基于卷积注意力机制的情感分类方法
2020-02-08顾军华彭伟桃李娜娜董永峰
顾军华,彭伟桃,李娜娜+,董永峰
(1.河北工业大学 人工智能与数据科学学院,天津 300401;2. 河北工业大学 河北省大数据计算重点实验室,天津 300401)
0 引 言
在深度学习之前,情感分析[1,2]是以基于规则的和统计的方法为主[3]。Maite等[4]提出了一种融合多方面的文本情感因素的方法来进行情感分析,根据句子语气强度的不同而赋予不同的权重,同时考虑了否定词、程度副词等对情感倾向的影响,最终取得了不错的分类效果。
随着深度学习在图像处理上取得的成就,近年来,学者们将其应用到自然语言处理情感分析上面来。Zhang等[5]提出了一种用于文本分类的字符级别的卷积神经网络(CNN),且获得了不错的结果。胡朝举等[6]将主题词融入进行建模,使用双向LSTM网络模型进行情感分类。Zhou等[7]首先使用LSTM网络来捕捉文本的前后语义关系,之后使用二维的CNN卷积和池化的方式来提取局部最优情感性。Hassan等[8]将CNN卷积结合LSTM进行分类,实验验证了卷积层结合LSTM网络进行文本情感分类的有效性。RNN的优势在于能够更好地捕捉上下文信息,特别是长文本的语义。但RNN模型无法捕捉文本局部信息,忽略了情感转折词对整个文本情感倾向的影响,从而限制其分类精度。
基于以上问题,本文首先提出了一种基于卷积操作的注意力模型,使用卷积操作提取文本注意力信号,将其加权融合到Word-Embedding文本分布式表示矩阵中,从而突出文本关注重点的情感词与转折词,实现文本注意力机制;其次提出CNN_attention_LSTM模型,将注意力模型和LSTM加权融合最终实现文本情感分类。
1 相关工作
1.1 注意力机制
注意力机制最早由Bahdanau等[9]应用到自然语言处理领域,之后该模型成为了主流注意力模型的理论基础。
Yang等[10]将注意力机制应用到文档级别的情感分类,以RNN隐藏单元作为输入的感知机来模拟人脑注意力机制,与非注意力机制相比,取得了不错的结果。Pavlopoulos等[11]提出深层注意力机制,将其应用到审核用户评论,取得了比 RNN 更好的效果。Du等[12]提出新的卷积注意力模型,基于认知神经科学思想,使用卷积神经网络和长短期记忆神经网络(LSTM)模型来提取文本注意力,使用卷积操作获取文本权重,再将权重赋予到LSTM隐藏层输出上作为文本的注意力信号。
本文结合以上研究成果,提出一种基于卷积操作的注意力机制模型,对于文本数据,使用CNN做一维卷积操作将词嵌入矩阵转化为一维向量表示。在CNN的模型中,长度为n的文本序列(必要时填充)可以表示为
x1∶n=x1⊙x2⊙…⊙xn
(1)
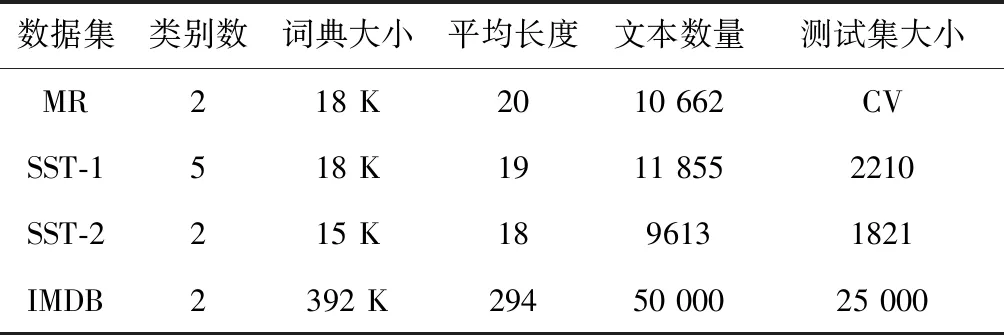
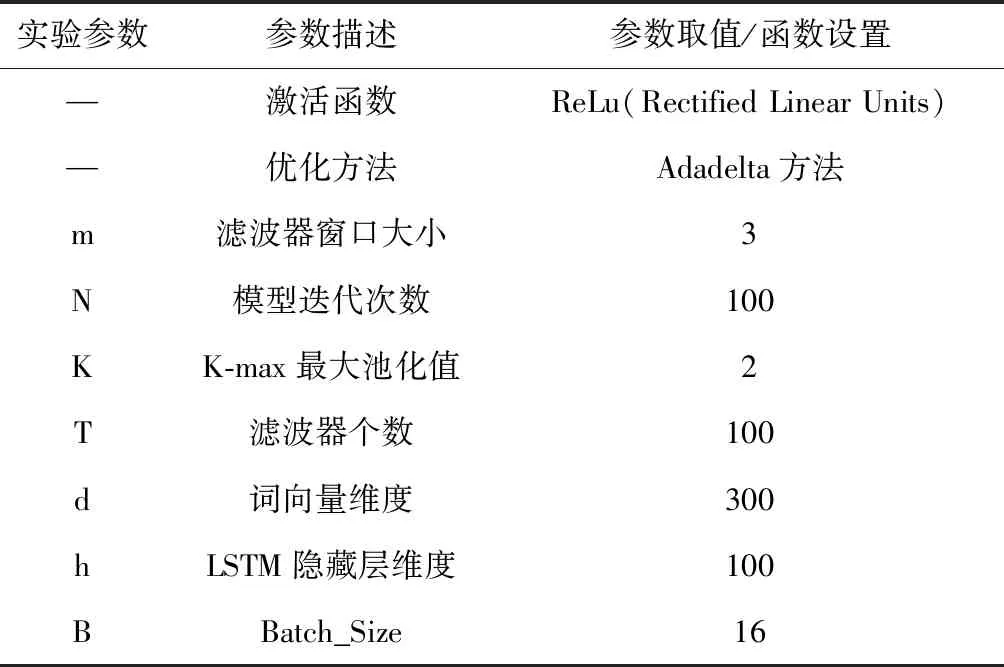
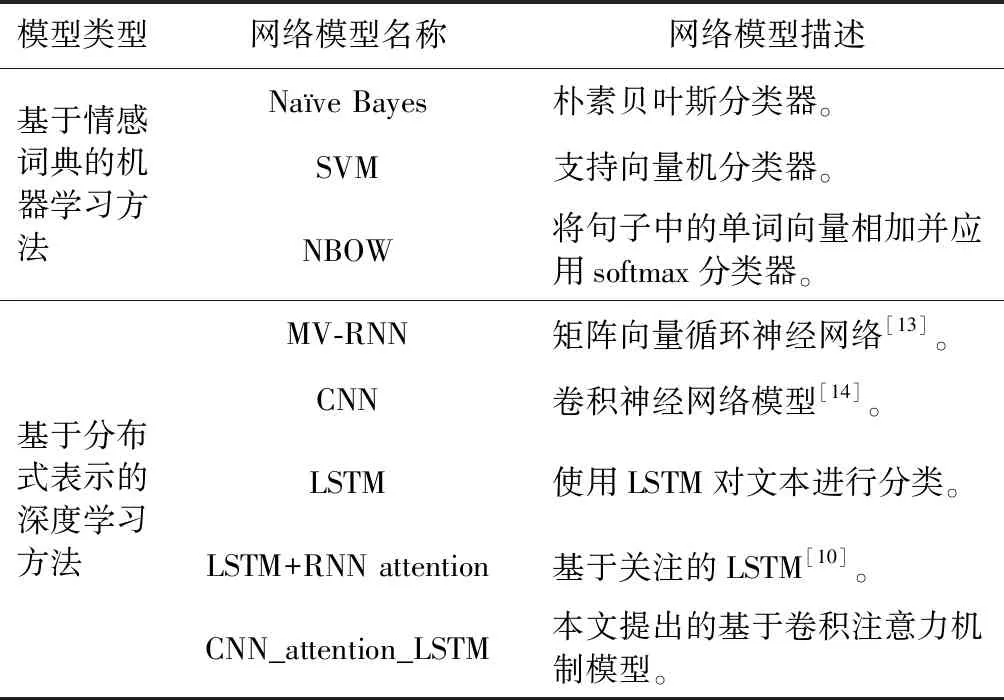
其中,xi∈K(i={1,2,…,n}) 对应文本序列中第i个词的k维向量表示,⊙表示向量的连接操作。x1∶n表示文本中的第1个词到第n个词的对应向量的首尾连接。w∈hK表示卷积滤波器,其高度为h(h ci=f(w·xi∶i+h-1+b) (2) 其中,b∈K为偏置项,f为非线性函数(像tanh,ReLu)。当输入{x1∶h,x2∶h+1,…,xn-h+1∶n} 一整个词序列时,将产生如下特征图 c=[c1,c2,…,cn-h+1] (3) 每个卷积滤波器的输出是来自原始文本的关注信号。为了减少注意信号中的噪声,本文选择多个卷积滤波器应用于原始文本的矢量表示,并对这些滤波器的结果进行平均以获得平滑的关注信号。 假设卷积滤波器的个数为m,这些滤波器由 [w1,w2,…,wm] 表示,相应的注意信号特征向量为 [c1,c2,…,cm]。 在经过平均滤波器的处理之后,将获得平滑的注意信号c∈T,其中每个元素表示对应词的重要性 (4) 整个卷积注意抽取模型,如图1所示。 图1 卷积注意抽取模型 长短记忆网络LSTM是基于循环神经网络(RNN)改进的模型,使用门控系统来实现长短记忆。LSTM模型的每个神经元引入了称为存储单元的新结构,存储单元由4个主要部分组成:输入门it,输出门ot,忘记门ft和记忆单元ct,它们都是d维度的向量。LSTM的计算公式如下 it=σ(Wixt+Uiht-1+Vict-1) (5) ft=σ(Wfxt+Ufht-1+Vfct-1) (6) ot=σ(Woxt+Uoht-1+Voct-1) (7) (8) (9) ht=ot⊙tanh(ct) (10) 其中,xt为第t时刻的输入,σ为sigmoid激活函数,⊙为元素对应相乘。 LSTM通过门控系统的方式,来削弱近距离相对不重要的信息,增强长距离中重要的情感倾向信息,从而实现捕捉文本长距离之间的语义关系。 通过卷积注意抽取模型之后,我们将得到文本的注意力信号,并将其附加到文本word-embedding的矩阵中实现注意力融合,再通过LSTM网络获取文本上下文语义信息。本模型包括词向量层、卷积注意神经网络层、注意力融合层、LSTM分类层、池化层、全连接层。网络整体结构如图2所示。 通过word2vec将文本中的输入序列转化成向量x1∶n=x1⊙x2⊙…⊙xn,其中n表示词序列的长度(必要时填充),每个词用h维的向量表示,则输入x为n*h维的矩阵。 我们使用CNN网络来捕捉句子中的注意力信号。假设输入文本序列为 [x1,x2,…,xn],其中xt∈d(t=1,2,…,n),m个长度为l的卷积滤波器表示为 [w1,w2,…,wm],对应的卷积结果为 [c1,c2,…,cm],其中ci∈t(t=1,2,…,m) 代表分布在长度为n的序列的注意力。我们对m个滤波器进行平均,得到稳定的关注信号c。之后我们将注意力信号c赋予到输入矩阵x上,得到带有注意力机制的文本矩阵表示c⊙x。 我们通过特定的卷积操作提取注意力之后,使用图2中的方式进行注意力融合,注意力融合公式如下 si=λ1·xi+λ2·xi·ci (11) 其中,i∈{1,2,…,n} 代表当前文本中的第几个词,λ1为原始词向量所占权重,λ2为注意力信号权重。通过上式将得到融合注意力信号之后的词向量表示序列s=[s1,s2,…,sn]。 图2 卷积注意力机制网络模型(CNN_attention_LSTM) 我们用LSTM网络来对此序列提取前后语义信息。此时,输入为 [s1,s2,…,sn],LSTM的隐藏层维度为k,那么我们将得到一个大小为n*k矩阵。再使用最大池化的方法获取文本的最强特征n*1的向量。 上面通过LSTM网络得到的结果,再使用线性函数来进行分类,最终得到文本情感极性结果 p=softmax(Wcs+bc) (12) 为了测试本文模型的性能,我们将本模型应用于4个数据集上进行实验,包括多细粒度的二分类和五分类数据集以及句子级别和文档级别的情感分析数据集。具体数据集介绍如下: (1)MR(move review):包含4个子集,本文选用基于句子级别的电影评论数据集进行实验,分类涉及积极和消极二元评论类别(下载链接:http://www.cs.cornell.edu/people/pabo/movie-review-data/); (2)SST-1:为MR的扩展,提供了数据集的详细划分,将数据集划分为训练集、验证集和测试集。此数据集为五分类问题,将标签划分为:非常消极、消极、中性、积极、非常积极(下载链接:http://ai.stanford.edu/sentiment/); (3)SST-2:与SST-1数据集类似,只是删除了更细粒度的标签,将标签分为积极和消极两类; (4)IMDB:文档级文本分类数据集,为积极和消极二分类电影评论数据集(下载链接:http://ai.stanford.edu/amaas/data/sentiment/)。 前3个数据集为句子级别分类,包括二分类和五分类任务,每个样本所包含词语长度为20个词左右。最后的IMDB数据集为文档级别分类,将整篇文档内容分为积极和消极两类。在实验中,对于没有标准列出训练集和测试集的数据集,本文使用10折交叉验证。表1列出了数据集摘要统计数据。 表1 4个数据集的摘要统计 该模型可以通过反向传播以端对端的方式进行训练,损失函数选用交叉熵损失函数,使用Adadelta优化方法提高训练速度。在实验中,word embedding使用Google公开的word2vec 300维向量进行初始化,这是谷歌在新闻数据集上使用1000亿个字训练而成的,囊括了各个领域的词语,也是目前常用的预训练词向量。在对词向量矩阵进行卷积操作时,由于矩阵的每一行代表一个词,所以每一行需要作为一个整体,单独拆开没有意义。因此,实验中卷积核高度为3,宽度等于word embedding的维度。模型其它参数见表2。 表2 实验参数设置 为了验证本文提出的基于卷积注意力机制和循环神经网络模型的有效性,我们将本文模型与一些基准的方法进行比较。进行实验的模型见表3。 实验结果见表4,我们使用7个模型与本文提出的模型来进行比较。包括传统的Naïve Bayes、SVM方法和一些深度学习模型。首先我们可以看到,深度学习方法明显好于传统的机器学习方法。其次我们注意到,在深度学习的几个模型中,基于循环神经网络的MV-RNN和LSTM的性能不如嵌入注意机制的模型,因为RNN模型提取的顺序特征不适合文本分类。但是从实验结果来看,本文提出的CNN_attention_LSTM模型可以结合CNN和RNN的优点来提高性能。结果显示,我们基于注意力机制的CNN_attention_LSTM模型,在4个数据集上取得3个最优精度,在五分类SST-1数据集上和LSTM+RNN attention模型持平。 表3 对照实验及描述 表4 实验结果对比 为了进一步分析和验证我们的模型能够捕捉到文本句子中的显著部分,我们在MR数据集抽取了3条评论数据做了注意力层的可视化显示,选取评论数据见表5。 表5 样例抽取 我们使用训练好的模型提取以上测试样本的注意力信号,使用热力图来直观展示评论数据中各个词语的注意力信号。在这些句子中,我们的模型正确预测了类别标签。如图3中的每一行都是我们模型提取的关注信号的热图。注意力信号已经标准化到[-1,1]区间,其中-1表示最消极,用黑色色块表示;+1表示最积极,用白色色块表示,使用黑色到白色线性渐变来表示-1到1之间的数值。 图3 注意力信息可视化 从图3中可以看出,本文提出的模型可以识别出带有强烈情感倾向的情感词语,像flawed(有瑕疵的)、fear(害怕)和insecurity(心神不定)等。此外还可以处理句子中的情感转换。例如,在第二句话中,我们的模型对句子前半部分给予了高度的积极关注,但模型也能发现这句话的后半部分与负面情绪高度相关。且负面情绪的相关性更高,因此使得最终预测标签为负值。 通过实验结果比较以及注意力信号可视化显示可知,本模型能够提取文本的局部最优情感极性,且能够捕捉到文本情感极性转移的语义信息,从而提高文本分类精度。 本文提出一种基于卷积操作的注意力模型,并融合循环神经网络(LSTM)进行情感极性分类。实验结果表明,本文的模型能够提取文本句子中的显著部分信息,从而提高文本情感分类性能。此外,我们的模型能够结合CNN和RNN的优点来提高文本分类性能。最后,我们使用热力图可视化显示了提取到文本注意力信息值,直观展示了本模型能够捕捉到文本中的否定和语义转化情感词,从而能够正确分类。 本文没有考虑带有表情符号的文本语料,怎么将本文的卷积注意力机制应用到表情符号的注意力提取上,是下一步工作的重点。本文接下来将针对文本中表情符号的问题进行进一步研究。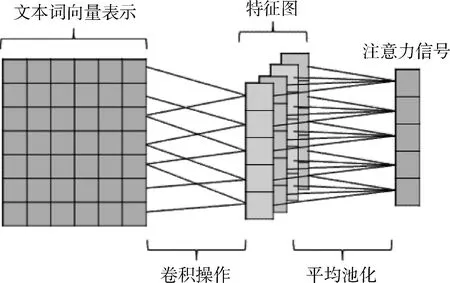
1.2 LSTM
2 模型结构
2.1 构建词向量输入层
2.2 卷积注意力层
2.3 注意力融合层
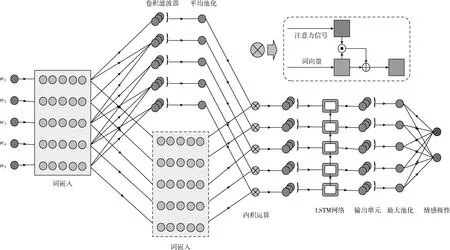
2.4 LSTM层
2.5 分 类
3 实验结果及分析
3.1 数据集
3.2 实验设置
3.3 对照实验
3.4 结果分析



4 结束语
