基于深度学习的连锁超市销售预测研究
2020-02-01王志刚冯云超江勇
王志刚,冯云超,江勇
(湖南师范大学信息科学与工程学院,长沙410081)
0 引言
连锁超市零售业是一个竞争非常激烈的市场,库存控制能力是公司盈利的关键。因此,准确的销售预测是取得成功的基础。否则可能会出现缺货或库存过剩等情况,直接影响公司的盈利[1]。这种影响并不局限于盈利性业绩,服务客户的质量也会受到低效预测系统的影响。例如,缺货将导致客户去其他零售商购物。此外,连锁超市行业的供应链很长,涉及大量参与者(如原材料供应商、制造商、分销商和零售商),这导致在对产品的需求水平有一个准确的了解之前就下了订单。
尽管有相关性,但销售预测是一个复杂的过程,因为产品的销售高度依赖消费者的个人品味,而消费者的品味差异很大[2]。商品也是由大量不同尺寸的不同产品组成,对应许多不同的库存单位(SKUs)。此外,天气条件、节假日、市场活动、促销和当前的经济环境等外部因素也会对销售产生直接影响[3]。
本案例研究旨在通过以下方式改善销售预测问题:
(1)考虑新产品销量和因素的大量变化,可以对未来的销售产生很大的影响。而过往研究的模型通常只包含影响销售的有限因素;
(2)评估深度神经网络(DNN)的性能,以在连锁超市销售预测上下文中执行预测。虽然深度学习的应用还处于起步阶段,但值得进一步探索。另外将DNN模型与浅层数据挖掘回归技术的性能进行比较,以便了解使用更先进的方法是否可以显著提高模型精度,或者更简单的方法是否可以获得类似的结果;
(3)将领域专家的意见和产品的特性结合起来,作为预测变量的一部分。
1 相关研究
为了探讨连锁超市零售额预测的问题,研究人员开发了几种分析模型。在统计技术中,最常用的是基于时间序列的预测方法,如ARIMA、SARIMA、指数平滑、回归等。
尽管统计方法很受欢迎,但仍存在一些局限性,例如需要将定性数据转换为定量数据、需要汇总信息或时间序列数据,而这在连锁超市行业通常是不可用的,因为其库存单位经常被更换,销售模式可能不规则[4]。模糊系统或数据挖掘模型已经优于统计方法。这些方法能够处理大型数据集,并且可以处理数值和标称数据[5]。可以模拟销售和历史商品变量之间复杂的非线性关系,再将这些关系推广到未来商品的销售预测中[6]。在各种研究中都有令人满意的结果,例如文献[7]将神经网络与进化计算相结合来支持一个预测系统,其模型的性能优于SARIMA模型,且适用于需求不确定性低、季节性趋势较弱的短期零售预测。然而,很难在精确的结果和计算时间之间取得良好的折衷。
近年来,深度学习技术受到了广泛关注。基于其灵活性和显著优于其他数据挖掘方法的能力[8],该技术已被用于解决不同研究领域的实际问题,如图像分类、语音识别和生物信息学[9]。深度学习技术在需求预测中的应用也越来越多,诸如交通系统[10]、医院管理和电力负荷等。然而,深度学习算法在零售业销售预测中的应用还处于起步阶段。
尽管数据分析技术为改进预测做出了不可否认的贡献,基于其更高的客观性和推理能力,来自领域专家的意见应得到特别关注。一些研究将专家意见纳入预测模型,强调了在预测需要调整的情况下,领域专家起关键作用。这些调整可能是源于获得的额外信息或存在特殊事件[11]。这些研究的一个共同点是,将专家的知识与数据分析工具相结合,而不是仅仅依赖其中一个工具,预测模型的性能会更好。然而,在连锁超市零售的背景下,还没有研究将产品特性和领域专家的意见作为预测变量来预测销售额。
国内对零售采购决策做的研究工作不多,主要集中在供货渠道、价格和盈利管理方面的研究。文献[13]构建了一个由平台商和电商平台构成的混合销售渠道决策模型,分析了不同权利结构下制造商入驻的质量条件、入驻前后对双方的决策影响。文献[14]研究了一个初入行业的生产型零售商,和一条由上下游竞争零售商组成的成熟型供应链,将市场需求不确定性进行量化,将自制和外购策略的定义具体化。探讨了在两种策略下,零售商的生产/订货量、供应商的批发价和参与者的期望收益。
关于连锁超市行业的预测研究一般是按产品类别进行的,对单个库存单位进行销售预测的研究也很少。这些研究工作的一个共同特点是考虑很少的变量来预测销售额(通常不超过4个),并且都没有考虑领域知识。
本文通过评估DNN在连锁超市零售行业中进行销售预测的效率,同时考虑不同性质的特性,如产品的物理特性、价格和代表领域知识的特性。
2 案例研究和数据
以一个在各地有近百家分店的连锁超市公司作为研究案例。尽管这家公司的产品种类繁多,如雨伞、手表、帽子和箱包,但本研究分析的数据与2017年春夏(S17)和2018年春夏(S18)期间三百多种箱包的销售有关。
数据有每个产品的历史销售数据及其物理特性、公司的物流和内部组织方面,还包括领域专家的意见。所有这些因素都被用来了解哪些特性使产品对客户更有吸引力,从而帮助采购部门更好地确定要订购的产品数量。
目前,公司订购的箱包数量依据三个因素:上一季和同一季节同类产品的销售情况、采购部人员的经验,以及开发人员和市场部从不同来源收集的未来趋势信息。表1列出了收集的信息类型,对于每个变量,都指定了名称、类型、含义以及可以采用的类别总数。
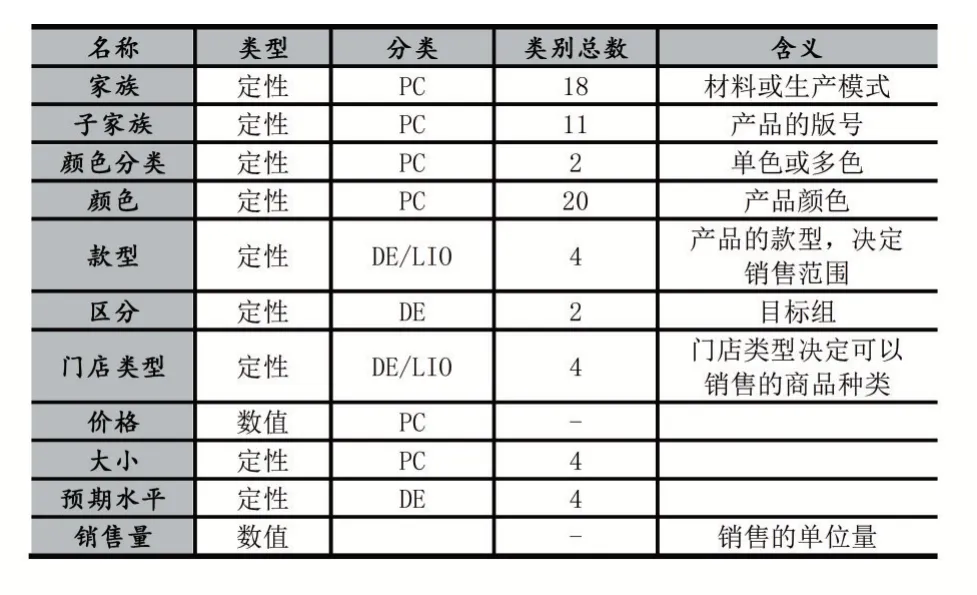
表1 变量及说明
变量分为产品特征(PC)、公司后勤与内部组织(LIO)和领域专家(DE)三个类别。共10个变量描述产品的特性,价格和销量是数值变量,其他是定性变量。
按规模及其销售潜力将公司的门店分为四种类型(A、B、C或D),A类是指展示面积大、销售潜力大的店,将接收为该季节采购的全部产品。而销售潜力较低的小型门店,可供选择的产品种类将比较有限,分类为D。门店的这种分类用于定义每个商品的总订购量。为了推断这一数量,根据以下方法创建了门店类型的聚集区:D类门店将只提供可以在公司的所有门店展示的商品,而A类可以接收更特殊的产品,因为这些门店已经证明了销售这些产品的能力。因此,分类为DCBA的产品将在公司所有门店销售,分类为A的产品仅在A类门店中销售。预期水平变量与产品的销售期望水平有关,有四个可能的值:SB、M1、M2和M3,分别对应销售预期的最高值、正常、平均、较低,这种分类由市场、开发和采购部门定义。因为类别名称不能传达每个类别之间的差异,款型变量则可以根据季节趋势将产品分为四类:时新、基本时新、普通和集中分发;其中时新产品更接近当季潮流;集中分发与普通类似,只是在所采用的分发策略上有所不同。这种分类还与产品在店内销售的周数有关,时新产品在商店可以销售4周,基本时新产品在6周内可以买到,普通和集中分发类则可达8周。产品也根据其设计的目标受众进行区分。例如被归类为“青少年”的产品是为青少年设计的,而打算销售给女性的产品则被归类为“女性”。这种分类是市场部工作人员对年龄或性别的看法,目标受众会对特定产品表现出更大兴趣。
期望水平、门店、款型和区分这四个分类都是由公司的专业人员生成,它们代表了领域知识。这些变量被作为附加值整合到预测模型中。
3 模型设计
虽然没有每个季节新推出产品的历史销售数据,但公司拥有以前产品的销售信息,并完全了解历史和新产品的特点。因此,可以根据历史商品的销售情况和新旧商品的特点,探索两者的相似性,从而实现对未来商品销售的预测。为此,提出探索不同的回归数据挖掘技术来开发新产品销售预测模型。
在模型的学习过程中,使用了同一季节产品的历史销售数据。如图1所示,在数据预处理步骤之后,根据观测所属季节将初始数据集分成两个子集。有关S17季节的信息是训练过程的基础,该过程对应一个由300多个商品组成的数据集,其中有可用的历史数据。S18季节对应的数据用于对模型进行性能评估,即总共300来个未来商品。必须强调的是,产品不会从一个季节过渡到下一个相应的季节,这意味着两个不同季节之间的产品没有重叠。
在S17和S18记录的库存单位销售总量中,大部分产品的销售记录在2000至6000件之间,大约相当于构成各自收集的库存单位总数的80%左右。也可以得出这样的结论,少数库存单位的销量超过了剩余产品的销量。销量超过14000件的可以被认为是优秀产品。

图1 流程示意图
预测模型的构建有三个相互联系的重要步骤,即改进模型的学习过程和创建更精确的预测工具。这些步骤是:应用贪婪方法选择模型中的预测变量,对所涉及的参数进行优化,并对模型进行测试。图2描述了算法的结构,下面将介绍这些步骤以及在模型开发过程中的链接方式。

图2 算法结构
该过程的目的是首先确定变量和参数的选择,它们仅使用历史数据就可以得到更好的模型,然后,在对未来和未知信息进行测试时,评估所获得的最佳模型的性能。
为此,应用K=10的K-fold交叉验证将初始训练数据集划分为K个折。通过多次重复训练与验证过程(与定义的折数相同)来找到最佳的参数和预测器组合。
为了选择模型中预测变量的最佳组合,采用贪婪特征选择方法在每个阶段进行局部最优选择。这一过程将因变量分别与每个自变量相关联,也就是说,开始考虑仅用一个独立变量获得的所有可能的组合(总共有10种可能性)。对于每一个组合参数都进行优化,其中包括在验证数据集上的模型测试过程。对所分析的参数定义值进行暴力网格搜索。每一参数组合的决定系数R是模型评估过程中获得的10个R值的平均值。每个变量组合的最佳参数组合被选为使R平均值最大化的参数组合。类似地,在所有可能的变量组合中,选择能使平均R达到最高值的组合。
然后将能够达到最高平均值R的单个预测值与其余预测值相结合。重复这个过程,直到平均R值没有改善,这意味着加入一个额外的预测值(不管是哪个预测值)并不能改善模型估计的预测值和观察到的销售值之间的R。然后,将预测因子和一组参数组合起来,得到最佳的绩效模型,用于构建预测未来销售的模型。
最终模型的性能评估过程遵循自举方法,并由以下步骤重复十次组成:通过重新定位原始S17和S18数据集,创建训练和测试数据集(与原始数据集大小相同),开发预测模型、测试数据集预测值的确定、R的计算以及预测值和测试数据集之间的剩余性能度量值。
由于在预测模型的构建和测试中采用了这种重复采样过程,模型的鲁棒性提高了,并避免了过度拟合。计算均方根和均方根误差等评价指标来衡量最终预测模型的性能。模型性能指标的最终值被确定为十次迭代的平均值。
此外,为了比较深度学习技术与浅层技术的性能,还采用了线性回归方法。所采用的一些数据挖掘技术需要定义一组可以调整的参数,以便确定每个参数的值,从而提高预测模型的效率。
总的来说,结果表明模型可以作为有效的工具来预测销售,并帮助定义连锁超市行业的订货和营销策略,但管理者必须充分意识到与使用这些模型相关的一些特殊之处。
另外,管理者需要了解与可用的不同类型模型相关的复杂性,以及所需的不同资源。例如,DNN可以在大型和小型数据集上成功运行,但在实践中,由于需要复杂的训练过程,这种技术可能难以实现。在许多情况下,更简单的技术如RF也能取得良好的结果,也是最具成本效益的方法。
基于专家在确定潜在销售方面所起的重要作用,管理者必须确保其员工充分了解市场及其需求,并在决策过程中整合他们的知识。值得注意的是,连锁超市零售市场的一个公认特征是高度依赖顾客的偏好,这种偏好非常不稳定。因此,决定使用这类模型来协助其决策过程时,管理者必须每年用新信息对模型进行再培训,因为这一步骤能使模型捕捉客户的最新偏好。
4 结语
本文论述了一个预测模型的研发,以估计未来的产品销售。探讨了使用深度学习方法实现这一目标的潜力。使用了一家在连锁超市零售市场经营的公司提供的销售数据。数据集包括以前收集的产品销售信息,以及描述以前和未来产品的预测变量。
虽然这项工作的重点是连锁超市零售业,但所提出的模型也可应用于其他零售业领域,因为问题的特点通常是相似的。
