稀疏度过滤和密度聚类的商圈核心区域范围划分方法
2020-02-05睢文蓉
睢文蓉
(美味不用等(上海)信息科技股份有限公司 上海市 201203)
1 概述
随着交通出行方式多样化、居民消费水平不断提高以及旅游业不断发展的影响下,中国城市商圈概念得到快速发展。在这样的大背景下,对商圈核心范围划定并做空间维度统计分析,可以帮助商业管理者和业主们制定经营策略方向和区域商业布局,甚至还可以帮助城市做整体区域规划和城市交通规划等,在商业布局及城市规划上都具有重要意义。如何对商圈核心范围进行精准的划定,本文提出了一种新方法:稀疏度过滤和密度聚类(Sparsity-Filter and Density-Cluster),简称SFDC。此方法通过结合GeoHash 编码算法和DBSCAN 聚类算法,利用它们的特点来计算经纬度样本分布稀疏度,实现边缘样本过滤和噪点过滤,同时完成高密度核心区域的划定。实际数据证明,通过SFDC 的方法,可以有效过滤边缘样本和噪点,并将边界误差控制在±0.076km 范围内。
2 GeoHash编码和DBSCAN密度聚类算法
2.1 GeoHash算法
GeoHash 编码是一种对空间编码的算法,也就是创建空间索引的算法,以B 树实现。在墨卡托投影平面上进行划块,划成N 个矩形区域,每个矩形区域都被赋予一个字符串编码,所有落在同一个矩形区域内的经纬度样本将被赋予相同的编码。
对一个经纬度样本进行GeoHash 编码的过程就是对经度和纬度进行多次二分法逼近,落在左区间为0,右区间为1。然后将获得的两个二进制字符串进行合并,偶数位放经度,奇数位放纬度。GeoHash 采用base32 编码方式,即每一个字母或数字由5bits 组成(2^5=32),通过将经纬度二分法合并获得的二进制值进行进制转换和编码字符对应转换后形成新的字符串,这个新字符串即GeoHash 编码。通常使用0-9 和a-z[^ailo]来进行对应。
因为base32 基于5bits,需要经度和纬度进行二分法的次数之和是5 的倍数、经度次数≥纬度次数且次数值最相近,以达到划块趋近正方形的效果。以编码位数为1 位来举例,需要5 个bits,即00000~11111,可获得32 种不同的二进制值。对纬度进行2 次二分逼近,经度进行3 次二分逼近,获得对应二进制字符串。
按照偶数位经度奇数位纬度合并后,得到5 位bits 的二进制编码表,如表1 所示。
最后通过进制转换成十进制,再根据编码字符对应转换生成最终的编码。通过上面的过程,就获得了把整个地图用1 位GeoHash编码切分为32 个矩形的效果。这个算法过程其实是遵循Z 阶空间填充曲线的算法,是z-orader 的一种应用,在进行最近邻查询等场景应用中非常方便。
当编码长度取1 位时,就相当于把整个地图切割成32 个矩形区域,再增加一位就相当于在这32 个矩形区域各自再次划分,以此类推,编码位数越多,划块越多,也就是地理上精度越高。
2.2 DBSCAN算法
DBSCAN 是一种基于密度的聚类算法,有两个参数,分别是密度圈半径(epsilon)和圈内点个数(minPts),结合这两个参数可以把所有样本点分为三种,即核心点、边缘点和离群点。按照以下步骤进行数据的处理:
(1)将样本坐标点(X,Y) 作为样本数据集,给定参数(epsilon,MinPts)后,将所有样本坐标点(X,Y)标记为“unvisited”。
(2)随机选择一个样本坐标点作为起始点,将它标记为“visited”,以它为圆心画个圈,如果这个圈覆盖到其它样本坐标点的数量n MinPts,则把此样本点记为核心点,而被圈中的n 个样本坐标点与合并归入为一个类,同时把其中标记是“unvisited”的点改为“visited”。之后对这n 个样本坐标点做与相同的操作:画圈、覆盖其它点、归入类,如此循环。如果循环中某个样本坐标点的圈内样本数量n MinPts,则将此样本坐标点记为边缘点,并且它圈内的点不再参与循环。当类没有新的点可以参与循环后,则循环结束, 聚类完成。
(3)然后从其它标记仍然是“unvisited”样本坐标点中随机选择一个点作为下一个起始点,开始和上面相同的操作直至第二个类聚类完成。如此往复直至所有样本坐标点都被访问过为止。如果某个起始点的圈内样本数量n MinPts,则此起始点记为离散点,不做其它操作,直接开始随机选择下一个起始点。
按照上述算法步骤,当样本数据集中所有“unvisited”的样本遍历完成后,所有样本被聚类到一个或几个类(Ln)中,同时依照设置的参数,把一些离散的噪点检测出来并过滤掉。
3 商圈核心区域划定方法——稀疏度过滤和密度聚类(SFDC)
3.1 商圈店铺分布特点
商圈内店铺的密度分布,一般有几个特点:
(1)商圈与商圈之间店铺分布有稀疏紧密之分,但一个商圈内店铺是比较集中的。
(2)商圈内店铺分布一般是核心密集边缘稀疏。

表2:GeoHash 经度对照表
图1
3.2 SFDC划定商圈核心区域过程模块
用稀疏度过滤和密度聚类(SFDC)划分商圈核心区域的过程分几个模块:
(1)样本准备:需要采集商圈店铺地理位置信息,并将商圈店铺地理位置样本转换成经纬度,将此数据作为初始数据样本。我们利用地图开放平台和本地生活平台的开放API 来获取数据,并规整为我们需要的经纬度样本数据。
(2)GeoHash 编码:对经纬度样本进行GeoHash 编码,将POI 经纬度转换为编码样本。
(3)稀疏度过滤:对编码样本计算稀疏度,做大范围边缘样本过滤,剔除那些离商圈核心过于遥远的样本。
(4)DBSCAN 聚类:对编码样本坐标点做聚类,过滤离散样本即噪点,标记核心点和边缘点,形成可信的样本聚类作为商圈范围度量。
(5)可视化:对边缘点的凸点绕数实现可视化展示。
3.3 GeoHash编码和稀疏度过滤
假定商圈A 获得了大量的店铺经纬度样本后,下一步要获取商圈稀疏度指标用以过滤非常边缘的样本,也即是计算商圈的稀疏度。经纬度样本落在地图上,有疏有密,一般都遵循核心密集边缘稀疏的规律,利用单位面积内的经纬度样本数量来确定稀疏度。
把地球展开成一个二维坐标平面,即墨卡托投影,那么经线为范围为[-180,180]区间的x 轴,纬线为范围为[-90,90]的y 轴。
商圈A 的店铺经纬度样本将在墨卡托投影上进行GeoHash 编码。
根据经验和计算,GeoHash 编码位数对应的精度如表2 所示。
零售店铺面积大小在边长为0.076km 区域范围内是比较合理的,因此我们把先前获取的商圈A 的店铺经纬度样本进行7 位长度的GeoHash 编码 (Geo7)。
3.4 计算稀疏度过滤边缘样本
将商圈A 的店铺经纬度样本进行7 位GeoHash 编码后,我们按编码分组计算每个编码样本的经纬度样本数(N),N=0 排除,获得商圈A 的一组编码样本(Geo7,N),样本个数为C。设定阀值为n,我们将商圈A 的编码样本(Geo7,N)中N ≥n 的样本计数(CN≥n),然后将其占所有样本数的比值作为稀疏度(S)。

将(Geo7,N)的矩形区域中心坐标经纬度作为该编码样本的坐标点(Lati, Lngi),通过对商圈A 所有(Lati, Lngi)做平均经纬度计算得到编码样本的中心点(Latc, Lngc)。

将(Lati, Lngi)与中心点(Latc, Lngc)做距离计算获得每个编码样本坐标点之间的距离(Ri)。
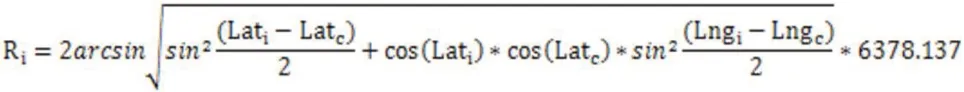
将所有编码样本距离(Ri)中的最远距离记为R,R 与稀疏度S的乘积作为过滤编码样本的依据,也就是说每个编码样本的坐标点(Lati, Lngi)与中心坐标点(Latc, Lngc)之间的距离超过R×S,则将之过滤,留下的编码样本即为商圈A 的核心区域。

这个过程中,设定一个合适的n 值是最为关键的,它跟每个商圈的样本的数据量、数据质量都有很大关系,需要进行大量的实验调整才能达到预期。本文统一使用了n=20。当然,根据不同的商圈,n 可以适当调整为差异化的值。
经过以上步骤,商圈的大致范围以及需要精细过滤和边界查找的编码样本就得到了。
3.5 DBSCAN精细过滤噪点,查找边界
在上一步过程后,商圈的大致范围已经勾勒出来,下一步我们通过DBSCAN 算法对编码样本坐标点进行处理,精细过滤噪点,以及进行边界查找。
本文选择过滤后的GeoHash 编码样本坐标点作为DBSCAN 算法样本,而不选择过滤后的经纬度样本,有两个原因:
(1)在地理位置范围上,现实中划分商圈核心区域边界误差在±0.07 内是完全可以接受的。
(2)经纬度样本的密度分布不均匀,这对于使用给定值参数(epsilon, MinPts)的DBSCAN 算法来说,处理多密度的效果和效率不理想。而编码样本坐标点是密度均匀的, DBSCAN 效率会非常高且效果好,这易于我们实验和调整参数。
我们将商圈A 所有编码样本坐标点(Lati, Lngi)进行DBSCAN算法处理,一些离散异常样本可以被找到并被过滤掉,同时聚类获得的核心点和边缘点也基本可以把商圈A 的边界查找出来。而要想获得较为符合常识和预期的商圈边界结果,算法的参数(epsilon, MinPts)值的选择就非常关键,这需要进行大量的联合调参工作,经过多次迭代计算对比,选择最合适的参数值。
3.6 基于绕数的方法描边图形展示
我们对经过过滤的编码样本坐标点边缘点进行绕数的方法来进行图形描边。原理是:
(1)每个边缘点作为凸点样本,找到Y 最大的样本中X 最小的那个点作为起始点,记做点A,将此点作为原点做水平切线,顺时针旋转,当线碰到的第一个点记做点B,联线AB。
(2)以点B 为原点做切线,切线方向为C,同样做顺时针旋转,当线碰到的第一个点记为点C,联线BC。
(3)C 与B 做相同操作,以B 为切线方向,以此类推,直到找到起始点A。
把商圈编码样本进行上述操作后,就可以获得直观的商圈范围划定。
4 结论
本文通过结合GeoHash 编码算法和DBSCAN 聚类算法,提出一种新的方法:稀疏度过滤和密度聚类(SFDC),在划分商圈核心区域范围中得到应用。利用商圈内店铺经纬度样本,通过GeoHash编码将经纬度样本转变为一种密度划块的形式,从而计算出商圈的稀疏度,通过稀疏度进行大范围的边缘数据过滤。然后对编码样本坐标点通过DBSCAN 算法处理,精细过滤离散点数据,获得核心点和边缘点,实现边界查找。通过这种方法,我们可以有效划分出商圈核心区域的范围,且边界误差保持在±0.076km 范围内。整个过程中,稀疏度的样本数阀值n 和DBSCAN 的(epsilon,MinPts)参数的选择对结果的准确性影响非常大,需要对数据进行大量实验不断的调整后才能得到较为理想的参数值,同时整个计算过程也较为依赖样本数据的量和数据质量的情况。
