基于级联卷积神经网络的服饰关键点定位算法
2020-01-17姚麟倩
李 锵,姚麟倩,关 欣
(天津大学微电子学院,天津 300072)
近年来,随着电商平台和时尚行业的快速发展,对于服饰分析的算法需求越来越迫切.服饰关键点定位技术,可以有效克服尺度和形变的影响,推动服饰部位对齐、服饰局部属性识别、服饰图像自动编辑等应用的效果提升,引起了社会广泛关注.目前应用于人体的关键点定位算法已经取得长足发展,但在与时尚行业相互融合过程中,由于服饰在类别、比例和外观上的多变性,服饰关键点定位算法仍然面临重大挑战[1].对于人体关键点,大多数传统方法通过直接回归出人体关节点的坐标来定位,但是由于人体运动的灵活性以及回归模型可扩展性的限制,此类方法的效果都不太理想.
随着深度学习技术的发展,其在图像分类、识别以及关键点定位上已得到广泛应用,2016年 Wei等[2]提出的 CPM(convolutional pose machines)网络通过顺序化卷积方式进行空间信息以及纹理信息的表达,是一种鲁棒性较强的关键点定位算法.同年Newell等[3]提出 SHN(stack hourglass networks)网络,通过引入多模块全卷积神经网络(convolutional neural network,CNN)来解决单人关键点定位问题,每个 CNN模块捕捉不同尺度图片的特征,以此来发现人体空间关系,推断人体的关节点位置,但是随着模块的增加该网络的定位效果难以进一步提升.随后,多人关键点检测算法逐渐出现,效果较好的为自顶向下的算法,即先检测出单人,再定位每个人的关键点.2017年 Papandreou等[4]提出的 G-RMI算法,首先利用Faster R-CNN[5]检测图中的多个人,而后使用深度残差网络(deep residual networks,ResNet)[6]精确定位关键点.2018年,He等[7]在Faster R-CNN基础上提出 MASK R-CNN算法,在实例分割、边界框检测和人体关键点定位等多个任务中都取得优于单一模型的效果.随后 RMPE算法[8]为克服由单人检测框差异而造成关键点定位误差的问题,利用金字塔结构的单目标检测算法SSD(single shot detector)[9]检测单个人,再使用 SHN网络进行单人姿态的关键点检测.2018年 Chen等[10]为优化多人姿态估计中的较难关键点定位问题,提出了级联金字塔结构网络(cascaded pyramid network,CPN),这是一种自顶向下的算法,先使用MASK R-CNN的目标检测分割图中的多个人,再通过 CPN中级联的 GlobalNet和RefineNet实现对每个人关键点定位,通过区分简单和困难的关键点大幅提高定位的精确度,该网络获得2017COCO人体关键点检测挑战赛冠军.
本文算法与 CPN网络思想类似,为级联的卷积神经网络,为了进一步优化 CPN网络中的小物体即关键点定位精度的问题,充分利用特征信息,在第 1级使用 ResNet-101特征提取网络和特征金字塔结构,引入空洞卷积(dilated convolutions)[11]在不损失感受野的情况下提升高层特征图的空间分辨率,保留更多的图像细节信息,实现对所有关键点的定位;在第 2级以沙漏网络[3]为基础,整合来自上一级的特征信息,利用前一级预测出来的关键点之间的结构先验,对困难关键点即第1级损失较大的关键点进行精细调整,进一步提升整个网络的定位精度.
1 基础理论
1.1 深度残差网络
深度残差网络[6]是 2016年由 He等提出的一种CNN结构,在深度卷积网络中,随着网络层数的加深,虽然可获取丰富的语义信息,但也造成了梯度消失、爆炸等问题.ResNet通过引入残差学习来解决这种难以优化的问题.具体地,假定一个网络的输入为x,理想的映射输出为H(x).为了获取H(x),利用堆叠的非线性层来拟合残差映射F(x)=H(x)-x,由此可以得到H(x)=F(x)+x.因此拟合最优映射的问题转化为拟合残差映射函数,使得网络模型不再是学习一个完整的输出,而只是学习残差F(x).图1为普通网络结构和残差网络结构的示意[12].ResNet的核心思想是在前馈网络中引入捷径来表示F(x)+x,跳过一个或者多个网络层执行恒等映射.

图1 普通网络和残差网络示意Fig.1 Schematics of general and residual networks
相比较普通网络,ResNet引入捷径跳过某些层的连接,再与主径汇合,使得底层的误差可通过捷径向上层传递而解决梯度消失的问题,在不增加额外参数又不提高计算复杂度的同时增加网络模型的训练速度、提高训练效果[13].作为简单且实用的深层次网络模型,ResNet在图像分割[14]、目标检测[15]等图像处理领域内应用广泛.本文采用 ResNet-101作为特征提取网络.
1.2 沙漏网络
沙漏网络是一种形如沙漏的下采样-上采样结构,最初由文献[3]提出,利用多模块的沙漏网络定位关键点来识别人体姿态.沙漏网络结构为如图 2所示的对称结构[3],左侧部分通过卷积和池化操作将特征图降低到较低的分辨率,下采样通过池化操作完成,同时通过另一路卷积保留下采样前的特征图,用于和右侧上采样部分同尺度的特征图进行融合,当下采样部分特征图达到最小分辨率后,网络经过最近邻上采样后与保留的同尺度特征图进行融合,最后网络输出表示各个关节点在该像素出现的概率的特征集.
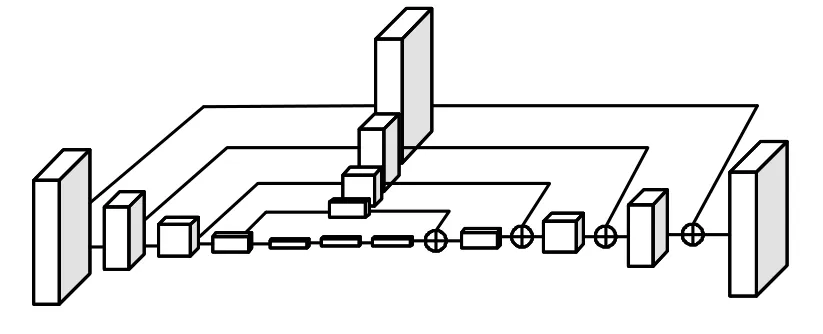
图2 沙漏网络Fig.2 Hourglass network
沙漏网络设计的目的在于获取不同尺度下图像所包含信息,SHN[3]通过堆叠 8个沙漏网络模块,每个模块都添加损失,通过 8个损失共同监督网络训练,利用前一个沙漏网络输出的关节点之间的关系来进行定位预测,从而提高关键点定位的精度.SHN网络在单人关键点的定位任务中取得了非常好的效果,但是这种堆叠结构随着模块数目的增加,模型的性能将难以有较大的提升.在文献[10]中,作者通过实验证明,两个堆叠沙漏网络便能取得非常好的定位效果.
2 服饰关键点定位
2.1 级联卷积神经网络
受背景拥挤、颜色相近、服饰形变较大等因素的影响,各类服饰中往往存在难以精确定位的关键点,为了解决这一问题,本文提出了基于级联卷积神经网络的服饰关键点定位算法.如图 3所示,算法框架分为级联的两部分;第 1部分为全局关键点定位网络,通过特征金字塔融合多尺度特征,实现关键点的初步定位;第2部分以沙漏网络为基础对第1级损失较大的关键点精细调整,进而实现对服饰关键点的精确定位.
本文算法第1级使用ResNet-101作为特征提取网络,将不同层的特征图尺度差异形成的金字塔结构加以利用.如图4(a)所示,特征金字塔结构[16]在网络前向卷积的过程中对每一分辨率的特征图引入后一分辨率缩放 2倍的特征图做逐个元素自底向上相加的操作,以这种方式将 CNN中高分辨率低语义信息的底层特征图和低分辨率高语义信息的高层特征图进行融合,使得融合之后特征图既包含丰富的语义信息,也包含由于不断降采样而丢失的底层细节信息.
金字塔结构中特征图的空间分辨率随着下采样操作而降低,这个过程使得很多在原图中只占有极小的像素区域的关键点的信息丢失.为了解决这个问题,本文算法在特征金字塔结构中引入空洞卷积.空洞卷积在卷积过程中引入扩张率参数r,使得卷积核处理数据时各值的间距为r-1,以扩大感受野.图 5所示分别为扩张率为 1、2、4的空洞卷积示意图,分别产生感受野为 3×3、7×7、15×15,并且尺寸和原图相同的特征图.如图4(b)所示,空洞卷积的引入克服了原始特征金字塔结构中为获得较大感受野而降低特征图空间分辨率的问题,在保证高层特征图较高的感受野和语义信息的同时,保持较大的空间分辨率,从而保留了更多在关键点定位任务中发挥重要作用的细节信息,有效提升关键点定位精度.
如图 3所示,网络首先通过 ResNet进行特征提取,C1~C5分别代表ResNet中Conv1~Conv5产生的特征图.输入一张大小为 512×512的图像,原始的ResNet经过5次步长为2的卷积操作达到降采样的目的,特征图发生 5次尺度变化,最终卷积层输出的特征图 C5的尺寸为 16×16.与原始 ResNet不同,本算法移除了 Conv4和 Conv5中的带步长卷积操作,并分别以扩张率为2和扩张率为4的空洞卷积代替.图 6所示为 Conv4和 Conv5的具体操作,C1~C5各层特征图尺度分别为 256×256、128×128、64×64、64×64、64×64.相比原始 ResNet,引入空洞卷积后高层特征图在保留高感受野的同时,提高了空间分辨率.利用 ResNet提取的特征图构建特征金字塔时,因为特征图 C3~C5具有相同的尺寸,所以可不经过上采样直接融合.融合后的结果与 C2继续融合时,先经过双线性插值进行 2倍的上采样.每一级产生的特征图都生成一组热力图,同组的每张热力图包含输入图像的一个关键点的坐标,和真实关键点坐标生成的热力图进行误差计算求得损失,共同监督网络训练.在测试阶段,第 1级网络输出的热力图可以得到全部关键点的位置坐标.
虽然第1级网络已经能够完成关键点定位任务,但是由于服饰背景、姿态等的复杂性,一些困难关键点依然难以实现精确定位,因此本文算法设计了第 2级网络对困难关键点的坐标进行精细调整.第 2级网络使用两个堆叠的沙漏网络,但与原始的沙漏网络不同的是,第1个沙漏网络的下采样部分即上采样部分的输入是第 1级金字塔结构输出的特征图.针对困难关键点,选择第1级损失较大的关键点进行精细调整,仅从这部分关键点反向传播损失算法.第 1个沙漏网络融合来自第 1级网络所有金字塔层的信息进行定位,第2个沙漏网络利用前一个沙漏网络输出的热力图作为关键点之间的结构先验进行定位.每个沙漏网络都生成一组热力图,并与真值的误差作为损失函数监督网络训练.测试阶段,最后结果为 2级输出结果的综合.
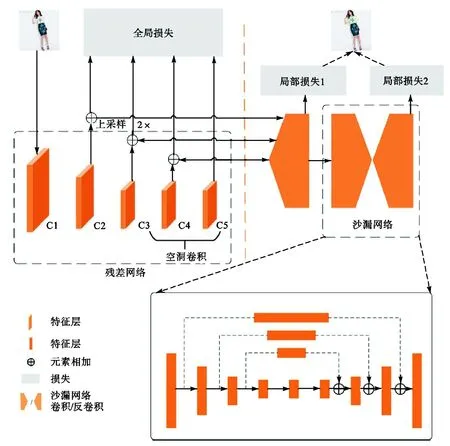
图3 算法框架Fig.3 Algorithm framework

图4 不同特征金字塔结构示意Fig.4 Schematics of pyramid structures with different features
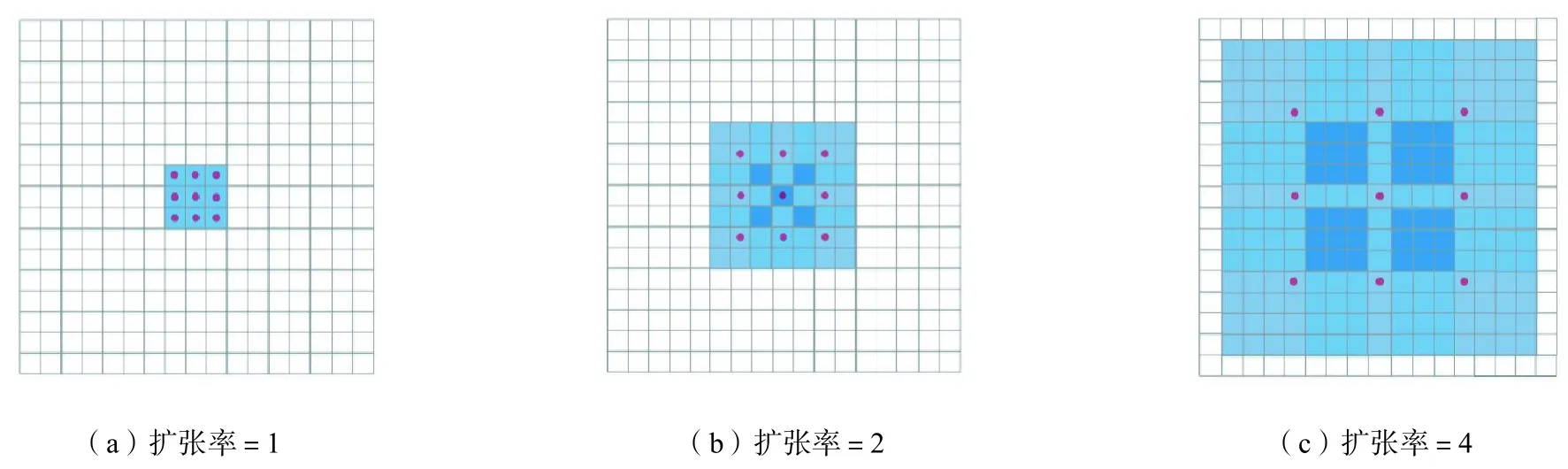
图5 空洞卷积示意Fig.5 Schematic of dilated convolutions

图6 Conv4和Conv5不同卷积方式Fig.6 Different convolution methods used in Conv4 and Conv5
2.2 损失函数
算法第1级的损失函数Global Loss采用所有标注热力图损失Lg,即

式中:yij表示根据真实关键点坐标生成的单张热力图;表示网络学习出的单张关键点坐标热力图;M表示每组热力图的数量,在数值上与输入图像关键点的数量相同;N表示每一次迭代过程中批量数据的大小.
算法第 2级的作用是对第 1级损失较大的关键点坐标进行精细调整,其策略是根据训练损失,进行在线挖掘困难关键点[17].因此,Refine Loss主要对Lg损失最大的P个关键点坐标进行惩罚,即

式中P表示Lg损失最大的关键点热力图的数量,如文献[10],P设置为 8时在困难关键点和简单关键点的平衡训练中达到了最好的效果.同时,类似于SHN网络,为了避免损失经过多层的反向传播而产生的梯度消失现象,在两个沙漏网络的训练过程中,训练其中一个损失时,固定另一个损失,分别独立地进行反向传播.
3 实验与结果分析
3.1 实验环境
实验机器配置为 Ubuntu14.04操作系统,Intel Core i7-8700 CPU,16G运行内存,Nvidia GTX1080Ti GPU,选用的深度学习框架是Tensorflow.在训练过程中,优化算法选用 ADAM;初始学习率设置为 5×10-4,学习率每经过 10轮(epoch)迭代便以 0.5倍进行衰减;权重衰减率(weight decay)设置为 1×10-5,批量数据大小(batch size)设置为 16;特征提取网络 ResNet-101的参数用在 ImageNet上预训练的参数进行初始化,整个模型大约训练45h.
在测试过程中,每一个关键点所对应的热力图中的最高响应到第二高响应方向上的 1/4偏移量的位置作为关键点的最终坐标.为了减小测试误差,从原图生成不同尺寸的测试图,分别进行定位预测,取均值作为最终的测试结果.
3.2 实验数据准备
实验选取 2018 FashionAI 服饰关键点定位数据集,为同时符合机器学习要求和服饰专业性的高质量时尚数据集.本文研究的关键点定位针对女装服饰.服饰的关键点基于服装设计的 5大专业类别定义,分别为上衣、外套、裤子、半身裙、连身裙.在该数据集中,每种服饰具体关键点如图 7所示.本文的数据仅包含单个模特或者商品的图像,所预测的服饰所属的类别已知,不需要单独进行分类,数据集包括54166个训练样本和9971个测试样本.
在原有数据的基础上,本文采用旋转、平移等数据增强方法对训练数据集进行扩充.方法包括:图像随机旋转一定角度(±30°、±45°、±60°、±90°)的旋转变换;图像沿垂直或水平方向翻转的翻转变换;图像在平面上以一定方向平移的平移变换;图像按照一定的比例进行缩小或放大的缩放变换.

图7 数据集中服饰关键点示意Fig.7 Schematics of key points in clothing dataset
3.3 实验结果对比与分析
3.3.1 级联结果对比
本文算法旨在通过级联的两级卷积神经网络分别实现对关键点的初步定位和进一步修正,对于输入网络的图像,每一级网络都有关键点定位结果的热力图输出,两级结果对比可判断网络是否有效.
图8所示为包含上衣、外套类别的4张服饰图像经过级联网络的关键点定位结果图,每张图片的上面一张显示的是只经过第1级网络的结果输出图像,下面一张包含第 2级网络的结果输出图像.图像中的部分关键点经过了调整,尤其是方框圈起来的关键点在第2级网络经过了比较明显的调整,比如第1张图像中的右腋窝和右袖口内关键点,由于被遮挡误差较大;第2张图像左腋窝定位错误;第3张图像左袖口内侧被遮挡定位误差较大;第4张图像右腰部关键点被水印遮挡,经过第2级网络这些关键点都得到了进一步调整,很明显地减小了定位误差,使得最终输出的定位结果更加准确.这一级联结果对比证明了本文算法可提高关键点精确度的有效性.

图8 级联网络定位结果对比Fig.8 Comparison of detection results by cascaded network
3.3.2 不同网络结果对比
整个网络的结果通过统一标准归一化误差率(normalized error,NE)评估,NE 是在考虑可见点的情况下,预测点和标注点的平均归一化距离.

式中:dk为预测和标注关键点之间的距离;sk为距离的归一化参数(上衣、外套、连衣裙为两个腋窝点欧式距离,裤子和半身裙为两个裤头点的欧式距离);vk表示关键点是否可见.
在测试时,首先不区分测试集中的服饰类别并使用不同的网络进行关键点定位预估,与常用的关键点检测网络SHN网络[3]、CPM网络[2]相比,定位精确性效果明显提升,整体误差率分别降低了 5.85%、4.74%,与在关键点定位任务中表现效果较好的 CPN网络[10]对比可发现,算法进一步提升了服饰关键点的定位精确度,将同一数据集的定位整体误差从5.89%降低到 3.56%.除此之外,为了进一步确定和对比网络定位效果,按测试集的5种服饰分类分别对每一类别服饰进行定位预估,对应上衣、连身裙、外套、半身裙、裤子,本文算法与 SHN 网络对比,误差率分别降低了2.19%、8.44%、7.07%、3.08%、5.20%;与 CPM 网络对比,误差率分别降低了 1.72%、6.41%、6.18%、3.03%、5.85%;与 CPN 网络相比,结果误差率分别降低了 0.90%、3.54%、2.39%、0.39%、1.16%,具体结果如表1所示.

表1 不同网络的归一化检测误差率Tab.1 Normalized error of different networks %
不同网络对比实验结果表明,本文算法在服饰关键点定位中取得了最好的结果,通过引入空洞卷积和沙漏网络的级联卷积神经网络相比于现有方法,检测效果提升明显.不同网络检测结果的效果图对比如图 9所示,本文算法的定位结果最接近真实标签,其余网络中的关键点定位存在较大误差,尤其是困难关键点,比如图9中第1组图像(上衣)中与背景较为相似的右袖口外关键点对比,第2组图像(裤子)中被遮挡的左腰部和右腰部关键点对比,不同算法结果差距明显,本文算法表现出了较好的定位效果.

图9 不同网络检测效果对比Fig.9 Comparison of detection results by different networks
4 结 语
本文将人工智能和深度学习引入时尚行业,提出基于级联卷积神经网络的服饰关键点定位方法,旨在进一步提高服饰关键点定位的精确度.该算法在电商、时尚搭配等场景下具有重大商业应用价值,对于电商平台发展和人们生活的便捷性提升有很大的帮助.
本文算法的主要贡献为:①针对关键点定位任务更依赖图像底层细节特征的问题,算法在第1级利用空洞卷积改进特征金字塔结构,在不降低高层特征图感受野的情况下,增大特征图的空间分辨率,从而有效地进行关键点定位;②算法第2级使用两个堆叠的沙漏网络,利用前一级预测出来的关键点之间的结构先验,对困难关键点的进一步调整.在服饰关键点定位任务中,本文算法与 SHN网络、CPM 网络以及CPN网络的对比中取得了最好的结果,有效降低了服饰关键点定位的误差率.
