数字人文背景下基于需求的知识可视化方法研究*
——以国图公开课的视频内容可视化为例
2020-02-08周笑盈魏大威
周笑盈 魏大威
(国家图书馆 北京 100081)
1 引言
数字人文是将计算机技术深入应用于传统人文学科的跨领域融合产物,是将现代信息技术融入人文研究领域,改变知识获取、标注、比较的方式,通过分析、可视化等手段重塑知识,帮助人文研究学者与普通知识受众更好地了解知识之间的关联,把握人文知识的宏观发展规律和趋势。
数字人文要求在对知识进行有序整理的基础上,依据不同的知识需求,提供不同形式的知识服务。当用户需要了解某一客体时,需要对该事物特征进行可视化展现;当用户需要了解不同客体的联系时,需要对不同客体之间的关联关系进行可视化展现;当用户需要了解事物时空发展逻辑时,需要对演进路径进行可视化展现。知识可视化是以图形、图像、交互网页的形式对融合、聚类后的知识体系进行视觉表征,以满足用户个性化的知识需求。随着知识组织的不断深入,数字图书馆可以更大程度地实现知识资源的深度聚合,提升用户对于知识信息的理解性认知水平,提升知识资源的利用效率。知识可视化是未来数字图书馆满足用户深层知识需求、促进知识消费水平升级的必由之路。
2 相关研究
2.1 内涵界定
知识可视化源于科学计算可视化, 2004 年,M.J.埃普拉(Martin J. Eppler)和R.A.伯卡德(Remo A. Burkhard)首次提出了知识可视化(Knowledge Visualization)这一概念,指出知识可视化是指所有用来建构和传递复杂见解的图解手段。在国内,赵国庆认为知识可视化是研究如何应用视觉表征改进两个或两个以上的人之间复杂知识创造与传递的学科。此后,“科学可视化”“数据可视化”概念相继被提出。知识可视化的概念与信息图形、信息可视化、科学可视化以及数据图形密切相关,图是知识可视化的基础,视觉表征是知识可视化的目的所在,认知是知识可视化的突出特点。
结合在数字图书馆领域的具体应用,知识可视化是对数字图书馆资源聚合结果处理与利用的过程,综合利用聚合技术对资源进行聚类与融合,再对聚合后的数字资源进行基于视觉表征形式的知识解构、分析和利用,最终促进知识组织从“数据—信息—知识—智慧”的方向进行转化,以实现知识资源的再利用。借助于知识聚合和知识可视化,数字图书馆可以更好地推进资源有序化处理,实现基于用户个性化与精准化知识需求的资源开发与组织。
2.2 理论基础
1781 年德国哲学家康德提出了图式理论,认为思维可视化由四部分组成,分别为构建、推论、搜索、整合。1986年心理学家佩维奥提出人类认知的双重编码理论,认为人类认知基于两个独立且密切联系的认知子系统:言语系统和非言语系统,言语系统主要输入和输出言语对象,非言语系统用于表征和处理非言语对象,知识可视化辅助言语理解,通过图像表征系统提高知识传播效能,降低言语认知负荷。国内王朝云提出的经验之塔理论是知识可视化理论的基础,该理论将学习经验分为实践经验、观察经验和抽象经验三种,将知识可视化的过程抽象为认知金字塔模型,位于金字塔最底层的是最具体的实践经验,越往塔顶经验越抽象,学习者需具备丰富经验才可实现从具体经验向抽象经验的进阶。
20 世纪50 年代兴起的认知心理学被认为是语义网模型的基础,认知心理学将事件抽象为概念节点,用节点间的线条和箭头指向表示概念间的联系,节点之间按照上下层的组织关系构成网络系统,在语义网环境中通过概念节点的激活和扩散搭建概念网络并根据节点间联系的紧密程度分析概念间的语义距离,为网状知识图分析提供支撑。
国内外学者对知识可视化的框架方法进行了大量的研究,取得了重要的成果。M.J.埃普拉、R.A.伯卡德最早提出知识可视化框架,基于知识类型、可视化目的和视觉表征三个分类搭建知识可视化框架,主要回答了知识可视化的三个关键性问题:可视化的知识类型有哪些?(what)为什么要进行知识可视化?(why)如何进行知识可视化?(how)2005 年R.A.伯卡德对上述框架进行进一步的修订和完善,强调了知识的发送者与接受者之间的互动过程。M.J.埃普拉、R.A.伯卡德将知识可视化视觉表征概括为6种类型:①启发式草图( Heuristic Sketches ); ②概念图表( Conceptual Diagrams ); ③可视化隐喻( Visual Metaphors ); ④知识动画( Knowledge Animations ); ⑤知识地图( Knowledge Maps ); ⑥科学图表( Scientific Charts )。
国内学者李洁、毕强[1]基于社会网络可视化(Social Network Visualization,SNV)理论,结合社会网络分析方法、知识计量方法和知识图谱、知识网络理论提出了“DLRs-KA 一体两翼框架图”,以知识聚合为中心,社会网络可视化和知识计量作为两翼,构建数字图书馆资源知识聚合的可视化模型。周宁、张李义提出了信息资源可视化RDV 模型,RDV 模型由原始数据层析取数据的特征属性,搭建数据特征关系层,通过关系映射构建可视化对象层。赵慧臣[2]提出知识可视化视觉表征的分析框架,从图像视角、技术视角和知识视角探讨知识可视化视觉表征框架的设计和应用。图像视角重平面元素,轻视觉传播因素;技术视角重技术制作步骤,轻制作者创造过程;知识视角重视觉表征的功能,轻内容建构的方法。
总体而言,国内知识可视化研究侧重于对单一客体的特征性表达,对不同客体之间的关系与时空演进知识的可视化研究较少,未形成基于不同需求类型的完整的可视化方法模型。本研究希望在总结现有数字人文可视化成果的基础上,归纳出基于需求的知识可视化框架。
3 知识可视化的表达框架
数字资源具有多面性,对资源的解读是多侧面的,因此可视化的解读维度也应是立体的和全方位的。本文基于需求,从特征描述、关系描述、演进描述三个需求类型,对知识可视化方法进行归纳,进而建立基于不同需求的知识可视化模型。
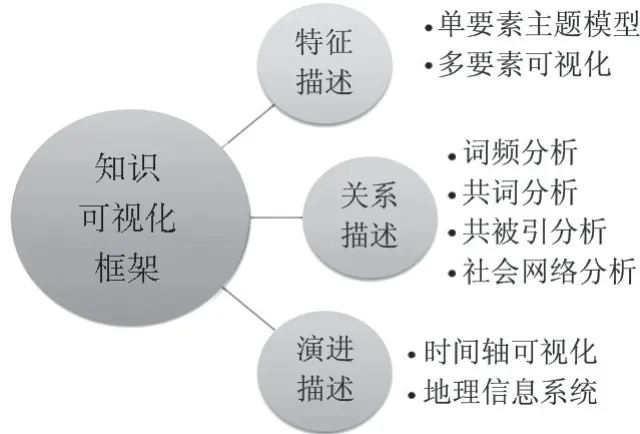
图1 知识可视化视觉表征的分析视角
3.1 特征描述的知识可视化
特征描述需求重点在描述知识本身,以知识单元作为可视化的基础,通过矩阵排列、节点连线等形式展示知识单元的特征属性、分布规律和结构关系,参照可视化技术的分类,可将特征描述可视化依据要素维度分为单要素可视化和多要素可视化。
(1)单要素主题模型
人文科学研究的主要材料是文本资源,属非结构化数据,对非结构化数据的大规模量化分析需要借助计算机的自然语言处理技术,常见的自然语言可视化方法为单要素主题模型。单要素主题模型主要针对资源的单个数值要素属性进行分析,例如定义多维空间,利用空间节点作为要素属性节点,在不同节点间建立从属关系或关联关系,主题层与资源实体(即数字资源,例如文本、视频、网页)通过统一资源定位符完成资源指引。图2 显示了国家图书馆讲座关联数据平台主题词词云。国家图书馆讲座关联数据平台针对公开课资源进行基于元数据的关联数据加工,参考中文名称规范数据库,利用资源描述框架(RDF)对元数据的题名、课程简介、学科分类、主题词、课程评价、相关推荐、主讲人等元数据进行标引和语义化描述,形成关联数据集,将课程信息、主讲人信息及课程所涉及知识点以散射图的形式对课程信息进行补充,变层级导航为网状导航。图2 对讲座视频元数据信息表中的主题词进行提取后,生成主题词词云图,方便读者发现课程数据中所隐含的知识及知识的发展趋势。

图2 国家图书馆讲座主题词词云
(2)多要素可视化
多要素可视化是针对三个或三个以上的要素进行可视化展示的方式,既可以展示大数据集的整体趋势,又可以显示小数据的详细特征,如双曲线树、概念图、思维导图、认知地图等。
概念图是应用较为广泛的可视化方法,它用节点表示概念,通过连线方式将不同的概念进行连接,不同节点之间一般为层级结构和交叉连接关系,一般用来表示某一主题的层级结构和相关文献、背景知识的关系,主要用于对抽象概念的理解和层级关系分析。如图3 表示各概念的层级结构,各层级分别为:主要概念、一般概念、概念、具体概念与实例,通过方框表示概念节点,通过连线揭示不同概念之间的层级关系。

图3 概念图
3.2 关系描述的知识可视化
2012 年,Google 率先提出知识图谱(Knowledge Graph)的概念,本意在提升搜索引擎的智能化水平,而这个概念,在 2013 年后开始被学术界和业界广泛使用。知识图谱本质上是一种语义网络知识库,具有有向图结构,以结点表示实体或者概念,以边表示实体或者概念之间的语义关系,在搜索引擎、智能系统、数据可视化等应用中发挥重要作用。
关系维度的共现知识图谱是对数据的量化分析,关系维度的共现知识图谱的视觉表征形式具体包括词频分析法、共词分析法、共被引分析、社会网络分析等,以知识图谱方式形象直观地表达各领域学科的研究热点与研究趋势。
(1)词频分析
词频法是传统的计量分析方法,因其简单易行、便于应用,又被称作省力法则。其理论基础是齐普夫定律,通过分析相关文献中关键词或者主题词的出现次数,反映文献的研究内容和研究方向。
(2)共词分析法
共词分析法顾名思义,是统计一组词汇共同出现的次数,并以共同出现的次数为基础,来判定该组词汇中不同词语的亲疏关系,出现在同一篇文章中的次数越多,两个词语之间的关系就越密切。通过共词分析的方法来分析关键词,可以很好地展现出关键词之间的密切程度。
共词分析法以关键词为节点,可以通过连线的方式来建立共词网络。在共词网络中,离得远的关键词,共同出现的次数低,以此可以表示出该研究领域研究主题的关联性以及研究主题的演进逻辑。在计量学领域,共词分析主要用于识别某一专业研究领域的主题和热点。
(3)共被引分析
共被引分析与共词分析类似,统计两篇文章中作者、机构或引文被共同引用的次数,并以共被引网络对共被引关系进行表示,共被引网络中两篇文章距离越近,说明两篇文章描绘的主体更接近,关系更为密切。共被引分析体现了学科交叉、渗透的特征,利用数学及统计学的归纳、概括等逻辑方法,揭示作者、机构或引文计量分析的内在规律。
常用的共被引分析主要包括三类主体:文献共被引、作者共被引、期刊共被引。文献共被引主要研究学科前沿,挖掘学科结构;作者共被引主要揭示学者研究兴趣的变化;期刊共被引主要对期刊进行定位和分类,确定期刊在学科中的核心或边缘地位。
共被引分析的具体形式包括:引文耦合、引文共被引、作者耦合、作者共被引、期刊耦合和期刊共被引等。随着矩阵分析、网络可视化技术的发展,引文分析的结果可以用更直观的方式展示出来,这一方法得到图情学、统计学等各领域的广泛认可。
(4)社会网络分析
社会网络关系是通过特定的模型,利用特定的关联关系,将人与人之间建立联系,以此建立人与人之间相互影响的关联模型。基于此,可以分析某一时间对社会全体的联动影响。
图4 显示了国图公开课主题词分类的共现关系。图4是国家图书馆讲座关联数据平台主题词分类关系,基于语义网同主题的语义聚类属性,对讲座视频元数据信息表中的主题词按照学科门类进行共现分析,方便读者更准确地了解课程数据整体框架,并从语义层面为深入搜索提供支持。

图4 国家图书馆讲座视频数据库主题词分类关系图
关系维度的知识可视化主要流程包括:知识单元抽取、知识单元整合、知识可视化。知识单元抽取是数据量化分析的第一步,是共现知识图谱构建的基本元素。知识单元的内容包括作者、关键词、机构等著录内容,或基于文本提取的术语词源。知识单元整合环节对知识单元间的属性进行抽取,利用聚类技术、多维尺度分析等方法对知识单元间的关系和潜在规律进行挖掘,引入算法分析知识单元的关系和发展脉络,常用的算法包括布局算法和统计算法。布局算法通过对不同知识单元的距离大小和关系连线强弱进行分析,得到不同节点间的共现强度,统计算法对不同知识单元进行关系聚类,以展示整体的发展脉络和演化过程。知识可视化基于抽取的特征属性,将数据属性(例如知识单元的连线、共现频次等)映射到图谱属性上,最终将知识单元间关系的分析结果以图的形式表现出来。
3.3 演进描述的知识可视化
数字人文研究将人文叙事与地理空间技术相结合,采用定性分析与定量分析相结合的手段,将多样的事件纳入到时空参考框架中进行可视化和分析,为拓展地理空间技术在人文社会学科中的应用奠定了基础。
时空维度的叙事可视化主要针对文本格式的数据,简单的叙事描述包括when、where、what(何时、何地、何事),复杂的叙事描述包括5W1H:when、where、what、who、why、how(何时、何地、何事、何人、何因、如何)。时空维度的叙事可视化凸显了知识可视化的时空性和动态性视觉表征特点,特别是对于长时间跨度的历史事件,随着时间的发展,事件的空间状态和其他要素属性的变化可以通过时空维度的可视化进行动态展现。
时空层面的叙事可视化主要涉及时间维度和空间维度两个层面,涉及的要素主要包括四类:时间信息要素、空间信息要素、人物关系要素和主题关键词要素,不仅要能够将人物关系、事件主题特征等多维属性纳入时空框架之中,同时涉及文本挖掘、文本要素的地理空间映射以及可视化认知与表达等研究领域。可视化流程包括四步:第一步通过文本挖掘技术与人工辅助识别相结合的方法,识别地名、时间、人物、关键词等事件信息;第二步构建事件要素的存储模型,对事件进行不同层次的划分;第三步通过地名共现、人物共现等方法进行数据关系分析;第四步在时空框架中对事件进行还原与展示。
(1)时间轴可视化
时间轴的可视化有生命线可视化展示、二维时空路径和流向地图三种可视化效果。生命线可视化是时间的多维拓展,在病人就医记录、犯人犯罪记录、历史记录以及各种传记数据可视化中被广泛应用。二维时空路径是一种带有地理坐标信息的生命线,将资源内容按照时间轴的顺序映射到二维地图上。
(2)地理信息系统(GIS)
地理信息系统(GIS)的应用形式多样,最常见的是通过Web 模式提供位置服务的谷歌地图、百度地图、高德地图等。GIS 在数字人文领域的应用是指通过添加元数据的时间信息和空间信息,以显示不同时期、不同地点变化的特点。GIS 的应用一般包括三个功能:后端位置存储功能、前端数据图层插件和平台API 插件。GIS 的应用场景一般选用典型的B/S 架构,如基于高德地图的Web 模式GIS 技术,通过云平台提供位置服务,云平台配备位置存储服务,通过地理位置的名称识别自动匹配经纬度坐标,通过云数据图层插件将数据信息叠加到地图上,通过平台API 插件提供数据检索、区域面积计算等功能。使用者只需配备相关数据,通过平台的配置和客户端编码,即可实现数据的可视化研究,同时可根据地域面积与数据内容的匹配度进行伸缩的精细化展示。
4 以“国图公开课”为例探索基于需求的知识可视化
本文以“国图公开课”视频资源的内容挖掘和可视化为例,对不同的需求类型采用不同的可视化方式进行知识可视化展现。笔者利用文本挖掘软件对国图公开课与丝绸之路相关的视频文本进行了提取,得到人物、时间、地点、事件信息,基于特征描述、关系描述、演进描述三种需求对公开课视频内容进行了聚类分析、多维尺度分析和社会网络分析,构建关键词词云、实体共现矩阵、地理标签云图和时间轴标签云图。
4.1 样本内容挖掘
国图公开课是国家图书馆借鉴“慕课”的在线课程理念设立的专题在线学习课程,目前发布在线课程1 600 余场。本文选取“丝绸之路”这一主题采集视频样品,丝绸之路是古代中华民族对世界文明的巨大贡献,在“一带一路”的背景下,丝绸之路又焕发了新的生机,对这一主题进行研究具有重要的历史意义与现实意义。
笔者在国图公开课视频平台中搜索“丝绸之路”,得到与“丝绸之路”相关的公开课视频4个,时长超过1 000分钟,公开课视频资源相关信息如表1 所示;针对4 个公开课视频提取字幕文件,对文本文件进行切分、识别,根据算法找到最优分词路径,利用智能分词软件和词性标注模块完成所有字幕内容的分词与词性标注。
4.2 实体抽取
实体抽取是基于角色标注算法自动识别命名实体,通过对语言规律的理解和科学预测,智能识别文本中出现的人名、地名、时间、事件及文章的主题关键词。笔者通过对国图公开课视频内容中事件类、地点类、人物类、时间类关键词的提取与整理,设置自定义词表,重新分词得到分类关键词有效词表。表2 列出了各分类中排名前30 位的关键词,由此可以大致了解丝绸之路公开课视频的核心内容。

表1 国图公开课样本视频信息
4.3 特征描述可视化
我们在进行文本分词时利用分词与词性识别软件判断每个词语的词性,即名词、动词、形容词等,筛选出所有的名词和动词,并就单一要素设计可视化视图,图5 为对地名要素进行词频统计后的可视化图。
利用文本挖掘软件对人名、地名、时间点、事件四类要素的所有关键词进行词频分析,生成词云图。从图6 中可以清晰看出,“唐朝”“西域”“日本”“敦煌”“中亚”“丝织”“传教士”“收藏”“文化遗产”等关键词处于图谱的中心位置,这些关键词是丝绸之路公开课文本的核心内容。

表2 国图公开课视频内容实体词频统计

图5 国图公开课地名高频词可视化
而在网络边缘的“遣唐使”“大运河”“回鹘”“高丽香料”等关键词虽然游离于核心词之外,却对丝绸之路的注解更为具体,代表了丝绸之路内容中的具体领域和发展趋势,同样具有重要的价值。

图6 丝绸之路国图公开课视频内容关键词云图
4.4 关系描述可视化
在特征描述可视化的基础上,本文尝试对大规模视频内容中的地名、人物和事件进行共现分析,旨在对事件中潜在的空间模式、人物关系和事件关系进行探究。共现分析有两个前提,即重要的关键词会在视频内容中反复出现,同时关系越紧密的主题词在相同段落中同时出现的概率也越大。其具体的实现方法为,首先通过文本挖掘识别出公开课视频资源中所有出现的地名、人物和事件,进而统计每两个主题词在200 字以内共同出现的次数,生成地名共现矩阵。人物共现关系图和事件共现矩阵,在共现网络中,一个地名、人名和事件名称对应网络中的一个节点,任意两个共同出现节点之间会生成一条边,边的权重即为二者之间的共现频次。在共现模型的基础上,利用网络可视化技术,生成共现网络。图7 便是根据前文中识别的地名,生成的地名共现矩阵。

图7 地名共现矩阵
从关键词网络分析结果中,可以看出地名之间的结构关系。在地名共现网络中,“中国”这一节点位于网络中核心的位置,对其他关键词共现的影响力最大。与“中国”这一节点关联度最高的分别是“欧洲”“日本”“印度”,可见丝绸之路的主要地理趋向为向西的印度—欧洲、向东的日本,丝绸之路成为了古代东西方经济文化交流的主要通道和沟通中国与欧亚大陆的重要通路。
从图8 的事件共现矩阵中可以看出,公开课主讲人在讲座内容中的核心节点为“丝绸之路”,与这一节点关联度最高的有两类主题:文化遗产与文化交流。与文化遗产相关的事件分别为“申遗”“考古”,与文化遗产类主题网络离散程度稍低的事件包括“马王堆”“四大发明”“收藏”;与文化交流相关的事件分别为“文化交流”“交流”,与文化交流类主题网络离散程度稍低的事件包括“联合国教科文组织”“二战”“印刷术”等。可以看出,丝绸之路不仅是中外贸易的交流通路,还是世界文化交融的载体。在古丝绸之路上,各国家各民族交易的内容十分丰富,有茶叶、玉器、香料等,丝绸只是其中一种。在“一带一路”的背景下,丝绸之路作为中西文化交流的平台又焕发了新的生机。

图8 事件共现可视化
图9 是基于事件、人名、地名和时间所生成的多要素共现矩阵。从该共现矩阵中可以看出,主讲人在丝绸之路的讲解中,以“中国”为核心,与核心节点关联度最高的多为地点类节点(例如“日本”“印度”“波斯”“新疆”“敦煌”),其次为时间类节点(例如“唐代”“汉代”“西夏”),最边缘的关联节点多为事件类和人名类。由此看出,主讲人对于丝绸之路的研究以地域为主要脉络,时间线为辅助脉络。关系描述的知识可视化更能反映出知识之间的关联和依赖关系,可以挖掘出内容中所包含隐性知识之间的联系。

图9 事件、人名、地名、时间共现矩阵
4.5 演进描述可视化
演进描述可视化的应用范围广泛,历史事件、新闻、课程资料等都可被纳入演进描述的框架中进行表达。公开课的课程内容由多个事件组成的,内容跨度长,叙事文本多来自于人文作品,属于自由文体,具有高度的灵活性。笔者在前文的信息规范化处理的基础上,将课程文本中的时间信息、地名信息、人物信息、事件关系等纳入时空框架统一进行管理,以地理标签云与时间轴标签云的方式进行可视化表达。
地理标签云是地理信息可视化的组成部分,常规地图标注往往注重地理要素的单一属性,而地理标签云结合了地图可视化与文本可视化技术。动态的地理标签云还能从数据库中实时抽取数据,根据不同比例尺实现动态信息显示。本文选取了中国地图和世界地图作为空间信息数据源,在中国地图中根据主题词权重确定主要省份标签,以主要省份为单位,计算其他结构化信息与地理信息的共现关系,按照主题词权重顺序依次显示在对应的省份上;在世界地图中根据国家主题词权重确定主要国家标签,根据共现关联生成主要国家地理标签云。从图10 中可以看出,国内与丝绸之路相关的省份主要为中西部的甘肃、宁夏、青海、陕西、四川、新疆和东部的浙江、江苏。东部省份的主题词多与丝织工艺有关,西部省份的主题词多与运输通路有关,自东向西主要涉及的地域包括嘉兴、杭州、海宁—河西走廊、麦积山、兰州—敦煌、阿尔泰山等。从图11 中可以看出丝绸之路在世界各国的大体通路,向东与日本的交流主要为文化交流,“唐朝”“遣唐使”成为权重较高的主题词;向西与印度的交流则以“佛教”的交流为主,与欧洲各国的交流主要涉及贸易领域,“丝绸”不仅仅是核心主题词,“白银”“香料”“玉器”等主题词的出现频率也较高。
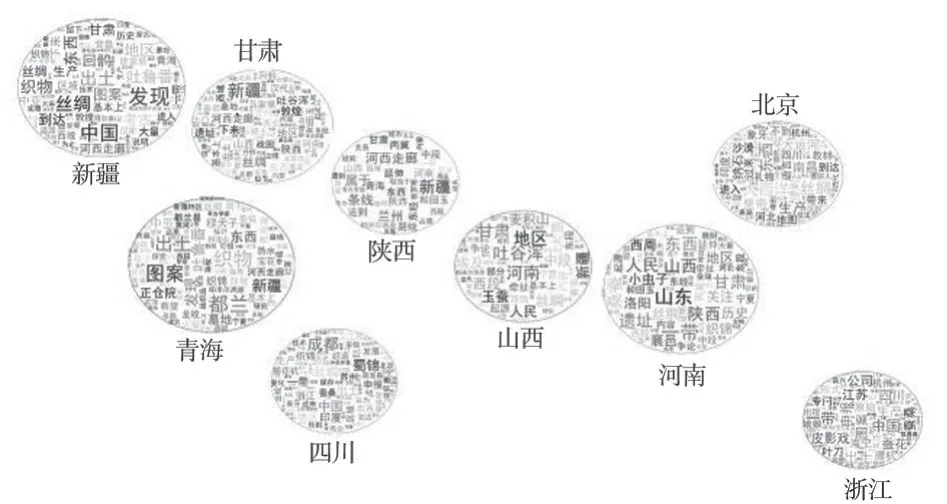
图10 中国主要省份地理标签云可视化

图11 世界主要国家地理标签云
图12 从时间维度对公开课视频内容特征进行描述,从时间轴可视化可以看出,丝绸之路的最早时间可以追溯至战国时期,主讲人认为在汉代以前,就已经存在这条沟通中国与中亚的西域交通道路,例如殷墟墓葬、马家塬战国墓葬中的玉器和琉璃制品,这说明西域的产品在很早的时候就已经进入中原;秦汉时期,与地域相关的主题词主要有“都护府”“河西走廊”“敦煌”,说明主讲人主要讲述了丝绸之路的开辟,“马王堆”作为另一高频词强调了长沙马王堆汉墓素纱衣的价值和秦汉时期丝织业空前发展;到隋唐时,出现的高频主题词为“图案”“宝花”“纹样”“日本”,标志着唐代提花技术的重要变革,其纹样形式多以“宝花”形式存在,且广泛传播到日本等地区;蒙元时期疆域的扩展和民族大迁徙的发展,为中西陆路贸易奠定了重要基础;到明清之际,东西方的丝绸交流进入传教士时代,天鹅绒、西洋锦、中国风都成为了丝绸之路的特色代表。

图12 时间轴标签云
数字人文环境下,数字图书馆用户对知识的需求往往清晰且精准,本文希望在梳理用户认知需求的基础上,根据不同需求完成馆藏资源的挖掘和可视化。
①特征描述维度的可视化。在文本挖掘与特征分析的基础上进行词频分析,常用的可视化形式包括:主题云图、思维导图、认知地图等。例如通过对国图公开课视频原始字幕文本中的特征信息进行分析,概览性地勾画出四位主讲人讲述内容的语言特征信息和主题词,帮助读者最快了解课程整体内容架构。②关系描述维度的可视化。从数据的多重关系角度揭示共现关系,常用的方法包括:共词分析、共被引分析、社会网络关系分析等。本文通过搭建4场国图公开课视频资源的地名共现矩阵、事件共现矩阵和事件、人名、地名、时间多要素共现矩阵,揭示了丝绸之路研究的地域范围、主要事件和主讲人研究脉络,不仅使分析结果直观形象,同时让研究更具个性化特质和信息美学特征。③演进描述维度的可视化。从空间和时间角度揭示资源中暗藏的地理线和时间线,帮助读者从更加宏观的角度把握视频内容。在国图公开课的演进可视化结果中,我们不仅可以了解到丝绸之路在世界各国的通路与主题,还可以分析不同朝代丝绸之路的特征。可视化技术让庞杂的非结构化数据更加形象、有条理,为相关的数据决策提供了有力支持,也为场景模拟、历史仿真等人工智能技术的应用打下了基础。
5 结语
馆藏资源是数字人文可视化的重要基础,图书馆等公共文化服务机构存在大量数据资源,既包括书目数据、知识组织等结构化的资源,又集合了大量的音视频、网络信息、全文数据等非结构化的数据资源。数字人文背景下,非结构化数据的挖掘与可视化可以更精准地满足用户的认知需求,通过对异构数据的深度挖掘与分析,将分析结果以多样化的形式呈现给用户,帮助用户以全新的视角获取知识与灵感。
本文基于图书馆实践,按照受众知识需求类型对知识可视化方法进行归纳分类,形成基于不同需求类型的可视化方法模型,通过对不同来源的非结构化数据内容进行挖掘,可以从不同侧面对内容进行描述与结构化分析。本文以国家图书馆“国图公开课”视频资源的内容挖掘与可视化为例,从大规模的视频资料中对时间、地点、人物、事件和关键词进行了提取和规范化,对公开课课程这一数字资源,基于不同需求类型形成不同的可视化展现解决方案,希望为提升图书馆数字资源传播效率与知识服务能力作出贡献。
(来稿时间:2019 年9 月)
