基于细节提取的运动目标追踪算法①
2020-01-15蔡坚勇张明伟卢依宏曾远强
李 科,蔡坚勇,2,3,4,张明伟,卢依宏,曾远强
1(福建师范大学 光电与信息工程学院,福州 350007)
2(福建师范大学 医学光电科学与技术教育部重点实验室,福州 350007)
3(福建师范大学 福建省光子技术重点实验室,福州 350007)
4(福建师范大学 福建省光电传感应用工程技术研究中心,福州 350007)
近些年,由于深度学习的火热,在视频中的运动目标追踪中出现了很多新方法.就追踪任务而言,可分为MOT (Multiple Object Tracking)和VOT (Visual Object Tracking)[1–3].MOT主要是同时追踪多个目标,对抗干扰能力要求不高,VOT则是在干扰条件下持续追踪单个目标.基于监督学习算法的主流目标追踪方法的可分为,生成法和判别法两种.两种方法都是通过数据集训练模型,达到预测结果的目的.不同的是生成法先求出联合概率p(x,y),再通过p(y|x)=p(x,y)/p(x)得到条件概率;判别法则是直接学习条件概率.两种方法得到的条件概率均可转换为目标框中的像素得分.然而对于追踪任务而言判别法效果优于生成法[4],判别法开山之作SiamFC的出现,使得追踪任务取得很大的进展,但是它仍然无法处理多重干扰数据集.本文提出的DPPSiamFC神经网络 (Detial-Preserving Pooling Fully-Convolutional Siamese networks)是对SiamFC网络的改进,可在旋转、快速移动、变形、遮挡和相似性干扰等数据集上取得更好的效果.本文采用的验证数据集是VOT2017 (包含的种类有bag、ball、basketball、birds等40多种类)[5–8].
图1中SiamFC由对称的两个神经网络架构组成,Z代表标注的图片,X为候选图片.在X上计算候选区域和预测区域重叠面积的得分,从而计算出预测精确度,φ通常是若干卷积层和池化层(经典Alexnet采用5层卷积层),网络通过φ函数得到128个通道的特征图,并将两个特征图通过深度卷积进行融合定位视频中目标位置.
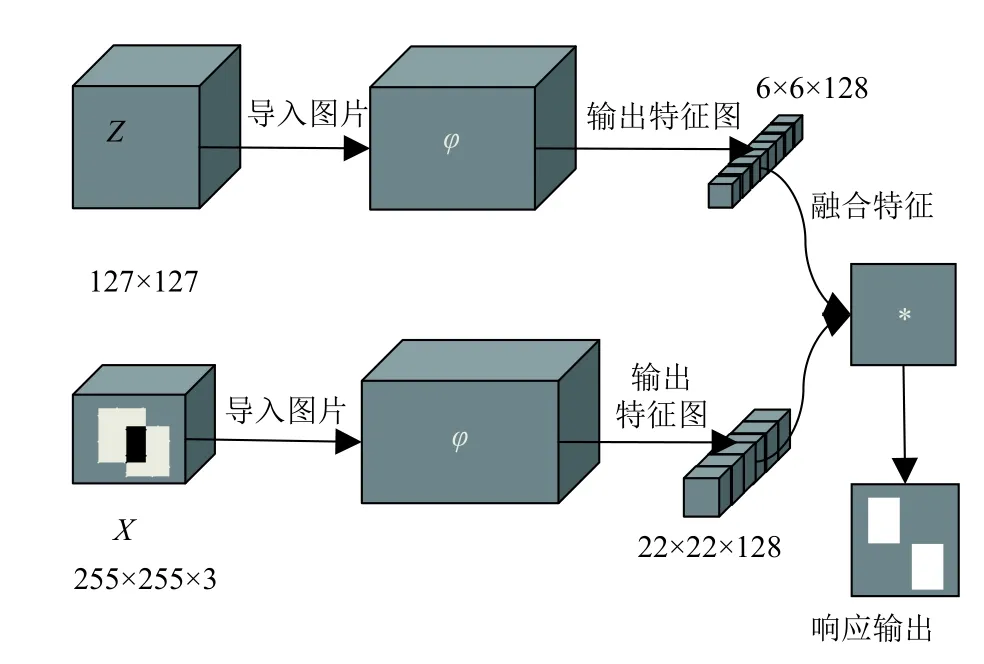
图1 SiamFC网络基础架构
1 视频中运动目标追踪
由于CNN网络在目标检测领域取得良好的效果,能有效记忆目标的特征,所以CNN网络也被引入追踪网络算法中[9].SiamFC网络在VOT2016 (Visual Object Tracking)竞赛中获得良好的比赛成绩,相较KCF(Kernelized correlation filter)有较大的提升,SiamFC在ILSVRC2015数据集上进行训练,训练两条分支的网络参数权重ω和偏置b[5,7,8,10–16].在得到稳定的网络模型后,可进行在线追踪的任务.进行追踪任务时,SiamFC只需要读入初始标定的目标,即可持续在未标定视频中连续追踪特定目标,给出预测的目标位置框,并计算与GroundTruth集合的重叠面积,从而得到预测精确度.
图1中两个孪生的φ在实际网络中可用5层卷积神经网络代替,其中Conv1和Conv2卷积层之后有Pool1和Pool2池化层.两个池化层目的是减少网络参数的个数,但同时也会失去目标的一些细节特征.上述情况在VOT2017数据集上表现尤为明显[17,18].因而对于追踪方法来说,一定的细节保留是必要的.DPP池化层能保留目标物的一些细节特征,对于追踪方法中的一些细节判别和寻找提供一定的帮助.因而我们在每层网络都引入DPP池化层同时又在Conv1和Conv3层之后添加到融合层的残差网络.本文的残差网络解决网络深度增加引起的梯度消失问题,DPP池化层主要解决特征提取时的细节丢失问题[9].
1.1 残差网络
DPP-SiamFC网络不仅在SiamFC网络上每层引入DPP池化层,还引入Conv1和Conv3的池化层之后到融合层的残差网络.残差网络能很大程度将输入的特征引入输出,而并不带来很多网络开销.在网络达到一定深度以后能很好帮助前馈网络,同时降低错误率.SiamFC的Conv1–Conv5层是类似于AlexNet的神经网络.定义f(x)为 输入值,g(f(x))为输入经过CNN网络卷积池化的函数,则加入残差网络进行融合的表达式如式(1)所示:
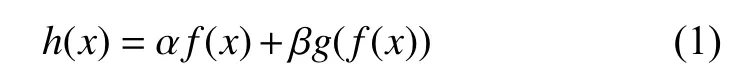
式(1)所示的残差网络将一部分输入特征直接引入网络输出,使得网络的梯度下降的更快,α和 β为调节参数.
1.2 DPP (Detail-Preserving Pooling)细节保留池化
DPP细节保留池化是应用于目标检测的CNN网络Conv卷积层之后的池化层,目的是改善原来CNN检测网络的池化层对目标细节特征的丢失.目标检测比较常用的Avg-Pooling和Max-Pooling分别利用池化区域的平均值和最大值来代替原来的像素点,而在目标追踪领域常用的是Max-Pooling.随着网络层数以及数据集难度的增加,Max-Pooling和Avg-Pooling丢失目标特征的弊端将逐渐展现出来.DPP池化的结构如图2,主要完成线性减少特征图I的数据量.处理流程是将原始特征图I进行线性缩减尺度,将得到的结果与原始特征进行比较(方法是引入逆双边权重),判断出特征丢失程度.输入特征图I经过激励函数得到的输出O特征公式(2):
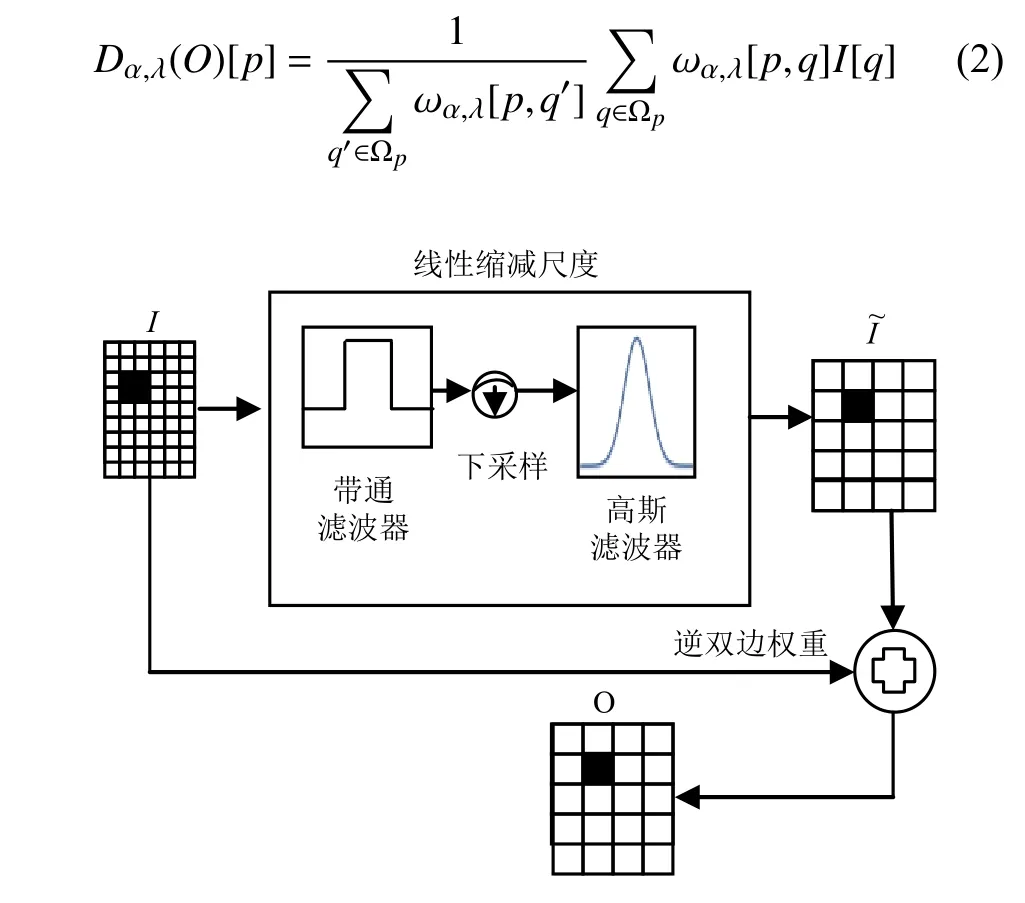
图2 DPP池化层逻辑结构示意图
式(2)计算的是输入相邻点I[q]q∈Ωp的空间加权平均值,作为池化的输出结果.其中I[q]为输入DPP池化层的图片特征图,O[p]为输出池化层的图片特征图,α,λ为神经网络回报参数,是根据不同数据集训练得到的,该逆双边权重公式(为了解决下采样之后特征损失)如式(3):
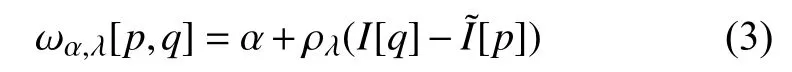
在网络反馈学习中,通过优化 log(α)和 l og(λ)确保参数非负,对于α参数是为了确保输入的特征不被网络训练完全清除,保存细节特征,并最后作用于输出结果.λ为调节奖励函数形状的参数.对于I[q]>[p]时采用非对称的作为奖励函数.反之采用对称的作为网络的奖励函数(ε是修正因数,减少x的浮动带来的影响,使函数图像从0开始).
2 DPP-SiamFC网络架构
2.1 网络架构
本文为了实现视频中目标相似性干扰、旋转、快速移动、遮挡和变形等问题处理能力.对SiamFC网络进行改进,改进之后的网络结构如图3,融合网络(Concatenation)是3条分支的加权平均值,再通过深度卷积层对特征进行融合.

图3 DPP-SiamFC网络架构
Conv和Conv_1是对称的卷积层,它们卷积核大小,通道数和步长并不相同,相同的是两个卷积层使用的卷积核的个数.这使得输出特征图的个数一致.DPP池化层的结构如图2所示,目的是更好的保留目标细节特征.
Fully-Convolution是将两个分支的结果进行卷积处理,生产下一帧的目标位置,从而得到最终的特征输出.
2.2 DPP-SiamFC网络各层参数
DPP-SiamFC网络各层参数并不相同,其中DPP层提供ΩP,,ε三 个参数.其中ΩP通常取3×3相同如,ε=0.1,则网络的各层参数如表1所示.
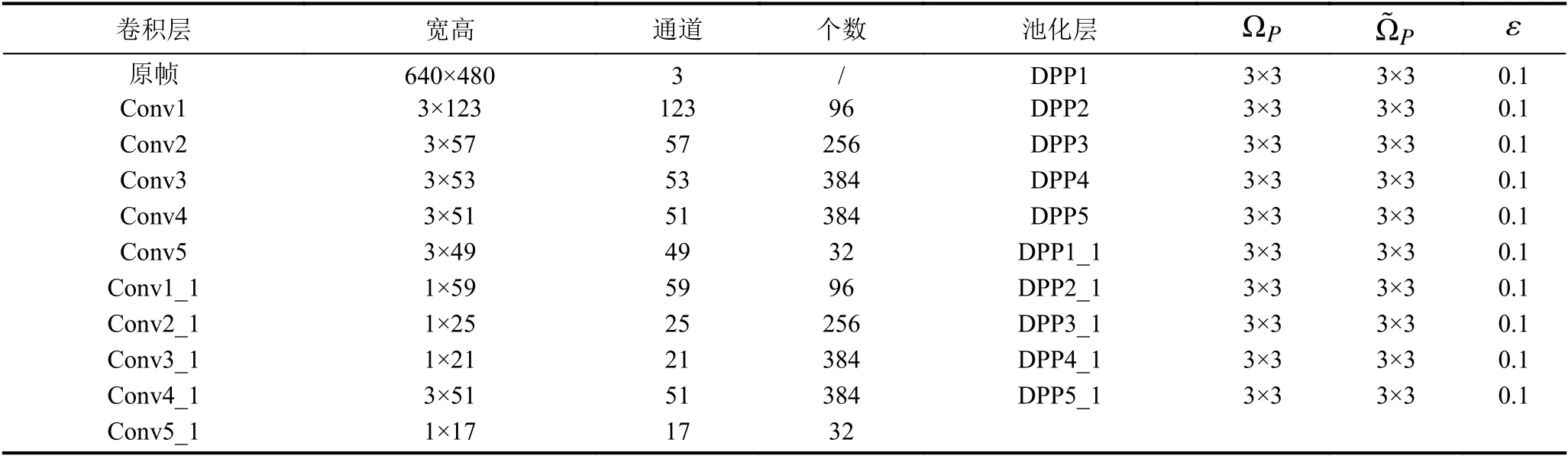
表1 DPP-SiamFC网络各层参数
3 实验分析
我们将DPP-SiamFC网络于ILSVRC2015数据集上进行训练,实现对每个分类特征的离线训练.在线追踪于VOT2017追踪数据集,观察在各个分类追踪的效果[19–21].
3.1 运动目标追踪
实验展示DPP-SiamFC在VOT2017各个分类效果,尤其在含有复杂背景,有众多干扰物、遮挡、快速移动、和目标变形的数据集.
3.2 DPP-SiamFC与经典网络实验效果对比
图4展示了DPP-SiamFC在有很多干扰物且存在部分遮挡条件下追踪单个目标物的效果,整个视频的标定区域和预测区域重叠面积比平均约为79.1%,高于80%预测精度的视频帧约占总数的83%.
图5是DPP-SiamFC在目标快速移动任务中效果.该数据集是摩托车比赛,途中有树木的遮挡.

图4 groundtruth(蓝色)、DPP-SiamFC(红色)、KCF(相关滤波算法黄色)和SiamFC(绿色)在相似物干扰数据集的效果
图6是目标形变,和背景复杂的夜间街道数据集中DPP-SiamFC追踪效果.追踪效果较为良好,能实现对目标持续追踪的目的.
如图7所示SiamFC很难追踪快速上升并旋转的特技摩托.而DPP-SiamFC能很好的将目标捕捉,达到旋转物体追踪的效果.
通过图8中SiamFC、DPP-SiamFC和KCF算法预测区域和groundtruth标定的重叠面积比(IOU)在60个追踪数据集上的平均精确度(例如:图8中KCF'表示KCF算法在60个数据集上的精度平均值)78%,87%,70%(如表2)可以看出,改进之后的DPPSiamFC神经网络在大多数数据集上效果优于SiamFC和KCF网络,本文在SiamFC网络中引入DPP池化层和残差网络能很好保留数据集上的细节特征,提升在追踪任务中的准确度,但在综合的任务数据集中稳定性还需提高.

图7 groundtruth(蓝色)、DPP-SiamFC(红色)、KCF(相关滤波算法黄色)和SiamFC(绿色)在摩托车特技比赛中的对比
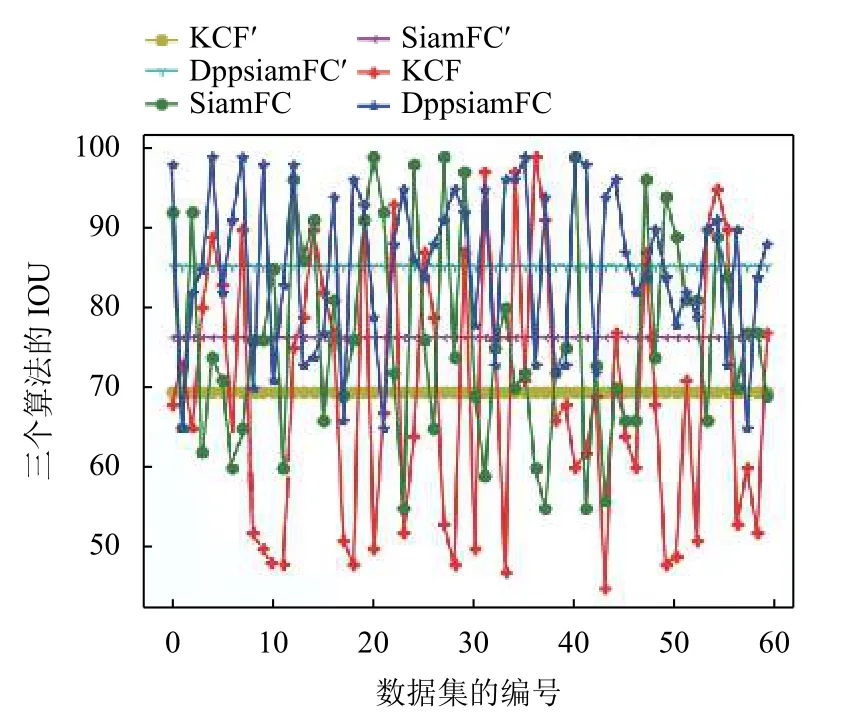
图8 SiamFC、DPP-SiamFC和KCF的IOU比较
4 结论与展望
实验结果证明,通过在SiamFC孪生网络上引入DPP池化层和残差网络,有利于网络细节特征的保留,在VOT2017追踪数据集中DPP-SiamFC有更高精确度,同时在背景复杂、物体变形、快速移动、遮挡等数据集中目标追踪有一定改善.但是在多重任务追踪集的效果还有待提高.今后我们的工作将致力于网络与数据集之间的对抗性研究.

表2 SiamFC、DPP-SiamFC和KCF精度比较 (单位:%)
