多任务约束条件下基于强化学习的水面无人艇路径规划算法
2020-01-14封佳祥江坤颐袁志豪
封佳祥,江坤颐,周 彬,袁志豪
(哈尔滨工程大学水下机器人技术重点实验室,黑龙江 哈尔滨 150001)
0 引 言
水面无人艇在海洋科研、海洋开发和军事领域具有极其广泛的应用前景,已经成为国内外智能化装备的研究方向之一。环境感知与路径规划是无人艇完成任务的重要部分,也是无人艇执行任务的基础。无人艇依据环境感知信息自主完成路径规划的能力,体现了无人艇的智能水平。
随着人工智能领域的发展,强化学习在路径规划领域得到了应用。M.C.Su 等[1]提出将强化学习加入路径规划的理论。G.Tan 等[2]提出基于 Dijkstra 算法的强化学习路径规划的理论。T.L.Lee 等[3]提出未知环境下移动机器人的模糊运动规划方法。Z.Hong 等[4]提出基于分层强化学习的路径规划的方法。Y.Song 等[5]提出一种有效的移动机器人Q 学习方法。强化学习在机器人路径规划中的的应用已经有较多的研究,而在无人艇领域的研究较少,并且当前对于无人艇路径规划的研究,大都是以寻找最短的无碰路径,而对无人艇执行任务过程中,任务约束条件下的路径规划研究几乎没有。
针对海上环境的特点,本文提出一种利用灰色预测辅助区域建议神经网络的水面目标检测方法,快速准确地获得海上无人艇的任务环境信息。以Maritime RobotX Chanllenge 比赛中的任务为背景,提出一种多任务约束条件下基于强化学习的路径规划算法。依据任务条件,以获得的任务感知信息为输入,通过强化学习训练,使无人艇能够在随机起始状态下,寻找到完成任务的最优路径,并通过仿真试验和实船试验对其进行验证。
1 强化学习
强化学习是一种基于环境交互的学习算法,强化学习的过程如图1 所示。强化学习可以简单描述为:智能体处于某个环境中,通过感知系统感知到当前的环境状态,并在该环境状态下采取某个动作,作用于该环境状态,当前的环境状态按照某种概率转移到另一个状态,同时环境也会根据潜在的奖赏函数反馈给机器一个奖赏值。强化学习的目的就是使智能体获得的累计奖赏值最大。
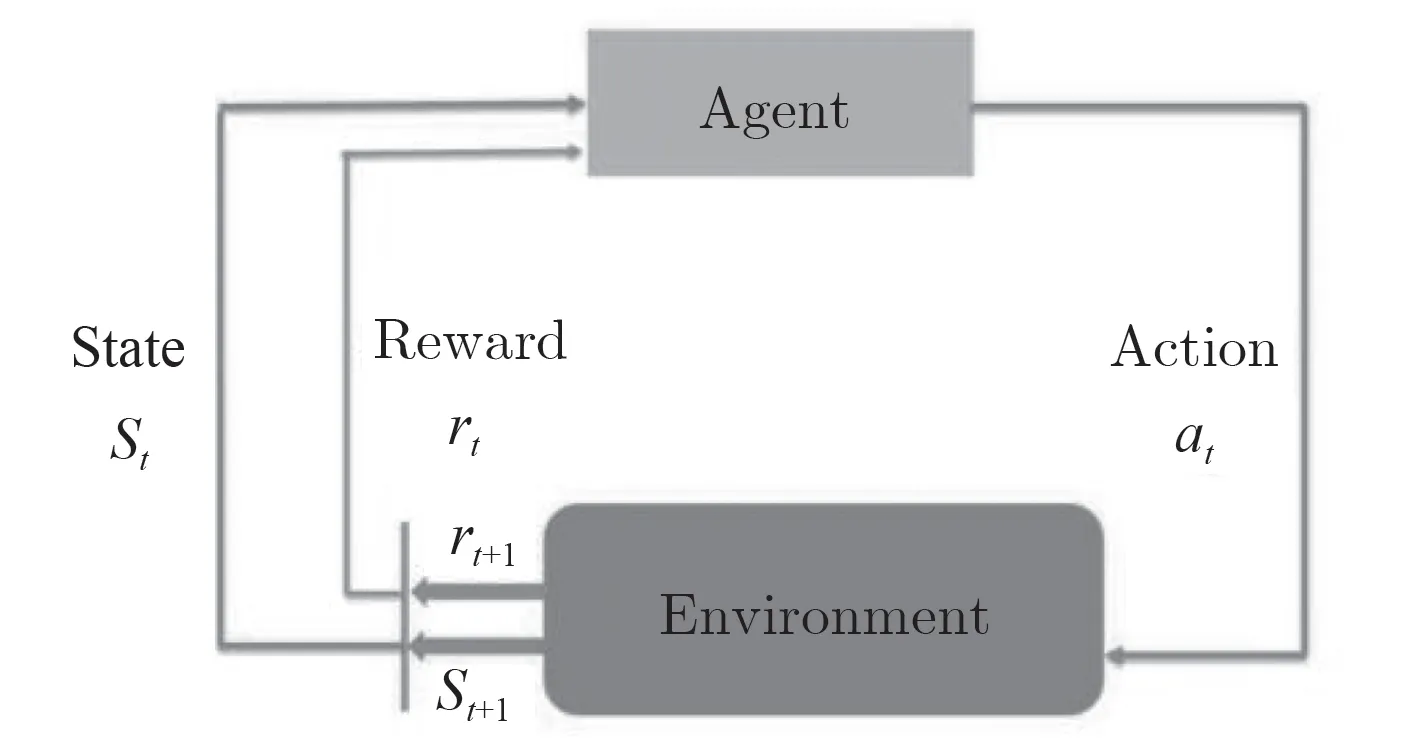
图 1 强化学习示意图Fig.1 Schematic diagram of reinforcement learning
Q_learning 是一种行之有效的强化学习方法。Q_learing 算法通过训练得到Q-table,Q-table 代表了智能体学到的知识。探索环境(environment)之前,Q-table 会给出相同的任意设定值(大多数情况下是0)。随着对环境的持续探索,这个 Q-table 会通过迭代地使用动态规划方程更新来给出越来越好的近似。
Q-table 的递归方程形式如下:
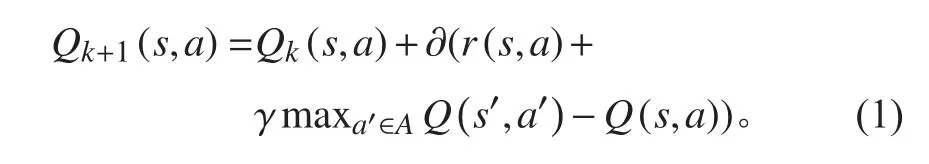
式中:r(s, a)为在s 状态下采取a 行动所得到的奖赏值;s′为s 状态后的下一个状态;∂为学习率,代表学习知识的程度,∂∈[0,1];γ 为折扣率,代表考虑未来报酬的程度,γ∈[0,1]如果γ 越接近于0,智能体更趋向于仅仅考虑即时奖励;如果γ 更接近于1,智能体将以更大的权重考虑未来的奖励,更愿意将奖励延迟。
2 多任务约束条件下基于强化学习的水面无人艇路径规划算法
2.1 任务约束条件
本文水面无人艇执行的任务以Maritime RobotX Chanllenge 国际水面无人艇比赛中的基础过门任务和避障任务为背景。
基础过门任务描述如图2 所示。无人艇必须依靠导航和感知信息全自主无碰撞通过2 组红绿浮标(图中深浅)表示。其中红色浮标和绿色浮标的距离约为10 m,两组红绿浮标间的距离约为30 m。该任务的约束条件为无人艇能够从开始门进入,从结束门出去,且不能够碰撞浮标,不能够从2 组红绿浮标间穿过。
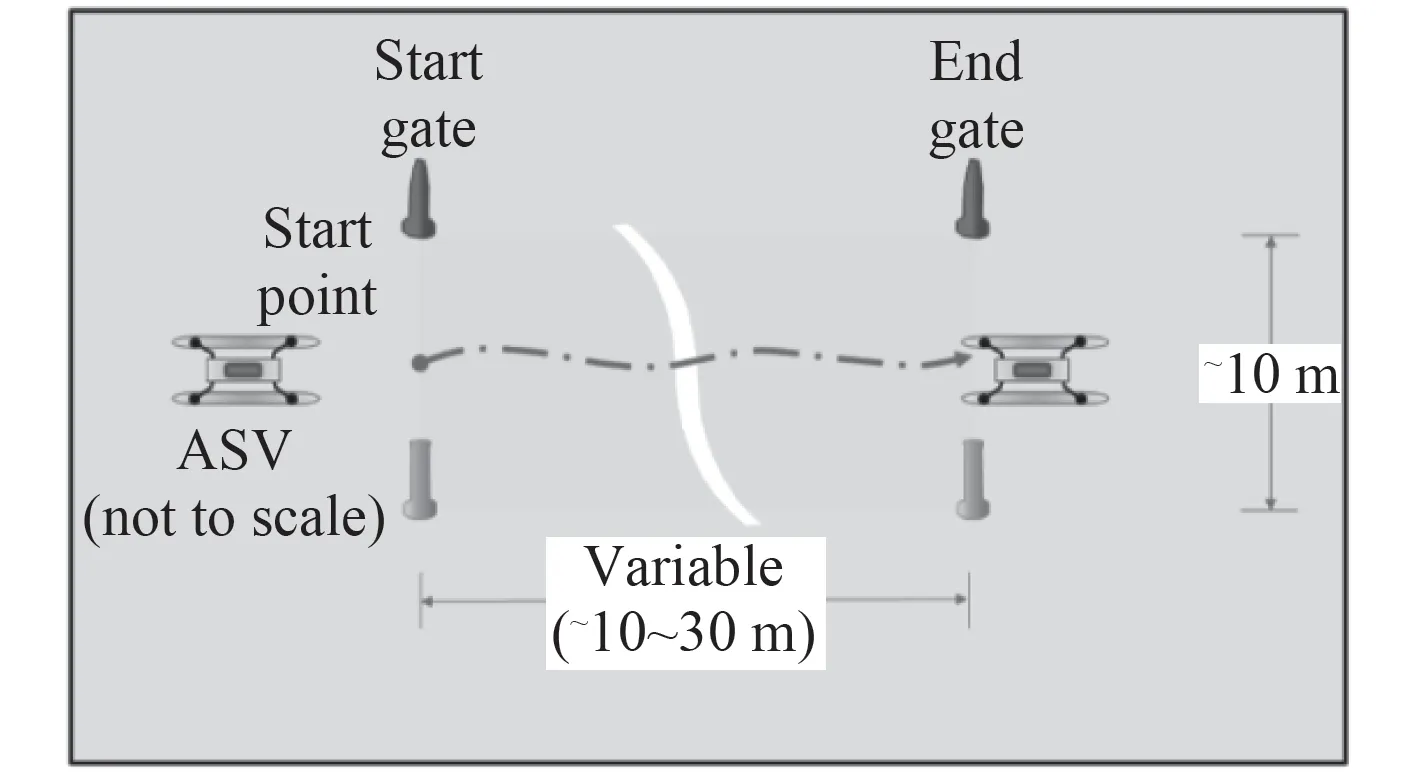
图 2 基础过门任务示意图Fig.2 Schematic diagram of task of entrance and exit gates
避障任务描述如图3 所示。无人艇必须依靠导航的感知设备自主穿过障碍物区域,且不能够碰撞任何障碍物。障碍物的直径约为1 m。该任务的约束条件为无人艇能够以最短路径穿过障碍物区域,并且不能够碰任何障碍物。
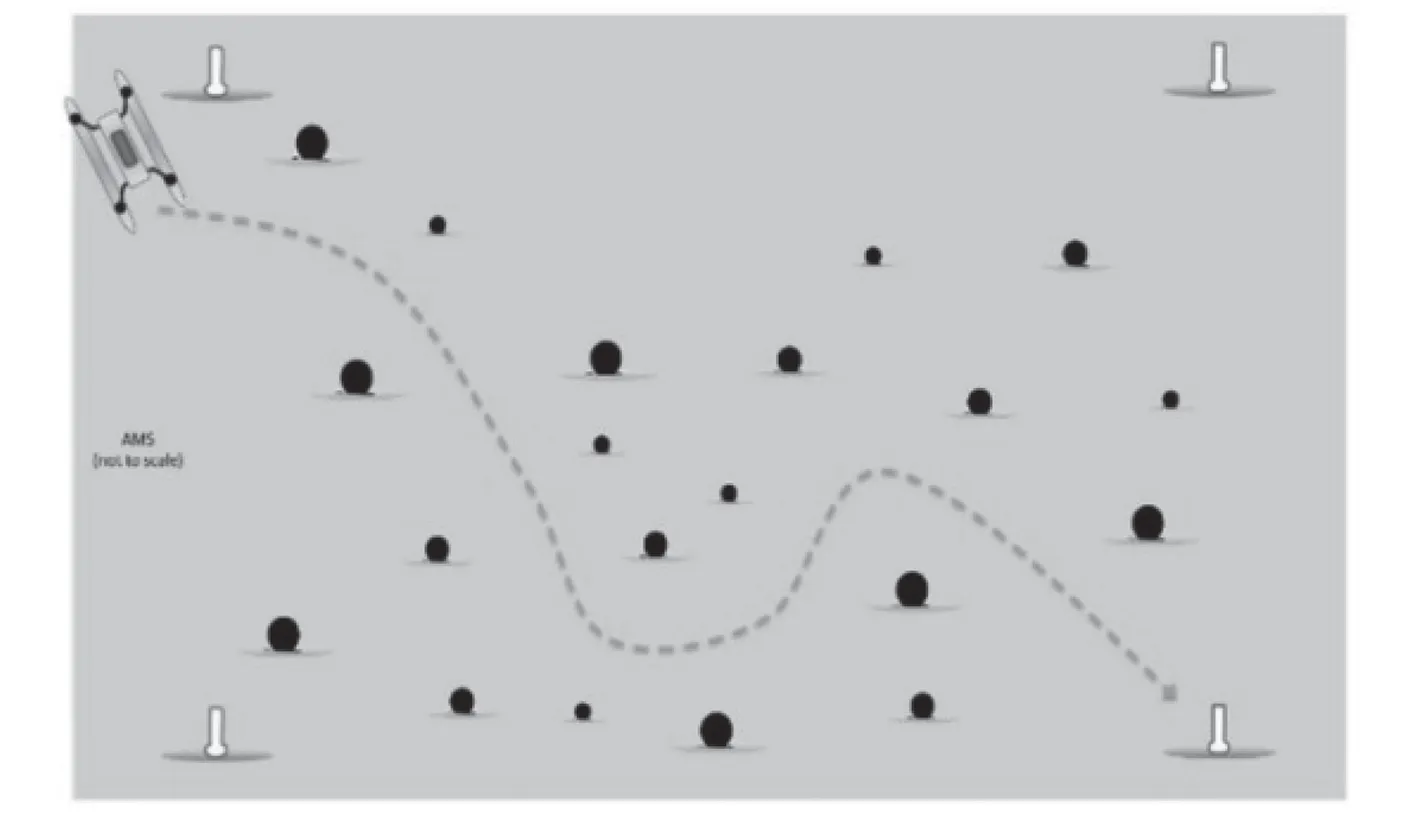
图 3 避障任务示意图Fig.3 Schematic diagram of task of avoid obstacles
本文将2 种任务融合在一起,在基础过门任务的红绿浮标外侧布置障碍物,无人艇从起点出发,穿过障碍物区域,并且完成基础过门任务。
2.2 环境建模
在执行路径规划算法之前,首先需要将水面无人艇周围的环境信息表示出来。由任务描述可知,要完任务水面无人艇必须能够准确分辨出浮标和障碍物,并且能够得到浮标颜色及浮标和障碍物的准确位置。为了在有风浪流等干扰因素的复杂环境下快速准确得到水面目标信息,本文提出一种利用灰色预测辅助区域建议神经网络的水面目标检测方法。在得到任务信息及目标信息后,采用栅格法表示环境。
2.2.1 利用灰色预测辅助区域建议神经网络的水面目标检测方法
利用灰色预测进行区域建议,提升神经网络检测连续视频帧中水面目标的速度和准确率,具体流程如图4 所示。
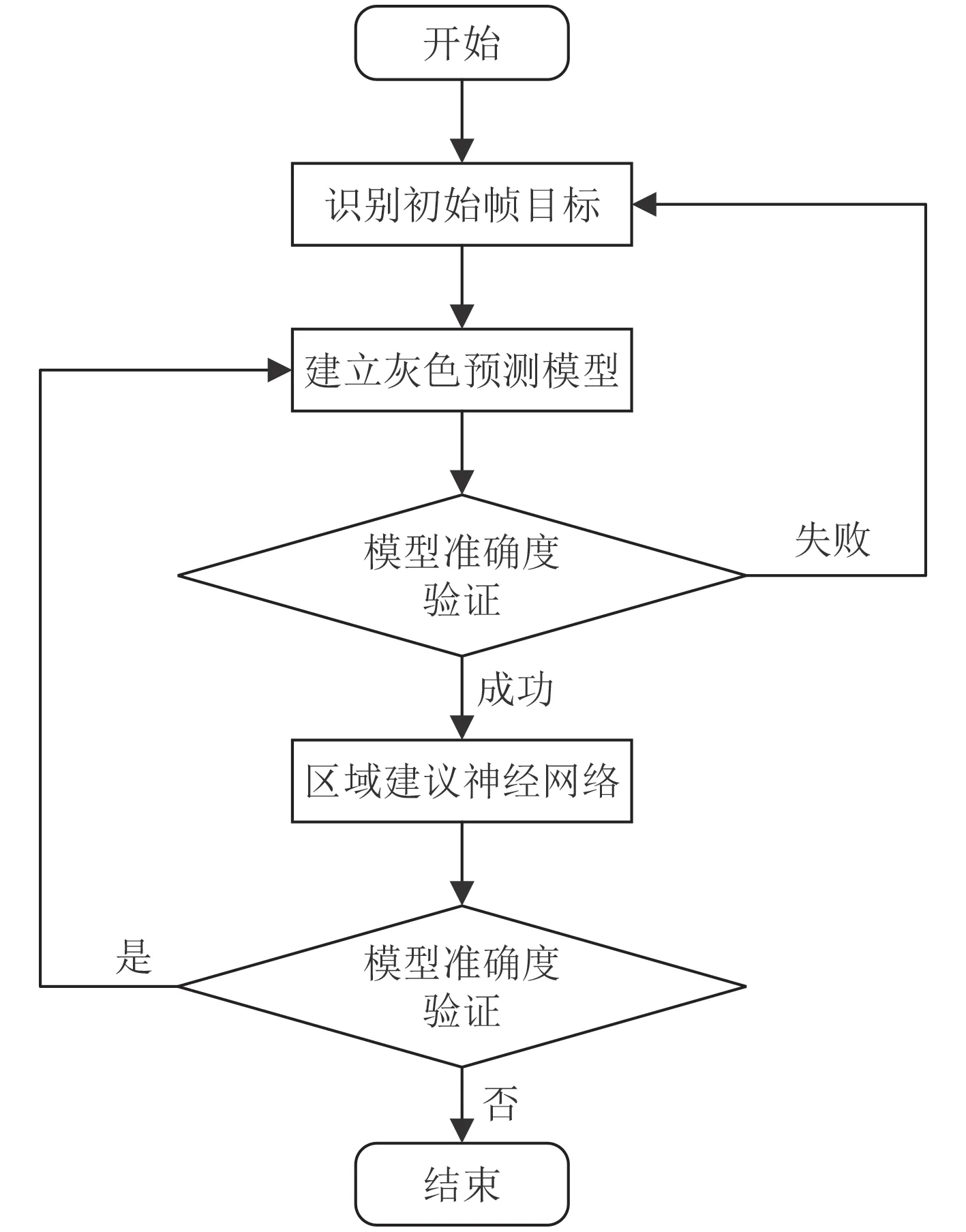
图 4 算法流程图Fig.4 Algorithm flow chart
水面目标多出现在样本图片中的水天线附近,且连续视频帧间同一水面目标在视频帧中的位置存在内在联系。本文提出的方法利用这一特点,使用灰色预测与海天线检测布置锚点和候选框,辅助Faster RCNN 网络识别水面目标,提升水面目标识别的快速性和准确性。
利用经典的Faster RCNN 方法识别水面目标,并记录下目标识别框中心点在视频帧中的像素坐标(u, v),设置采样时间间隔t=0.2 s,采样帧数为5 帧。
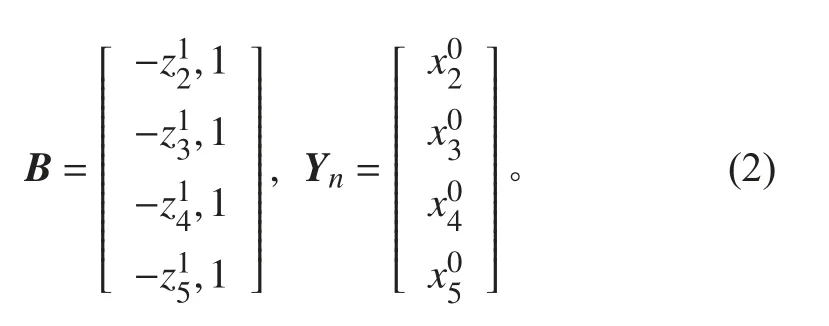
利用初始目标帧中的采样信息建立灰色预测模型,其初始元素序列数据为其中分别为第k 帧采样帧中目标识别框的中心点横坐标u;对 X(0)做 一次累加生成得到序列其 中,令为的紧邻均值生成序列,其 中建 立G M(1,1)的灰微分方程模型为,其中a 为发展系数,b 为灰色作用量。灰微分方程的最小二乘估计参数列满足,其中:
建立灰色微分方程的白化方程,求其解并做累减还原可得最终预测结果如下:
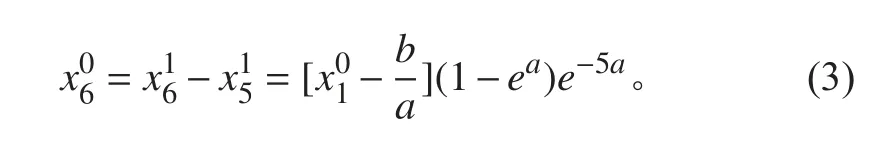
即为灰色预测得到的下一视频帧中水面目标识别框的中心点横坐标。
对计算得到的灰色预测模型相对残差 ε(k)进行检验。

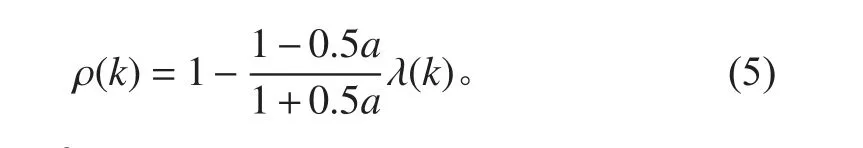
改进经典Faster RCNN 神经网络结构,利用灰色预测的结果进行区域建议。改进后的Faster RCNN 网络结构如图5 所示。首先使用海天线检测获取视频帧中海天线的位置,随后在海天线上、灰色预测获取的水面目标横坐标附近按照高斯分布布置锚点,在每个锚点处仍然选用3 种大小与3 种长宽比的共9 种候选框,将这些候选框输入区域建议网络(Region Proposal Network,RPN),使得区域建议更加精确。另一方面,得益于精确的区域建议和较单一的背景特征,精简特征提取网络层数,使用VGG13 网络代替VGG16网络,提升网络运行速度。随后进行池化,目标分类与边界框回归操作,获取最终的检测结果。
判断是否检测到目标。若检测到目标,则利用新息对灰色模型进行实时更新,防止模型预测结果随时间发散,然后利用新模型重新进行预测和检测。若没有检测到目标,说明水面目标可能已经离开视野或预测不准确,此时应停止本次检测过程,将新息作为目标初始帧,重新开始下一个检测过程。
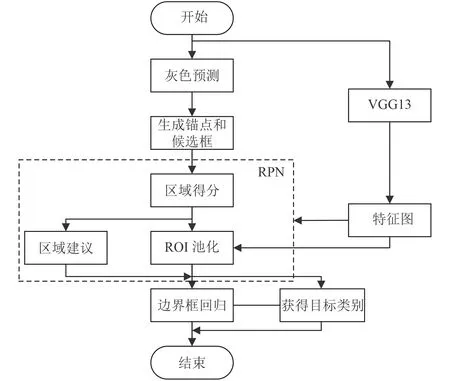
图 5 改进Faster RCNN 算法网络结构图Fig.5 Improved Faster RCNN algorithm network structure diagram
2.2.2 环境模型
依据得到的任务信息和感知信息建立环境模型,本文建立多任务环境模型。由于无人艇在航行过程中自身位置是连续状态的空间,而连续性的高维状态空间会使强化学习算法难以收敛,需要将无人艇环境状态空间离散化。在Maritime RobotX Chanllenge 水面无人艇比赛中,水面无人艇任务区域一般为40 m*40 m,该区域一般在无人艇的感知范围之内,考虑到无人艇的航行性能,并且使状态空间尽量合理,本文将任务区域划分为40*40 的栅格区域。
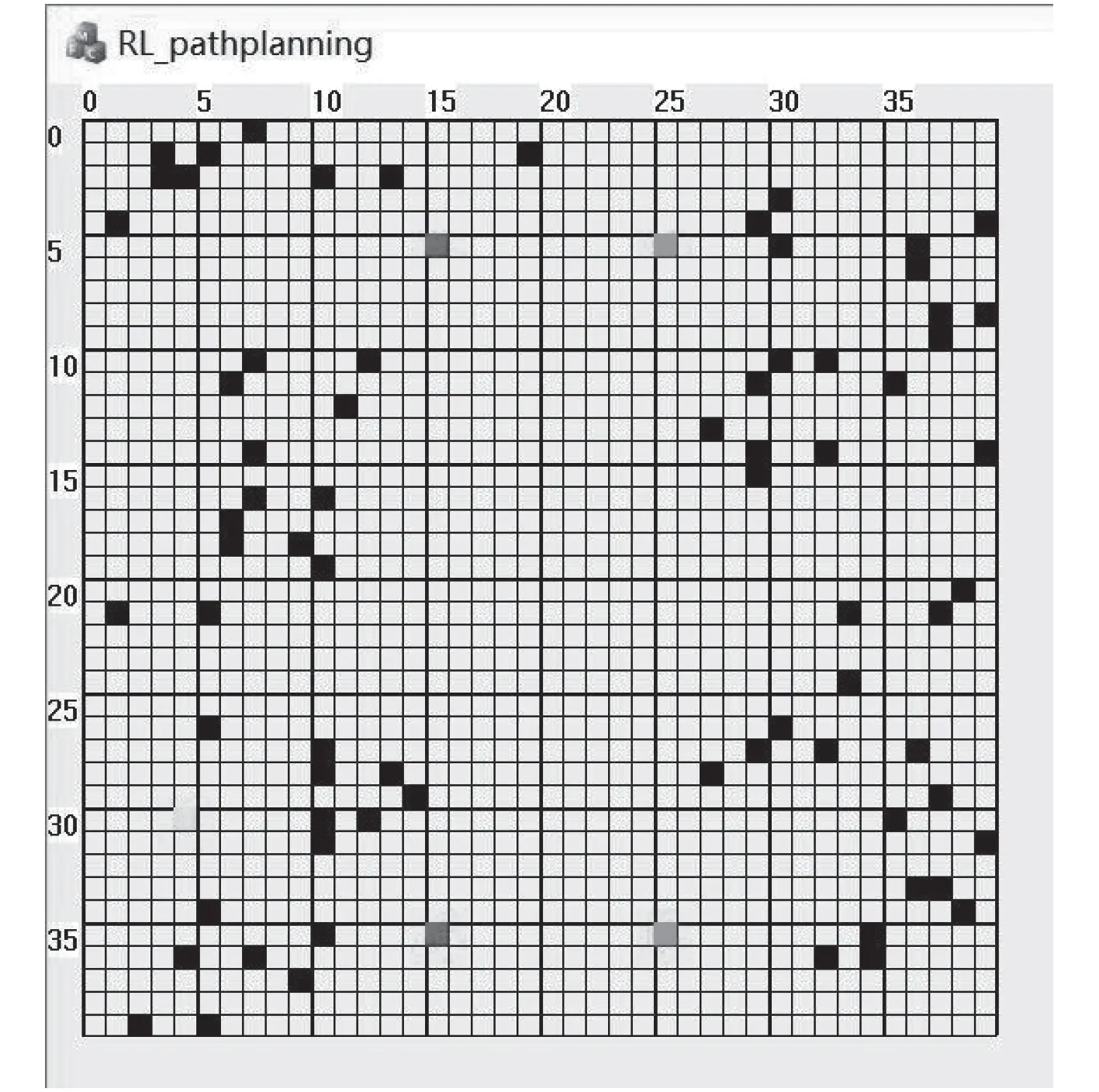
图 6 多任务环境模型Fig.6 Environment Model of multi-task
以得到的门的浮标位置为中心建立栅格环境模型,如图6 所示。图中深灰浅灰栅格表示感知信息检测到的门浮标位置,上边的门为入口门,下边的门为出口门。黑色栅格表示障碍物区域,黄色栅格为无人艇起始位置。
2.3 基于任务分解奖赏函数的Q_learning 算法
依据水面无人艇所要执行的不同任务设计不同的奖赏函数,能够有效提高强化学习算法的收敛速度。面对多任务约束条件下的水面无人艇路径规划,奖赏函数的设计决定了其能否快速收敛到最优解。为提高多任务约束条件下Q_learning 算法的收敛速度,本文设计了任务分解奖赏函数。
2.3.1 任务分解奖赏函数的设计
依据任务的优先级,对无人艇所要执行的任务进行优先级划分,避障任务始终处于任务第1 位。将水面无人艇路径规划的奖赏函数表示为各个分任务奖赏函数的加权和,如下式:

其中:R 表示总的奖赏函数;Ri(i=1, 2, ···, n)表示分任务的奖赏函数;n 表示无人艇可以执行任务的数量;ωi(i=1,2,…,n)表示分任务奖赏函数的权值,ωi∈[0,1],ωi值越大表示任务优先级越高,需要优先考虑该任务的奖赏函数,通常无人艇周围有障碍物时,优先将避障任务权值调整为最大。
针对本文中水面无人艇要执行的任务,设计如下的奖赏函数:
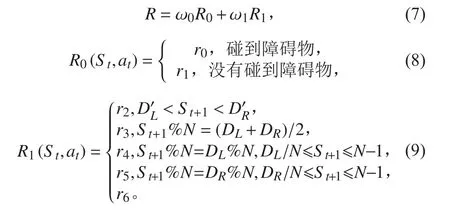
式中:R 为总的奖赏函数, R0(St,at)与 R1(St,at)分别表示避障任务约束中St状态下采取at行动的奖赏值和基础过门任务约束中St状态下采取at行动的奖赏值。r0为碰到障碍物的奖赏值,r0=-5;r1为没有碰到障碍物的奖赏值,r1=0。DL,DR,D′L,D′R为环境感知信息的输入值,分别表示入口左边浮标状态值,入口门右边浮标状态值,出口门左边浮标状态值,出口门右边浮标状态值;N 为环境模型大小,N=40;St+1为St状态下采取at行动后的状态;r2为到达目标区域的最终报酬值,r2=10;r3为门中心区域状态的报酬值,r3=2;r4和r5为撞到门浮标和从门侧面穿过的报酬值,r4=-5,r5=-5;r6为可以自由航行的区域,r6=0。ω0为避碰任务奖赏函数的权重,ω1为避碰任务奖赏函数的权重,初始时ω0=1,ω1=0,随着无人艇穿过障碍物区域,ω0逐渐减小,ω1逐渐增加。
依据任务对奖赏函数进行分解,通过对不同任务奖赏函数权重的分配,使无人艇在训练过程中,能够根据当前执行的任务选择该任务的奖赏函数,从而使其能够得到最优的奖赏值。
2.3.2 策略选择
动作的选取策略需要考虑“探索”与“利用”平衡问题,“探索”即智能体对为止环境的探索,“利用”即智能体选择当前最优策略。初始训练时,由于智能体对环境一无所知,应该以较大“探索”概率进行环境探索;当训练一段时间后,智能体对环境有了一定的了解,应该以较大的“利用”概率选择最优策略。
本文采用经典的ϵ-贪心策略,ϵ 值表示“探索”概率,即在训练过程中随机选择动作的概率。1-ϵ 表示“利用”概率,即在训练过程中选择最优动作的概率。由于在训练前期,智能体对环境信息一无所知,需要以较大概率进行“探索”,而在训练一段时间后,智能体对环境信息有了一定的了解后,可以依据之前的训练情况选择最优动作。因此,本文中ϵ 的值随着训练次数线性递减,即
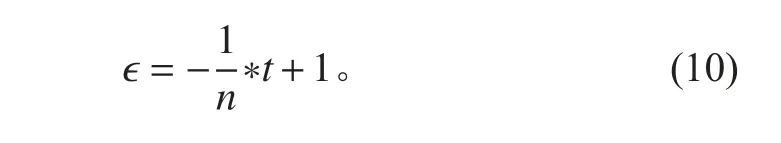
式中:n 为训练总次数;t 为当前训练次数。
3 试验
3.1 仿真试验
基于Windows 操作系统,在VS2012 开发环境下编写多任务约束条件下基于强化学习的水面无人艇路径规划算法。仿真试验的参数设置如下:学习率α=0.9,折扣率γ=0.8,总的训练次数为10 000 次。仿真试验动作的选取策略为ϵ-贪心策略,ϵ 初始值设为1,确保在初始时无人艇有较大随机探索概率;随着训练次数的增加线性递减,即每训练一次ϵ 值减少0.000 1,确保在多次训练后采取回报值较大的动作。
图7 为水面无人艇单个任务的仿真结果。通过强化学习的训练之后,无人艇能够自主规划出完成任务的路径。经过多次试验,训练的时间约为100 ms,能够满足无人艇航行过程中实时在线训练的要求,并且能够较好地规划出完成任务的路径。
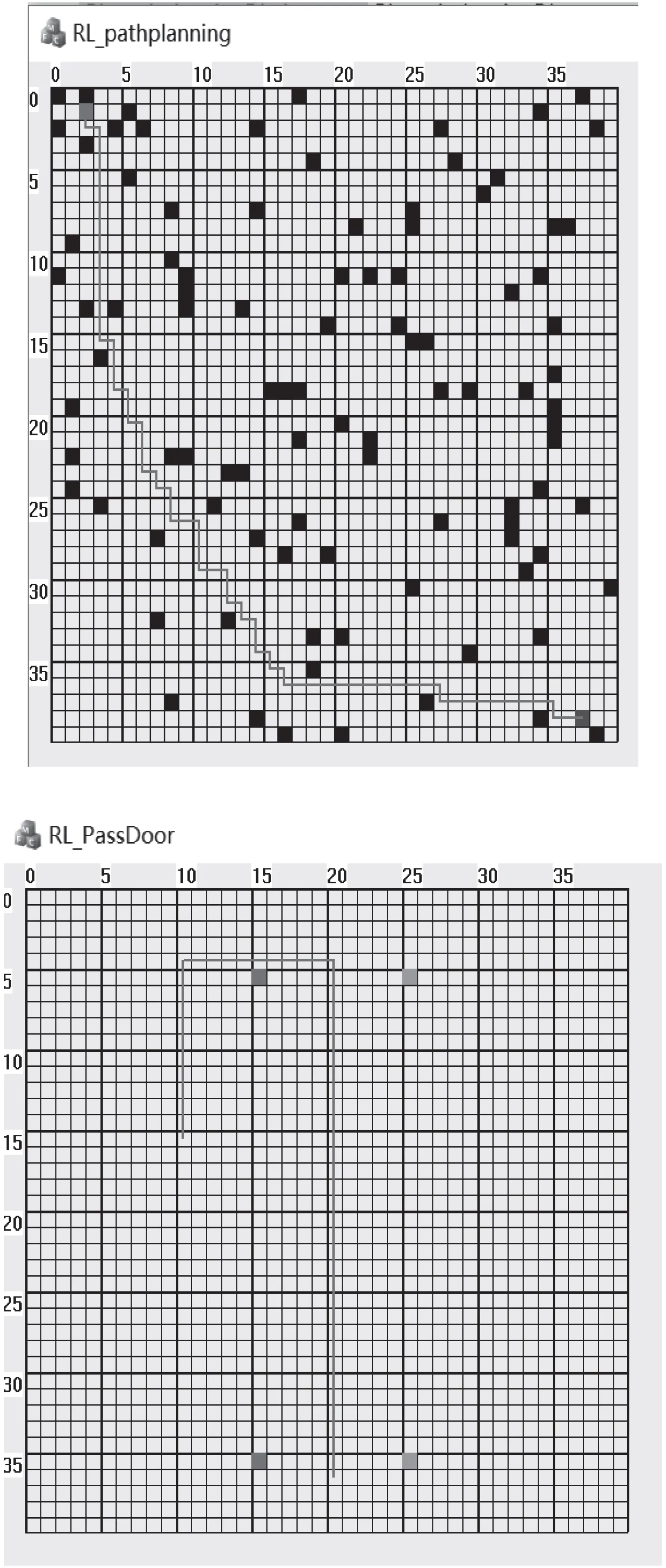
图 7 水面无人艇单个任务路径规划仿真结果Fig.7 Simulation results of single task path planning for USV

图 8 多任务约束条件下基于强化学习的无人艇路径规划仿真结果Fig.8 Simulation results of path planning of USV based on reinforcement learning under multi-tasking constraints
图8 为多任务约束条件下基于强化学习的水面无人艇路径规划结果。经过强化学习训练,水面无人艇能够安全穿越障碍区,并且完成基础过门任务。
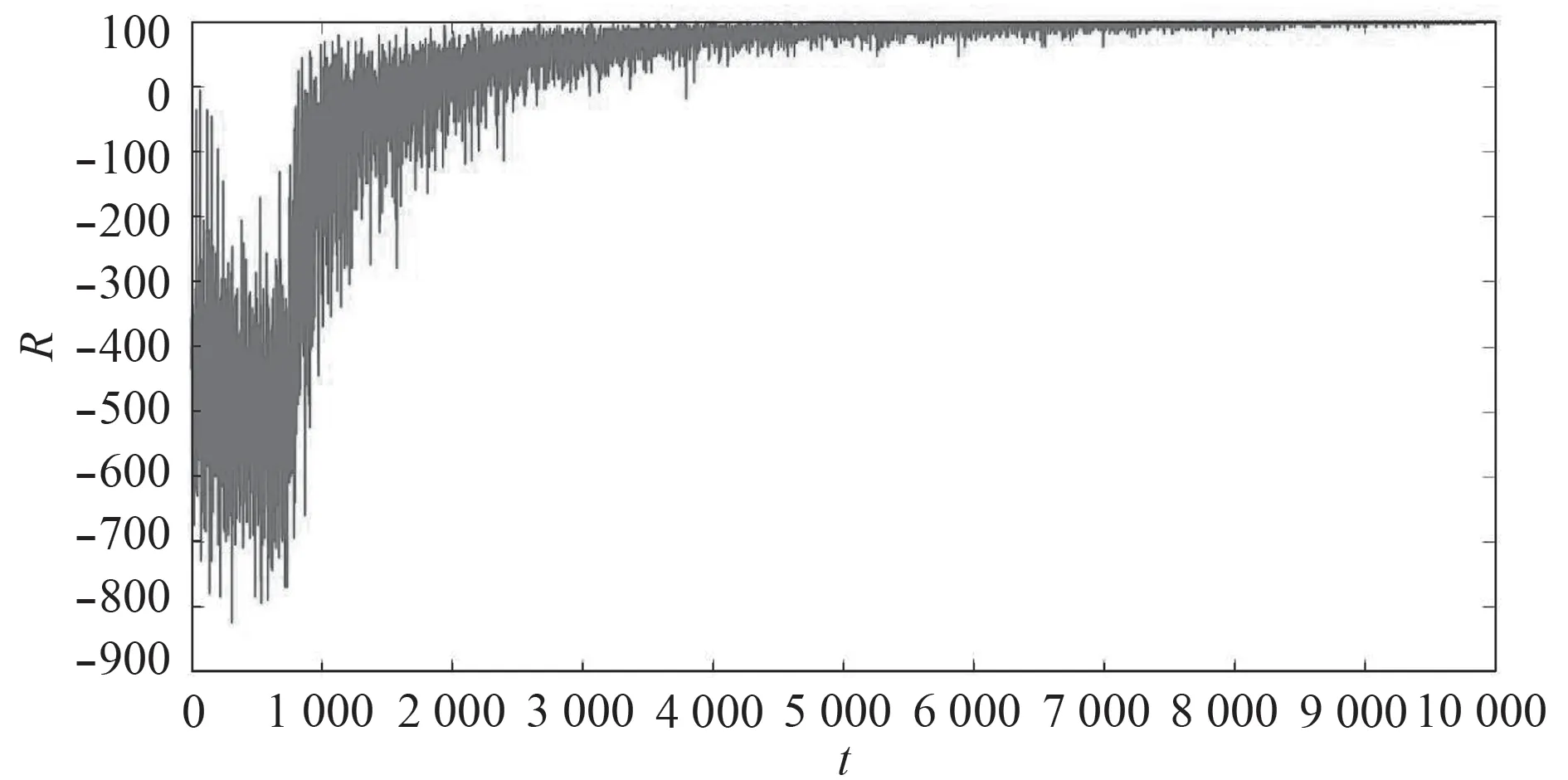
图 9 累积奖赏值随训练次数的变化曲线Fig.9 Curve of cumulative reward value with training times
图9 为强化学习训练过程中每次训练的累计奖赏。在训练过程中,无人艇碰撞或者违反任务规则会得到一个负的奖赏,当无人艇沿任务规则航行会得到一个正的奖赏,当无人艇到达目标区域会得到一个更大的正奖赏。
可以看出,基于任务分解奖赏函数的Q_learning 算法能够很好地收敛。在训练前期无人艇处于探索时期,会经常发生碰撞或违反任务规则,所以开始的时候累计奖赏大多为负值。随着训练的不断进行,无人艇能够利用之前训练的“知识”选择奖赏较好的动作,奖赏值逐渐增大最终收敛到一定范围。

图 10 基于任务分解奖赏函数的Q_lea rning 算法与经典Q_learning 算法成功率对比图Fig.10 Comparison chart of success rate of Q_learning algorithm and classic Q_learning algorithm based on task decomposition reward function
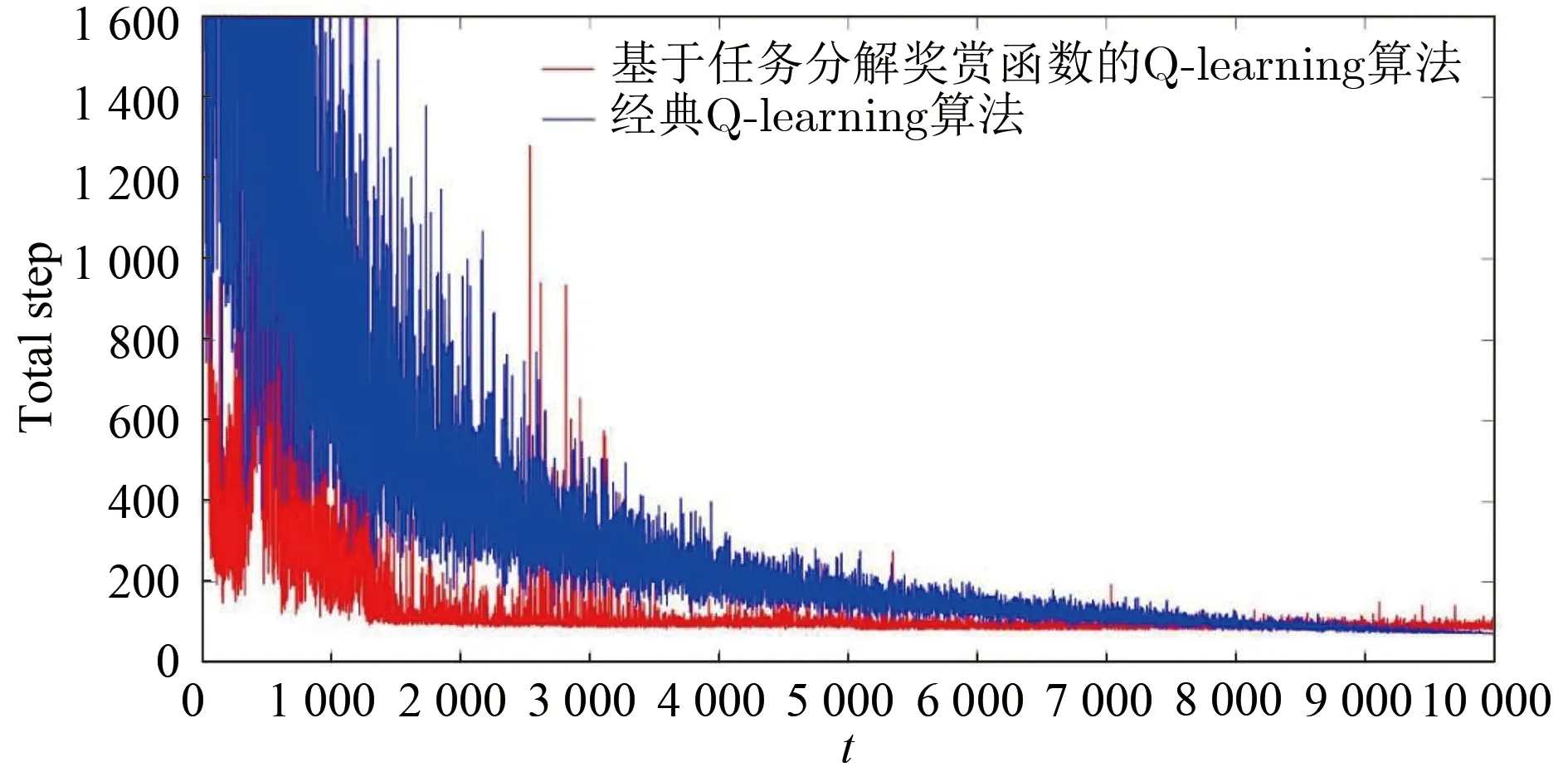
图 11 基于任务分解奖赏函数的Q_lea rning 算法与经典Q_learning 算法成功率对比图Fig.11 Comparison chart of Convergence of Q_learning algorithm and classic Q_learning algorithm based on task decomposition reward function
图10 与图11 分别对比了基于任务分解奖赏函数的Q_learning 算法和经典Q_learning 算法的成功率和收敛性。可以看出,基于任务分解奖赏函数的Q_learning 算法能够有效提高训练过程中寻找路径的成功率,并且能够快速收敛到最优解。由于采用ϵ-贪心策略会有一定概率随机选择动作,因此图中会有许多“毛刺”。
通过仿真试验可以看出,在多任务的约束条件下,基于任务分解奖赏函数的Q_learning 算法能够加快训练收敛速度,从而节省训练时间,保证水面无人艇路径规划的实时性。通过强化学习训练,水面无人艇能够较好规划出完成任务的路径。
3.2 实物试验
3.2.1 无人艇试验平台搭建
无人艇硬件系统结构如图12 所示。导航设备主要有:GPS 和电子罗盘(TCM);感知设备主要有:激光雷达和摄像头;艇上有2 台工控机,分别用来执行规划控制算法和感知系统中的算法。感知工控机与规划控制工控机之间的通信采用网络通信(TCP/IP 协议)。
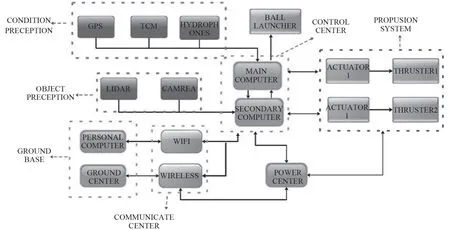
图 12 无人艇硬件系统结构Fig.12 Hardware system structure of USV
3.2.2 无人艇软件系统结构
无人艇软件系统结构如图13 所示。
任务规划汇总来自各个模块的数据,依据当前艇的状态及任务信息,决定完成任务的最佳策略。任务规划器将导航和感知信息汇总分析后,将信息传送到环境建模模块完成任务执行的环境建模。路径规划器依据当前的环境模型,基于强化学习寻找最优路径,完成任务执行的任务路径规划。
3.2.3 试验结果分析
本文提出的方法在2018Maritime RobotX Chanllenge 中得到了成功应用并取得了预期效果。在试验中,无人艇首先采用利用灰色预测辅助区域建议神经网络的水面目标检测方法得到任务区域中入口门浮标的位置和颜色,之后,由任务规划器依据感知信息完成当前要执行任务的决策,并计算出出口门的位置,同时完成任务环境建模,最后,基于强化学习完成执行任务的路径规划。
在基础过门任务与避障任务的执行中,使用与仿真试验相同的参数,无人艇能够完成基于强化学习的在线学习,并成功规划出完成任务的最优路径,无人艇执行任务过程如图13 所示。经过试验验证本文提出的任务约束条件下基于强化学习的水面无人艇路径规划方法能够满足实际要求。
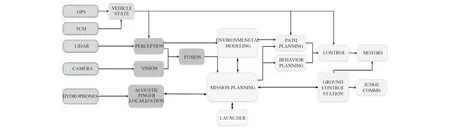
图 13 无人艇软件系统结构图Fig.13 Software system structure of USV
4 结 语
本文提出一种利用灰色预测辅助区域建议神经网络的水面目标检测方法和一种多任务约束条件下基于强化学习的水面无人艇路径规划算法。采用灰色预测进行区域建议,提升神经网络检测连续视频帧中水面目标的速度和准确率,提高了获得水面任务环境信息的准确性,利用感知系统得到的环境信息完成环境建模,并基于强化学习在线训练,完成任务约束条件下的无人艇路径规划。以Maritime RobotX Chanllenge 中的基础过门任务为背景,通过仿真试验,验证了在任务约束条件下,采用强化学习进行路径规划的可行性,并通过实物试验,验证了这2 种算法能够满足实际要求。
