可见光谱图与深度神经网络的垩白大米检测方法
2020-01-08张华哲何坚强邹志勇陈永明
林 萍,张华哲,何坚强,邹志勇,陈永明*
1. 盐城工学院电气工程学院,江苏 盐城 224051 2. 四川农业大学电机学院,四川 雅安 625014
引 言
大米是世界上最重要的粮食作物,大米品质的好坏直接影响到人们的生活健康状况,如何快速准确地对大米品质进行判别成为目前国际学术领域重要的研究课题。垩白参数是影响大米市场销售价格的主要因素之一。大米垩白是在大米籽粒胚乳中心白色不透明部分,它是由于稻米胚乳中蛋白和淀粉颗粒填充疏松和充气引起的,按其在大米颗粒中出现的部位可分为腹白、心白和背白等类型,是大米籽粒在结构上的一种缺陷[1]。传统的大米垩白的检测方法是基于人工目测抽样检测,主观性较大,不同人员的检测结果往往不一致,这就严重影响了大米品质判别准确度。因此,国内外采用机器视觉结合模式识别处理技术开展了针对大米中的垩白的自动化检测研究。房国志[2]提出了一种基于形态学分水岭的图像垩白区域检测方法。刘璎瑛[3]提出了采用切比雪夫逼近方法的大米垩白自动分割。王卫星[4]提出了基于直方图修正和小波自适应定位多阈值算法对大米垩白区域进行有效分割。黄星奕[5]等采用遗传神经网络对大米垩白度进行计算,结果显示基于机器视觉的检测方法由于图片的获取过程需要外加光源照射,正常米粒中有一部分区域会造成强反射现象,容易引发误判。目前提出的基于机器视觉的垩白大米图像检测方法都是采用由人工来选定目标特征的方式,人工提取到的特征对于大米的垩白特性表达性能不一致,因此最终获得的检测精度并不理想。
为了解决现有垩白大米检测算法效率低,精度不高的问题,提出了一种基于可见光谱图的垩白大米深度检测方法,通过构建深层次卷积神经网络模型对大米垩白区域进行特征提取,通过深层次隐含模型训练来确定网络结构并获取深度检测模型的最佳特征权重参数,进而有效提升垩白大米的检测精度。
1 实验部分
1.1 仪器
基于机器视觉的垩白大米检测分析实验平台系统原理图如图1所示。该系统主要部件由暗箱、CCD像机、图像采集卡、计算机、光源和载物台构成。样品放在暗箱内; 暗箱下面是载物台,暗箱顶部安装有CCD像机,可以同时采集700,550和440 nm附近3个波段的大米可见光谱图像信息。暗箱部安装有光源; 为了避免样品在检测时形成镜面反射,暗箱内表面均粘贴有背景纸,使得光在箱体内形成均匀的漫反射。为了进一步消除光源照射时在背景上产生的阴影,最终选用环形荧光灯管作为照射光源。图像采集采用松下WV-CW370型CCD彩色像机和嘉恒公司的OK_C30A-E型彩色图像采集卡,其中像机镜头采用精工SE1614型F1.4的16.0 mm 24位真彩色高清摄像镜头,其分辨率为1 024×768,并结合环形光源,确保能采集到准确清晰的大米图像信息。一台Alienware 17 R3笔记本电脑(美国戴尔)配置有Nvidia Geforce GTX 980M,8 GB图形卡和Intel Core(tm)i7-6820hk CPU,16G内存卡,1T数据存储容量卡。
1.2 样本
实验样本采用三种不同粒型的大米,糯米、泰国香米和长粒香。白样本信息如表1所示。通过深度学习网络对大米垩白区域进行检测需要大量样本数据对网络进行学习训练,若全部采用实验获取的垩白大米图像会增大采集工作量,并且原始图像数据集不够充分,不能满足网络学习和训练的要求。因此,对采集到的大米图像数据通过旋转、翻转以及调整对比度等随机变换处理对图像数据进行增强,提升网络训练数据集,从而提升网络的整体的学习性能。通过数据增强方法将大米样本集扩充至3300张,用于防止深度检测模型在学习过程中出现过拟合现象。
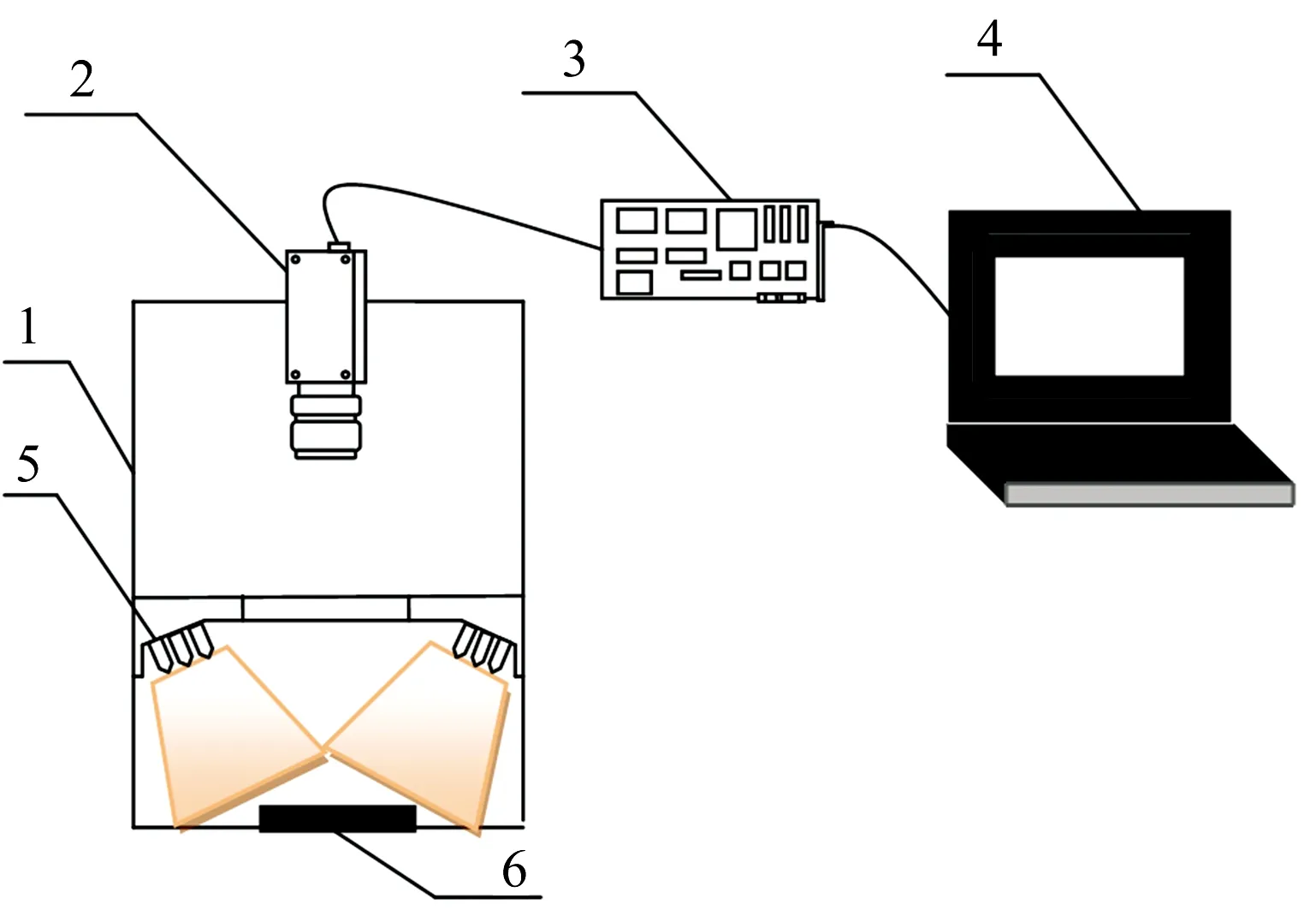
图1 基于机器视觉的垩白大米检测分析实验平台系统原理图
Fig.1Schematicdiagramofchalkyricedetectionandanalysisplatformbasedonmachinevision
1: Black box; 2: CCD camera; 3: Image acquisition card; 4: Computer machine; 5: Light source; 6: Loading platform

表1 大米样本数据集
2 理论和方法
2.1 SIFT算子
尺度不变特征变换(scale-invariant feature transform, SIFT)[6]算子通过在高斯差分尺度空间中寻找尺度域和图像域上的极值点的方法使得特征点对图像缩放、旋转和平移具有不变性。SIFT算子通过特征点附近邻域像素的梯度直方图给每个特征点匹配一个主方向,进而保证特征点对旋转具有不变性,最后利用特征点周围邻域内像素的梯度为提取到的每一个特征点建立一个128维的描述子,由此提取的每一个特征点都可以用一个128维的特征向量进行表示。图2(b)是提取的含有垩白大米图片的SIFT特征点,从图中可以看出,提取的特征点主要集中分布在非垩白区域。
2.2 GIST算子
空间包络算子(GIST)[7]是一种生物启发式算法,该算法通过对人体视觉活动的模拟,获得图像中的上下文信息,从而形成对外部世界的一种空间表示。GIST算子核心主要是将Gabor函数扩展到多尺度空间,并将Gabor滤波器进行多尺度旋转后对垩白大米图像在频率域进行特征获取,并将滤波后的图像进行均匀划分如图2(c)所示,接着采用窗口傅里叶变换和离散傅里叶变换将每个网格图像的全局特征信息提取出来,最终获得可鉴别的垩白大米GIST网格图像的全局特征信息。

图2 (a)原始垩白大米图片; (b) SIFT关键特征分布图; (c) GIST网格图像的全局特征信息
Fig.2(a)Originalchalkyriceimage; (b)SIFTkeycharacteristicdistributionmapofchalkyrice; (c)GISTglobalfeatureinformationofchalkyrice
2.3 PHOG算子
金字塔梯度方向直方图(pyramid of histograms of orientation gradients, PHOG)[8]算子是对形状的一种空间描述,它首先利用Canny 算子提取出图像的边缘信息,其次对图像进行层次化表征,然后提取每层次各子区域的梯度直方图特征,最后将各子区域的梯度直方图特征进行级联,由此构造出原始垩白大米图像的PHOG特征。图3(a)为原始的垩白大米图像; 图3(b1)为垩白大米图像第一金字塔层表征层,即原始图像采用 Canny 算子提取的轮廓图像,图3(b2)为垩白大米图像第一金字塔层特征分布图; 图3(c1)为垩白大米图像第二金字塔层表征层,图3(c2)为垩白大米图像第二金字塔层均匀4等分特征分布图; 图3(d1)为垩白大米图像第三金字塔层表征层,图3(d2)为垩白大米图像第三金字塔层均匀16等分特征分布图; 从图3(b2), (c2)和(d2)中可以看出,随着分割层数的增加,统计梯度直方图对图像的刻画也越来越具鲁棒性和精细化。
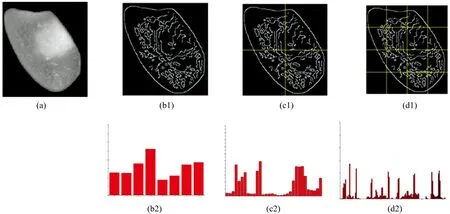
图3 垩白大米PHOG特征分区检测及相应的统计梯度直方图
2.4 深层次卷积神经网络构架
样本图像采集时由于光照、背景等扰动因素影响,通过人工方式设计一个鲁棒性强、能有效表达垩白大米样本特征算子在实际应用中十分困难。因此,提出构建深层次卷积神经网络(convolutional neural networks, CNN)模型来提高垩白大米样本的识别精度,从而避免了繁琐的特征算法选择和特征设计的过程。
2.4.1 卷积网络层结构
传统的神经网络构架每个输出都与每个输入完全相连,而卷积神经网络构架采用局部感受野策略,使得每个输出单元只与输入图片的部分区域相连,因此只能感知获取的图片局部区域,而不能涉及图像的全局信息[9-10],需要利用空间局部相邻单元之间的相关性进行运算。利用CNN实现全局图像特征参数共享,在局部连接中确保每个神经元的参数一致,减少了整个网络的参数数量,有效利用空间局部相邻单元之间的相关性进行卷积运算,改进提高了网络计算精度。如图4所示,垩白大米深层次卷积神经网络模型特征提取模型由输入模块(Input)、卷积运算模块(C1、C2)、池化采样操作模块(S1、S2)、全连接运算(F1)和输出模块(Output)系统构成。卷积层参数可以看作是一种能够通过网络训练和学习得到优化的滤波器,在前向计算过程中,滤波器和上层网络局部区域的数据进行卷积运算后得到新特征参数作为卷积层的神经元,该滤波器在原始图片上按照设定的步长进行滑动,再与各局部区域的数据进行卷积运算,计算出所有的新神经元,由此组成所需要的卷积层。然后将得到卷积层数据输入池化层进行降维处理,网络进行一系列的卷积与池化操作之后接入全连接层,全连接层将提取到的特征向量通过Softmax分类器进行分类,分类结果和数据集标签进行比对并计算损失函数,随后通过梯度下降算法对参数进行反向传播对网络进行优化,从而调整网络参数,网络在不断训练学习的过程中降低损失值(Loss)直到设定的阈值后收敛。

图4 垩白大米深层次卷积神经网络模型特征提取原理图
2.4.2 卷积模块
在卷积模块中使用可训练的卷积核与上一层输出的图像进行卷积运算,卷积核以固定的观察域大小通过在前层输出图像上以设定的步长均匀滑动来实现特征提取操作,通过不同核大小的的卷积特征模块来获取不同尺度图像的语义特征信息。其中,不同的卷积核映射出不同特征,即可以提取出图像中某类特定表达特征,因此用n个卷积核经过卷积运算后就可以提取n种特征,最终输出n个不同语义信息的特征图,具体的均匀滑动卷积运算公式如式(1)所示
(1)
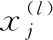
2.4.3 池化操作
在每个卷积层之后都有一个池化层,池化层的功能是降低上一层卷积计算输出的维数,有效减少训练参数的数量,防止过拟合,从而压缩图像的空间大小。经典CNN模型通常采用最大值池化层策略和平均值池化层策略[11-12]。即将提取到的特征图像区域的一部分求最大值或者平均值,由求得的矩形邻域内的最大值或平均值来代表该部分区域,其中最大值池化策略最常用。池化层的计算公式如式(2)所示。
(2)
其中,β为特征图系数,down(·)为采样函数。在卷积神经网络中,卷积层与池化层通常交替进行,并且每个卷积层都包含多个特征图,每个卷积核对应一种特定特征,因此每个卷积层都能提取出多个特征图,这些特征图经过线性组合形成更抽象的卷积特征图,由此形成对输入图片的语义特征描述。
2.4.4 全连接层
输入图像经过多层的卷积和池化操作处理后,最终提取的特征图按行展开成向量输入全连接网络。在全连接层中,每个神经元都要与前一层网路中的所有神经元相连,最后全连接层与输出层相连,输出属于各个类别的得分值。输出层通常为分类器,常用的分类器有Softmax函数作为特征分类器,函数计算公式如式(3)
(3)
式中,h(x(i))表示样本i属于第k类的概率,总类别数为K。
3 结果与讨论
采用的CNN网络结构主要包含3层,分别由输入层、隐含层和输出层构成。隐含层包括5个 层,即C1,S1,C2,S2和F1。第一层的输入为网络训练提供数据,由于深度学习的框架要求输入图片大小统一为227×227大小的彩色图像,因此将数据库中所有输入图片调整为像素尺寸为227×227的标准。C1层为第一层卷积层,该卷积层通过大小为9×9的卷积核按照设置步长为2滑动,随后提取出6幅124×124大小的特征图,S1层为第一层池化层,该层将上层提取的特征图按1∶2的比例采用最大值池化策略进行下采样处理得到6幅62×62大小的特征图; 第二层卷积层为C2层,该卷积层通过大小为5×5的卷积核按照滑动步长为1,提取出12幅58×58大小的特征图,S2层为第二层池化层,下采样比例设定为1: 2,由此获得的特征图尺寸为29×29,最后将提取的12幅特征图与全连接层相连; 全连接层F1分别与上一层的对应单元相连接,共有10 092个单元,最后输出层包括两个分类单元,给出预测的分类结果。其中一类对应包含垩白的大米样本,另一类为正常大米样本。
3.1 整定网络训练参数
深度卷积网络的训练批处理参数设为64,迭代次数设为250,学习率设为0.1。测试了三种不同激活函数的收敛情况,如图5所示。当增加CNN神经网络训练迭代次数时,Loss值总体呈现下降趋势。当迭代次数达到100次后,下降趋势得到缓和,曲线趋于平缓。当迭代次数达到200后,损失值小于0.1,虽然仍然有所降低,但下降程度不明显。Sigmoid函数的损失值在迭代次数为100到200区间有所上升,在迭代次数达到200后损失值继续下降并趋于收敛。因为Sigmoid函数是连续非线性的软饱和函数,且其导函数在整个定义域内连续; Tanh函数的收敛程度与Sigmoid函数接近; 当迭代次数为150时收敛,但损失值较大。ReLU函数收敛速度较慢,主要原因时ReLU函数是分段的非线性函数,导致不同区域的部分特征线性没有得到有效处理,但当在迭代次数为200时,收敛性能得到了有效的改善,即输出的Loss值最小,因此本研究选用ReLU函数作为激活函数来训练网络。
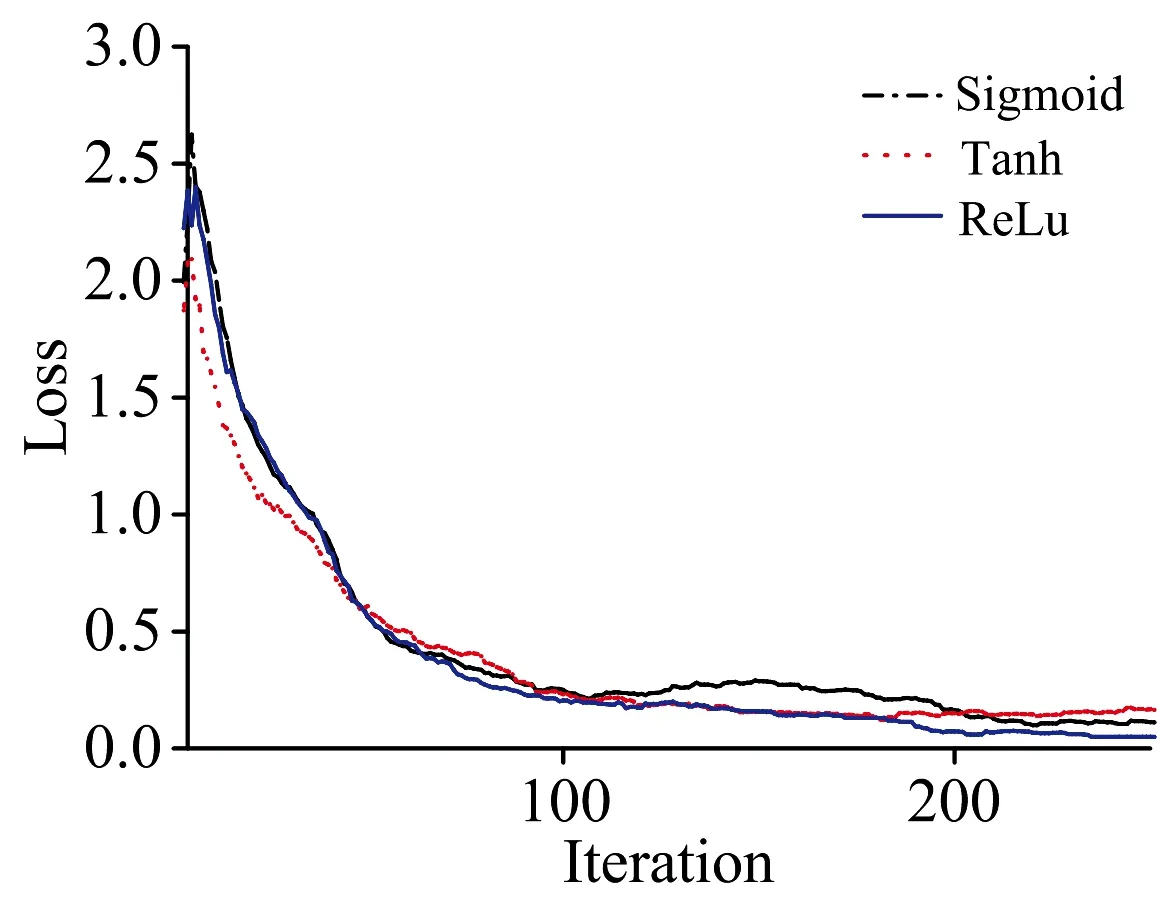
图5 不同激活函数迭代次数与损失值之间的关系
Fig.5Therelationshipbetweenthenumberofiterationsandthelossvaluefordifferentactivationfunctions
3.2 算法性能比较
图6为四种不同预测模型的查全率查准率曲线图(precision recall curve),图中纵坐标为查全率(recall),横坐标为查准率(precision)。通常评判检测模型好坏时,查全率查准率值越高模型检测效果越好,也就是查全率查准率曲线上的点越接近右上角坐标(1, 1)说明模型检测效果越好。因此,查全率查准率曲线覆盖面积(Area under Curve,AUC)是综合评定检测模型性能的指标之一,其值越接近1说明模型预测效果越好。从查全率查准率曲线可以看出,对于验证集样本CNN模型的查全率查准率曲线覆盖面积最大,预测准确率最高,其次依次为GIST+SVM, PHGO+SVM和SIFT+SVM模型。
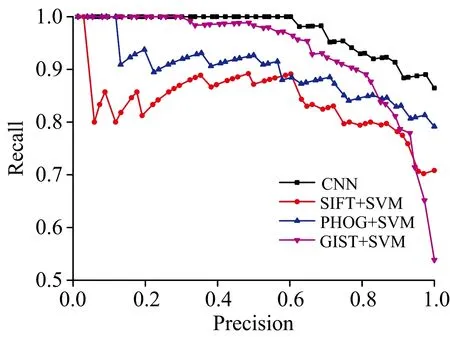
图6 四种不同模型验证集样本查全率查准率曲线图
表2为训练集样本和验证集样本分别采用SIFT+SVM,PHOG+SVM,GIST+SVM和CN四种不同方法建立的检测模型效果。对于训练集样本SIFT+SVM,PHOG+SVM,GIST+SVM和CNN四种建模方法的检测精度分别为81.47%,83.84%,78.76%和94.79%,其中CNN模型的精度最高。还计算了mAP (mean average precison)值,在训练集样本中CNN的mAP值最高为0.93,PHOG+SVM,SIFT+SVM和GIST+SVM模型分别为0.86,0.89和0.88。在训练集样本中CNN表现出了最优的检测性能。对于验证集样本,CNN的预测精度最高为90%,mAP值为0.91,预测效果明显好于其他三个模型。SIFT+SVM,PHOG+SVM,GIST+SVM的三个模型检测精度分别为70.83%,77.08%和79.16%,因此CNN模型的检测方法要优于基于传统特征提取的垩白大米鉴别方法。说明构建的深层次卷积神经网络模型提取到的特征对大米垩白特征具有更鲁棒的表达,泛化效果更好,从而使垩白大米检测效果得到显著的提升。

表2 四种不同模型检测性能参数
4 结 论
构建了深度卷积神经网络模型应用于垩白大米可见光谱图的检测,与传统的图像识别方法相比,深度卷积神经网络不需要人为地对输入图片进行特征提取,采集到的图像能够直接输入到神经网络中,特征提取的工作由卷积神经网络通过学习和训练自动完成,免去了复杂的特征提取步骤,大大减少了数据预处理的难度。同时权值共享策略与局部感受野减少了参数空间,大大降低了算法的复杂度,提高了算法效率,增强了网络的鲁棒性和泛化性。当卷积神经网络的学习率为0.1,迭代次数为200时,模型的识别精度最高为90.00%。传统基于可见光谱图的垩白大米鉴别方法SIFT+SVM,PHOG+SVM和GIST+SVM分别为70.83%,77.08%和79.16%。本方法为当前我国现代农业生产大米品质自动化快速精准检测提供了理论依据和有效的技术支撑,具有一定的理论价值和实际意义。
