基于深度学习算法的车辆违法行为智能分析
2020-01-09王军群李华鹏
王军群, 李华鹏
(1.中远海运科技股份有限公司,上海 200135;2.深圳大学 深圳电磁控制重点实验室,广东 深圳 518060)
0 引 言
近年来,随着我国经济的不断发展,人们的生活水平不断提高,道路上的车辆越来越多,相应的交通拥堵问题和交通事故频繁发生。造成交通拥堵问题和交通事故的主要原因是车辆违法行为,因此对车辆违法行为进行智能分析较为重要。在车辆违法行为监测方面,传统的检测工具主要有磁感应线圈、红外线和超声波等。这些交通检测工具虽然在缓解交通秩序和交通压力方面起到一定的作用,但维护成本高、硬件设备安装复杂等缺点限制了其应用。近年来,随着计算机视觉技术的不断发展,基于视频监控的车辆违法行为检测技术逐渐得到应用。
基于视频监控的车辆违法行为检测主要包括目标检测、目标追踪和轨迹运动分析,其中目标检测以往采用的是传统的图像处理方法,只能检测出运动的车辆目标,无法实现车辆类型分类,且检测速度慢,检测精度低,极易受外界环境的影响。检测完毕之后运用卡尔曼滤波、粒子滤波和CamShift等方法进行跟踪时,由于车辆目标检测阶段造成的检测精度低、检测速度慢和漏检情况频发等情况,使得后续目标追踪的效果很差,进而影响轨迹的运动分析。对此,本文将深度学习算法应用到车辆违法行为分析系统中,采用基于YOLOv3的深度学习算法对车辆目标进行检测,利用卡尔曼滤波对车辆目标进行跟踪,绘制车辆的运动轨迹,进而通过对车辆的运动轨迹进行分析,判断车辆是否存在违法行为。
1 基于YOLOv3的车辆检测算法分析
1.1 预期检测效果
输入一张图片或一段视频序列,输出图片中每辆车的类别和边界框(可选置信度),结果见图1。车辆类别选择小客车、大客车、小卡车(车长小于6 m)和其他(清洁车、消防车等)等4类。4类车辆示例见图2。

1.2 网络结构
为实现车辆检测,对基于YOLOv3的车辆检测算法进行分析。首先需确定YOLOv3的神经网络结构,其中网络采用darknet-53[1]框架,网络结构见图3。
YOLOv3是一个完全卷积神经网络,主要是卷积层、残差块和上采样层的组合,最显著的特点是可在3种尺度上进行检测,主要通过3个不同尺度的feature map来实现。卷积层在第79层之后经过3个卷积层得到第82层的feature map,相当于原始图像的32倍下采样,由于下采样倍数高、多尺度范围大,该feature map用来检测尺寸较大的车辆目标。为实现对更细粒度的检测,第79层的卷积层进行上采样,与第61层融合,得到第94层的feature map,相当于原始图像的16倍下采样,感受野中等,用来检测中等尺寸的车辆目标。同理,第106层得到的feature map相当于原始图像的8倍下采样,尺度小,用来检测小尺寸的车辆目标。
1.3 网络的输入与输出
若只观察输入到输出的映射关系,可将上述YOLOv3的网络架构简化(见图4)。
根据YOLOv3的设计,网络的输入是分辨率为416×416的RGB图片,3个像素通道;输出是3个不同尺度的张量,大小分别是13×3×3×9、26×26×3×9和52×52×3×9。以13×13×3×9的张量为例:13×13是输入图像经过下采样32倍得到的feature map的尺寸,可将输入图像划分为尺寸为13×13的网格(见图5)。输出张量中的13×13像素对应着输入图像的尺寸为13×13的网格;3表示颜色通道,代表每个网格输出边框的个数,由先验框的个数决定;9代表边框的4个坐标、1个边框置信度和4个车辆类别概率。
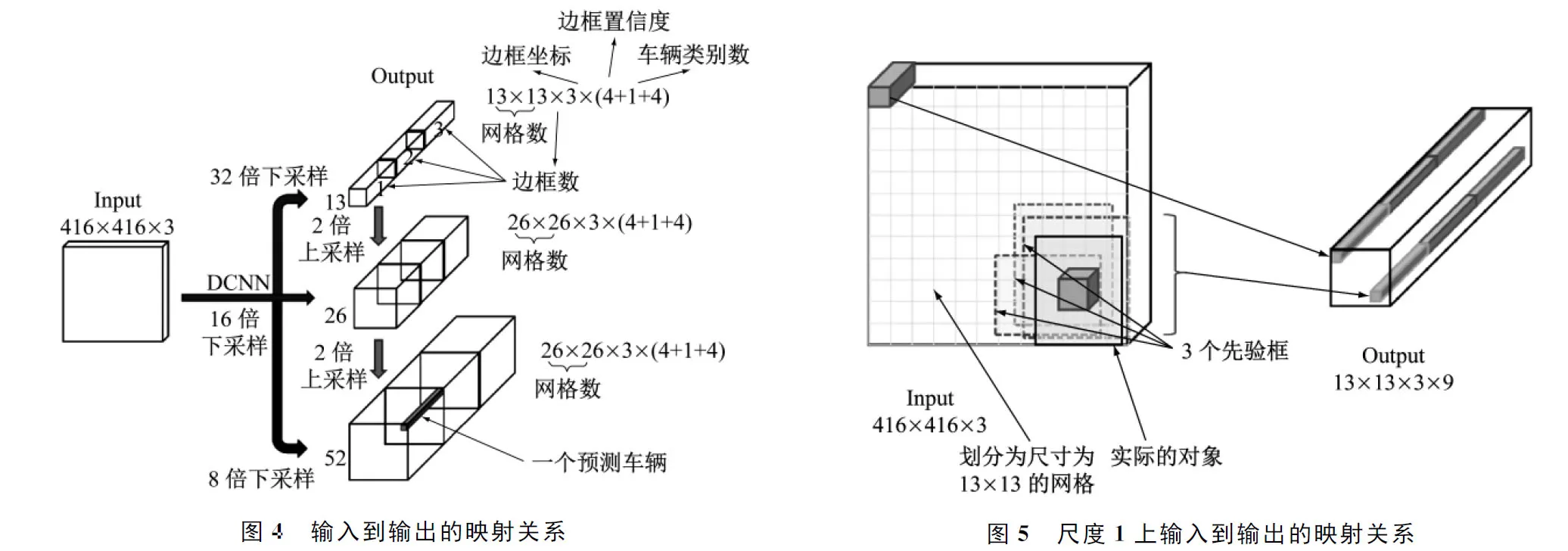
1.4 多尺度检测
YOLOv3借鉴Faster RCNN的做法,尝试使用先验框[2]。预先在每个网格设定一组不同大小和不同宽高比的边框,用其覆盖图像的不同位置和不同尺度。这些先验框作为预定义的候选区,检测网格中是否存在车辆目标,若存在,则微调边框的位置。根据第1.2节的分析,输入416×416的图片会得到3种不同尺度的feature map,用来检测不同尺寸的目标。由于利用了先验框的约束作用,实现了多尺度检测。以图6中的3幅图为例,框A是先验框,框B是ground truth(真实对象),框C是ground truth的中心。

如图6所示,根据输出feature map的大小,将输入图片划分成相应数量的网格,并在每个网格上放置3个先验框。由于先验框的尺寸不同,可约束检测目标的大小。由于有3种尺度的feature map,每个尺度需3个先验框,总计需9个先验框。通过在数据集上进行k-means聚类[3],得到具体的先验框尺寸分配情况和适用车辆目标大小见表1。
由图6和表1可知,先验框可约束预测的bounding box。图7为先验框的约束作用。其中:短划线边框是先验框;实线边框是待预测边框;bx、by、bw和bh为预测边框的中心和宽、高;cx和cy为归一化之后当前网格左上角与图像左上角之间的距离,cx=cy=1;tx、ty、tw、th为网络的输出的用于计算坐标的中间值;σ为sigmoid函数,可将tx和ty约束到(0,1)的范围内,进而将预测边框的中心点约束到实际目标中心点所在的网格A内;pw和ph为先验框的宽和高,通过图中右侧的计算式可使预测目标的尺寸接近于先验框的尺寸,即可实现先验框的约束作用。
1.5 训练
在确定网络的输入和输出之后,即可进行训练样本构造。作为监督学习,需先构造训练样本,使模型从中学习。
对于一张416×416的输入图片,会得到3个输出张量,以尺度为13×13×3×9的张量为例,其他2个张量的构造同理。首先输出的13×13对应于输入的13×13网格;对于3×9共27维的向量,可看作是3个1×9维的向量,且这3个向量的构造方式相同。由第1.3节可知,每个1×9维的向量中包含4个车辆类别的概率、1个bounding box的置信度和bounding box的4个坐标。
1) 4个车辆类别的概率。对于输入图像的每个车辆目标,先找到其中心点。例如图8中的小客车,其中心点在框A内,因此在该框对应的3×9维向量中,小客车的概率是1,其他3类的概率都是0。
2) 1个bounding box的置信度。对于训练样本来说,bounding box即为ground truth,故置信度的值为1。
3) bounding box的4个坐标。YOLOv3网络输出的bounding box的4个坐标输出值为tx、ty、tw和th。
在确定每个维度的信息之后,便可进行样本便签向量的填写,具体样本标签见图9。
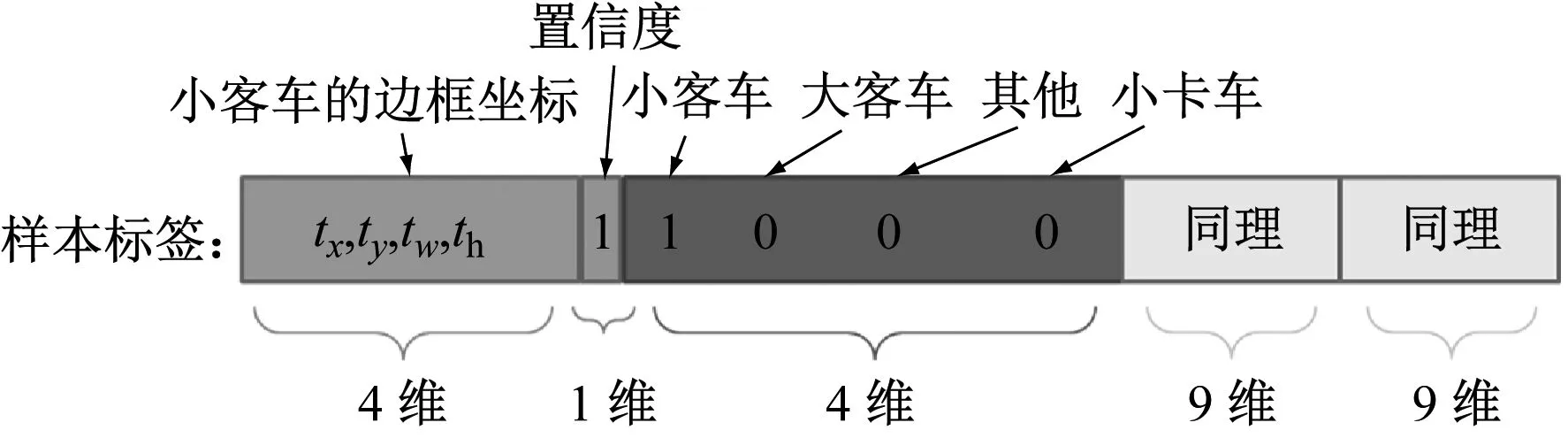
图9 样本标签
在训练前期的迭代中,前向传播之后,网络的实际输出值与样本标签值之间一定会有偏差。假设第一次迭代网络输出见图10,与图9的样本标签存在差异,这时需用YOLOv3的损失函数[1]计算出该偏差,并通过反向传播减小该误差。不断迭代前向传播和反向传播的过程,逐步减小偏差,使网络的实际输出值尽可能地逼近样本标签值,即使预测变得更加精确。
1.6 预测
在网络训练好之后,便可进行预测(inference),输入一张416×416×3的图片,输出大小分别为13×13×3×9、26×26×3×9和52×52×3×9的3个张量,其中包含每个预测目标的位置信息、置信度和类别概率。但是,由于每个网格都会预测3个bounding box,总计会有10 647个bounding box,而对于每个目标,最终只需要1个预测的bounding box,故采用非极大值抑制算法(Non Maximum Suppression,NMS)来去除多余的bounding box。NMS效果示意见图11。
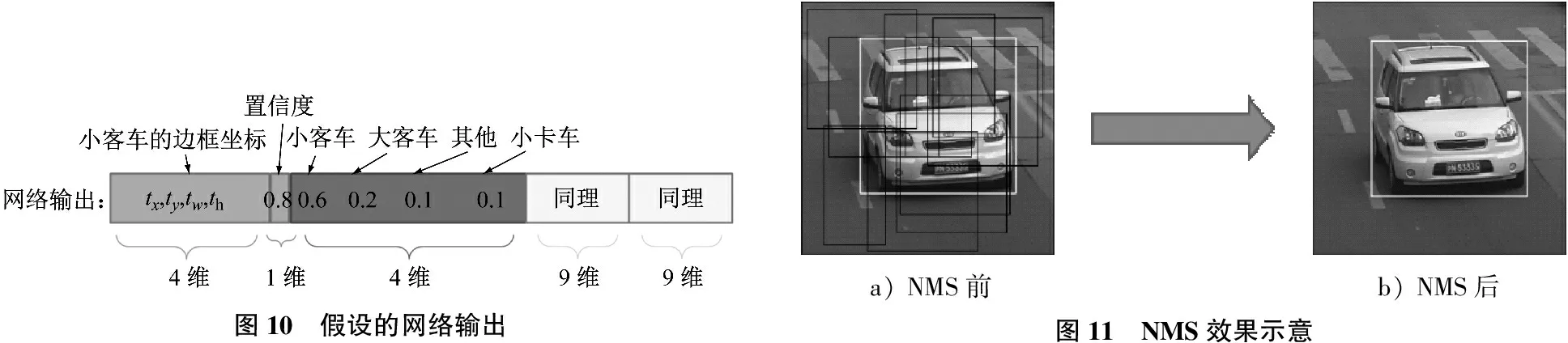
图10 假设的网络输出a) NMS前 b) NMS后图11 NMS效果示意
2 试验结果与分析
首先构造训练样本,从上海市东宝兴路与芷江中路交叉路口采集监控视频。视频时长1 067 s,共计26 679帧,每60帧取1帧图像,共获得样本444帧。对每个样本的每帧图像中的所有车辆进行标注,包括类别和外接矩形。在构造完训练样本之后,使用TensorFlow框架,在NVIDIA RTX2080显卡下进行训练。采用迁移学习的方式,预加载YOLOv3在COCO数据集[5]上训练得到的权重,以416×416的图片大小训练200个epoch,再以640×640的图片大小训练200个epoch。训练完成之后,输入视频序列,得到的检测结果见图12,视场中不同远近和不同尺寸的车辆均得到有效检测。

在对算法进行评估时,选择平均精度(Average Precision,AP)、均值平均精确度(mean Average Precision,mAP)和检测速度(Frames Per Second,FPS)作为评价指标,其中:AP可反映模型在检测特定类别车辆时的性能表现;mAP通过对所有车辆类别的AP求平均值得到,不仅能反映模型在所有车辆类别上的平均性能表现[6],而且可避免某些类别比较极端化而弱化其他类别的性能表现的问题;FPS为检测每帧图像中的所有车辆所花费的时间。各项性能指标见表2。
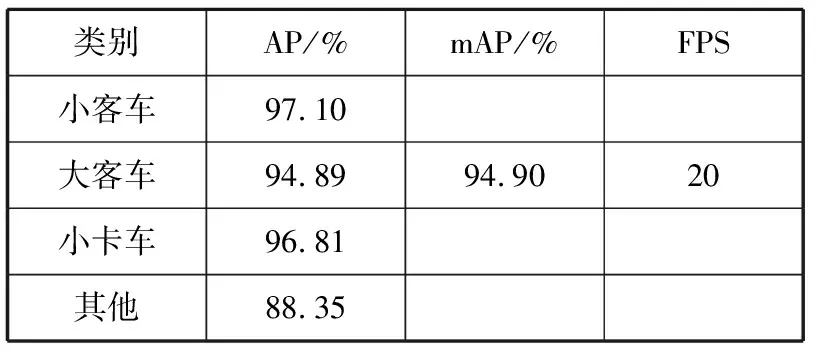
表2 检测性能指标
在完成车辆检测之后,便可对车辆进行跟踪。车辆跟踪算法采用卡尔曼滤波算法[7],用来预测更新轨迹。卡尔曼滤波是一种递归的估计,即只需获知上一时刻状态的估计值和当前时刻状态的观测值就可计算出当前状态的估计值,经过卡尔曼滤波的预测和更新,可得到车辆在当前时刻预测得到的位置信息,将其与当前时刻车辆检测得到的位置信息相关联,由每个检测得到的车辆目标与每个预测得到的车辆目标之间边界框的交并比IOU[8]计算成本矩阵,采用匈牙利算法进行匹配[9],即可实现目标跟踪。随后对跟踪的车辆绘制运动轨迹,结合车辆的运动轨迹、位置信息和相应的交通标志,便可实现对车辆违法行为的智能分析。交通系统中常见的车辆违法行为包括闯红灯、逆向行驶、违反禁止标线、左转不让执行、路口滞留和机动车占用非机动车道等。图13为监控视频中检测到的常见车辆违法行为,其中:方框表示的是违法车辆的位置信息;曲线线条表示的是车辆近2 s内的运动轨迹。

3 结 语
为实现对车辆违法行为的智能分析,采用基于YOLOv3的深度学习算法对车辆进行检测,利用卷积神经网络提取车辆特征进行分类识别,同时采用多尺度检测方法优化对监控视场远景处小目标进行检测的能力,将车辆目标的定位和识别步骤合并,大幅度提高了检测精度和检测速度,为后续车辆目标跟踪提供了依据。由此,便可通过卡尔曼滤波器进行目标跟踪获取车辆的运动轨迹,根据车辆的运动轨迹和位置信息对车辆的违法行为进行智能分析判定。然而,当车辆目标出现大范围遮挡,或出现某些样本集很少的车辆类别时,仍会出现漏检或误检的情况,进而影响车辆的跟踪效果,甚至影响车辆违法行为分析结果的准确性。因此,如何扩充数据集和在有目标遮挡时进行更加准确的检测,是未来研究的重点。
