基于深度学习的移动物体检测
2020-02-03曾贤灏
曾贤灏
(兰州工业学院计算机与人工智能学院 甘肃省兰州市 730050)
移动物体检测作为目标检测的一个重要分支,就实用价值而言,它广泛的应用于、视频监控、智能车辆等领域;就研究价值而言,目标检测不管是在角度、姿态、灯光、部分遮挡等方面都会引起很大的变化,随着计算机及人工智能领域对视频移动目标检测需求的不断提升,传统的经典目标检测方法遇到了瓶颈,不能够精确的检测视频移动目标信息以及对其进行动作预测分析,在深度学习下,目标检测的效果要比传统手工特征检测效果好太多。本文提出一种基于深度学习的方法对移动物体进行检测,能够满足一般用户对视频移动目标检测识别的需求,同时还能对目标的行为进行预测分析。
1 目标定位技术
近几年来,目标检测算法取得了很大的突破。比较流行的有基于Region Proposal 的R-CNN 系算法(R-CNN,Fast R-CNN, Faster R-CNN 等),它们是two-stage 的,需要先算法产生目标候选框,也就是目标位置,然后再对候选框做分类与回归。还有Yolo,SSD这类one-stage 算法,其仅仅使用一个卷积神经网络CNN 直接预测不同目标的类别与位置。第一种方法准确度高一些,但是速度慢,第二种算法速度快,但是准确性要低一些。基本都具有高冗余度、高时间复杂度,影响目标检测性能,而边框回归方法[2]可以提高目标检测的准确性,因此在边框回归方法的基础上提出基于前馈神经网络(feedforward neural network,FNN)的目标定位技术。
1.1 基于FNN的目标定位模型分析
为了将移动目标分割出来,将移动目标检测区域L 进行等间隔划分,将区域平均划分为K 行K 列,将区域中能够划分出K 行或K 列的概率用向量Pk表示,记为
本文用2 种边界概率表示方法对划分的行列进行表示。一种是利用可能性边界划分的概率大小计算移动目标边界框的行或列,行概率表示为列概率表示为为手动标记边界,因此第一种边界概率P={pX, py}的期望T={tX, ty}。tX, ty分别计算如下:

第二种表示利用边界概率代替行的上下边界框及左右边界概率:分别为边界概率表示为P={pt, pb, pl, pr},具体关系可以表示如下:

1.2 基于FNN的目标定位设计
基于FNN 的移动目标定位模型框架如图1 所示。

图1:定位模型框架
图1 的输入是尺寸为w×h 的图像I 的相应两个颜色通道图,输入尺寸为w×h×3。前馈神经网络网络结构如图2 所示。图2 的主要作用是降维,通过8 个卷积层将原始图像I 和要搜索的移动物体所在区域K 进行映射,得到特征映射图,特征映射图的大小为特征映射图中的M 映射区域被裁剪掉。
对于定位而言,需要定位4 个点,可以让标签y 的形式形同(K,x1,y1,x2,y2,x3,y3,x4,y4)K 为是否有该类图像,如果有4 个点的数据才有效,否则无效,但是点的意义要讲顺序,比如点1 是头顶,点2 是脚,顺序不一样容易导致输出结果错误。相当于网络多输出实现定位点输出。本文模型将被划分成2 个不同分支,分别为X 分支和Y 分支,2 个分支中经过池化降维后最终生成相应的边界概率,经过运算得到行和列。如图1 所示在X 分支中先对X 方向上的特征由最大池化层池化降维后得到相应的映射特征图,再将所得池化后特征图输入完全连接层整合,最后搜索区域通过sigmoid 函数输出。对于分支Y 则先通过最大池化层池化[4]得到相应特征映射,再把获取的特征图作为连接层的输入,传输到完全连接层,完成映射样本标记空间,最后由sigmoid 函数输出判断区域K 以及边界的概率(pt, pb)。与X 分支不同的是在池化时汇集方式不同及输出的边界概率不同。X、Y 分支的最大汇集公式为:

1.3 目标定位检测算法流程
本文所提出的视频目标定位检测算法流程如图3 所示。
候选边界一般有2 种生成方法。 第1 种为滑动窗口法。将所有可能的图像边界情况详尽的列举出来。即在图像中的每一个尺度和每一个像素位置进行遍历,逐一判断当前窗口是否为人脸目标。这种思路看似简单,实则计算开销巨大。第2 种方法为区域提案法,先预测目标可能出现的区域,在每个位置同时预测目标边界和objectness 得分,这样可以减少过多的帧,而且具有相对较高的召回率。因此本文对第2 种方法进行改进。
在目标定位检测算法流程中,对于给定迭代次数的边框改进选择方法,预先给定的候选边界将会生成这一条边界所对应的置信度而该置信度可表明检测目标的可能出现区域。
输入:集合中每个单元所对应的数组
输出:集合中数组的极大值


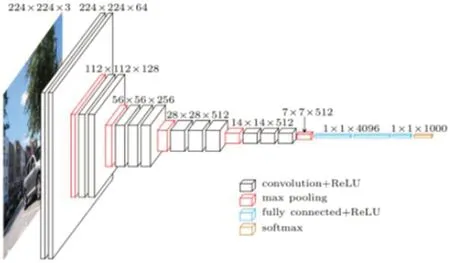
图2:网络模型结构

图3:目标定位检测算法流程

图4:卷积神经网络结构图
2 基于时空的移动物体动作检测
2.1 时空网络结合法
为了表明移动目标的行为动作与空间和时间的特征有关联性,必须将时空网络相融合。首先要进行神经网络特征图像的匹配。若匹配不成功则要将比较大的要素图样进行再采样。时空融合方法描述公式为:

表1:目标搜索准确率表

图5:自然查询模型结构

图6:级联分类器框架

公式4 说明2 个神经网络的2 个特征图融合为1 个新的特征图。合并后特征空间为H×W×D,其中,H 为特征要素图的高度,W 为特征要素图的宽度,D 为特征要素图的通道数。公式5 为利用sum 方法收敛d 通道特征图的像素点(i,j),其中1 ≤i ≤H,1 ≤j ≤W,1 ≤d ≤D。
2.2 框架设计
本文设计的移动目标识别总体框架主要包括3 个模块:特征提取,特征的融合,目标识别。在该框架中,根据神经网络特点,通过时间轴将2D 卷积神经网络扩展成3D 卷积神经网络时,连接层会损失部分图像特征信息,可通过改变光流图像输入来改善,这是因为光流图像被添加到该模型的输入中时,处理的为静止图像,这样图像鲁棒性得到相应提升,同时还可以补偿光流特性。
2.3 目标动作行为检测
卷积神经网络结构如图4 所示。图4 所示卷积神经网络模型共包含有3 个卷积层,2 个池化层,1 个完全连接层、丢失层。网络卷积层使用核心数分别是60,140,230。3D 卷积神经网络(CNN)可以同时卷积水平和垂直维度,还可以将时间维度空间维度融入3D 卷积[6]。池化层使用的汇集方法为最大池法。3D 汇集内核的大小分别为2×2×2,空间和时间的深度为3,时间和空间的跨度为1×1×1。
3 自然查询模型
3.1 模型框架
本文提出的自然查询模型框架如图5 所示。
图5 中简化模型结构简单,分3 层,包含4 部分:第1 层卷积神经网络CNNglobal,第2 层1 个GRU 循环单元GRUquest,第3层1 个自嵌入层和1 个自预测层。简化后原始模型为:
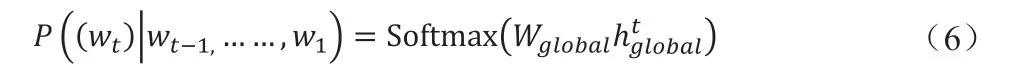
由上式(6)可得简化后SGRC 模型与LRCN 模型相类似,在LRCN 模型中,随机梯度下降用于优化整个图像标记的数据集,所以在SGRC 模型中也用随机梯度下降进行优化,参数的权重矩阵的值被设置为Wlocal=0。
先对用户输入的图片进行查询确定相应于图片的候选边界,通过运算输出最优候选边界,再通过查找最大置信度得分确定查询物体目标边界。
3.2 模型训练
所谓的级联是指包括许多级别的分类器,并且只有前一级别的样本可以进入后一级。 因此,可以在前几个阶段快速消除许多非目标样本,从而为更像目标区域的检测节省了大量时间。如图6 所示。
3.3 实验结果
将本文算法实验结果与传统CAFFE 算法、LRCN 算法、SGRC(无空间转移)算法进行对比,结果如表1 所示。
由表1 可以看出:基于CAFFE 方法搜索精度比较低,LRCN算法其次,SGRC(无空间转移)算法较好,本文算法准确率最高。这是因为CAFFE 方法、基于ImageNet,ReferIt 数据集,其特点为如果目标文本注释中若出现不在数据集ImageNet 中的标签词,最终的搜索可能会找不到目标。LRCN 算法采用循环卷积结构,没有更好的表达能力,本文算法基于时间空间融合方法提取特征,通过级联分类器剔除非有效目标,有效提高了移动物体检测的准确性和效率。
4 结语
本文提出了一种基于深度学习的移动目标检测技术,充分利用FNN 获取图像特征,经过运算得到特征映射,通过迭代得到候选边框,对候选边框进行非最大抑制优化,筛选出目标可能区域,结合了时间空间融合技术,采用级联分类器进行训练,利用自然查询模型算法完成目标搜索。实验结果取得了较好的检测准确率。
