
1.计算机辅助审计技术。即审计人员在审计及相关管理过程中,使用计算机或者计算机软件作为工具,以半自动化或自动化方式执行一定的审计程序及审计工作的一种审计技术。
2.非现场审计技术。即审计人员通过连续收集、整理审计对象业务经营管理过程中的数据和资料,运用适当的方法或流程进行分析的一种远程审计程序。
计算机辅助审计技术是审计方法的集合,而非现场审计技术则是一种审计程序或者说是一种审计实施方式。计算机辅助审计技术并不是非现场审计所特有的,在现场审计活动中也可使用该种审计方法;但非现场审计主要依赖计算机辅助审计技术。
3.智能审计技术。近年来,随着大数据技术的出现及人工智能技术的飞跃式发展,多种智能技术的出现打破了传统审计在数据规模、范围以及类型方面的限制,出现了智能审计的概念。智能审计相比于计算机辅助审计技术,审计覆盖的数据范围更大,数据分析能力更全面,能够对各类结构化和非结构化数据处理分析,且智能审计具有更强的自动化处理能力,最重要的是涵盖机器学习技术的智能审计具备智慧的风险洞察能力。智能审计技术与早期的计算机辅助审计技术联系密切,其本质是计算机辅助审计技术的进化,但青出于蓝而胜于蓝,智能审计是人工智能与大数据时代的计算机辅助审计,是审计数字化进程中具备智慧的一种计算机辅助审计技术。
(四)语音识别技术
语音识别技术是人工智能技术的重要组成部分之一,其目标是将自然语言的语音内容转换为计算机可读的字符序列,进一步研究这些字符序列的含义,即让机器听懂自然语音。
二、语音识别技术原理模型
(一)语音识别原理简介
语音识别即把语音变成文字可以看成是广义上的标注问题。如给定一段语音信号作为输入X,语音识别就是需要找出一个单词序列W,使得W与X的匹配程度最高,这个匹配程度用概率W*表示。語音识别就是求解条件概率最大值:
通常一段自然语言的语音产生是由人先想好想说的词句即W,然后再把它说出来即X,故上述条件概率是反的。可利用贝叶斯公式,将上述条件概率反过来变成:
其中P(W)表示单词序列W本身的概率,也就是W这样串成的单词本身有多大可能性成为一句合理的句子。P(X|W)表示给定单词序列W以后出现语音信号X的概率,即W这串单词有多大可能性发成X这串音。语音识别即要找W使得这两个概率乘积达到最大值,这是语音识别的核心内容,而P(W)被称为语言模型,P(X|W)被称为声学模型。
(二)语言模型
语言模型P(W)一般利用马尔科夫链式法则,把一个单词序列的概率拆解成其中每个词的概率之积,即设W是由组成的,则可以拆成:
其中各项为在已知之前所有词的条件下,当前词的条件概率。一般语言模型的处理方法是认为每个词的概率分布只依赖于之前若干个词,这样的语言模型就是常用的n-gram模型,即其中每个词的概率分布仅仅依赖于之前的n-1个词。
(三)声学模型
声学模型的任务是计算P(X|W),即给定单词序列W,发出这段语音X的概率。首先通过词典模块把单词串转换成音素串,词典一般认为是与声学模型、语言模型并列的模块;然后通过动态规划算法进行词的音素分界点的计算;同时,还需对语音信号进行频谱分析,即将语音信号分成一个个帧,对于每一帧通过傅里叶变换,将其转换成一个特征向量,常用的特征向量有梅尔倒谱系数(MFCC)等。通过训练数据中特征向量与其对应的音素就可以得到特征到音素的分类器,进而得到声学模型P(X|W)。此前广泛使用在语音识别中的利用隐藏马尔科夫链的高斯混合模型(GMM-HMM)就是一种音素分类器,而近年流行的基于神经网络的深度学习模型(DNN)就是一种新型音素分类器。GMM-HMM估计出每个音素的特征向量分布,然后计算每一帧特征向量xt在给出相应音素si的条件概率P(xt|si),再将每一帧条件概率相乘,得到声学模型P(X|W)。而DNN是直接给出P(si|xt),利用贝叶斯公式转换成P(xt|si),再相乘得到声学模型P(X|W)。使用GMM-HMM的语音识别可称为传统的语音识别,对小词汇量及孤立词识别很好,而在连续长语音识别中DNN可以进一步提升识别精确度。
三、商业银行智能审计“FACP”过程方法论
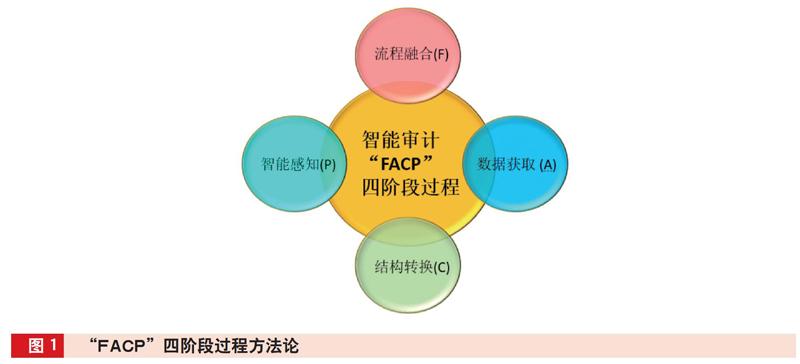
目前国内对于商业银行智能审计并未制定相关的准则来使其标准化,笔者在深入分析人工智能技术可运用在审计过程各阶段的可能性上,将其有机结合,归纳总结出一套智能审计“FACP”过程方法论,将智能审计技术分为流程融合(Flow-fusion)、数据获取(Acquisition)、结构转换(Conversion)、智能感知(Perception)四个阶段,如图1所示。
(一)流程融合阶段(Flow-fusion)
原中国银监会于2005年10月提出“流程银行”的概念后,构建“流程银行”的理念迅速被各家银行所接受。商业银行各项业务即是对不同业务流程相应规定的集合,而风险疑点也往往根据业务的不同出现在特定流程的特定环节上。了解银行业务的最好切入点是熟悉业务流程,商业银行内部审计最主要的价值是发现问题揭示风险,这就要求审计对业务流程进行把控。
掌握业务流程,就有了审计框架。对于智能审计而言,首先要教会机器具体的业务流程,利用人工智能将审计需要把控的业务流程自动化。对应这项过程概念,目前已应用的智能审计技术是机器人流程自动化技术(Robotic Process Automation, RPA)。RPA是一种既定规则的软件程序,目标是替代人类执行规定的高重复性信息系统操作步骤。重要的是RPA不受信息系统间接口和IT基础架构的限制,使用非侵入的方式,模仿人类操作行为对信息系统进行访问,如银行职员在操作信息系统时常见的复制、粘贴、点击等操作,或者是日常工作中收发邮件操作。RPA还可以根据预设的内部审计规则,在非业务时段每天从信息系统中持续获取审计证据,使得开展持续性检查变成可能。运用智能审计RPA技术可以使内部审计效率得以提升。流程融合阶段就是要分析具体业务流程,将可自动化的业务审计流程固定在RPA的既定规则里。
(二)数据获取阶段(Acquisition)
上述RPA技术主要是强调流程自动化的实现,同时也可获取部分格式的业务数据,但通常这些数据是固定的规范化格式的内部数据。智能审计的另一项主要数据获取技术是爬虫技术(Spider),通常用于获取互联网外部数据,它是一种浏览网页的自动化程序,即按照一定的规则模拟人工点击,自动地抓取互联网信息,如网页、文档、图片、音频、视频等信息。一般这种爬虫程序的运行可以实现自动高效的读取收集网络数据,包括结构化数据及非结构化数据。大数据时代的爬虫技术,是大数据前端数据采集技术,为内部审计带来了丰富的异构化数据,是智能审计的基础性技术。
(三)结构转换阶段(Conversion)
智能审计不同于传统的计算机辅助审计,它有能力对非结构化数据进行处理分析。目前,在图像和语音非结构化数据处理方面应用的技术有文字识别技术(Optical Character Recognition,OCR)及语音识别技术(Automatic Speech Recognition,ASR)。文字识别技术是对扫描的图像文件经过预处理、图像切分、特征提取、匹配及模型训练等步骤将图片中的文字转化为可编辑文本的图像信息处理技术,简而言之就是研究怎么把图像转换成文字。而语音识别技术就是研究怎么把语音转换成文字。此外还有视频模式分析技术,如可以对银行监控录像进行自动视频分析转换成相应的事件文字描述。总之,在智能审计数据转换实施过程中,主要的任务就是把图片、语音、视频等非结构化数据转换为结构化数据。
(四)智能感知阶段(Perception)
上述三个阶段的目标就是为智能感知阶段服务,虽然每个阶段都或多或少地融入一些人工智能技术,但智能感知阶段才是智能审计的意义所在。对应的人工智能技术包括自然语言处理技术(Natural Language Processing,NLP)、知识图谱技术(Knowledge Graph,KG)等。自然语言处理技術是使计算机拥有处理自然语言的能力,让计算机能够理解自然语言。而知识图谱技术是在语义识别的基础上体现各个主体之间复杂的关联关系。在智能审计的感知阶段,其实已没有固定的定式化技术,而是针对具体问题用特殊的人工智能方法来处理。对内部审计而言,就是如何让机器理解已转为结构化数据的这些数据的含义,自动地提取审计风险点。
四、语音识别技术的智能审计实践及实证分析
传统的人工检查理财等销售录音录像(以下简称“双录”)方式,不仅成本高、工作量大,而且长时间观看可能会产生疲劳而遗漏对具体问题的发现。笔者运用语音识别技术针对某银行理财等销售录音录像非结构化数据,使用自行研发的音视频处理工具进行语音识别及审计取证,同时结合“FACP”四阶段过程方法论来进行实证分析。
(一)流程融合
某银行目前对理财等代销业务“双录”的规程为2018年下发的《关于柜面及电子机具开展个人代销业务“双录”工作的操作规程(试行第三版)》(以下简称“双录规程”),其中明确并细化了客户通过同一或不同柜面(地点)及客户通过ITM自助机具购买产品“双录”流程及话术。经过对“双录规程”总结,风险把控点主要包括:(1)客户通过同一或不同柜面(地点)购买产品进行“双录”前需要争得客户同意;(2)客户通过ITM等自助机具购买产品时网点人员仅限给予口头指导,严禁代客户操作;(3)需向客户推介匹配其风险承受能力的产品,避免不当营销;(4)不得代替客户填写或签字,不得诱导客户填写不真实的选项;(5)销售人员需按相应话术进行“双录”,不得违规承诺或夸大收益;(6)风险提示语句等内容,应在录像中清晰可辨。
经过讨论分析,风险把控点(1)因某银行尚未规范化录音录像文件格式规格且在同一或不同柜面(地点)即理财室内进行营销操作的录音为远场录音,不在一般的语音识别技术处理能力范围内。把控点(2)(4)(6)需用到视频模式识别技术。而把控点(3)(5)则可对ITM智能机具“双录”(为近场录音)通过语音识别“风险”“承受”“收益”“保证”等关键词进行初步识别。
(二)数据获取
通过科技提数,随机提取UIP系统(某银行“双录”系统,以下简称UIP)2019年以来发生的20笔ITM智能机具录音录像文件,语音普通话较为标准,视频格式为MP4。
(三)结构转换
运用语音识别技术专门针对某银行理财等销售录音录像非结构化数据进行语音转换识别,并进行审计实践取证。识别工具的运用及语音识别实践的主要包括以下方面。
1.运用识别工具的视频文件处理模块对“双录”视频文件进行处理转换。该模块还支持对“双录”视频文件的人工查看,以方便审计人员人工确认“双录”内容,如图2所示。
视频处理模块最主要的功能是用来截取视频文件中的音频流,并对截取的音频流重新编码转换为PCM文件,具体转换为单声道16位编码16K采样率的小端PCM音频文件,通常的语音识别底层引擎是在该技术规格的PCM音频文件基础上进行语音识别。PCM文件保存的是未经压缩的音频信息,其中16位编码是指,每次采样的音频信息用2个字节保存(一个字节含有8个字位)。16K采样率是指1秒内采样16,000次。单声道是指只有一个声道。视频处理模块同时支持单个“双录”视频文件PCM转换及批量化的PCM转换,并将转化结果保存在特定的目录下供音频识别模块处理,如图3所示。
2.在识别工具的音频识别模块中对转换好的PCM文件进行语音活动检测(Voice Activity Detection,VAD)切分。在切分前因“双录”录音含有客户敏感信息故采用Audition软件人工截去客户敏感信息。由于语音识别底层引擎并非直接对任意时长的语音进行识别,而是对数十秒内的语音段进行识别,所以需要对长段语音进行切分。而语音活动检测就是对语音端点(语音边界)进行检测的技术,即在语音的静音处进行截断。笔者自研的识别工具语音活动检测模块采用的是Google开源音视频流项目WebRTC中的语音活动检测函数模块,主要思路是对音频的每一帧计算其高斯概率分布并以此判斷该帧是静音还是有语音存在,进而在连续静音后遇到语音的帧之前或连续语音后遇到静音的帧之后进行切分,以此完成对长段语音的切分。语音活动检测模块将切分好的小段语音音频提供给音频识别引擎进行识别。
3.识别工具的语音识别模块采用百度人工智能开放平台中的语音识别引擎进行语音识别,该引擎在希尔贝壳中文普通话开源语音语料库的基础上训练并提供调用接口,在经过了DNN等当代流行的语音识别模型的数年迭代发展后,已达到很好的识别效果。在自研识别工具中选中需要识别的PCM文件,即可对单个语音音频进行识别,识别速度较快,识别率在可接受范围内,并且可以对识别的结果进行半结构化的文本文件保存,如图4所示。此外,识别工具支持批量PCM音频文件的识别,并在批量识别完成后自动将每个语音文件对应的识别结果在特定的目录中保存为相应的半结构化文本文件,以供后续分析处理,如图5所示。
(四)智能感知
通过结构转换阶段,已将“双录”的MP4视频非结构化数据转化为语音所对应的文本格式的半结构化数据。在智能感知阶段,选用Astro Grep工具软件对半结构化的文本进行分析。匹配条件采用“风险|承诺|收益|保证|利率|利息”正则表达式,即通过正则表达式单词搜索出现过风险、承诺、收益、保证、利率、利息等字样的语音文本文件。对筛选出的含有相关字样的文本文件进行查看及进一步分析,发现有两类销售话术运用不当。
一是个别销售人员明确答复客户理财产品无风险。具体为一个ITM理财产品销售录音识别文本中含有“风险”字样,完整话语为“没有风险的啊”,看似一句疑问句,疑为客户询问某银行营销人员是否有风险。然后我们进一步调取同文件名的“双录”视频进行确认,视频中客户确实向大堂经理及理财经理询问、确认产品有没有风险,都得到了肯定的回答,不符合某银行“双录规程”规定。在这段视频中时长总计116秒,相比整个语音识别的耗时仅为26秒,仅为视频时长的20%左右。
二是销售人员话术中对收益的描述用词不规范。具体为通过正则表达式搜索发现有4个销售录音识别文本中含有“利息”字样,疑为销售人员在描述理财等产品收益时使用了存款产品中对应的“利息”概念,而某银行标准话术应为“预期收益”。进一步调取同文件名的“双录”视频进行确认,发现其中两个视频为客户自己引用“利息”概念,而另两个视频为销售人员在向客户销售时使用“利息”一词。这两个用词不规范样本语音识别耗时亦为视频总时长的20%左右,并且此次全部处理的语音识别耗时平均固定在视频总时长的20%上下,远少于人工查看“双录”视频所需耗时。
五、结论与展望
(一)研究结论
一是语音识别技术能将传统计算机辅助审计技术无法涉及的语音资料纳入审计范围。二是语音识别技术相对于传统由人力查看录音录像视频可以极大缩短取证时间,提高审计效率。此外,笔者总结归纳的智能审计“FACP”四阶段过程可以作为智能审计的方法论广泛运用于人工智能技术的审计过程中。
(二)后续研究展望
一是录音录像、包括采样率在内的规格格式尚未统一,利用语音识别技术进行审计全覆盖就必须先统一规格格式。二是语言识别模块需要加入同时支持远场语音及近场语音识别的场景。三是语音识别模块还应具备说话人识别的功能,针对银行案例中,应能够区分来自客户和银行工作人员的语音话语。四是某银行业务体量绝大部分集中在S地区,应考虑在语音识别技术中加入当地方言的支持。五是在最后智能感知阶段可采用自然语言处理技术,即让机器直接理解语音识别对应的文字,而不是使用工具对半结构化文本进行搜索。
有鉴于此,未来商业银行智能审计语音识别应把握两个方向:一是鉴于实时短语音识别在效率和准确性上优于事后全量长语音识别,可考虑在流程融合阶段将风险把控触角直接放在录音录像时进行,使得风险控制更为及时。二是对于全国性大型商业银行、有较多分行的股份制银行或部分规模较大的城商行来说,应考虑在语音识别前置入方言识别分类模块,相关技术将涉及神经网络语言识别等。
(作者单位:上海银行,邮编:200120,电子邮箱:yangyt@bosc.cn)
主要参考文献
陈燕等.非结构化数据处理技术及应用[M].北京:科学出版社, 2017
柳若边.深度学习语音识别技术实践[M].北京:清华大学出版社, 2019
吕赫.基于DNN的语言识别系统的研究与实现[D].电子科技大学, 2017
汪莉,叶健彪.基于OCR的审计技术创新与实现[J].中国内部审计, 2019(4):44-47
王小波.计算机辅助审计技术在商业银行IT内审中的应用与实践研究[Z].上海银行, 2018
