新浪微博签到的社交地理大数据获取与处理技术研究
2020-01-14孙国平耿继原
孙国平,耿继原
(1.沈阳市勘察测绘研究院有限公司,辽宁 沈阳 110004; 2.辽宁工程技术大学,辽宁 阜新 123000)
1 引 言
社交网络平台的存在使得感知不同社会群体的周围物质环境和社会环境成为可能,在现实世界中,人们通过自身的感知来体验周围的环境,它支配了人类的行为。根据认识论原则,感知通常是对某种既定事实的认知。感知可以了解自身拥有的信息,为自己下一步的判断和行为提供参考。它包括以下三层含义:感知是随环境而变化的知识;感知是通过环境中收集到的信息来实现的;感知是为了某一目的而服务的一种手段。利用社交网络数据感知人类社会的物质和社会环境,可以被称作一种“遥感”。如何获取与处理社交媒体地理大数据,成为众源地理空间数据分析与挖掘领域的主要任务。因此,透过空间数据分析与挖掘方法分析用户行为的首要任务便是社交媒体地理大数据的获取和处理,针对此问题本文以新浪微博数据为例进行研究。
2 数据获取
2.1 社交地理大数据获取方法
常见的社交地理大数据的获取方法分两种,网页爬取和使用社交服务商提供的开放数据接口获取。在服务商没有对外开放提取数据的接口的情况下,网页爬取是最有效的获取数据方法,如人人网、Flicker和Facebook等。网络爬取的不足之处是常被网站的反爬取技术所屏蔽,因此需要频繁地更新爬取代码,同时爬取数据存在很多重复的页面和垃圾页面,清洗工作量较大。与网络爬取相比,在服务商提供开放数据接口的情况下——如新浪微博服务商,这种开放接口允许第三方开发者通过得到应用的授权来获取数据,能够有针对性地获取数据,减少后期数据清洗工作量,并且不用担心反爬取技术的屏蔽,编程接口的变动相对稳定,也减少了代码维护工作。下面以新浪微博签到数据为例,阐述社交地理大数据的获取方法。
2.2 基于微博API的签到数据获取
新浪微博开放平台提供的应用程序编程接口(Application Programming Interface,API),该平台目前开放了将近200个数据接口,包括微博内容、评论、用户等数据访问接口,API日均调用量达到330亿多次。开放平台为开发者提供了多种流行语言的软件开发工具包,包括Python、C++、PHP、Java等。
新浪微博API调用流程如图1所示。
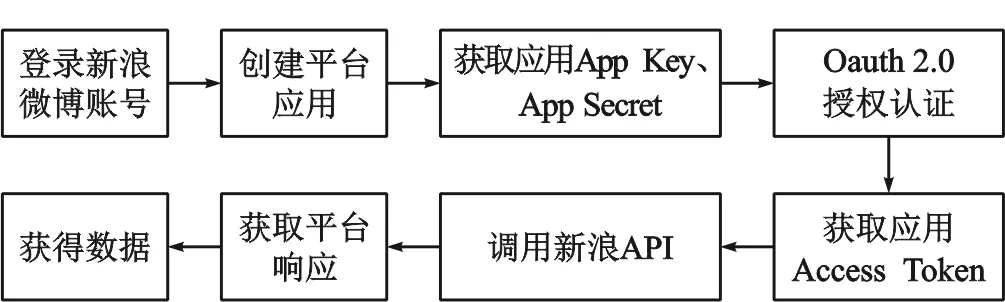
图1 新浪微博API调用流程
新浪微博API的接口中“位置服务接口”为第三方提供基于“位置服务”与“兴趣图谱”的多维度位置服务。以获取附近地点API和获取某个位置地点的动态API结合,以poiid作为两个API的连接点,获取带有时间和微博用户发布的文本数据。poiid是指POI的id,POI是点数据,它真实地理实体的空间信息和属性信息,例如经纬度、名称等。首先通过获取附近地点API,获取签到数据的poiid,得到每个签到地点的签到次数和签到用户数,以poiid为获取某个位置地点的动态API的必要参数,获取带有签到时间、微博文本等属性的签到数据。获取附近地点API签到数据样例如表1所示。
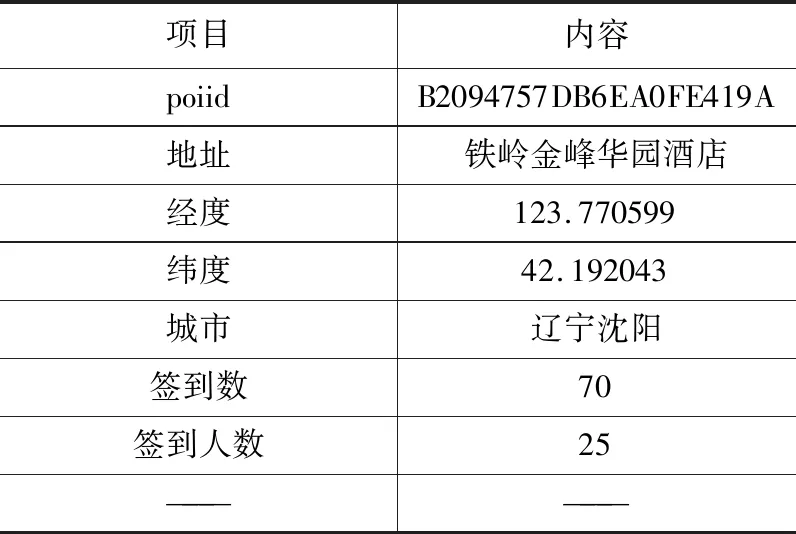
获取附近地点API签到数据样例 表1
2.3 研究区域格网化的并行算法
为了提高获取签到数据的效率,在提取研究区域的poiid值时,设计提取数据的并行算法,对研究区域网格化,研究区域非规则的正方形,划分后,为200行×200列共4万个矩形格网单元。根据区域内最小外接矩形的左上角、右下角、格网单元的行列号得出每个格网单元的质心坐标,通过设置半径,得到签到数据。
格网的划分以及局部放大视图如图2所示。

图2 格网划分及局部放大视图
图2中,(X1,Y1)表示研究区域MBR的左上角坐标;(X2,Y2)表示研究区域MBR的左上角坐标;DX、DY表示研究区域MBR的宽度和高度;Dx、Dy表示格网单元的宽度和高度;(GXmk,GYkn)表示格网单元的质心坐标。
为了方便利用计算机进行迭代计算,将格网单元质心坐标的计算方法归纳如下:
其中,m=1,2,3,…,l;p=1,2,3,…,l;k=2,3,4,…,l;△X=|X2-X1|、Y=|Y2-Y1|;△x=△X/200、△y=△Y/200。
利用上述迭代公式同时可以计算出格网单元的宽度和高度,取宽度和高度二者中较大值为查询范围半径。为了能全面覆盖格网单元,并且相邻格网单元之间要有适当的重叠度,本例取查询半径为 250 m。
3 签到数据处理
3.1 数据预处理
在数据获取阶段收集到的原始数据是“脏”的,存在混乱结构不一致、冗余或重复、属性数据的缺失等问题,具有模糊性、不完整性和冗余性等特点,使得数据的预处理成为数据挖掘前期准备的必要工作,从而保证数据的正确性,可靠性,完整性。
原始数据为Json格式,此格式对机器友好但并不适合人类阅读操作,因此需要对其进行解析。将属性信息以逗号间隔,并存储在.txt格式文件中。以逗号为分隔符有利于之后在Excel的单元格中展开数据,而且.txt格式文件能够被大多数数据分析软件导入。要针对时间序列数据进行分析,需从原始数据中提取带有签到时间的数据,共采集2012年~2016年5年新浪微博地理大数据,从中精选3年完整空间地理数据,分3年保存在3个txt格式文件中,时间包括2013年、2014年和2015年的微博位置签到数据。
本实验选择在ArcGIS中自定义Spatial ETL工具批量删除重复数据,从源数据中抽取出有用的数据。处理前与处理后的数据质量如表2所示。
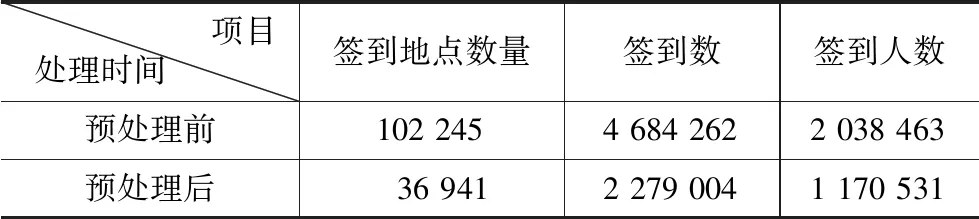
数据处理前后对比 表2
3.2 时间序列数据的处理
时间序列数据指某个指标根据时间的先后顺序排列而成的在不同时间点上的数值数列。在此试验中,时间序列数据就是同一区域(即poiid相同)的有时间变化的签到数据。
在调用获取附近地点API和获取某个位置地点的动态API后,得到带有时间属性和微博文本等内容的签到数据,以逗号间隔,保存到Excel表格。如一条时间序列数据,在Excel中展开,在python中编写代码完成时间格式的转换;在poiid相同的情况下,存在不同的签到时间,需转换为北京时间分析处理。
3.3 微博数据语义信息的处理
从已获得的签到数据中提取出含有文本信息的签到微博来作为语义分析的数据。数据以Excel表格形式存储。由于微博数据来源多样、形式不一、文本不规范等特点,对于提取到的原始语义数据还需进行数据处理来清洗和归整数据。
基于语义分析的研究并不局限于文本信息,还可以利用非文本信息,如地点标签、签到用户类型、评论数等关联签到位置来更好地进行人类行为模式的研究。
4 签到数据的描述性统计
描述性统计是通过数据的收集、加工处理、显示等来概括和分析数据的分布特征。描述性的指标包括均值、方差、直方图、偏度、峰度等。
经过数据处理,局部放大图(铁西区)如图3所示。由图片可以看出,铁西区随着“铁西广场”商圈的建成,逐渐成为热点区域,离地铁线越近的地方签到数量越多。

图3 局部放大图(铁西区)
图4为2015年某一天的签到次数统计,从中可以得出,从早上5:00开始,数量一直在增加,6:00~9:00、17:00~23:00直线增长,在23:00以后~6:00之前呈现明显下滑趋势,曲线整体描述符合人们一天活动的规律:6:00以前为晚间休息,所以签到数量一直在下降;6:00~9:00为早上上班时间,签到数量直线增加;11:00~14:00为午休,签到数量增量趋缓;17:00以后为下班时间(“自由活动时间”),签到数量也直线增长。

图4 2015年某天签到次数统计
5 结 语
社交地理大数据反映了用户在特定的时间、地点条件下记录的所见、所闻、所感、言论以及状态。这些发生在用户身边的事件能够通过发布包含文字、图片、视频等内容的签到功能记录下来,并在以用户为中心的关系网络中快速传播。本文以新浪微博的签到数据为研究对象,通过相关技术获取和处理签到数据,并对其进行描述性统计,为分析和挖掘签到数据做好基础,进而了解到用户群体的特征,例如年龄性别、学历层次、空间分布、兴趣爱好等,根据这些结论和知识为用户提供个性化的服务。
