基于预训练语言表示模型的汉语韵律结构预测
2020-01-17张鹏远卢春晖王睿敏
张鹏远 ,卢春晖 ,王睿敏
(1.中国科学院声学研究所语言声学与内容理解重点实验室,北京 100190;2.中国科学院大学电子电器与通信工程学院,北京 100049)
预测输入文本的韵律结构作为统计参数语音合成中必不可少的一个步骤,其结果与其他语言学信息相结合被进一步用于预测待合成语音的停顿、时长、基频和频谱等声学参数.因此,韵律结构预测的准确性将在很大程度上决定合成语音的自然度与可懂度.
在汉语语音合成系统中,通常将韵律结构在语法词的基础上自底向上划分为韵律词、韵律短语、语调短语3个层级,并以此来区分相邻语法词间的停顿长短.韵律结构预测就是针对每个韵律层级判断一句话中每个语法词边界是否为该层韵律边界,可以将此预测过程视为一个典型的自然语言处理问题——序列标注问题,即对输入文本序列建立一个其到输出标记序列的映射关系,以决定每个输入元素对应的输出类别.因此韵律结构预测可以使用常规的序列标注方法,在韵律结构预测中,输入序列与输出序列是等长的.
早期,序列标注问题的解决通常借助于统计机器学习方法,包括决策树[1]、隐马尔科夫模型[2]、最大熵模型[3]、条件随机场(conditional random field,CRF)[4]等在内的多种方法均被用于韵律结构预测问题中.随着深度学习的发展,预训练语言模型在众多自然语言处理任务中都展现了其有效性[5-7].通常将预训练的语言表示用于具体任务中,有两种策略.一种为基于特征的方法,即将预训练的表示作为具体任务中输入特征的一部分,预训练词嵌入向量就是这种策略的典型代表.目前,已经有很多工作将这种策略用在韵律结构预测任务中.Ding等[8]分别使用独热向量和预训练的字嵌入向量作为模型的输入特征,对两者进行了对比,实验表明使用预训练的字嵌入向量在各个韵律层级上的预测结果均优于独热向量.Zhao等[9]也得出了相同的结论.Zheng等[10]提出了一种增强的嵌入式特征,在词嵌入向量中融入字嵌入向量的信息,实验表明以该特征作为输入的性能优于直接使用词嵌入向量.Zheng等[11]还在输入词嵌入向量和字嵌入向量的基础上,将预训练语言模型预测的下一个词的概率作为一种上下文敏感的嵌入式向量额外作为模型的输入特征,进一步提升了网络性能.上述这些工作均是将利用大规模语料进行无监督学习得到的嵌入式向量作为网络的输入特征,在网络结构上都采用了能对上下文信息进行建模的双向长短时记忆网络(bidirectional long short term memory,BLSTM).
另一种将预训练表示用于具体任务的策略为基于模型微调,即在预训练语言模型的基础上,引入任务相关的输出层,然后对预训练的模型参数和输出层参数一起进行简单的微调.虽然 Huang等[12]和本文之前的工作[13]使用了类似的思想,但这两个工作是建立在相关任务(如分词、词性标注)模型的基础上,而非更通用的语言表示模型.受最近基于转换器的双向编码器表示(bidirectional encoder representation from transformers,BERT)[14]在多个自然语言处理任务中成功应用的启发,本文首次在通用语言表示模型的基础上使用模型微调的策略进行韵律结构预测任务,对BERT语言表示模型在韵律结构预测上应用的可行性进行了探索,包括对不同的韵律输出结构的对比,对预训练及额外引入分词任务的有效性的探讨,以及对不同数据量对模型性能影响的分析.
1 BERT语言表示模型
BERT是最近提出的一种语言表示模型,通过将掩蔽语言模型作为训练目标实现了预训练深层双向表征.作为一种基于微调的通用语言表示,BERT在多个任务上的表现甚至超越了任务相关的结构,达到了目前的最优水平.
1.1 模型结构
BERT在模型结构上使用了神经网络机器翻译模型Transformer[15]的编码器部分.如图1所示,其由N个完全相同的层堆叠而成,其中每层包含两个子层,层间进行残差连接[16]并做层归一化[17],即每个子层的输出Y为
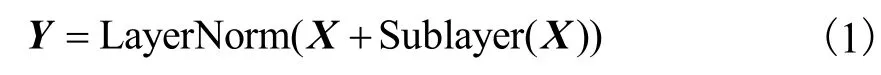
式中:X为该层的输入;Sublayer代表该层的实现函数.为了使用残差连接,模型中所有隐层的单元数均为d.
具体地,第 1个子层使用多头注意力机制,通过h个注意力头在多个表示子空间内对不同位置的注意函数进行学习.具体过程如图 2所示,对于输入d维的查询向量Q、键向量K和值向量V,首先对每个向量进行h次线性变换,得到h组不同的查询向量、键向量和值向量.然后对每组Qi、Ki和Vi

图1 BERT模型结构Fig.1 Model architecture of BERT
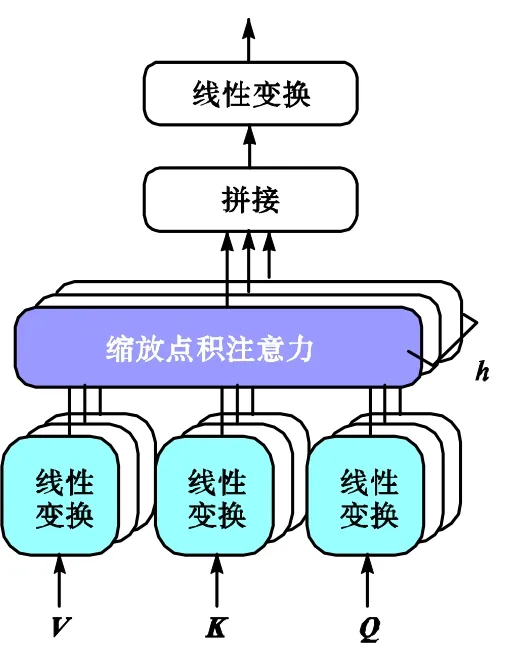
图2 多头注意力机制Fig.2 Multi-head attention mechanism
(i∈[1 ,h])进行缩放点积注意力[15]操作,得到Mi,即
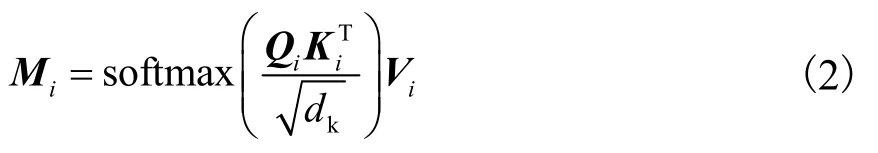
式中dk为Qi、Ki和Vi的维度,且dk=d/h.之后将h个Mi拼接在一起并做线性投影得到最终的输出.
第 2个子层是一个简单的全连接的前馈神经网络,由两个线性变换组成,在两个线性变换间用ReLu激活函数[18]连接,即
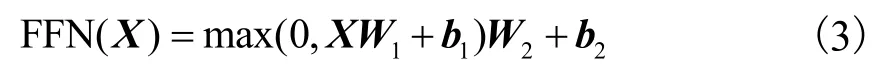
式中:W1∈Rd×4d;W2∈R4d×d.
1.2 预训练任务
为了训练深层的双向表征,BERT在预训练时使用了掩蔽的语言模型作为训练任务,即以一定比例随机掩蔽输入中的一些字,将这些字用“[MASK]”符号替代,然后只对这些字进行预测,这也可以被称为完型填空任务.因在实际任务中对模型微调时不存在“[MASK]”,为了避免这种预训练和微调的不匹配,训练数据生成的具体做法如下:首先以 15%的比例随机选择每个输入序列中将被掩蔽的字,对这些选中的字,将其中的 80%替换为“[MASK]”,10%替换为随机的其他字,10%保留不被替换.
为了让模型具有理解句子间关系的能力,BERT在上述任务的基础上额外增加了下一句预测任务,即判断输入序列中的第 2句话是否为原始文本中第 1句话的下一句话.在训练数据生成时,每个序列的第2句话有 50%为第 1句话的真实后续文本,另 50%为从语料中随机选取的任意文本.
1.3 输入特征
作为一种通用的语言表示模型,为了适用于各种不同的任务,BERT对输入序列进行了一些特殊处理.首先,BERT的所有输入序列的第一个字符均为一个特殊符号“[CLS]”,对于句级分类任务,可以直接以该字符对应的模型输出作为整个序列的表示进行分类.其次,因在预训练中引入了下一句预测任务,BERT的输入序列是由两个句子组成的句子对.为了对句子进行区分,一方面在输入序列中每个句子的末尾加入了特殊符号“[SEP]”来表示句子结束,另一方面两个句子在输入特征上使用不同的句嵌入向量A或句嵌入向量B.
在模型结构上,BERT未使用循环和卷积操作,不包含序列中的顺序信息,因此在输入中额外引入了位置向量,代表每个字在序列中的位置.对于文本序列中的每个字,其输入特征为该字对应的字向量、位置向量与句子切分向量三者之和,所有特征向量均嵌在网络中通过训练得到.
2 基于BERT的韵律结构预测模型
本文构建了基于BERT的韵律结构预测模型,在预训练 BERT语言表示模型的基础上通过微调的方式实现对韵律词和韵律短语的预测.之前大多数工作[1-4,8,11]在预测这两级韵律时采用了级联的形式,即对每个韵律层级构建一个预测模型,并把韵律词预测的结果作为韵律短语预测模型的输入.在实际应用中存储多个模型将占用过多的内存,所以本文利用一个模型对多级韵律同时进行预测,在输出结构上对比了如下两种方式.
(1)将韵律词边界预测和韵律短语边界预测视为两个相关的任务,对每个任务各引入一个输出分类层,利用多任务学习的框架对两个任务间的关系建模,实现对它们的同时预测.以韵律词边界预测为例,将其视为一个三分类任务,对于输入序列中的每个字判断其是否是韵律词边界或是其他(“[SEP]”等).具体地,如图3所示,首先对每个字得到其输入特征向量,即字向量、位置向量与句子切分向量之和.因这里只包含单一句子,所以只使用了句嵌入向量A作为句子切分向量.然后经过 BERT网络得到每个字的输出向量T,对向量T做式(4)操作得到概率向量P,其中W∈R3×h,P∈ R3.最后以P中概率最大的值对应的类别作为预测结果,在图3中分别用符号NB、B和O表示.韵律短语预测过程与此相同.

(2)将韵律边界预测视为一个多分类任务,认为每个字属于韵律词边界、韵律短语边界或非边界三者中的一种,在 BERT的基础上只引入一个输出分类层,实现对韵律词和韵律短语的同时预测.具体过程同(1)所述.
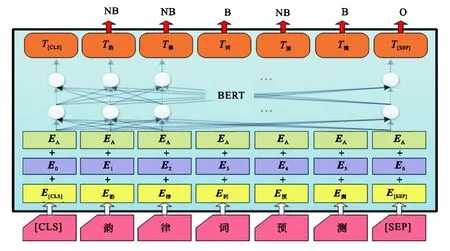
图3 基于BERT的韵律词预测Fig.3 Prosodic word prediction based on BERT
韵律词与韵律短语是建立在语法词的基础上的,以字为建模单位虽然可以避免对前端分词系统的依赖及其造成的负面影响,但是使模型内缺乏词边界的信息,增加了建模的难度.本文额外引入了分词任务,以通过共享隐含层中的高级特征在韵律边界预测任务中获得词边界的信息.实现时在上述韵律预测框架的基础上额外加入了一个输出分类层判断每个字在词中的位置,包括开头、中间、结束和单字4类.
对于每个任务,以交叉熵作为其损失函数,整个模型以最小化韵律边界预测任务与分词任务损失函数之和为训练目标,对预训练的BERT模型参数和新增输出分类层参数一起进行更新.
3 实 验
3.1 实验数据及配置
目前在语音合成领域公开的汉语语料库极少,导致没有通用的实验数据,因此本文实验使用了一个内部的由专业女声录制的包含 9000个句子的汉语语音合成语料库.语料库中所有句子的韵律边界均由标注人员通过阅读文本及听对应的音频进行标注,同时标注人员对所有文本进行了分词并标注了词性.在实验时,90%的数据用于训练,5%用于验证,另外5%用于测试.
在预训练BERT语言表示模型上,使用了谷歌开源的中文模型,模型层数N为12,隐含层单元数d为768,自注意力层头数h为 12.在此基础上进行微调训练韵律预测模型时,batch大小设置为 16,学习率为5×10-5,使用Adam[19]算法进行参数更新.
本文设置了两个基线模型:第1个利用传统方法CRF建模,使用了包括词、词性、词长在内的传统语言学特征,采用第 2节所述级联的形式实现;第2个使用目前效果最好的 BLSTM-CRF建模,模型包含两个隐层,每层每个方向 128个节点,采用多输出的结构以预训练的 BERT中 768维的字向量作为输入特征.除基线 CRF模型由 CRF++[20]工具训练外,其余模型均利用TensorFlow[21]训练.
3.2 实验结果与分析
所有实验以F1值作为韵律词和韵律短语预测的评价指标.定义为

两个基线模型的结果如表1所示,其中BLSTMCRF以字向量为输入,缺乏词边界的信息,所以在韵律词上的表现和以词为输入的CRF相比有较大差距.

表1 基线模型的F1值Tab.1 F1scores of the baseline models
首先对第 2节中提出的两种输出结构进行了对比,实验结果见表2.其中BERT-CLS和BERT-MLT分别代表只有一个输出层和每个韵律层级各有一个输出层这两种结构,两者均是在预训练BERT语言表示模型的基础上利用韵律标注数据进行微调得到.从表2可以看到,BERT-MTL这种结构的性能明显优于 BERT-CLS,这是因为韵律词与韵律短语之间不是非此即彼而是一种递进的关系,只有当该字为韵律词的边界时它才有可能作为韵律短语的边界,而当它是韵律短语边界时则一定是韵律词边界.这种韵律结构间内在的关系利用多任务学习的框架可以得到更好的建模.
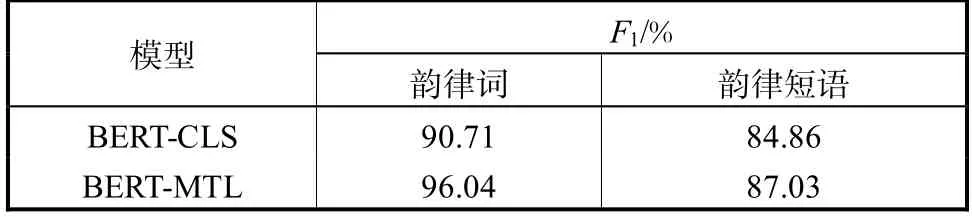
表2 不同输出结构的F1值Tab.2 F1scores of different output structures
为分析预训练语言表示的有效性,在 BERTMTL结构下对比了如下几种模型初始化方式.①BERT-MTL-N:不使用预训练,即所有参数随机初始化,整个模型从 0开始训练;② BERT-MTL-E:仅使用预训练的嵌入式特征部分,即利用预训练模型中的字嵌入式向量,位置向量和句子切分向量初始化韵律预测模型对应参数,其余参数随机初始化,相当于引言中所述的基于特征的方法;③BERT-MTL:使用所有预训练模型的参数作为韵律结构预测模型的初始值,相当于基于微调的方法.实验结果如表 3所示,可以看到从0开始训练的结果最差,这说明在此网络结构下,由于可用的训练数据过少,对汉语复杂的词法句法涵盖有限,导致无法充分建模文本内部包含的韵律关系.基于特征的方法和基于微调的方法与从 0开始训练相比均有提升,这说明了用额外数据预训练可以给网络引入更多的语言学信息.但基于特征的方法在韵律词和韵律短语预测的F1值上均只有大约2%的提升,和基于微调方法 8.16%和 7.26%的提升相差甚远.预训练的特征虽在一定程度上学习到了不同字间的不同表示,但对于处于不同上下文中的同一个字却无法进行分辨,而这种上下文间的关系对于韵律结构预测是至关重要的,所以其带来的提升有限.对于预训练的整个模型,在以掩蔽语言模型作为预训练目标,对大量文本无监督的学习过程中,学习到了每个字常在的词语组合,这种短时的关系在韵律词建模的过程中起到指导作用,即在词语组合的内部不会出现韵律词边界,从而提升了韵律词预测的准确性.对于长时的韵律短语,一方面预训练的模型可以捕捉到句子内部的长时信息,如句法结构、依存关系等,这对于韵律短语的预测是有益的;另一方面,韵律短语建立在韵律词的基础上,韵律词预测准确率的提升也有利于韵律短语边界的预测.
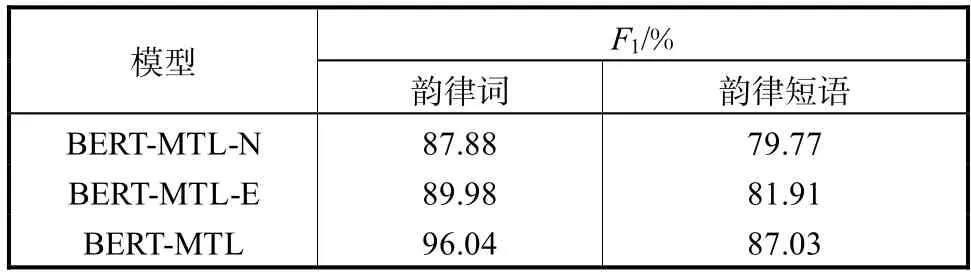
表3 使用不同参数预训练的F1值Tab.3 F1scores when using different pretrained parameters
为了在模型中引入词级别的信息,在表3列出模型的基础上加入了分词任务,实验结果如表 4所示.通过和表 3的对比可得出结论:分词任务的加入确实有助于提升韵律词和韵律短语预测的性能,但随着使用预训练参数的增加,加入该任务对韵律预测效果的提升减弱,这也说明预训练的特征和模型都在一定程度上学习到了词级别的信息.BERT-MTL-WS-E在和基线 BLSTM-CRF使用相同输入的情况下,实现了更优的结果,体现了其更强的建模能力.而BERT-MTL-WS实现了本文最好的结果,在以字为建模单元的前提下结果明显优于以词为建模单元的CRF,韵律词和韵律短语预测的F1值分别有 2.48%和4.50%的绝对提升,这进一步体现了预训练语言表示模型的有效性.
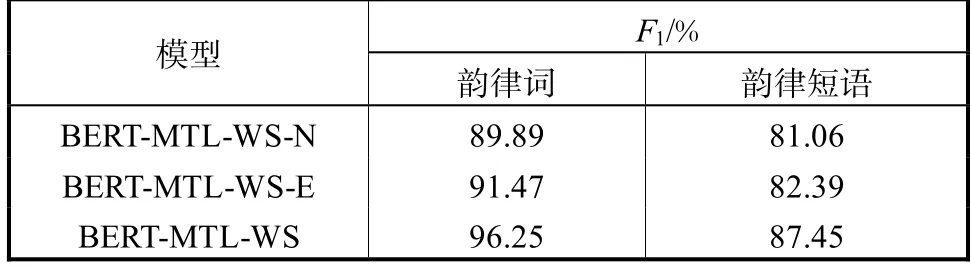
表4 加入分词任务的F1值Tab.4 F1scores when adding the word segmentation task
本文最后对比了不同训练数据量对 BERT-MTLWS-N和BERT-MTL-WS模型性能的影响,实验结果如图4所示,图中虚线为使用8000条文本训练的基线 CRF的结果.可以看到,韵律词和韵律短语的F1值随数据量变化的趋势相同.未经预训练的模型F1值都随着训练数据量的减少急剧下降,当数据量减少至1000条时韵律词和韵律短语预测的F1值与8000条相比分别下降7.83%和8.07%,当数据量更少只有100条时下降值为 33%和 46%.而经过预训练的模型在训练数据减少至 1000条时表现仍比较稳定,韵律词和韵律短语预测的F1值分别只有 0.66%和1.14%的下降,即使当训练数据只有 100条时,下降值也只有2.76%和5.36%,结果甚至优于未经预训练的8000条的结果.与基线CRF相比,经过预训练的模型仅需 300条训练数据即可达到优于 CRF的结果.以上这些量化的结果都表明了利用大规模数据预训练语言表示模型的优势,其不仅大大减少了对特定任务训练数据量的需求,而且在小数据量的前提下仍能实现并保持理想的结果,这也为解决其他训练数据难收集或难标注的问题提供了思路.
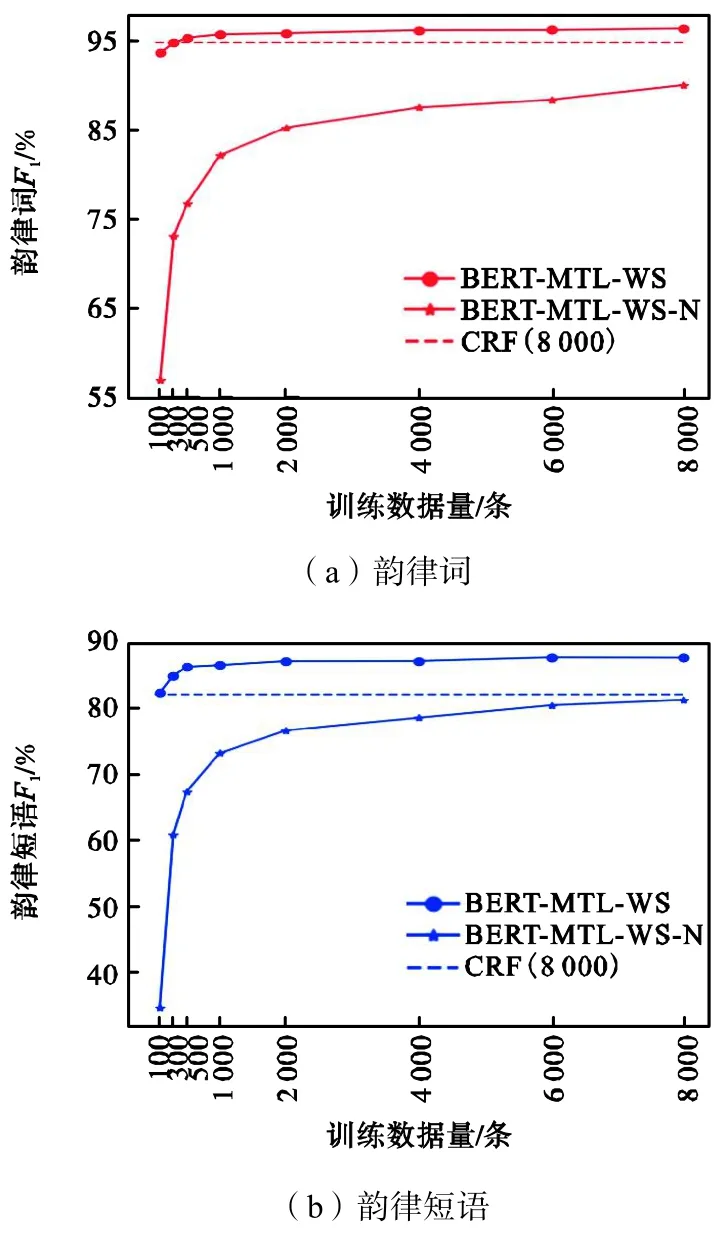
图4 不同训练数据量的F1值对比Fig.4 Comparison ofF1scores with different amounts of training data
4 结 语
本文在预训练语言表示模型 BERT的基础上构建了韵律结构预测模型,将多级韵律边界的预测视为相关的任务,通过多任务学习的框架捕捉各层级间的关系,实现了对它们的同时预测.通过实验对比证明了使用预训练的语言模型不仅可以大幅提高韵律预测模型的性能,而且减少了对训练数据量的需求.另外,实验表明在以字为建模单元的模型中通过加入分词任务获得词级别的信息,可以进一步提升模型的准确性.与基线模型相比,本文最好的结果在韵律词和韵律短语预测的F1值分别实现了 2.48%和 4.50%的绝对提升.
