基于语义分析的文本相似检索模型研究
2020-02-02黄丽娟
黄丽娟
(北海职业学院电子信息工程系 广西壮族自治区北海市 536100)
1 研究内容及研究方法
研究内容:深度神经网络的损失函数对模型训练的过度拟合有显著影响。为了使情感二元分类模型更有效地拟合预测误差样本,本文借鉴了合页损失函数和三元损失函数的思想,优化了BILSTM 和CNN 模型中的交叉熵损失函数,设计了BO-BI-LSTM 和BO-CNN 模型。
研究方法:优化损失函数,损失函数进行优化用交叉熵损失函数。公式如下所示:
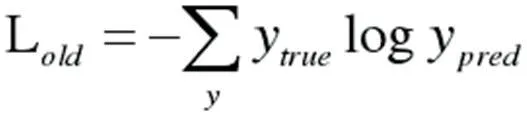
其中ytrue 是实际输出,ypred 是期望值。选择阈值M 并引入单位阶跃函数θ(χ):所以,考虑新的损失函数:

如果正样本的输出大于M,则不更新模型,反之则更新;负样本小于1-M,则不更新模型,反之则更新。得出结论:如果负样本的输出小于1-M,则不更新模型。据此,基于新的损失函数Lnew的基础上,对BI-LSTM 模型和CNN 模型的损失函数进行了优化,设计了BO-BI-LSTM 和BO-CNN 模型。
2 主要研究结果
2.1 实验装置
2.1.1 实行环境
环境配置:操作系统:Windows 10(64 位);
CPU:Intel® Core(TM) i5-8250u,1.8GHz;
内存:8G;
硬盘:2T;
编程语言:Java11.02;
深层神经网络框架:keras2.0;
词矢量训练工具:word2vec;
分词工具:Jieba。
2.1.2 英语知识库
包含5 万条剧评数据,其中正评数据2.5 万条,负评数据2.5万条。中文知识库:包括产品评论数据信息,如图2-1所示,包括六个方面的评论数据,其中文字数据2 万多条,其中正评数据1 万多条,负评数据1 万多条。
2.1.3 文本预处理
文本预处理包括文本分割、去死字、词频统计、文本矢量化等操作。本实验选用word2vec 框架来构造词矢量。
2.1.4 超级参数配置
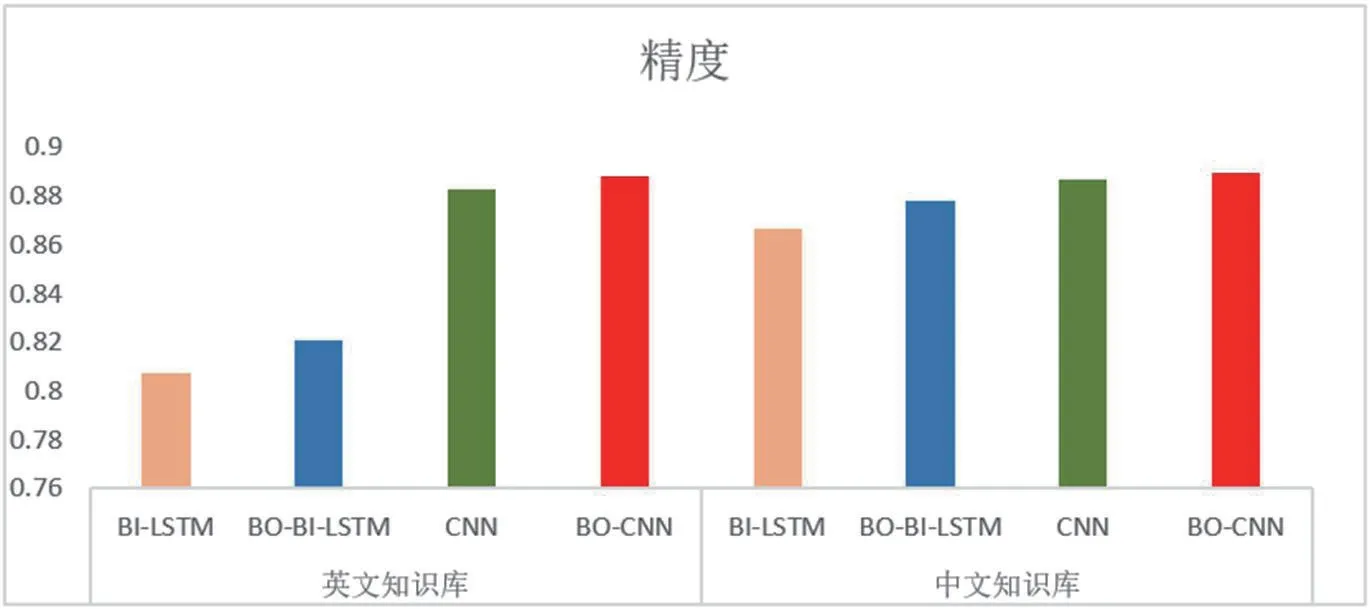
图1

图2
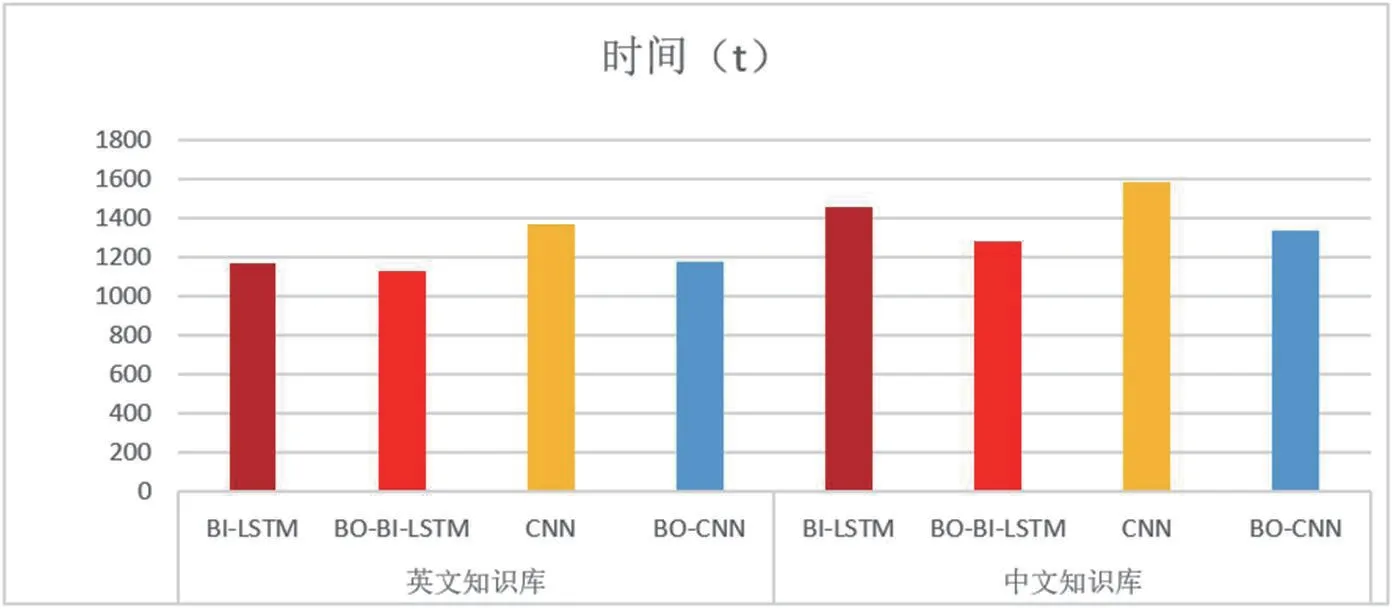
图3
在神经网络模型训练过程中,超级参数要进行调整,模型的超级参数配置如下:Batchsize:批量训练样本数;Hiddendam:隐藏层节点;Embeddingdam:词矢量维数;Filters:过滤器尺寸;Kernelsize:卷积核数;Maxfeatures:最大特征数;Epoch:模型迭代。
2.2 BO-BI-LSTM和BO-CNN模型的结果分析
2.2.1 优化参数
设计了四组参数优化实验。
(1)阈值M 的选择;选取阈值M 分别为0.5 到1.0,依次递增0.1。精度先增大后减小。当M=0.6 时,均为最大值。当M 值由0.5 变为0.6 时,两个模型的精度变化最大;丢失率先减小后增大。当M=0.6 时,两者均为最小值。基于上述实验结果,两种模型的阈值M 为0.6。
(2)损失函数对模型的影响:使用Binary-Optimize 损失函数后的BO-BI-LSTM 模型的精度最高。使用标准交叉熵损失函数的BI-LSTM 模型精度高于其他函数。基于以上实验结果证明了本文优化损失函数的有效性。
(3)词矢量维数选择:当字向量维数为100 时,BO-BI-LSTM模型的精度最高,丢失率最低。当BO-CNN 模型的词矢量维数为50 维时,精度最高,丢失率最小。
(4)Dropout 选择:本实验将Dropout 值从0.1 增加到0.5,当Dropout 设为0.2 时,BO-BI-LSTM 模型的精度最高,丢失率最低,耗时最少。当Dropout为0.2时,CNN-BO模型的精度最高,耗时最少。当Dropout 为0.3 时,丢失率最低。
通过对上述参数优化实验的分析和讨论,得出本模型的超级参数选择。
2.2.2 结果分析
为了验证两个模型的有效性,在中英文两种知识库和基准模型上进行了实验。
2.2.2.1 精度分析
从图1 得实验结果:
(1)不同知识库的实验结果存在一定差异。中文中BI-LSTM和BO-BI-LSTM 模型的精度分别比英文高5.98%和5.70%;中文中CNN 和CNN-BO 模型的精度分别比英文高0.36%和0.12%。
(2)从图2-6 可以看出,BO-CNN 模型在中英文知识库中的精度最高;BO-BI-LSTM 模型在中英文知识库中的精度分别比BILSTM 模型高1.41%和1.13%;BO-CNN 模型在中英文知识库中的精度分别比CNN 模型高0.52%和0.28%。
(3)训练集中的四个模型的精度随着迭代次数的增加而增加,最终趋于稳定。然而,在测试集中,随着迭代次数的增加,精度的变化趋势相对平缓且波动较大,特别是在BI-LSTM 和CNN 模型中。本研究结果表明,BO-BI-LSTM 和BO-CNN 模型能够更有效地拟合错误的预测样本,有助于防止过度拟合现象,提高情感倾向分析任务的精度。
2.2.2.2 丢失率分析
从图2 得实验结果:
(1)四种模型的丢失率随迭代次数的增加而降低,经过10 次迭代后趋于平稳。但是,每个模型在测试集中的丢失率变化很大,BI-LSTM 和CNN 模型在测试集中波动较大,总体丢失率呈上升趋势;BO-BI-LSTM 和CNN-BO 模型在测试集中随着迭代次数的增加而缓慢下降,最终趋于平稳。
(2)可以看出,在英语知识库中,每个模型的丢失率在第二次迭代后都有很大的变化,经过10 次迭代后,BO-BI-LSTM 和BO-CNN 模型的丢失率分别比BI-LSTM 和CNN 模型低。分析结果表明,优化后的损失函数使模型在多次迭代后具有更好的泛化能力和更低的丢失率。
2.2.2.3 时间性能分析
从图3 中可以看出,当正样本的预测值大于M,或负样本的预测值小于1-M 时,BO-BI-LSTM 和BO-CNN 模型不更新,而将重点放在预测不准确的样本上,以减少时间消耗。
3 此项研究的科学意义和应用前景;学术界的反映和引用
3.1 科学意义
情感检索分析在主题推理、舆情监控、评论分析和决策等领域得到了广泛的应用,具有很高的商业和社会价值。情感分析还应用于其他自然语言处理任务,如机器翻译,以判断输入文本的情感,选择更准确的情感表达进行翻译,提高系统的准确性。有利于各行各业的蓬勃发展。为人工智能领域的研究提供了坚实的基础,为全球智能化建设提供了强有力的理论和实践支持。
3.2 应用前景
随着人工智能的飞速发展,基于语义的文本情感检索模型得到了越来越广泛的应用,主要表现在以下几个方面。
(1)金融行业应用:金融交易和金融分析决策,进行后台风险防控和监管。
(2)政府行业应用:信息全程跟踪分析,形成对形势影响范围、公众反应、负面影响和理论内容等的分析报告。
(3)客户服务行业应用:解决简单重复的工作,支持业务类别的自动分类和语义处理,提供了更加智能化的高效的新人工智能体验。
(4)商业应用:为生产者和消费者提供网络评价报告。
3.3 学术界的反映和引用
情感检索模型的研究一直是学术界和工业界研究的热点。目前,国内外在该领域的探索性的研究较多。例如,斯坦福大学的基于智能概念的信息检索引擎;利用医学语料库和双语词典建立概念网络;中国科学院生成概念空间,实现基于概念空间的扩展检索;北京邮电大学手工创建了一个语义网络;中国科学技术大学和中国科学院计算技术研究所联合研究开发的基于概念语义空间的联想检索系统;微软新一代人工智能开放最新的人工智能技术和知识库,如微软机器阅读理解,微软研究院社交媒体对话语料库、18K 数学文本测试集等。微软亚洲研究院的语义分析知识库。
4 完成情况及存在问题
4.1 完成情况
(1)总结了相关理论。
(2)对BI-LSTM 和CNN 模型的交叉熵损失函数进行了优化,提出了BO-BI-LSTM 和BO-CNN 模型。通过中英文知识库参数优化实验和对比分析实验,验证了BO-BI-LSTM 和BO-CNN 模型在一定程度上提高了情感分析的精度,大大降低了丢失率,防止了过度拟合现象。
4.2 存在问题
在实验过程中,我们仍然发现了一些问题和许多不足:
(1)在文本预处理技术可以增加短语矢量或句子矢量的表达。
(2)本文采用正负两种情绪分类方法来比较,情绪强度的不足。后期可以对细粒度问题进行深入研究。
(3)提出的两个模型的性能有了很大的提高,但由于时间的限制,只对一些参数进行了优化实验,今后可对其他参数进一步优化,提高模型的性能。
