中医方剂数据挖掘关键算法
2020-01-16吴佳静
文/吴佳静
1 绪论
1.1 课题研究背景及意义
赤峰学院医学专业科研人员从事药学的教学、科研、实验工作,具有扎实的医学理论基础和良好的科研基础,对数据挖掘在医药领域的应用具有一定知识贮备和实践基础。本项目的研究内容、所采用的研究方法和技术路线是在项目申请者和项目组主要成员长期科研工作经验的基础上设计提出的,并与赤峰学院有关医学专业有着良好的专业合作关系,为项目的正常运行打下了坚实的基础。总之,学科交叉和专业融合,为本项目的顺利实施奠定了良好的基础。鉴于中医方剂数据库的复杂性,多样性以及标准化等现实问题,利用数据挖掘技术从事中医方剂学的研究。
2 数据预处理
2.1 数据计量标准化
传统的中医方剂用量药材注重的是用量级数,而不是具体的量化值【13】。 而中医方剂典籍中记录药量多为离散型的量化值,这就给计算机处理带了的难度。 本文中药量的处理采用一种基于聚类一模糊集的药量处理方法。

表1:聚类实例表

表2:冬苓车汤中药量模糊处理结果
采用数据挖掘算法对于统计后的药量进行聚类后,结果为 “高、中、低”三类后,结果示例如表1所示。
模糊集Low 函数模型fL(x):

模糊集Middle 函数模型fM(x):
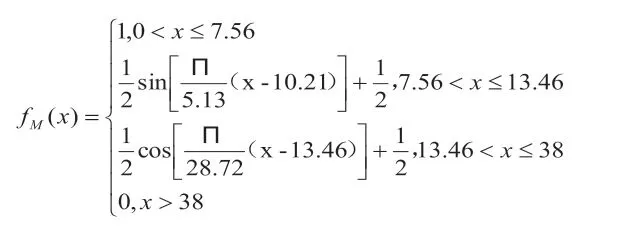
模糊集High 函数模型fH(x):
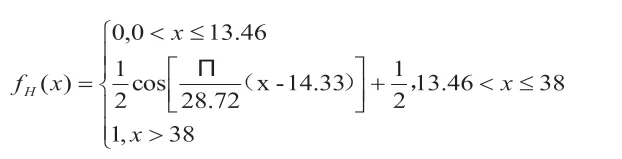
以治疗消渴病的而冬苓车汤为例,处理结果如表2所示。
3 中医药标准化流程与数据挖掘构建方法
3.1 中医药数据标准化流程
大数据挖掘技术由于具有数据易关联、特性,也逐渐被国内医疗界接受。如中国中医科学院中医药信息研究所基于已有的中医药学语言系统的构建中医数据库。本文设计了中医理论数据自动化构建流程 ,基于文本抽取技术 、频繁模式挖掘算法、关系数据到RDF 转(D2R)等一系列信息技术 ,实现了中医药数据标准化的自动构建 。
中医药知识可以看作是一张图 G,由中医药模式图GS、中医药数据图Gd以及和G之问的关R 组成,即 G =< GSGd,R>。模式图GS=<NS,PS,ES>,其中NS表示图中的类节点,PS表示属性边,ES表示由多条边连接的两个类之间的关系,E NS×PS×NS。数据图 Gd=<Nd,Pd,Ed>,Nd表示实例节点和字符节点,Pd表示属性边 ,使用Ed表示由多条边连接的两个节点之间的关系。每条边和边两边的节点都表示一个三元组事实 (主语 、谓语 、宾语)。
3.2 中医药大数据挖掘构建流程
中医药数据挖掘的构建与使用流程主要分以下5 个阶段:
(1)在医学知识范围内的帮助下,根据google 知识体系构建中医数据模式。
(2)信息化模块,将关系数据库中存储的中医结构化信息转化为RDF 数据。
(3)信息收取模块,采用模式挖掘算法,进行数据抽取。
(4)集成模块,对不同来源的中医知识数据进行数据治理,进行规范化匹配。
(5)中医药数据反馈模块,由人工专家解决上一阶段产生的模式层、数据层冲突。
3.3 中医药数据挖掘挖掘算法
为解决传统算法对于中医方剂药物配伍规律的研究中存在的问题和缺点,本文提出了一种基于带权无向图的Top-Rank-k 频繁模式挖掘算法,该算法中釆用DBV 对于权值进行压缩存储,并且结果集中过滤到1-项集和2-项集从而时间挖掘出k-项集3),同时可以有效的挖掘出核心药物组合所对应的方剂名,为中医学研究人员解决中医方剂配伍规律的研宄提供了相应的数据支持。
实验结果对比:WUG_T1C 本文的实验中分别选取了 Q Huynh-Thi-Le 提出的iNTK 和TL Dam 等提出的BTK 与WUG_TK 算法进行了测试,整个过程中生成的有效记录的困难就会增加,从该数据集合中挖掘出 满足k 值条件的结果会增加,从而整个算法代价就会提高。
4 结论
本文结合中医方剂数据特点基础上,采用数据挖掘中高效算法对《中医方剂 大辞典》等中医药古典书籍中收录的治疗消渴病和脑中风的方剂进行研究,构建标准化的中医方剂数据流程,分析方剂中的数据规范问题,有效的筛选出治疗上述症型的代表方。通过上述工作,可以得出以下结论:
(1)通过对方剂信息的收集和原始数据的处理,设计了中医方剂数据库表结构和表的对应关系,从而实现了方剂建模,创建了中医方剂数据体系。
(2)在基于带权无向图的Top-Rank-k 的中医方剂频繁模式挖掘过程中,釆取了DBV的压缩机制对于无向图中的权值进行了压缩处理,但是当处理的中医方剂数 据库比较稀疏时候,对于不同的项可能分散在大量的TID事务中,这就可能造成一定的程度的空间浪费问题,这也是下一步工作重点解决的问题。
