Landsat8光谱衍生数据分类体系下的牧草生物量反演
2020-01-08张爱武郭超凡刘路路胡少兴柴沙驼
张爱武,张 帅,郭超凡*,刘路路,胡少兴,柴沙驼
1. 首都师范大学三维信息获取与应用教育部重点实验室,北京 100048 2. 首都师范大学空间信息技术教育部工程研究中心,北京 100048 3. 北京航空航天大学机械工程及自动化学院,北京 100191 4. 青海大学畜牧兽医科学院(青海省畜牧兽医科学院),青海 西宁 810016
引 言
生物量作为草地生态系统的物质基础,是衡量草地生长状况的主要指标,代表草地初级生产力的基本水平,决定了草地的载畜能力[1]。及时、精确的掌握草地地上生物量的含量、分布及变化情况对于评估草地生态系统、计算草地载畜能力、确保草地生态安全具有重要意义[2]。
与传统实地测量方法不同,利用遥感技术可以快速、准确、无破坏的实现对草地生物量估算。Landsat系列卫星数据被称为是最有用的遥感数据之一,已被广泛应用于区域尺度牧草生物量估产。研究发现通过对Landsat系列数据进行波段计算获取的光谱衍生数据比原始波段在探测生物量方面具有更好的灵敏性。例如红光谱波段对植被叶绿素敏感,近红外光谱波段对叶片组织敏感,由红光谱波段和近红外光谱波段构建的归一化植被指数(NDVI)可以反映植被的绿度特征[3]; 短波红外光谱波段对植被含水量非常敏感,由短波红外构建的归一化红外指数(NDⅡ)可以反映植被水分含量[4]。这些指数能够直观的反映植被某些方面的理化特征(定义为直接因子),因此在植被生物量反演中得到了广泛的应用。但地面植被信息的遥感获取是一个复杂的过程,还会受到大气、其他地物背景的干扰。因此相关学者推出了一些突显地面植被信息、消除背景干扰的植被指数。例如土壤调节植被指数(SAVI)能够较好的去除土壤背景对于目标信息的影响[5]。此外缨帽变换的第三分量通过影像增强的方法反映地面的土壤水份含量,(这些指数定义为间接因子)。以及纹理特征(定义为空间因子)可以从图像反映植被冠层的空间变化规律和空间相关性。这些间接因子和空间因子从不同的角度反映了地面植被的信息,但由于与直接因子具有较强的共线性,很少被应用于植被生物量反演研究。
基于植被指数的单变量反演模型是目前进行大面积生物量估算的主要方法,常用模型包括线性和非线性模型[6]。当生物量较低时,建立的估算模型是一元线性的,随着生物量的增加,指数模型体现出更好的拟合效果[7]。一些学者尝试通过寻求各种统计方法构建基于多变量植被指数特征的植物生物量估算模型,如高明亮[8]等基于环境卫星遥感数据和同步野外实地采样数据,进行了黄河湿地植被生物量反演研究,结果表明MLRM(多元线性回归模型) 比 SCRM(一元曲线回归模型) 具有更好的反演精度和预测能力。
随机梯度Boosting算法(stochastic gradient boosting, SGB)是一种集成学习方法,在生态建模中有广泛的应用,但是在遥感中应用尚不多见。该算法的优势在于不需要预先筛选特征变量,同时可以适应复杂的非线性关系,且模型具有高度稳健型和可解释性,不容易陷入过拟合[9]。因此,提出基于随机梯度Boosting算法(SGB)来构建牧草生物量反演模型。以青海省海晏县为研究区,以Landsat 8遥感影像数据为数据源,进行方案的可行性探讨。研究的内容主要包括: (1)归纳总结植被生物量反演相关的Landsat-光谱衍生数据,并基于它们所反映的植被理化特征及它们间的关联方式构建分类体系; (2)基于随机梯度Boosting算法构建多变量非线性牧草生物量反演模型,探讨不同Landsat-光谱衍生数据类型组合对于模型的影响。以期为牧草生物量遥感监测提供理论依据,为提高牧草生物量的定量反演精度提供参考。
1 实验部分
1.1 研究区概况
研究区(图1)位于青海省海北藏族自治州海晏县境内,地处36°53′30″—37°5′30″N,100°47′30″—100°59′10″E; 年日照时数2 980 h,年平均温度1.7°,年降水量499 mm,夏秋降水多,春冬降水少,全县牧草草地面积占总面积49.35%,草种类型多样,是全国草地生态畜牧业试验区。

图1 研究区位置和Landsat 8真彩色合成图
1.2 采样点设置与生物量测定
地面鲜重数据采集于2017年8月11日—13日进行,根据草地类型和生物量等级高、中、低梯度选择了三个采样区(采样区Ⅰ,Ⅱ,Ⅲ),包括两个春冬草场(Ⅰ,Ⅱ)和一个夏秋草场(Ⅲ),三个区域分层随机采集100个混合样方(图1),剔除部分异常值后剩余97个采样点,样方尽可能代表整个研究区域的植被生长状况,同时用GPS仪测量每个样方中心点经纬度。样方规格为0.5 m×0.5 m,齐地刈割,挑出石子和动物粪便等不可食部分称取鲜重并记录。
1.3 Landsat OLI光谱衍生数据提取及分类体系构建
实验所用的遥感数据为美国陆地卫星Landsat 8 OLI遥感影像,时间分辨率为16 d,空间分辨率为30 m,影像过境时间2017年8月10日,使用波段包括深蓝波段(0.43~0.45 μm)在内的前7个波段,使用ENVI5.1对影像进行预处理,经过辐射定标,大气校正后得到反射率数据。
Landsat 8OLI数据在研究农作物信息提取、叶面积指数反演、生物量估算等方面均取得较好的效果。但植被生长是一种复杂的过程,伴随着多种植被特征状态的变化,如植株高度、冠层叶面积指数、植被颜色、植被水分等,不同的特征可能产生不同的遥感信号,需要将其区别对待。根据不同衍生变量在植被生物量反演过程中所反映植被的理化特征,将常用的Landsat-衍生变量分为7类(表1): 一是反映植被绿度的绿度指数(NDVI,GNDVI,RVI,II,TCG),由于红光谱波段对植被叶绿素敏感,近红外光谱波段对植被叶片组织敏感,两者有效结合可精确的刻画植被的绿度特征。二是反映植被衰败程度的黄度指数(NDTI,NDSVI),该类指数常用于提取植物枯枝落叶层及农作物残余物信息,主要反映植被整体的凋萎程度及作物成熟状况。三是反映植被水分含量的衍生变量,包括水分指数(NDMI,NDII)和缨帽变化中的湿度分量(TCW),可用于反映植株冠层水分含量和土壤湿度; 四是用于反映植被覆盖度的衍生变量,包括TCA和TCD,它们是经过缨帽变化中亮度分量(TCB)和绿度分量(TCG)变换到极坐标系统而获得的指数,TCA随着植被覆盖度的增大而增大; TCD随着阴影面积在像元中比例增加而减少,这两个变量可用于反映植被生长密集时的情况。五是用于消除大气影响因子的植被指数(ARVI,EVI,VARI),通过增加大气修正因子,能够有效减少大气对植被的影响。六是用于消除土壤背景影响的植被指数(SAVI,PVI,MSAVI,OSVAI) ,通过增加土壤调节系数,能够有效减少土壤对植被的影响[10]。七是反映植被空间特性的纹理指数,应用最广泛的是由Haralick等提出的灰度共生矩阵(GLCM),主要包括均值、方差、均匀性、对比度、相异性、熵、二阶矩、相关性等8个指标(窗口大小为5×5像素)。其中类一、类二、类三和类四直接反映了植物的理化特征,定义为直接因子。类五和类六通过消除背景干扰间接的反映植被理化特性,定义为间接因子。而纹理特征则是从空间的角度反映植被的特征,定义为空间因子。

表1 Landsat-衍生变量分类体系
注: Ⅰ表示属于直接因子,Ⅱ表示间接因子,Ⅲ表示空间因子
Note: Ⅰ represents direct fector; Ⅱ represents indirect factor and Ⅲ represents spector
1.4 随机梯度Boosting回归模型(SGB)
随机梯度Boosting(SGB)是一种可用于分类和回归模型的集成学习器,具有高度稳健性和可解释性。SGB方法对于异常值、缺失值、非平衡数据集有较好的鲁棒性,参与计算的变量不需要假设先验概率分布,并且在处理非线性关系及变量之间的存在较强自相关模型时有较大的优势。
2001年,Friedman[18]提出Gradient Boosting算法,该算法将每次迭代的组合分类器在x上的值作为损失函数空间在x上的负梯度,将组合分类器的系数作为步长,来近似逼近组合分类器的损失函数的最小值。令X=[x1,x2, …,xn]T,经M次迭代后,得到最终的回归树模型
F(x)=F0(x)+vβ1h1(X)+vβ2h2(X)+…+vβMhM(X)
(1)
其中,F0(x)是用于估计损失函数最小化的常数值; 收缩性参数v称为“学习率”,决定了每棵树对最终模型的贡献率;β是模型权重。
2002年,Friedman[19]结合Breiman的bagging思想,在Gradient boosting算法基础上引入随机化参数,提出了SGB算法,即在每一次迭代过程中,随机抽取训练样本的一部分来拟合分类器。

(2)

该方法实施后项特征消除来确定生物量预测所需要的Landsat-光谱衍生数据从而实现变量选择。更准确的说,根据式(2)可以计算各个变量的误差平方和减少量,误差平方和减少量越小,特征变量对模型的贡献越大,逐步消除变量贡献率小的变量实现变量选择[20]。
1.5 模型建立与精度评价
基于统计分析软件R的”gbm”包,通过随机梯度Boosting变量选择,选择直接因子、直接因子-间接因子、直接因子-空间因子和直接因子-间接因子-空间因子组合中最优特征组合,探讨不同数据类型组合对于估算结果的影响。
为了验证该模型的有效性,设计了5种常用模型进行对比分析,包括1种一元线性回归模型、2种非线性回归模型(指数模型和对数模型),1种多元线性回归模型(逐步线性回归)和1种多元非线性模型(随机森林模型)。采用均方根误差(RMSE)和决定系数(R2)对模型精度进行评价; 并使用十折交叉[21]验证方法对最优模型进行精度验证。十折交叉验证将数据集划分为10个子数据集,将每个子集数据分别做一次验证集,其余9组子集数据作为训练集,从而避免模型过拟合。
2 结果与讨论
2.1 模型构建
随机梯度Boosting方法进行特征选择与其他特征选择方法的不同之处在于该方法的特征选择是嵌入在训练过程中的,是面向于最终模型性能的。也就是说SGB算法各个特征对模型的影响是通过每个变量对模型的误差平方和减少量来计算得到的,减少量越大,变量对模型的贡献越大。采用SGB算法对由12个直接因子、7个间接因子和56个空间因子(7个波段,每个波段8个特征纹理,共56个)共构建的4个数据集(直接因子、直接因子-间接因子、直接因子-空间因子、直接因子-间接因子-空间因子)进行模型构建。

图2 不同模型的入选波段及变量对模型的贡献占比
基于SGB对四个数据集进行特征波段选择,选择的特征波段及变量所对应的模型贡献占比如图2所示。直接因子模型中,共有7个特征变量入选,其中GNDVI占比最大,达到33.5%。说明植被绿度在该模型中起关键作用。同时研究表明与其他绿度指数相比,GNDVI对于植被叶绿素含量的变化更加敏感。叶绿素反映植被的生长状况,进而反映在生物量方面。其次植被水分(TCW,NDII)和植被盖度(TCD)、植被黄度(NDSVI,NDTI)等因素也对生物量反演具有重要的意义。直接因子-间接因子模型中,共有8个特征变量入选。其中GNDVI同样占比最大,达到30.7%。说明植被绿度和叶绿素在该模型中起关键作用。除了反映水分植被盖度和黄度的指数,还新增加了大气消除指数和土壤消除指数,且均在模型中占有重要的比重。说明在牧草生物量反演中会受到这两个因素的影响。直接因子-空间因子模型中,共有11个特征变量入选,有5个是纹理特征,且平均值Mean_B3(第三波段的均值特征)成为占比最大的特征,占到了22.0%。说明纹理特征在生物量反演模型中具有非常重要的作用。GNDVI同样占比较高,说明植被绿度在生物量反演中的重要性。直接因子-间接因子-空间因子模型中共有11个特征变量入选。其中纹理因子5个,占比41.9%。且Mean_B3在所有特征中占比最大21.7%。直接因子5个,占比43.9%。间接因子2个,占比14.2%。总的来说这些常用数据类型组合从各个方面反映了植被的理化特征,进而反映出生物量。它们之间不仅仅是高相关性,还具有较好的互补性,随机梯度Boosting模型可以较好的克服其共线性问题。
表2为各个模型选择后的变量与样地生物量的建模结果。如表所示,仅采用直接因子与生物量拟合时精度最低,R2为0.80,RMSE为185.85 g·m-2。通过增加间接因子和空间因子均可增加模型的拟合精度。直接因子和空间因子模型的拟合结果表现为R2为0.83,RMSE为158.15 g·m-2; 直接因子和间接因子模型的拟合结果为R2为0.84,RMSE为157.63 g·m-2; 相较于直接因子模型R2均有所增加,RMSE均更低。而直接因子、间接因子和空间因子所组合的特征集进行回归建模R2最高,达到了0.88; RMSE最低,为141.00 g·m-2,是拟合生物量的最优模型。总的来说四个模型都能够较好的拟合草原的生物量。拟合模型的各个因子之间是具有兼容性的,通过因子组合可以更好的刻画生物量与这些特征之间的关系。

表2 模型及精度
2.2 模型对比及偏差分析
我们提出了一种多变量、非线性生物量模型,相比于传统的方法,一个比较明显的区别在于该模型更加的复杂化。为了探索本模型与其他模型在普及方面的区别,我们设计了5个对比模型,1个单变量线性模型,2个单变量非线性模型,1个多元线性模型(逐步线性回归)和一组多元非线性回归模型(随机森林)进行模型的对比分析。分别采用模型精度和交叉验证精度作为评价指标对不同模型与生物量的估算效果进行评价。此外,由于大量的文献提出过饱和问题是遥感反演中的一个制约因素,我们绘制了6种不同模型的残差结果与NDVI的关系图,以便能够直观的观察不同模型对于过饱和问题的效果。
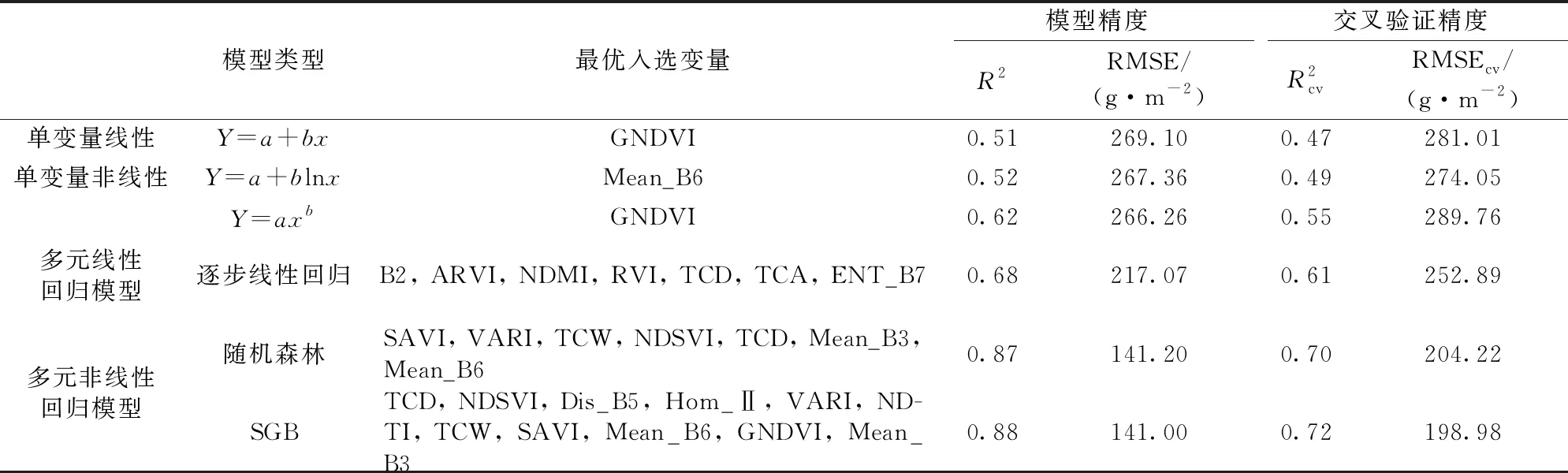
表3 不同模型精度对比

残差反映了模型观测值与估算值之间的偏差。NDVI是一种使用最为广泛的植被指数,但是研究表明,在生物量较高时会出现过饱和问题。因此采用残差-NDVI关系图直观的展示不同模型对于过饱和问题的响应。6组不同模型的残差-NDVI结果如图3所示。总体上讲,6种模型的残差趋势是一致的,当NDVI值小于0.7的时候残差较小,当NDVI值大于0.7时残差突然增大。说明这些模型均受到了过饱和问题的干扰。但图3(e)和(f), 尤其是本模型无论是总体残差还是当NDVI大于0.7后的残差均较小,说明本方法是可行的,能够在一定程度上消除过饱和的影响。

图3 残差结果与NDVI的关系图
2.3 牧草生物量反演及制图
基于上述分析,构建的牧草生物量反演模型较传统的方法具有明显优势,因此将该方法应用于整个研究区生物量反演制图。通过K-Means方法将研究区分为非植被(城区、道路和水域)和植被两类,非植被在制图中予以剔除。结果如图4所示,可以看出研究区牧草生物量分布具有明显的空间差异性。远离城区的牧草生物量较高,而城区周边的牧草生物量明显较低,可能是由于城区周围多为夏季牧场,牛羊放牧制约了牧草生物量的累积,此外旅游开发以及人为活动也会在一定程度影响牧草的生长。

图4 研究区牧草生物量估算结果图
3 结 论
采用Landsat8遥感影像结合地面实测数据进行牧草生物量反演研究。首先通过Landsat8光谱衍生数据所反映的植被理化特征及它们间的关联方式,构建了不同光谱衍生数据的分类体系; 并在此基础上提出了一种基于随机梯度Boosting算法的多变量非线性生物量估算模型,探讨不同光谱衍生数据分类组合对于估算结果的影响。以青海省海晏县为研究区进行方案可行性研究。结论如下:
(1)共收集了27个与生物量相关的Landsat8光谱衍生数据,根据它们所反映的植被理化特征,可以划分为7个小类,它们分别反映了植被的绿度、黄度、水分、植被盖度、纹理特征、消除大气干扰和消除土壤背景干扰。根据它们与植被理化特征的关联方式,7个小类可以合并为3个大类: 直接因子(绿度指数、黄度指数、水分指数、植被盖度)、间接因子(消除大气干扰指数和消除土壤背景干扰指数)和空间因子(纹理特征)。
(2)基于随机梯度Boosting算法探讨了不同光谱衍生数据类型组合对于估算结果的影响,结果表明在生物量估算模型中直接因子、间接因子和空间因子具有互补性。基于直接因子-间接因子-空间因子构建的估算模型优于其他组合模型,R2达到了0.88; RMSE为141.00 g·m-2。

综上,提出了一种利用Landsat数据进行牧草生物量估算的有效方法,一定程度上满足了畜牧业可持续发展的需求,并且该方法可以扩展到其他植被类型和更多生物参量的估算研究。为今后进行大面积区域草地动态监测以及其他农业领域的研究提供了参考和借鉴。
