基于小波包与自适应维纳滤波的语音增强算法
2020-01-10徐雨明马振中李列文
董 胡,徐雨明,马振中,李列文,任 可
(1.长沙师范学院 信息科学与工程学院,湖南 长沙 410100;2.湖南师范大学 物理与电子科学学院,湖南 长沙 410181)
0 引 言
语音增强是语音和信号处理领域的一个重要问题,它对许多基于计算机的语音识别、编码和通信应用都有一定的影响。语音增强的根本目标是提高语音质量和清晰度以被人类监听者感知到。语音增强算法包含传统的谱减法[1-3]、维纳滤波法[4-6]、小波系数阈值法[7-9]、子空间法[10-11]及近年来提出的深度神经网络法[12]等。这些语音增强算法或是基于统计模型或基于语音与噪声的先验信息,在一定程度上改善了含噪语音的质量。然而,在复杂噪声环境下,尤其是在非平稳噪声环境下它们的语音增强性能出现下降。针对上述问题,文中提出了一种基于小波包和自适应维纳滤波的语音增强算法。
1 小波包变换
小波包变换是一种直观且有效的语音增强方法。语音与噪声的小波包变换所表现的特性截然相反,语音信号小波包变换的模值随小波尺度的增加而递增,但噪声的模值却随小波包尺度的增加而递减。这样,接连多次小波包变换后,噪声对应的小波包系数基本被去除或者幅值非常小,剩余系数主要由语音信号控制。利用较显著的语音小波包系数来重构语音信号,进而较好地去除噪声。
小波包由两组正交小波基滤波器系数生成。若{hk}k∈z和{gk}k∈z是一组共轭镜像滤波器(QMF),满足:
(1)
gk=(-1)kh1-k,l,k∈z
(2)
小波包与小波分解不同,它不仅对低频信号部分作分解,还对高频信号部分作分解,因此小波包是一种比小波更加精细的分解算法[13]。图1为小波包对一维时间序列分解特性图,其中A代表低频,D代表高频,末尾下标序号代表小波包分解的层数。三层小波包分解关系为:
S=AAA3+DAA3+ADA3+DDA3+AAD3+DAD3+ADD3+DDD3
(3)
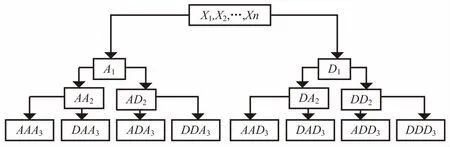
图1 小波包时间序列分解
2 自适应维纳滤波
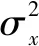
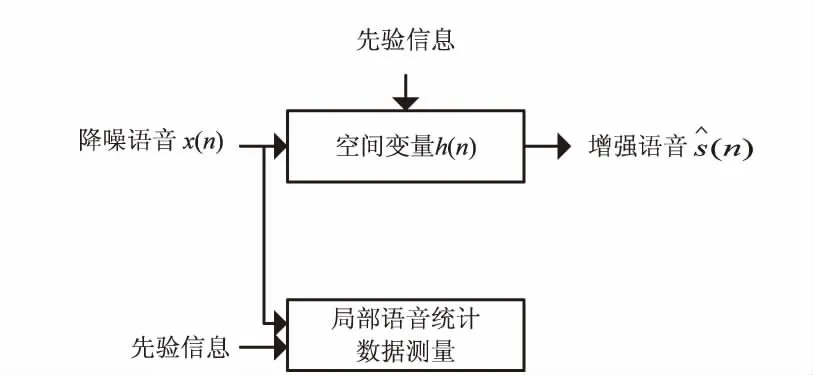
图2 自适应维纳滤波语音增强

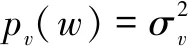
(4)
考虑到x(n)中一小段语音信号是平稳的,则x(n)可表达如下:
x(n)=mx+σxw(n)
(5)
其中,mx和σx分别表示x(n)的局部均值和标准偏差;w(n)表示零均值的单位噪声变量。
采用“直接判别”算法来预估当前帧的先验信息[14]。在一小段语音中,维纳滤波转换方程可近似作如下表达:
(6)
由式6可得维纳滤波脉冲响应:
(7)
由式7可知,局部增强的语音信号可表达如下:
(8)
假设每一帧语音信号的mx和σs都得到更新,增强的信号可表达如下:
(9)
由式9可得,x(n)的局部均值变量mx为:
(10)
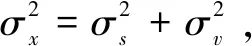
(11)
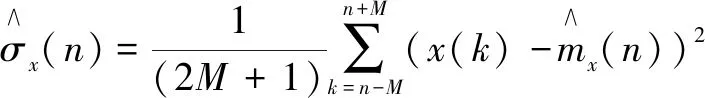
(12)
3 小波包与自适应维纳滤波语音增强算法
小波包变换具有能量集中特性,文中采用db10小波包进行多尺度分解。含噪语音信号经过小波包变换时,噪声的能量集中在高频部分且幅值较小的小波包系数上,而语音信号的能量则集中分布在低频部分且幅值较大的小波包系数上。语音信号的小波包系数值大于噪声的小波包系数值,因此通过小波包变换能够实现语音与噪声的分离。通过db10小波包的分解将含噪信号作频率谱划分得到不同尺度的小波包系数,然后对各个尺度的系数作自适应维纳滤波增强,最后将增强后的小波包系数进行重构即可得增强后的语音信号。整个语音增强算法的流程见图3。
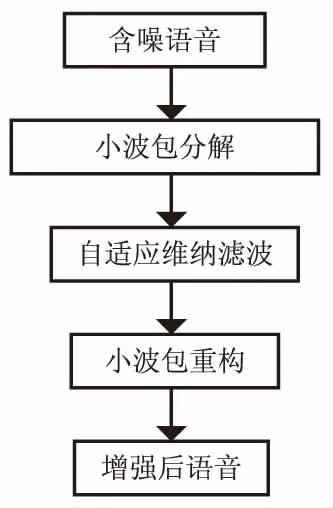
图3 小波包与自适应维纳滤波语音增强算法流程
4 仿真实验与分析
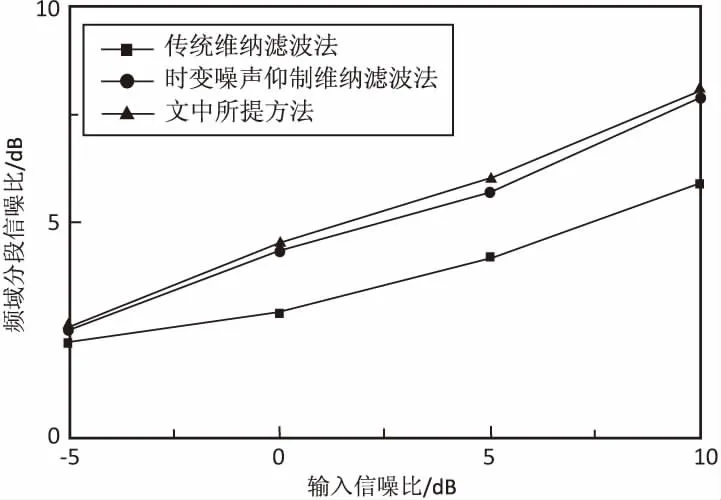
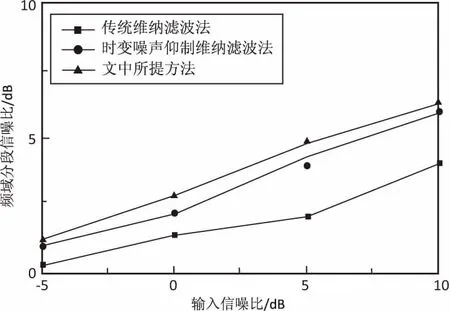
为验证所提算法的增强效果,利用MATLAB软件开展仿真实验。实验中使用录制的语音作为纯净语音样本。噪声信号取自NOISEX-92数据库中的白噪声、babble噪声、pink噪声和factory噪声。纯净语音和噪声的采样频率都为16 kHz,16 bit量化,将纯净语音与上述不同类型的噪声进行混合,合成信噪比不同的含噪信号。每帧信号帧长为15 ms,帧移为50%。为突出所提语音增强算法的有效性,分别将其与传统维纳滤波、文献[15]提出的时变噪声抑制维纳滤波进行比较,计算增强后语音的频域分段信噪比及客观语音质量评估(PESQ)。3种语音增强算法的频域分段信噪比如图4所示,图4(a)~图4(d)分别为白噪声、babble噪声、pink噪声和factory噪声条件下,3种语音增强算法的频域分段信噪比图。
(a)白噪声
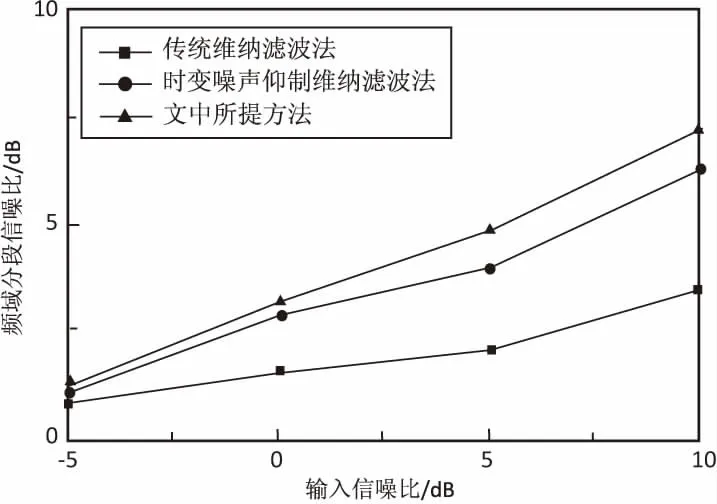
(b)babble噪声
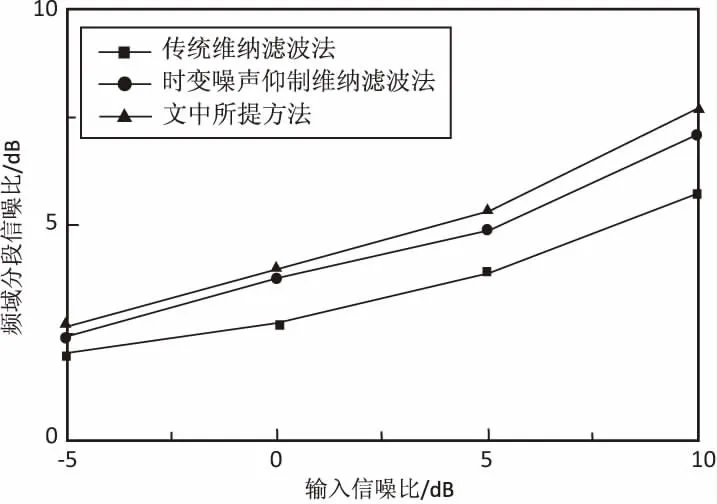
(c)pink噪声
(d)factory噪声
从图4可知,与传统维纳滤波算法比较,所提语音增强算法及文献[15]提出的时变噪声抑制维纳滤波算法频域分段信噪比较高,在低信噪比情况下尤为明显。文献[15]与所提语音增强算法相比,在白噪声和pink噪声条件下,其分段信噪比效果较接近,然而在babble和factory的非平稳噪声条件下,所提语音增强算法的分段信噪比较高,平均约高出0.5 dB。
3种不同算法语音增强后的PESQ如表1所示。由于传统维纳滤波在非平稳的噪声(factory、babble噪声)环境下会对含噪语音产生过分抑制,容易造成语音失真和产生音乐噪声,在表1中也分别给出了其他两种语音增强算法的PESQ值。经主观听测表明,采用传统维纳滤波语音增强后有较明显的音乐噪声,而采用文中算法和文献[15]算法后都能较好地抑制音乐噪声,其PESQ均高于传统的维纳滤波。其中,文中的语音增强算法的PESQ亦高于文献[15]提出的语音增强算法。
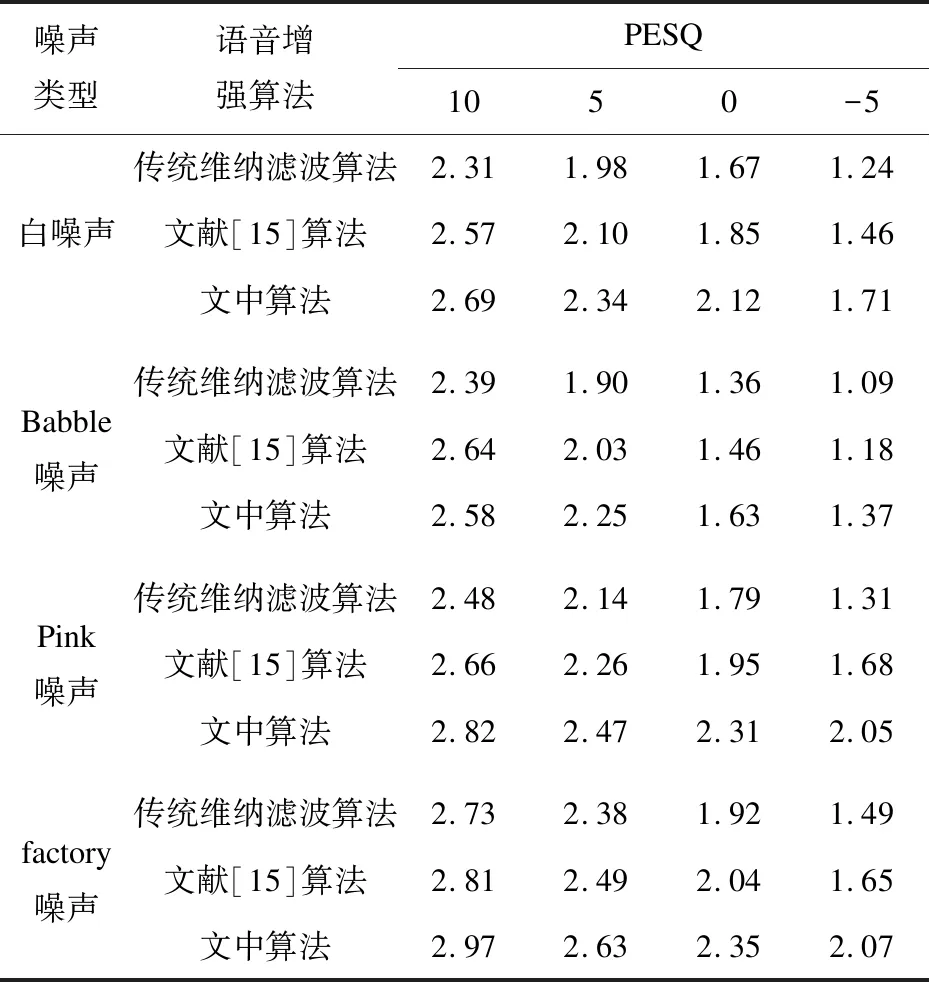
表1 3种语音增强算法PSEQ比较
图5比较了3种语音增强算法的语谱图。其中,图5(a)是含pink噪声(SNR=-5 dB)语谱图,图5(b)、图5(c)和图5(d)分别为经过传统维纳滤波、文献[15]算法及文中算法的语音增强语谱图。
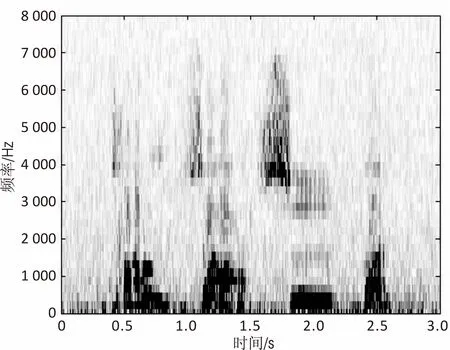
(a)含-5 dB pink噪声语谱图
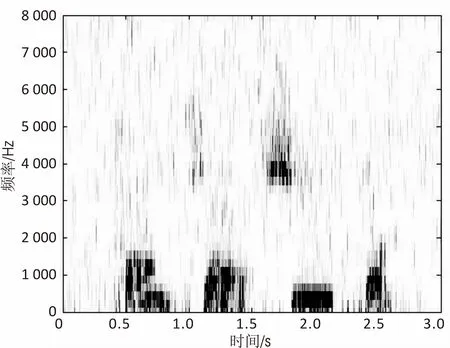
(b)传统维纳滤波算法
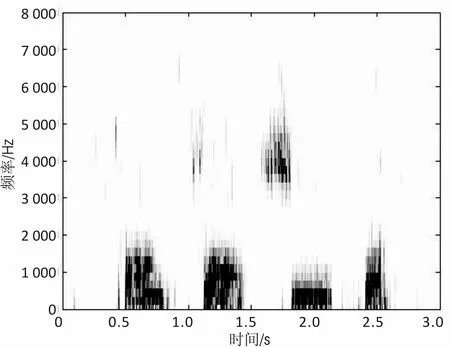
(c)文献[15]算法
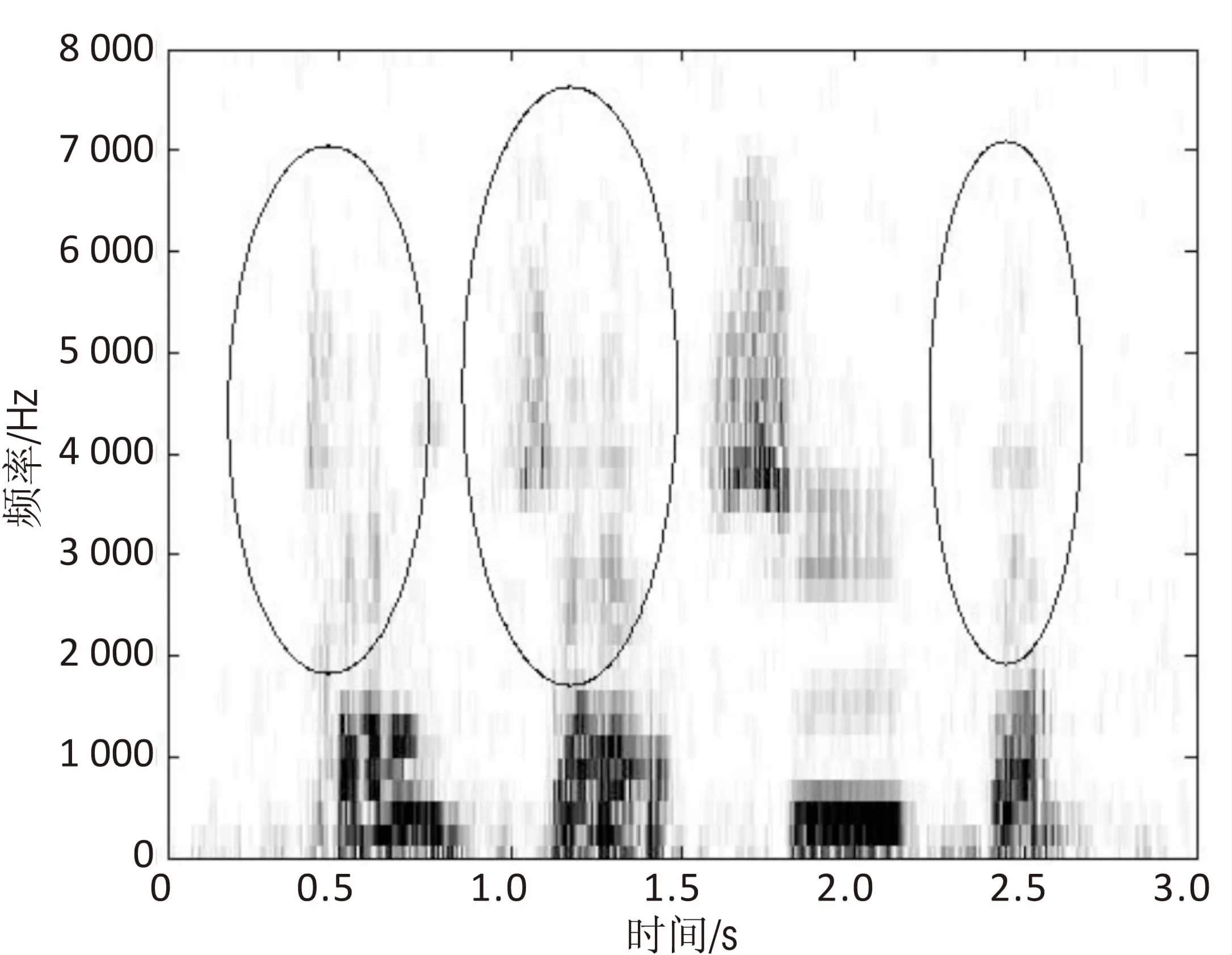
(d)文中算法
从图5可知,与图5(b)相比较,图5(c)与图5(d)在较好地去除背景pink噪声的同时,更好地保留了语音的谐波成分,而图5(b)则有较明显的语音失真。图5(d)与图5(c)相比,图5(d)保留了较弱的语音部分的谱特征,提高了增强后的语音质量。
5 结束语
提出的小波包和自适应维纳滤波算法结合了小波包和自适应维纳滤波两种算法的优点,利用小波包变换对非平稳的含噪信号作分解处理从而实现噪声和语音的初级分离,然后利用自适应维纳滤波作进一步降噪处理,在较低信噪比的非平稳噪声环境下,对语音的损伤相对较小,较好地抑制了音乐噪声的产生,语音增强效果较明显。文中算法比传统维纳滤波算法、文献[15]算法具有更高频域分段信噪比及PESQ,且主观试听上也无明显的音乐噪声。因此,该算法在降低音乐噪声的基础上提升了语音增强效果。
