基于频繁模式挖掘对企业成功人士取得成就的因素研究
2020-02-14余振洋
余振洋

摘要:当今世界随着信息技术的发展,一群有理想、能奋斗、肯吃苦的人在社会发展的大潮中站稳了脚步,他们十分成功。但是,诸类成功人士取得某种成就的因素不一而足,且众说纷纭。在此之前,已有诸多学者对此进行了大量研究,所得到的结论很多也是一样的,如:马云小的时候学习吃力,考学困难,诸多学者便从他的家庭背景、生活经历以及性格情况着手,进行分析,然而大多数从片面得出某些人之所以取得某种成就的结论,他们的结论缺乏一些科学性的数据来支撑其研究结果的科学性。而我将从“因素量化和公式计算”的角度分析得到科学的、有条理的结论。利用频繁模式挖掘的数据处理方法可以使数据更具条理更加容易分析,本文收集了诸多成功知名企业家和一些几乎是失败了的企业家的资料,并对可能对其取得成就的因素进行了提炼与分析,有正面例子,有反面例子分析这个问题就更全面了。经过一番研究观察之后,我最终发现成功人士取得某种成就的关键主要与社交人群的影响程度、成功路上的关键机遇的帮助、家庭经济基础、对所研究领域感兴趣程度、个人努力的程度、个人的创造能力、面对挫折的抗压能力、长远的目标和可行性计划这八方面因素有關。我会将这八个因素量化再运用频繁模式挖掘里的算法计算得到结论。
Abstract: With the development of information technology in the world today, a group of people with ideals, struggles and willingness to endure hardships has set foot in the tide of social development, and they are very successful. However, there are many factors contributing to the success of various types of successful people, and there are different opinions. Prior to this, many scholars have done a lot of research on this, and the same conclusions have been obtained. For example, Ma Yun was struggling to study when he was young, and Many scholars start with his family background, life experience and personality, but most of them draw one-sided conclusions that some people have achieved certain achievements and their conclusions lack some scientific data to support the scientificity of their research results. And the author obtains scientific and methodical conclusions from the perspective of "factor quantification and formula calculation". Data processing methods that use frequent pattern mining can make the data more structured and easier to analyze. This article collects information about many successful and well-known entrepreneurs and some almost failed entrepreneurs, and refines the factors that may achieve them. With the analysis, there are positive examples, and there are negative examples to analyze the problem more comprehensively. After some research and observation, the author finally discovered that the key to successful people's achievement is mainly the degree of influence of social groups, the help of key opportunities on the road to success, the economic foundation of the family, the degree of interest in the research area, and the degree of personal effort, personal creativity, ability to face frustration, long-term goals and feasibility plans. The author quantifies these eight factors and use the algorithm in frequent pattern mining to calculate the conclusion.
关键词:成功人士;成就;因素;数据挖掘
Key words: successful people;achievements;factors;data mining
中图分类号:TP301.6 文献标识码:A 文章编号:1006-4311(2020)01-0292-05
1 概述
1.1 背景问题
当今世界电子科技与互联网迅速崛起,由信息技术带来的信息革命使一批人抓住商机成为了著名成功人士,但是有些人的家庭条件不是很优越;有些人没有交到好的事业伙伴;有些人没有受到好的教育等等,影响一个人成功的因素有好多好多,很多情况下两个人的生活经历都不同但是都作出了一番事业,那么这便使我们开始好奇:究竟有哪些因素影响着一个人是否能取得一定的成就呢?
1.2 综述
关于影响人成功的因素的问题是许多社会学者所热切关注的问题之一。之前许多学者从他的家庭背景、生活经历以及性格情况着手,进行分析,从而片面得出某些成功人士之所以取得某种成就的结论,但缺乏一些科学性的数据来支撑其研究结果的合理性。而我将用频繁数据挖掘的方法科学地分析这一问题。
1.3 本文思想
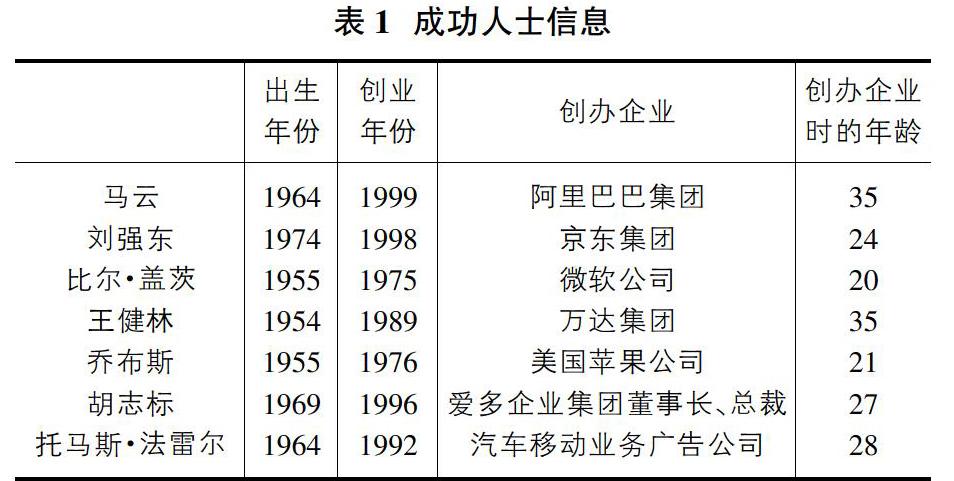
为了更好的研究这个问题,没有现实的数据是不行的,我将一些像马云一样的成功人士的事例搜集来做成表格,当然也有一些并不是十分成功的人的例子作比较。鉴于在此之前大多学者已从各个成功人士的家庭背景、生活经历以及性格情况着手分析,我在此基础上将其进行数据化,从较理性的层面通过大量数据的形式更加直观的将其呈现出来。经过我的初步分析,就拿这当中一些成功的企业家和不是很成功的人来举例,不难类比归纳得出如表1信息。
从表1中,不难发现这些成功人士存在的一些共同点。他们的创业年龄大多在二三十岁左右,同样是造诣相当高的一些著名企业家,他们的背景与经历却又存在着很多不同。那么究竟是什么因素在他们的成功之路上起到推波助澜的作用呢?他们所处的年代、国家等不同自变量变量对结果因变量应该起到了一定的影响。于是我又找到两位同时代的企业家爱多企业集团董事长、总裁胡志标、美国汽车移动广告业务公司的托马斯·法雷尔创业在一个时期失败的实例。可以看出一个人所处国家年代对结果没有多大影响。通过我对示例的提炼总结发现一个人的成功指数与这个人的计划和目标、社交人群、成长路上的机遇、经济基础、兴趣、努力程度、创造能力、抗压能力有关。我先对结果进行预测:成功与自身因素有很大关系相反与环境因素关系不大。为了更加便于研究,得出合理的结论,我们将我们所挖掘到的数据信息进行量化分析,得出下面的一系列分析结果。
1.4 本文结论
经过研究分析,数据结果显示与预测出入不大。由此基本上可以得出结论:成功人士取得一定程度上的成就的主导因素在自身,而与外界变量关系不大。
2 数据和模型介绍
2.1 数据介绍
我从大量的信息资料当中提取了八个因素进行分析,分别是有长远的目标和可行的计划、社交人群对研究对象的影响、研究对象在成长之路上的机遇、家庭的经济基础、研究对象对其研究领域的兴趣、个人努力程度、有强大创造能力、面对挫折有强大的抗压能力。在这些自变量中,再次将其按不同程度分为1、2、3、4、5五个档次。通过对多个不同的成功人士的分析以表格和图像的形式匹配相应数据。同时,我还搜集了一些在企业经营过程中并没有取得相对成就的人士实例,通过对比进行分析,得出更加完整有效的结论。
2.2 频繁模式挖掘介绍
频繁模式挖掘学术界也称之为关联分析法,是计算机用来处理数据的一种基本方式,目前在各与计算机和人工智能相关的行业中这种数据处理方法十分普及。频繁模式挖掘(关联分析)就是提取出频繁地出现在数据集中的模式(项、项集、事务等),这就像一个大超市人们在其里购物,商家须通过关联分析的方法找到卖出最多的商品从而提升超市的营业额。那么什么是项;什么是项集;什么是事务?项就是我们在分析超市顾客购物篮中的物品一样及我们研究对象的最小元素。项集是几个项组成的集合,是一个整体概念。事务是一种可以用作输入数据的特殊的项集,这就像顾客手中的购物篮一样里面装的是一个一个的商品——项。项有集事务也是有集合的,诸多事务集合在一起的集合就是事务集,事务集与项集不同的地方就在于:项集是一个集合的过程,而事务是作为输入的数据。接下来我会介绍频繁模式挖掘的符号体系。
符号体系:我们常用X表示一个项集,常用ti表示一个事务而事务集用T表示。支持度計数:项集的支持度计数是指这个项集在所有事务集中出现的次数,用符号σ表示,这就好比顾客们选了多少次相同的几种商品。
公式和思想:支持度、置信度计算公式:支持度计数的计算公式为:σX=ti|X?哿ti,ti∈T}|项集的支持度表示的是项集中的各项同时显示的频率,从一定程度上反映了各项之间的相互关联。
X支持度计数与事务的总数N的比值就是支持度,所以支持度:supX=σX/N,N=|T|置信度-描述一个规则可信程度的量:对于一个规则X→Y而言它的置信度是conf(X→Y)=σ(X∪Y)/σ(X)。
最小支持度阈值min_sup这个阈值就是判断一个项集是否足够频繁的标准即为-满足最小支持度阈值的项集就是频繁项集-有k个项的频繁项集就是频繁k项集。最小置信度阈值min_conf这个阈值是判断一个规则是否足够可信的标准-一般情况下的阈值设定-支持度阈值:0.2/0.3-置信度阈值:0.6/0.75。
规则的有效性:需要满足支持度阈值且满足置信度阈值的规则是有效的规则。因为具有不确定性的数据集越来越多,从不确定事务数据集中挖掘出频繁项集也成为数据挖掘项目中的一个重要且较困难的课题。
剪枝、加快计算速度的方法:①子集支持度一定比超集大;②子集不满足最小支持度阈值,则超集肯定不满足最小支持度阈值;③如果一个集合不是频繁项集,则没有必要计算超集,这就是先验原理。上述策略就是剪枝的一种,剪枝不是一种特定的算法,而是一种通用的优化策略。
介绍算法过程:如果一共有n个项,那么所有的项集一共有2n-1个,考虑x1?奂x的情形所以:supX1=σX1/N,supX=σX/N
必有σX1≥σX
则有supX1≥supX
我们可以知道可以不用计算超集,这就是剪枝的算法过程。
FP Tree是一种比较简单的求频繁项集的方法,依旧用之前的顾客购物的例子。
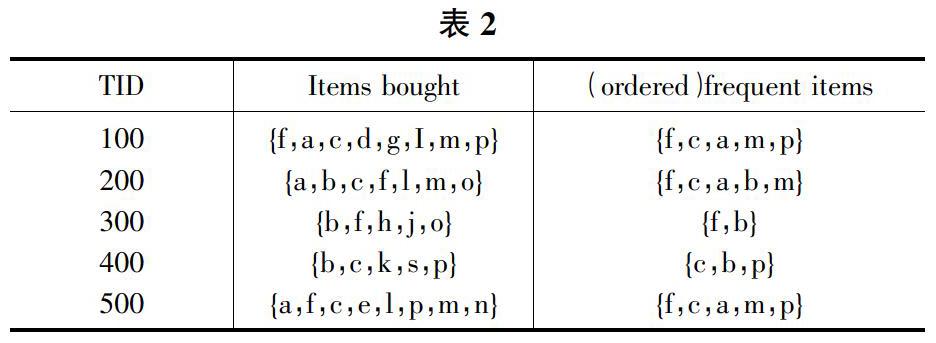
设项集I={a,b,c,d,e,f,g,h,I,j,k,l,m,n,o,p},交易数据库如表2。
解释表格中各表头意思,TID:事务编号Items Bought就是那个购物篮frequent items则是我们想要的频繁项集,我们可以用FP Tree求出频繁项集中最令人喜爱的也就是出现次数最多的那个“商品”。过程就是:依次求出各个项的频率,根据最小支持度阈值(0.6)留下频繁的项,按照频率从大到小依次排列,上文的(Ordered)Frequent Items就是将事务中的频繁项挑选出来按照频率从大到小排列。
得到表3。
有这个表格我们就可以轻易的看出大多数客人是喜欢物品F和C的。
下面我为大家介绍构建FP Tree-算法步骤:扫描一次数据库,计算各项的频繁度,将各项按照频繁度进行降序排列,生成频繁项头表,扫描数据库,建立FP-Tree。树的创立,①创立树的根节点,用null标记;②将每个事务中的项按递减支持度排列,并对每个事务创建一个分支,比如为第一个事务{f,c,a,m,p}构建一个分支;③当为一个事务考虑增加分枝时,沿共同前缀上的每个节点的计数加一,为跟随前缀后的项创建节点并连接,比如将第二个事务{f,c,a,b,m}加到树上时,将f,c,a各计数增加1,然后为{b,m}创建分枝;④创建一个项头表,以方便遍历,每个项通过一个节点链指向它在树中出现的位置。
上面的例子用FP-Tree做出来的效果如图1。
通过上述表格与这棵“树”我们很容易就发现了最频繁的项是什么,完整性:不会打破任何事务数据中的生长模式;为频繁模式的挖掘保留了完整信息,紧凑性:减少了不相关的信息——非频繁的项被删除;按频率递减排列——使得更频繁的项更容易在树结构中被共享;数据量比原数据库小运算简单容易发现结果,这两大性质组成了FP Tree的优点,现实计算操作中运用FP-Tree问题就会变得简单起来。
那么,FP Tree的数据挖掘方法是什么呢?首先必须具备拥有挖掘条件模式基(频繁项集的基础)然后从项头表开始挖掘,由频率低的节点开始,沿循每个(频繁)项的链接来遍历FP树,通过积累该项的前缀路径来形成一个条件模式基;然后由条件模式基再次构建FP-Tree(对于每一个条件模式基),为基中的每一项累积计数,再为模式基的频繁项构建出了FP-Tree。
3 频繁模式挖掘应用
3.1 数据准备
我们将成功人士的事迹通过分析总结转化为一个个变量——因素,又将因素转化为字母变量abcdefgh如表4。
选取训练集和测试集:既然非频繁项集的超集毫无价值,那么可以通过只合并频繁項集的方法来生成新的频繁项集 最简单的思路:Fk-1*F1:①将所有的频繁(k-1)项集放入集合Fk-1中;②组合Fk-1和F1可得k ——频繁候选项集; ③然后筛选候选项集,将频繁项集放入Fk;④重复上述过程直到停止;⑤初始的F1可以手动筛选获取;⑥存在的问题 - {a,b}+{c}={a,c}+{b}={b,c}+{a}。
3.2 计算过程
之后我们将数据代入一下老师所指导的电脑代码运算得到结果 ,依据结果得出影响人们成功的因素和树立向着成功人士学习的目标的结论。电脑代码如图2。
代码的介绍:数据的输入:将因素变量1~5和成功指数0~2代入本代码的数据导入部分,里面‘中加黑部分是我们输入的成功指数和因素程度,之后代码运作用搜查提取合并的方式计算出关于这几个数据的集,最后的list指的是,将这些自变量中的频繁项集与因变量中的频繁项集,搜出列表,输出这些集组合成的表,我们再由集统计分析出影响人成功的因素。
根据运行结果我们可以总结出有关成功人士成功的因素的结论:
①一个人的成功与一个人的内部因素十分得重要,外界的因素却影响不大。
②内部因素中,个人的努力程度和有长远的目标和可行的计划是最重要的,这两种因素使很多出身贫穷的人取得了成功。
③社交人群对研究对象有良好的影响如给予帮助等,会促进人的成功,但是社交人群对研究对象不好的影响时会使人跌入深渊。当个人对其研究对象有浓厚兴趣,且拥有强大的抗压能力会促使其成功。
④在当今社会具有强大的创造能力一定是每一个成功人士的必备品质。
⑤机会永远是留给做了准备的人的,成长之路上的机遇与个人的努力结合在一起十分容易成功。
⑥所以,我们应该在努力的基础上树立长远的目标和制定可行性的计划,在各个社交环境中结识对己有帮助的朋友提高社交群体的正影响,如果遇到机遇就不要放过用强大的创造能力开辟一片天地,在现实中锻炼出自己面对挫折有强大的抗压能力。
⑦做到以上这些就会离成功更进一步但是这一切因素的基础是努力程度。
4 总结
4.1 全文总结
在研究整个问题的过程中运用到了频繁模式挖掘的诸种方法,直观地反映了因变量随着自变量变化的趋势和结果,更加直观地对“什么因素影响人成功”有了了解。在本文中运用到了以下几种数学计算方法和公式:①支持度计数计算公式:σX=ti|X?哿ti,ti∈T,|这个公式表明了项集在事务集中出现的次数。②支持度计算公式:supX=σX/N,N=|T|这个公式可以直观的表现出某项集的支持的程度。③置信度公式为:对于一个规则X→Y而言它的置信度是conf(X→Y)=σ(X∪Y)/σ(X)它会反应规则可信程度。剪枝的算法过程:supX1=σX1/N,supX=σX/N。
必有σX1≥σX则有supX1≥supX它可以使我们的数据计算变得简单。
再者可以运用FP-Tree的方法通过扫描事务集中的频繁项集计算各项的频繁度,将各项按照频繁度进行降序排列,生成了直观的频繁项头表,再根据扫描频繁项头表从null开始创建更加直观的FP-Tree树图,创建步骤就是:将每个事务中的项按递减支持度排列;并对每个事务创建一个分支;当为一个事务考虑增加分枝时,沿共同前缀上的每个节点的计数加一,为跟随前缀后的项创建节点并连接;创建一个项头表,以方便遍历,每个项通过一个节点链指向它在树中出现的位置,再从树图中分析影响成功人士成功的因素的重要程度排序,依据这个结果得出影响人们成功的因素和树立向着成功人士学习的目标的结论。
4.2 文章反思
本篇论文对研究课题的呈现方式与之前诸多社会学者对这个问题的探究有所不同,我将大篇幅的已有信息与成功创业者们的个人资料背景分析整理成为了因变量与自变量,运用频繁模式挖掘多种方法和执行老师指导的电脑代码从更加理性的角度科学地对其进行了探究,这个样子的结果更具有说服力。本文还存在着一些不足之处,比如样本数量较少;计算结果与预期结果略有不同,所用方法较少等,我会吸取这类教训,增加自己的经验认识,在今后的学习及创建论文时尽量规避此类问题,增加样本数量、完善论文的科学性,从而使结果更具有合理性、科学性更加真实,得到的研究結论更为人认可。
4.3 展望
在今后的学习生活当中,随着我们知识的增长,阅历经验的不断丰富,相信将来一定会呈现出更加完整、更加理性的研究思路与架构,和更加准确的数学和计算机知识,也会多多规避在本次研究过程当中所遇到的一系列问题。我们会在这条研究之路上会越走越远,不断开拓,不断进取,不畏艰难,用不同种方法、更多知识,改良我对这个社会热点话题的研究成果,给自己、给社会提交一个更加完美的结论,提交一个更加可行的成功人士培训计划!
参考文献:
[1]罗之皓.知识图谱的Top-k摘要模式挖掘方法.
[2]曹菁菁.基于并行Apriori的物流路径频繁模式研究.
[3]池云仙.基于包含度和频繁模式的文本特征选择方法.
[4]李勇男.基于频繁序列模式挖掘的反恐情报关联分析.
[5]曾新.基于数据规范化的co-location模式挖掘算法.
[6]何镇宏.并行频繁项集挖掘算法研究.
[7]宗士强.基于频繁项集挖掘的雷达PRI模式提取方法.
[8]李涛.一种top-K序列模式挖掘算法.
